
批量测评
批量测评为机器人效果验证提供了一套更高效、更系统的测评方式。机器人实际效果好不好,不必再靠少量对话手动判断。您可以通过 回放测试 或 AI仿真测试 批量生成对话结果,结合大模型智能评分与人工核验,从整体指标到单通明细多层次评估机器人表现,快速发现问题场景和可优化点,支撑更高效的话术优化与效果迭代。
批量测评包括以下三个模块:
- 测评任务:用于创建、执行和管理批量测评任务,查看整体结果与会话明细
- 测试集:用于沉淀和管理测评使用的数据内容,作为回放测试的输入来源
- 评分规则:用于定义机器人回答的评判标准,帮助系统按照业务预期对测评结果进行评分
1. 测评任务
测评任务用于统一管理已创建的批量测评任务。您可以在该页面新建任务,查看任务执行状态与核心结果,并进入详情页进一步查看具体会话表现。
1.1 新建任务
点击页面右上角“新建任务”,打开新建任务弹窗。
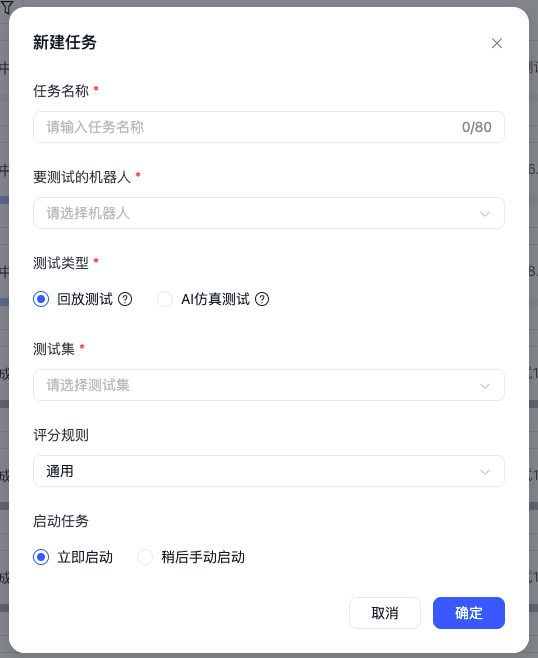
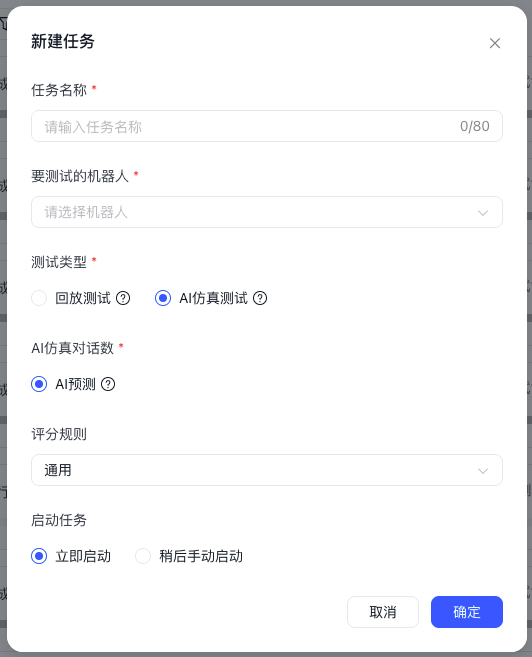
您需要完成以下配置:
- 任务名称:用于标识本次测评任务
- 要测试的机器人:选择需要参与测评的机器人(已发布版本)
- 测试类型:选择本次任务采用的测评方式
- 测试集:选择本次任务使用的测试集(AI仿真测试无需选择测试集)
- 评分规则:选择本次任务使用的评分标准
当前支持以下两种测试类型:
- 回放测试:基于测试集中已有的用户问题、问题顺序及变量信息,与机器人对话
- AI仿真测试:由AI模拟用户,与机器人对话
当配置完成后,点击“确定”即可创建任务。若选择“立即启动”,任务创建后将直接进入执行流程;若选择“稍后手动启动”,任务将先保留在任务列表中,便于后续按需启动。
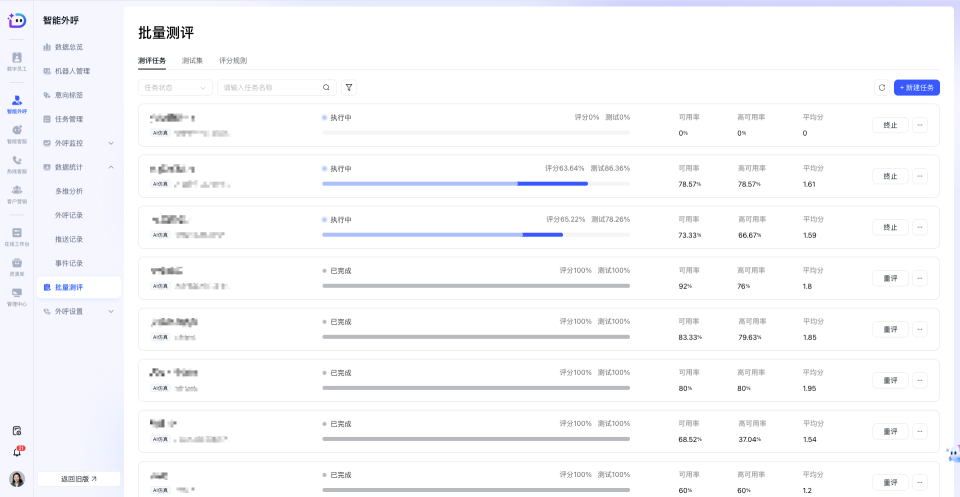
1.2 查看任务列表
您可以在页面快速查看任务执行情况,并通过筛选或搜索定位目标任务。页面会展示任务的核心结果指标,便于您快速判断当前机器人整体表现。 页面支持以下常用操作:
- 按任务状态筛选任务
- 按任务名称搜索任务
- 启动待执行任务
- 对已完成任务发起重评
- 进入任务详情查看具体结果
1.3 查看测评结果
点击任务卡片,进一步查看本次测评任务的整体表现和会话明细。
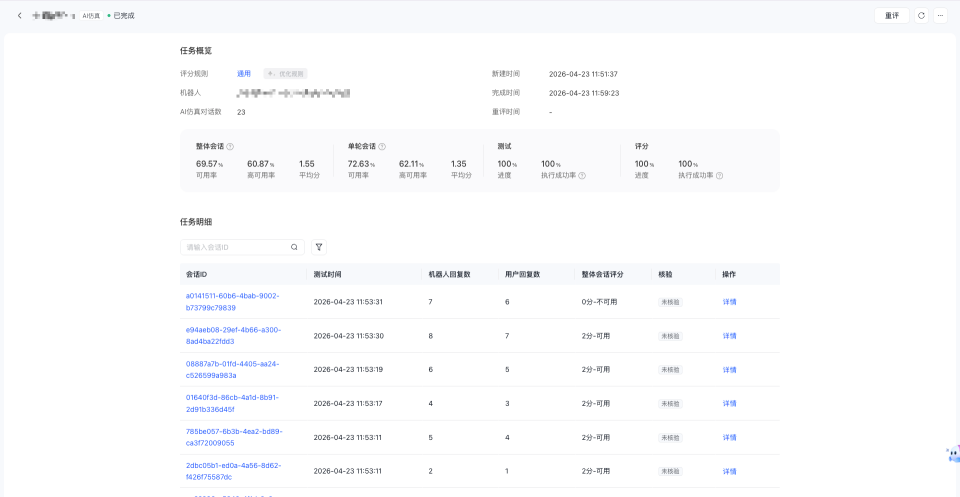
任务详情主要分为两部分:
- 任务概览:任务的整体执行情况与核心指标
- 任务明细:任务下各个会话的测评结果,支持逐条进入详情
1.3.1 任务概览
任务概览会展示任务的核心统计结果,您可以先从整体上判断机器人当前效果,再查看问题会话和具体原因。
-
整体会话维度指标
- 可用率:达到可用及以上标准的会话占比,衡量机器人在整通对话层面的整体可用程度
- 高可用率:达到更高质量标准的会话占比,衡量机器人在整通对话层面的高质量表现
- 平均分:全部会话整体评分的平均值,反映机器人在整通对话层面的综合表现水平
-
单轮会话维度指标
- 可用率:单轮回复评分为“基本可用”或“可用”的回复数,占全部回复数的比例
- 高可用率:单轮回复评分为“可用”的回复数,占全部回复数的比例
- 平均分:全部单轮回复评分的平均值
-
测试执行情况
- 执行成功率:测试的成功执行比例,反映测试阶段的整体执行稳定性
-
评分执行情况
- 执行成功率:评分的成功执行比例,反映评分阶段的整体执行稳定性
1.3.2 任务明细
任务明细展示本次测评任务下的会话列表。您可以在此查看每通会话的基础信息和整体评分结果,并支持按会话ID快速搜索指定会话。当需要进一步定位问题时,您可以点击“详情”查看该通会话的完整测评内容。
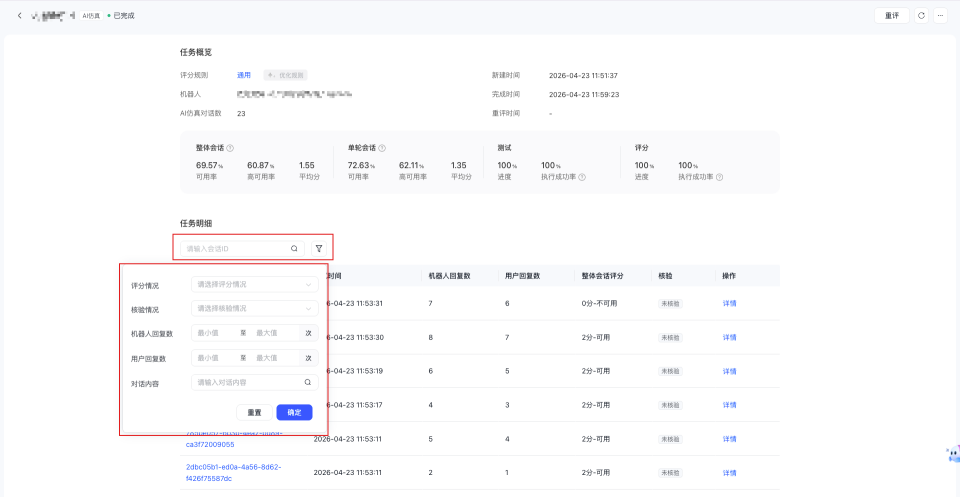
您可以重点关注以下信息:
- 会话的测试时间
- 机器人与用户的回复轮次
- 当前会话的整体评分结果
- 当前会话是否已完成人工核验
1.3.3 查看单通会话详情与核验评分
进入会话详情后,您可以查看该通会话的完整对话过程,以及系统给出的评分结果与原因。当您发现系统评分与实际判断不一致时,可以结合人工核验对结果进行修正,修正后的评分结果及原因会辅助优化评分规则。
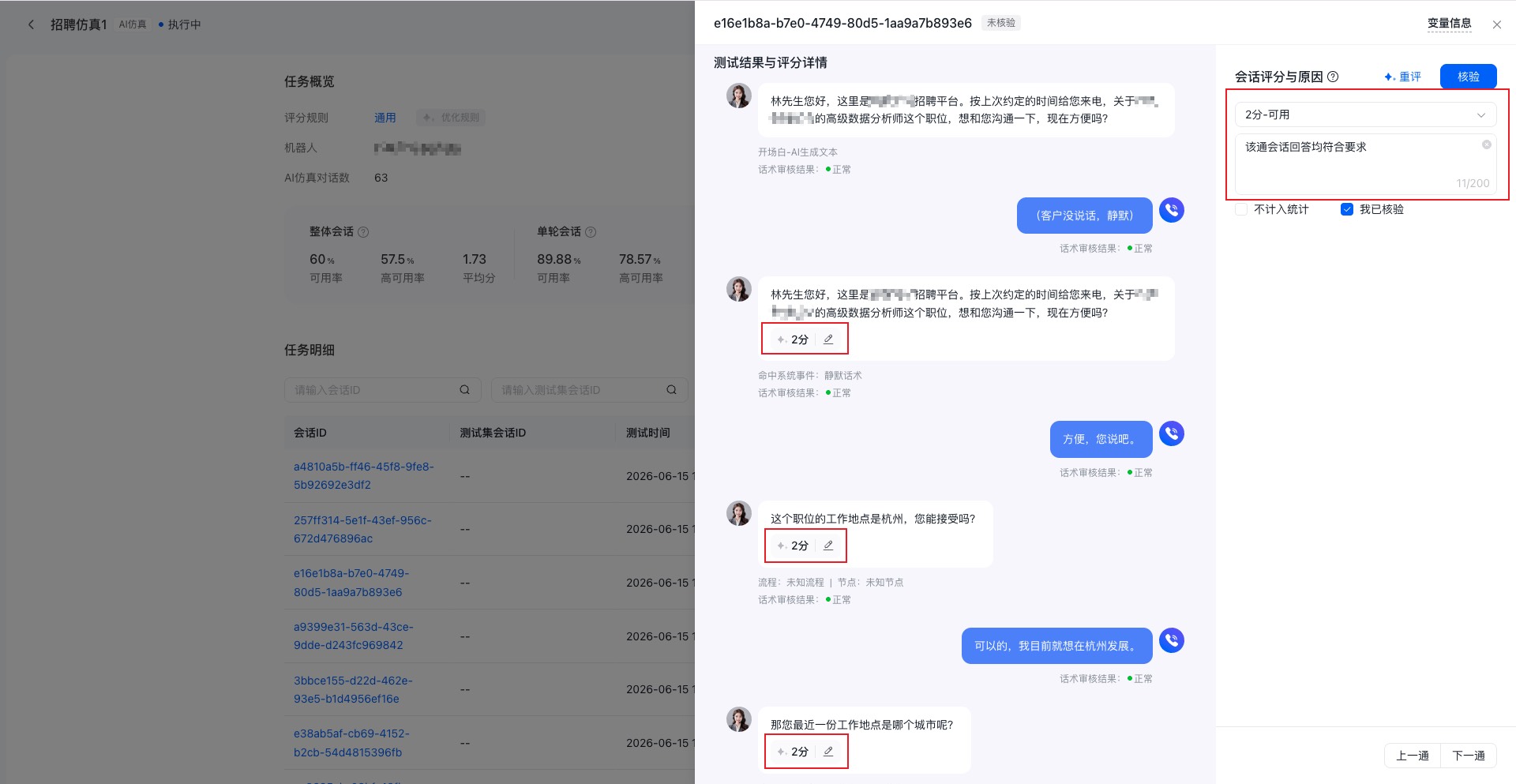
在该页面中,您可以:
- 查看机器人与用户的完整对话内容
- 查看单轮回复的评分情况
- 查看当前会话的整体评分与评分原因
- 对当前会话进行人工核验
- 在相邻会话之间快速切换
若您发现某条测试结果不符合预期时,还可以将该通会话标记为“不计入统计”。 这类结果虽然会保留在任务明细中,但不会作为机器人效果评估的参考。您可以勾选“不计入统计”,并点击“核验”或直接切换会话,将该通会话标记为不参与任务整体指标统计。
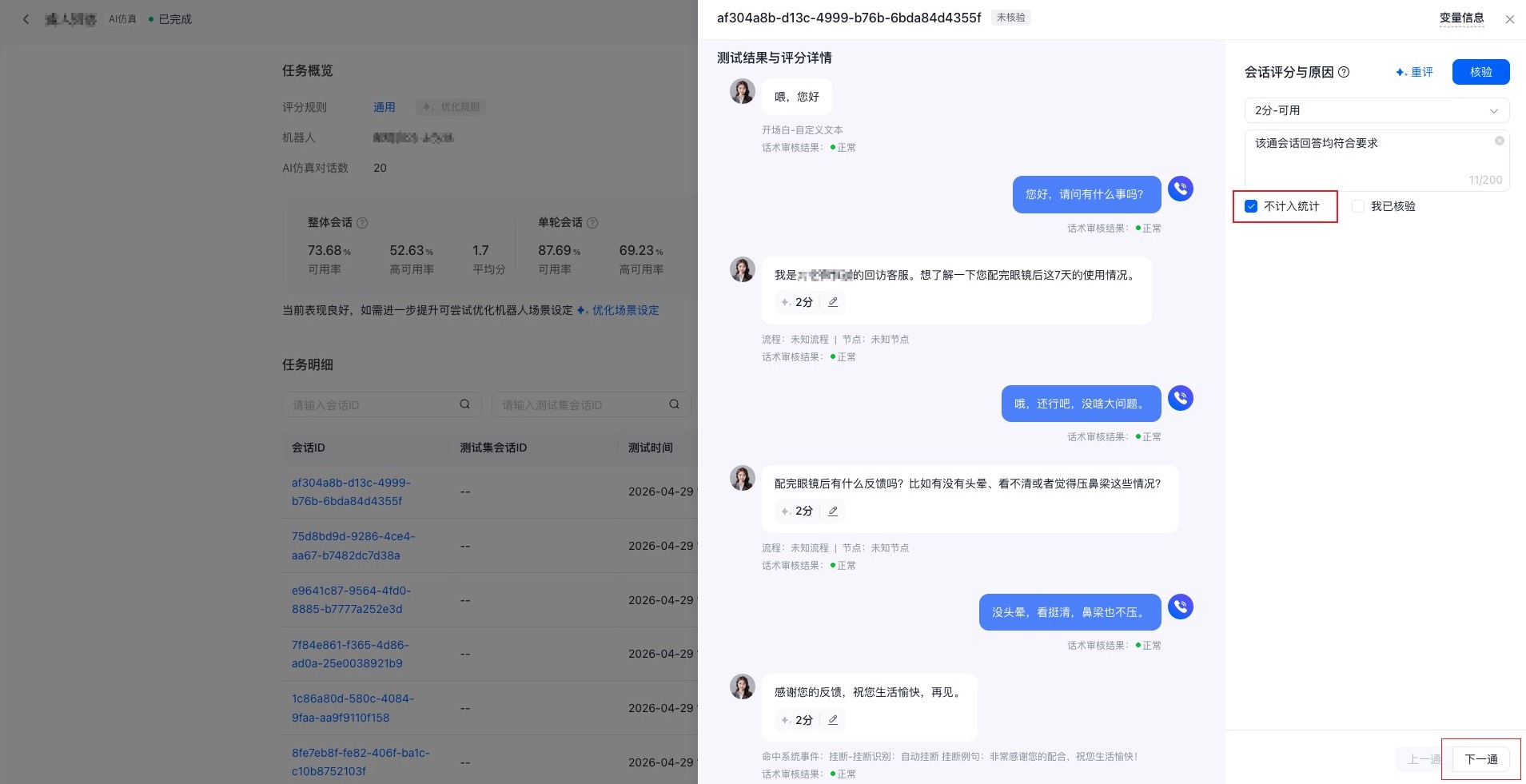
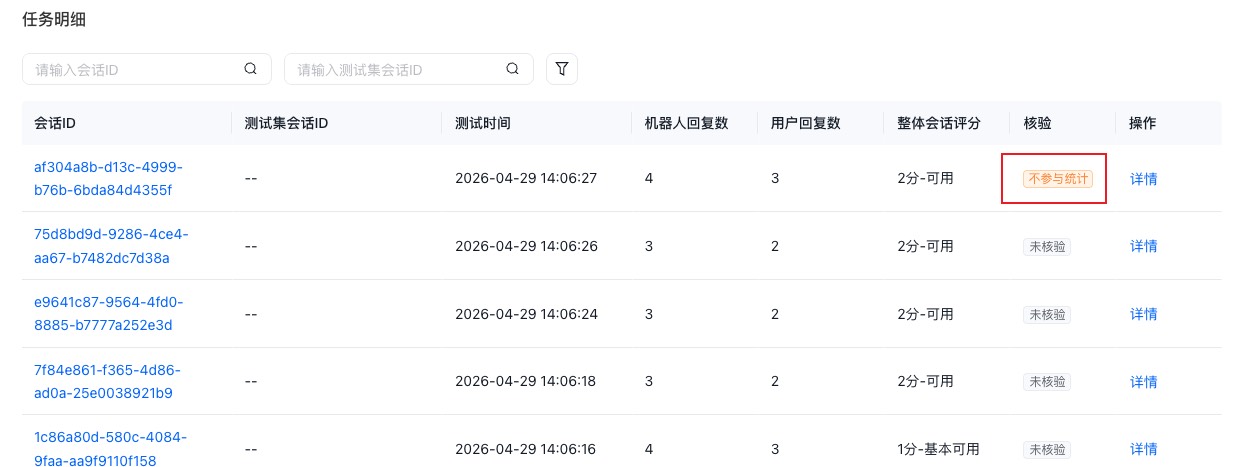
1.4 一键优化机器人
您可以将不符合预期的会话作为参考,由AI辅助优化新版快捷场景机器人。
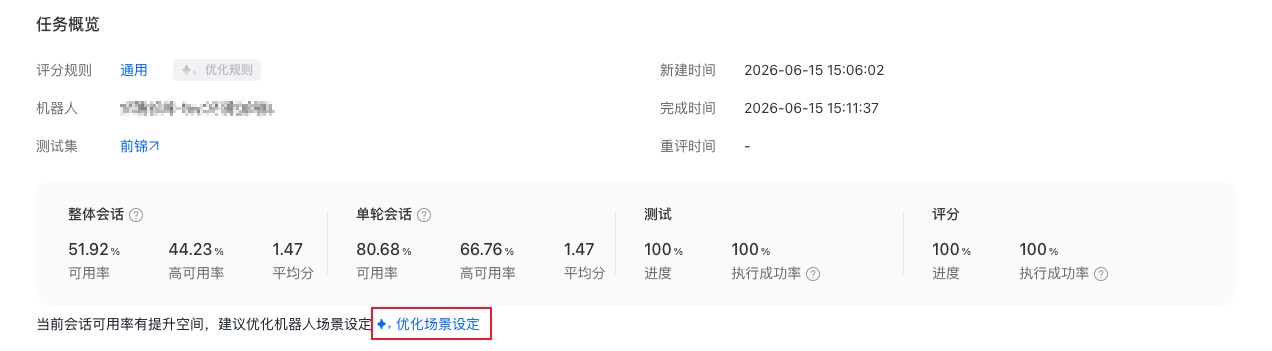
系统会结合会话内容、评分结果及问题表现,生成优化后的场景设定,并支持查看优化说明,帮助您快速定位本次调整的主要方向。您也可以开启对比原版,查看优化前后的差异,再决定是否采纳。

采纳优化结果后,系统可自动发布机器人,并创建新的测评任务,便于您对优化效果进行回归验证。

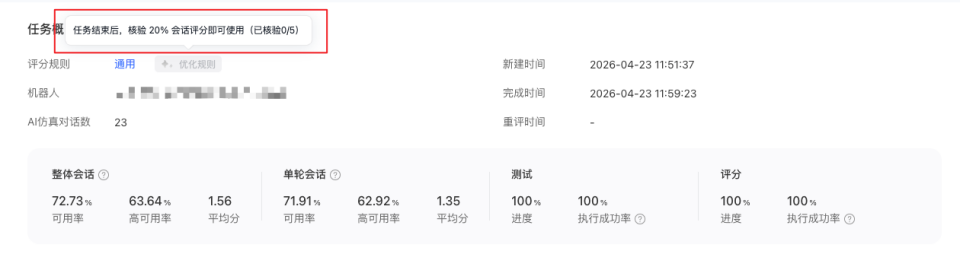
1.5 优化评分规则
当人工核验达到一定阈值后,您可以基于已核验结果对评分规则进行针对性优化,生成更贴近业务预期的优化规则,帮助后续任务获得更准确的评分结果。 系统会结合以下信息生成新版评分规则:
- 核验后修改的评分结果
- 自定义评分原因
当核验量未达到要求时,优化规则入口将暂不可用。页面会展示当前可用条件与完成进度。
生成优化规则后,您可以先查看规则内容,并在已核验会话上测试新规则效果。点击“使用新规则”后,该规则会保存至评分规则管理中,便于在后续任务中直接复用。
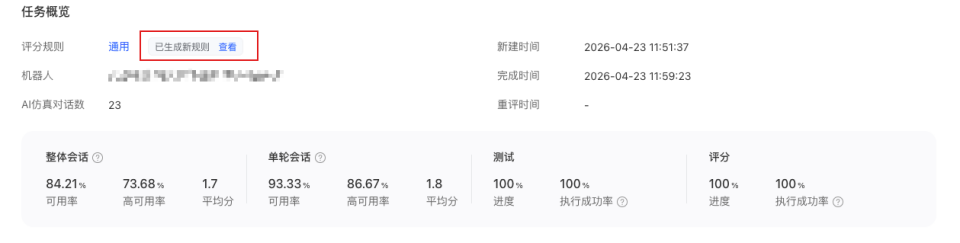

1.6 重评任务
对于已完成的任务,您可以在任务列表页或任务详情页发起重评。 当您已完成一定量的人工核验后,建议优先基于核验结果优化评分规则,再使用新规则发起重评。这样可以使重评结果更贴近实际业务判断。 重评适用于以下场景:
- 评分规则调整后,希望重新评估历史任务结果
- 希望基于最新评分标准重新查看任务表现
- 希望进一步校正原有评分结果
发起重评后,系统会重新执行评分流程。建议在查看重评结果时,结合整体指标与具体会话明细一并判断任务效果变化。
2. 测试集
测试集用于沉淀和管理回放测试所使用的数据内容,作为机器人批量回放验证的输入来源。您可以在该页面创建测试集,查看测试集的数据量与更新时间,并进入详情页进一步核查、补充或清理测试数据,为后续测评任务提供稳定的数据基础。
2.1 新建测试集
点击页面右上角“新建测试集”,打开新建测试集弹窗。

创建测试集时,您需要完成以下配置:
- 测试集名称:用于标识当前测试集
- 导入文件:上传测试数据文件,作为测试集内容来源
导入前,请先下载模板并按要求填写数据,您可自行构造或是从外呼记录中直接筛选合适的数据。 如需在回放测试中验证变量或静默场景,可在测试集中同步配置:
- 变量:将
customer_name、order_info等变量随测试对话一并传入。测试执行时,系统会使用机器人话术中实际引用的变量;未被引用的多余变量不会影响对话效果 - 静默:在用户问题中填写「(客户没说话,静默)」,即可模拟客户未说话、无响应等场景
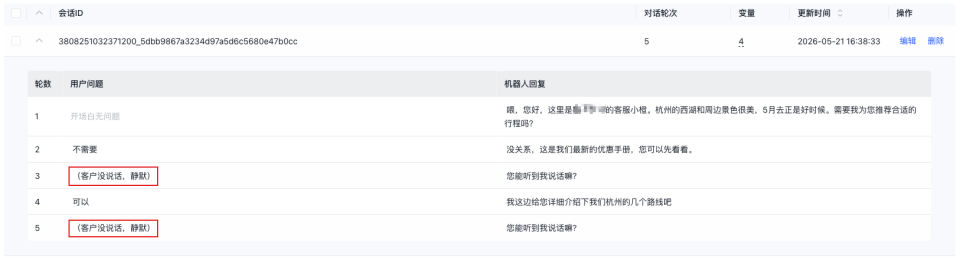
配置完成后,点击“确定”即可创建测试集。
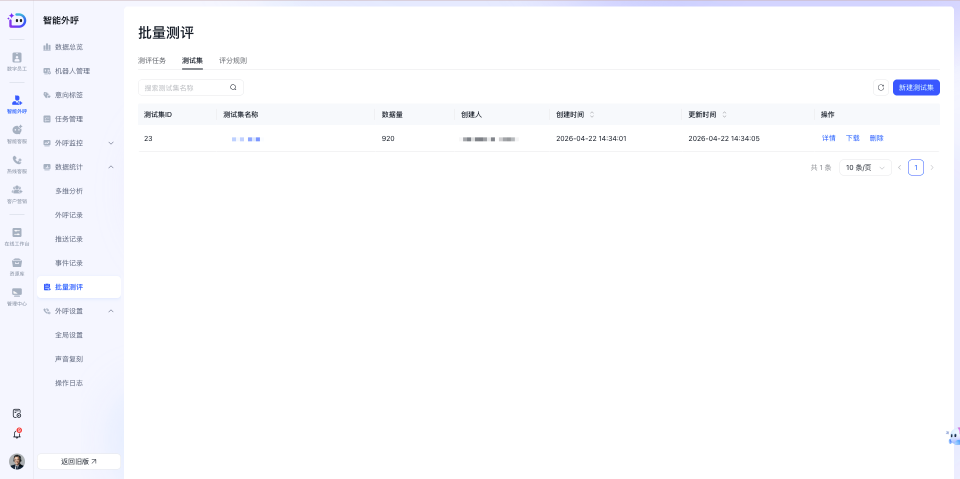
2.2 查看测试集列表
测试集列表页用于统一查看和管理当前租户下已创建的测试集。您可以在该页面快速查看测试集的基本信息,并通过搜索定位目标测试集。 页面会展示以下信息:
- 测试集ID
- 测试集名称
- 数据量
- 创建人
- 创建时间
- 更新时间
页面支持以下常用操作:
- 按测试集名称搜索测试集
- 新建测试集
- 查看测试集详情
- 下载测试集
- 删除测试集
2.3 查看测试集详情
点击测试集名称或“详情”后,可进入测试集详情页,查看当前测试集内已导入的测试内容。 您可以展开单条会话,查看该会话下各轮对话内容,便于核查测试数据是否完整、顺序是否正确、内容是否符合预期。
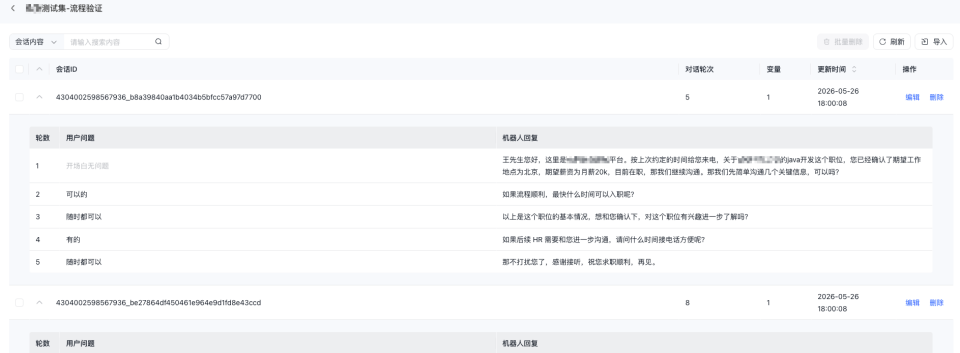
页面中主要展示以下内容:
- 轮数:当前会话中的对话轮次
- 用户问题:该轮用户输入内容
- 机器人回复:该轮对应的历史机器人回复内容
- 变量信息:当前会话随测试集同步传入的变量内容
您可以重点关注以下内容:
- 用户问题内容是否完整
- 用户问题顺序是否合理
- 是否存在明显异常或不适合用于测试的数据
2.4 管理测试集数据
在测试集详情页中,您可以对测试数据进行进一步维护,确保测试集内容持续可用。 当测试集中的部分数据不再适合继续使用时,建议及时清理或更新,避免影响后续回放测试结果的准确性。 页面支持以下常用操作:
- 按会话内容 / ID搜索:快速定位目标测试数据
- 导入:继续向当前测试集中补充数据
- 刷新:刷新当前测试集内容
- 编辑:修改单条会话内容、变量值
- 删除:删除单条会话
- 批量删除:批量清理不再需要的测试数据
3. 评分规则
评分规则用于定义机器人回答的评判标准,帮助系统在批量测评中对会话结果进行统一评分。您可以在该页面创建、查看和管理评分规则,为不同类型的测评任务配置更贴近业务目标的评分标准。
3.1 新建评分规则
点击页面右上角“新建评分规则”,进入新建页面。
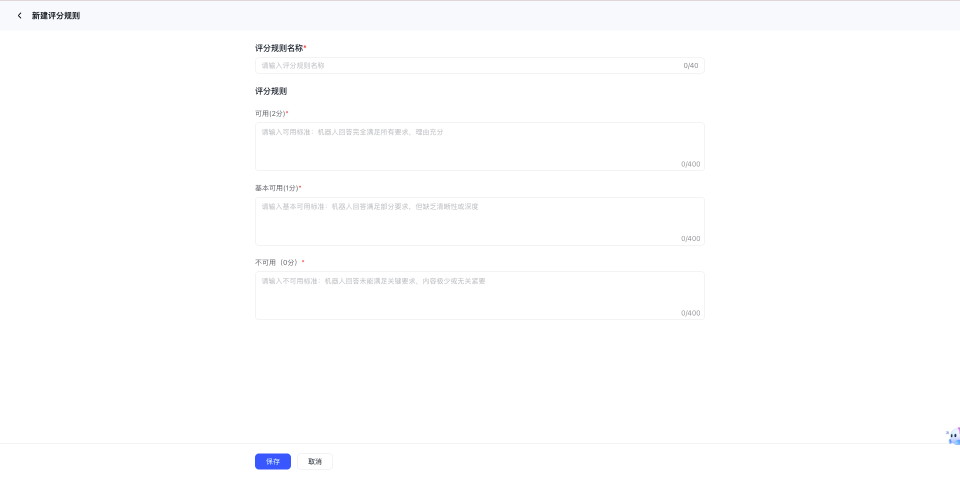
创建评分规则时,您需要完成以下配置:
- 评分规则名称:用于标识当前评分规则
- 可用(2分)标准:定义什么样的回答可判定为“可用”
- 基本可用(1分)标准:定义什么样的回答可判定为“基本可用”
- 不可用(0分)标准:定义什么样的回答应判定为“不可用”
填写完成后,点击“保存”即可创建评分规则。
3.2 编写建议
为了让评分结果更稳定、更贴近实际业务判断,建议您在编写评分规则时尽量保持标准清晰、边界明确。 建议重点关注以下几点:
- 围绕业务目标定义标准:优先描述什么样的回答算有效
- 区分三档评分边界:避免“可用”“基本可用”“不可用”之间标准重叠,影响评分稳定性
- 尽量使用可判断的描述:例如是否回答关键问题、是否提供有效信息、是否明显偏题等
- 避免标准过于宽泛:过于抽象的描述可能导致模型评分结果不稳定
当您在人工核验过程中发现系统评分与实际判断存在偏差时,也可以基于核验后修改的评分结果与自定义评分原因,对评分规则进行进一步优化。
3.3 编辑与复用评分规则
已创建的评分规则支持在列表页直接编辑或删除。 当您需要在多个测评任务中使用相同的评分标准时,可直接在创建任务时选择已有评分规则,无需重复配置。
若您已基于人工核验生成优化后的评分规则,应用后也会自动保存至评分规则管理中,便于后续任务直接复用。
评价此篇文章