
语音
更新时间:2025-11-04
配置语音识别和语音合成相关流程
1、语音识别
语音识别(Automatic Speech Recognition, ASR)是一种将人类语音转换为可读文本或指令的技术,其核心是通过算法和模型理解语音信号中的语言内容
1.1、热词管理
在调用ASR模型进行录音文件识别时,如果用户所在的业务领域有一些特有词,默认识别效果差的时候使用热词管理,将这些词添加到词表,有助于改善识别效果。
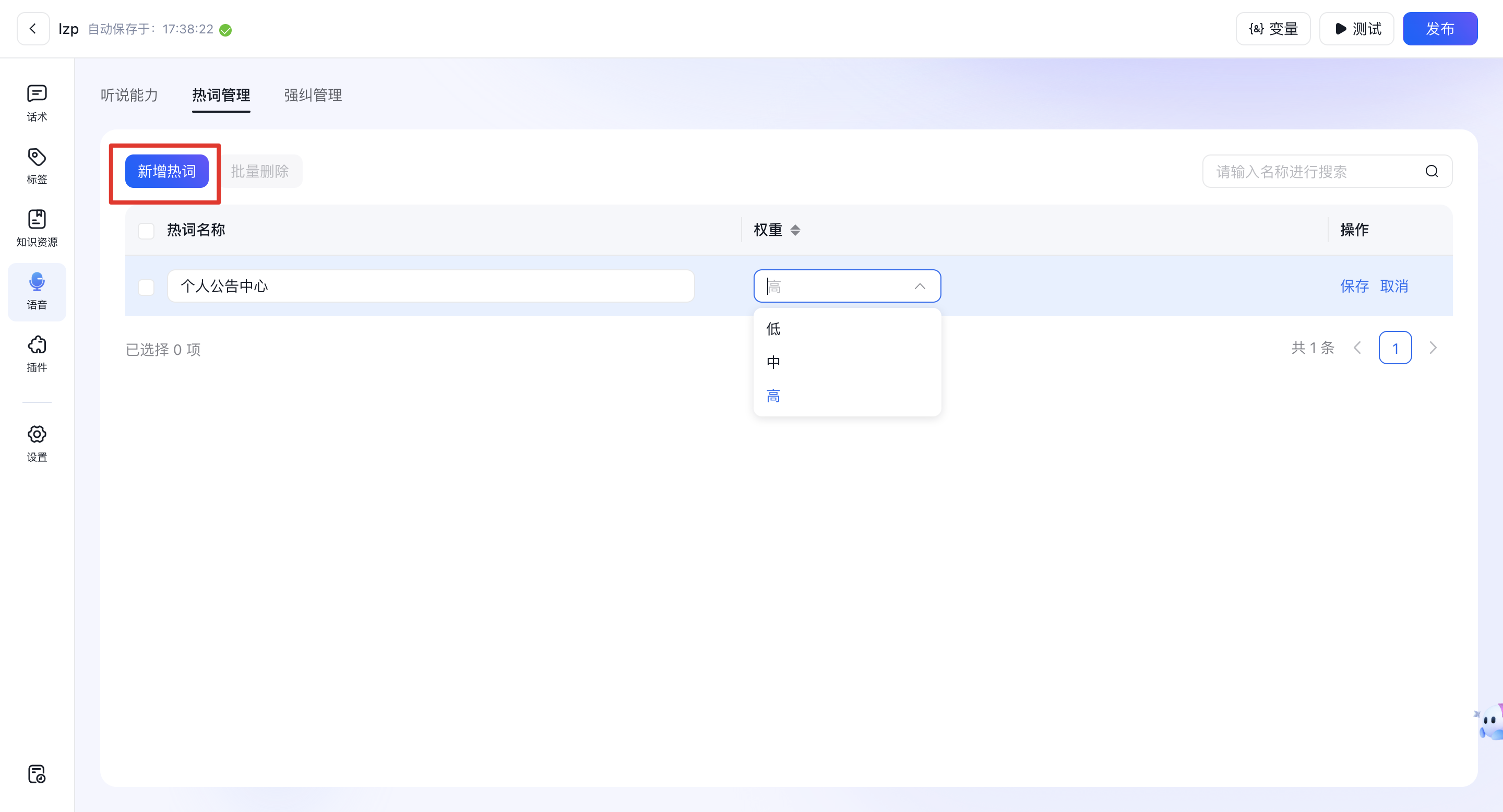
1.1.1、新增热词
-
用户可点击「新增热词」,在词条列表增加一行新热词条目进行配置。
- 热词字符数限制在2-10个字符
- 支持设置热词权重,权重范围为“低”、“中”、“高”
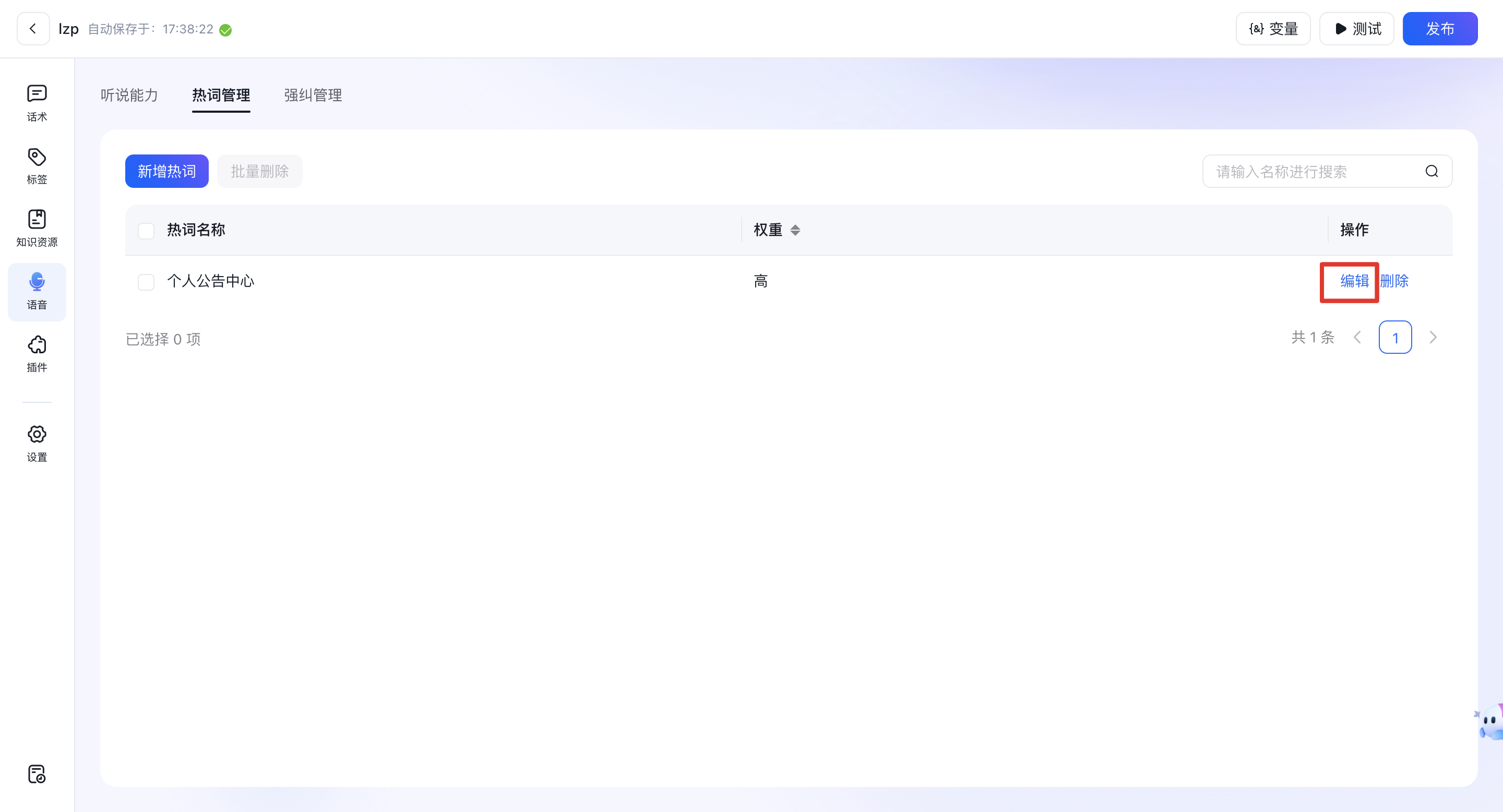
1.1.2、编辑热词
- 支持修改名称以及对应权重
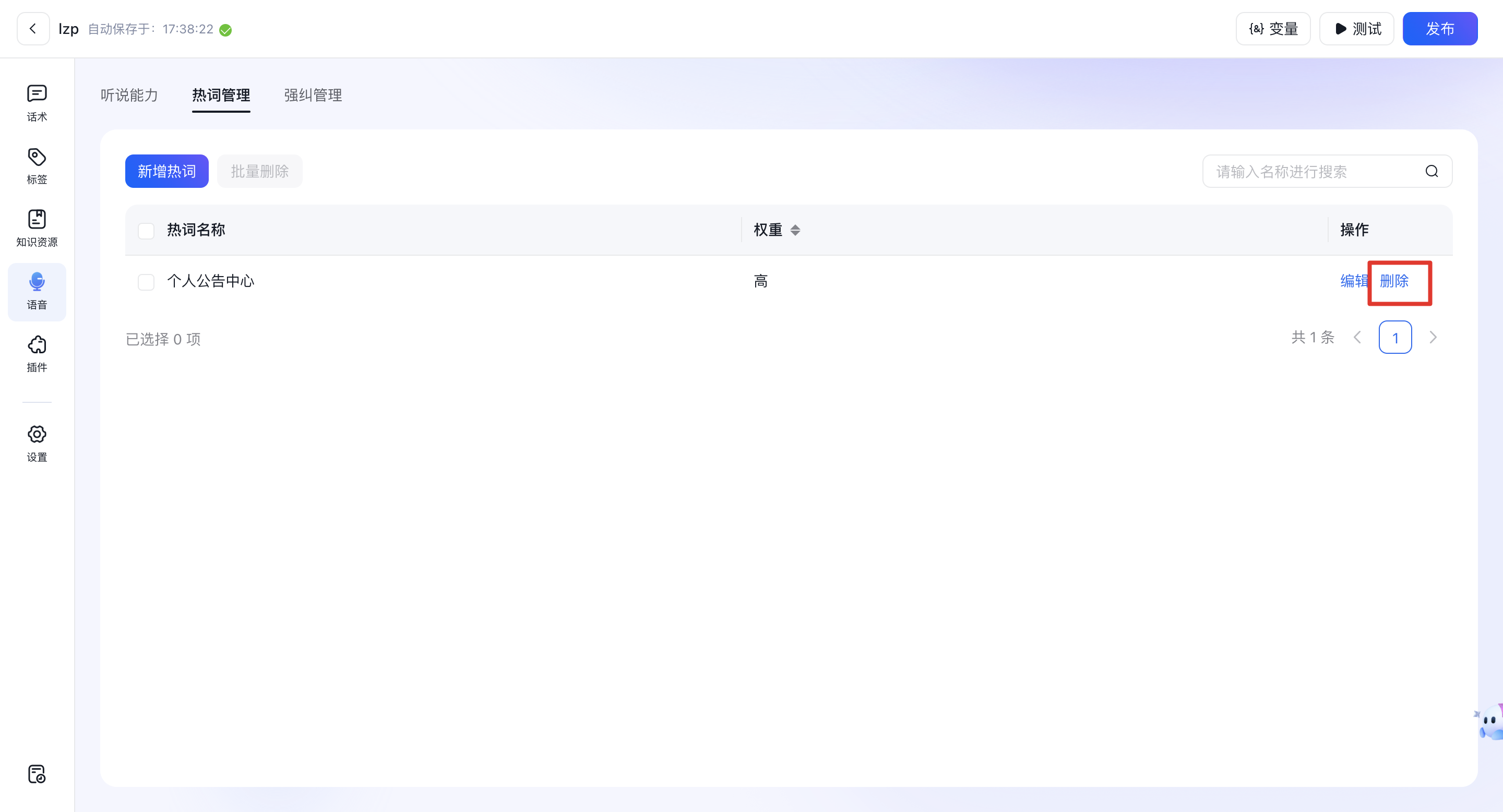
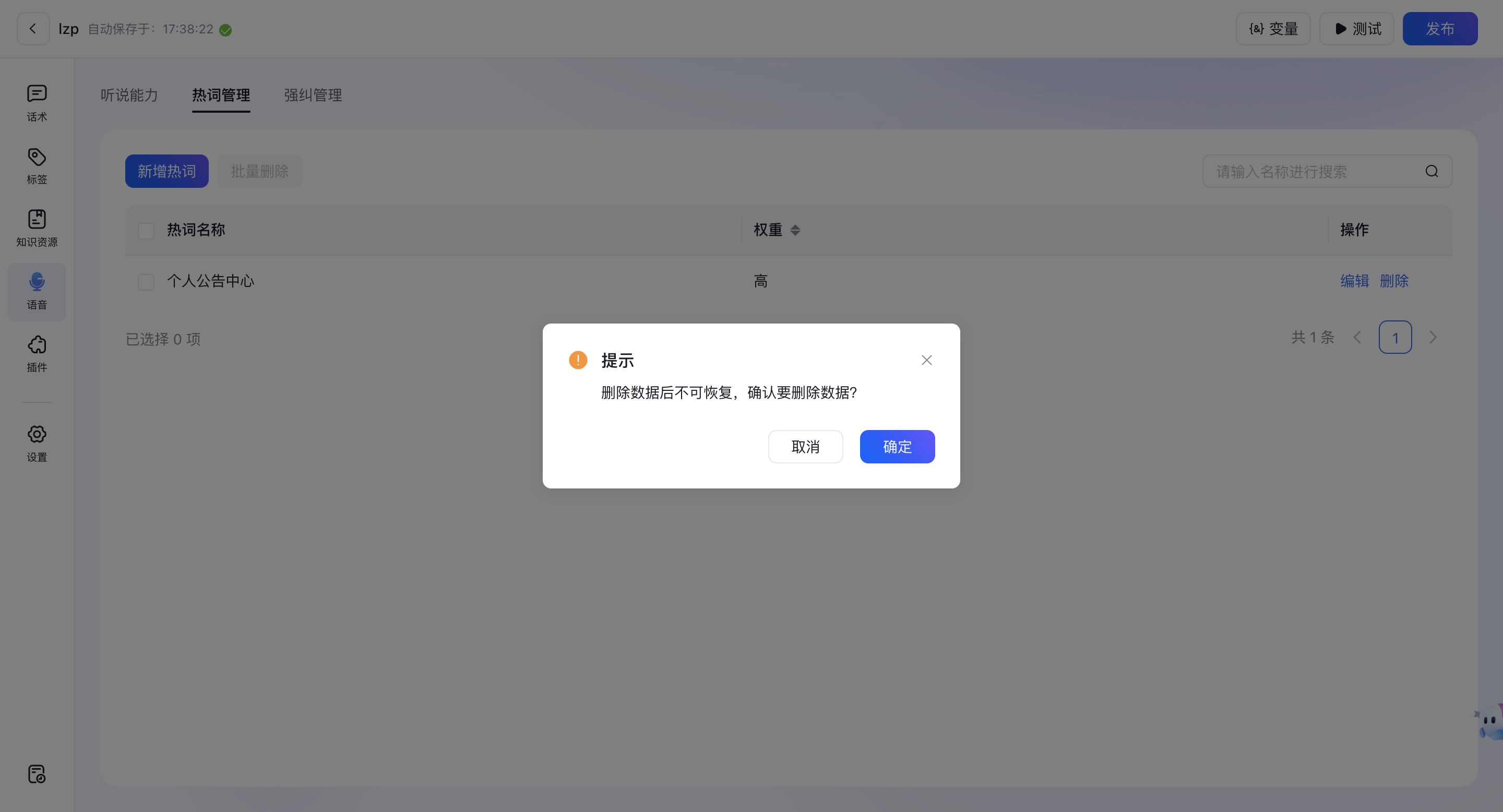
1.1.3、删除热词
- 点击“删除”根据提示选择“确定”确认删除。
1.2、强纠管理
在调用ASR模型进行识别时,如果用户所在的业务领域有一些专业术语/词,默认识别效果差的时候使用强纠管理,将这些词和对应的识别错的内容进行一一对应的配置,有助于改善识别效果。
1.2.1、新增强纠词
-
用户可点击「新增强纠词」,在词条列表增加一行新强纠条目进行配置。
- 强纠词字符数限制在2-10个字符,仅支持中英文数字字符
- 支持设置强纠正确词、错误词
1.2.2、编辑强纠词
- 支持修改强纠正确词和错误词
1.2.3、删除强纠词
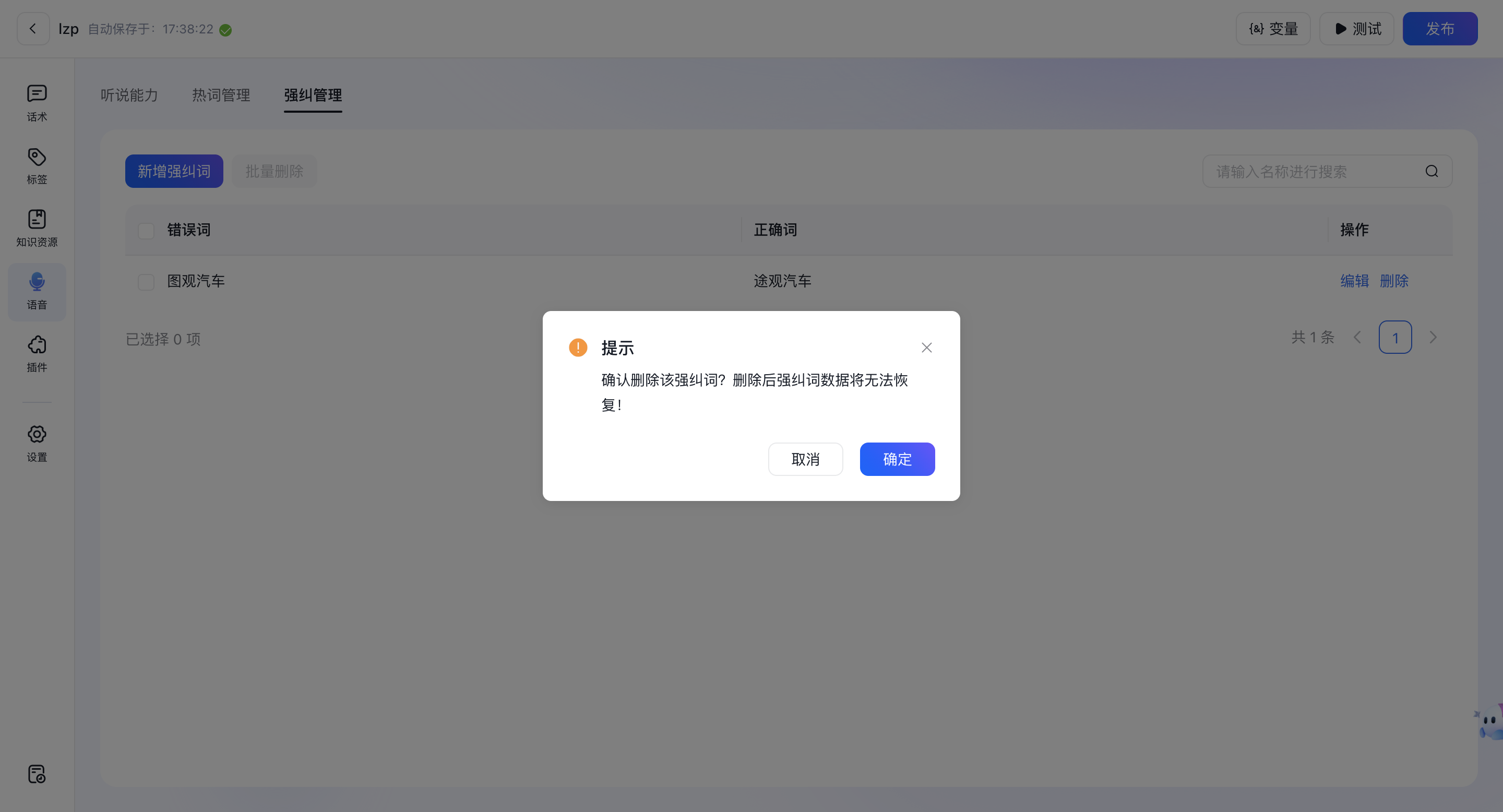
- 点击“删除”根据提示选择“确定”确认删除。
2、语音合成
语音合成(Text-to-Speech, TTS)是一种将文本转换为自然流畅语音的技术,通过算法模拟人类发音过程,使机器能够“朗读”文字内容
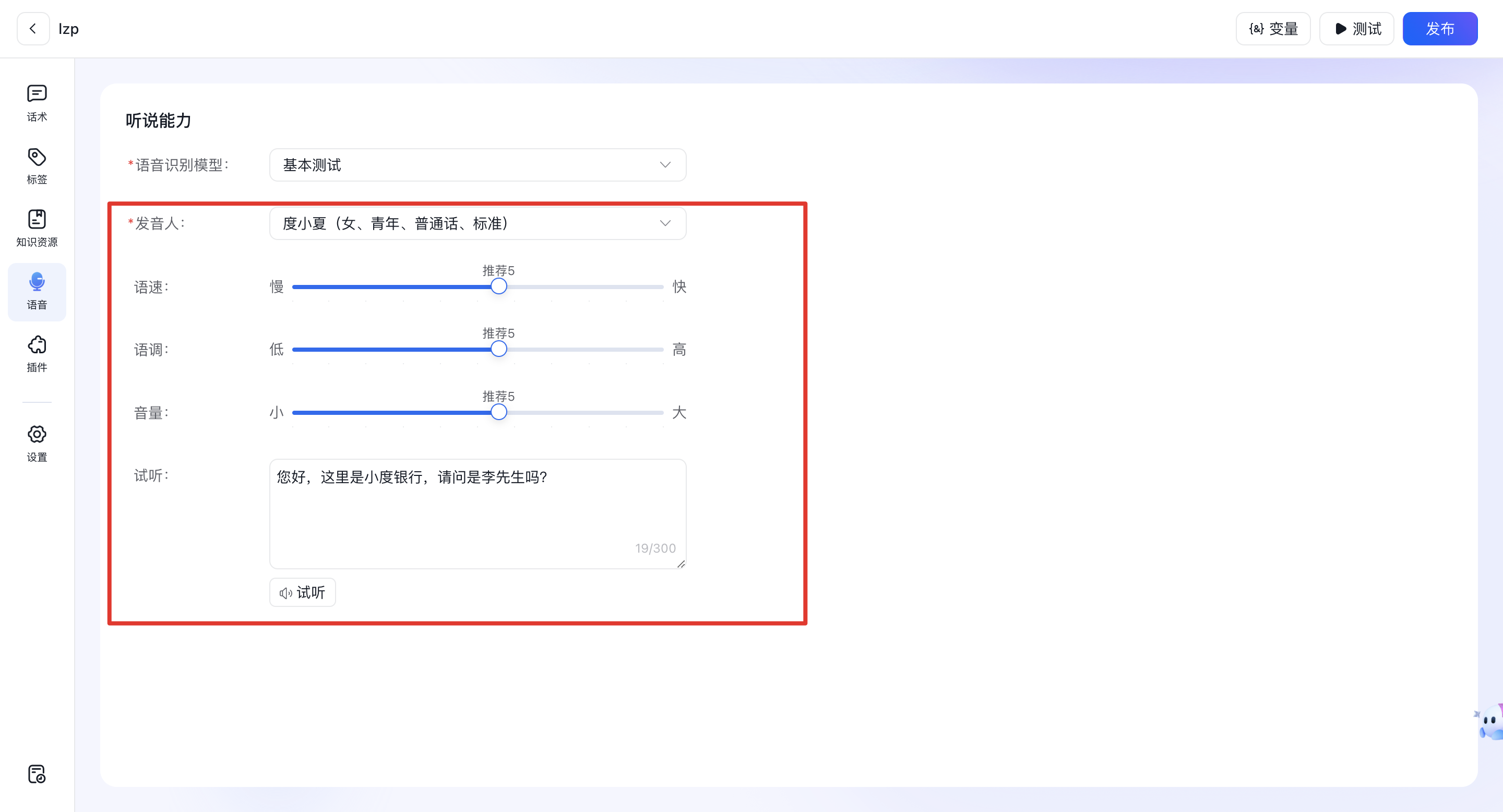
- 发音人:可以根据业务场景需求选择音色,可以参考具体音色。
- 语速、语调、音量:根据实际业务场景可以修改音色的语速、音量、语调。
- 试听:当语音参数配置完成后,可以自定义输入一些文字进行效果测试。
评价此篇文章