
AIHC-Daft算子开发使用指南
更新时间:2026-06-15
数据处理算子可使用百舸提供的 aihc-daft 包进行开发。aihc-daft 是百度 AI 异构计算平台(AIHC)推出的多模态 AI 数据处理框架,基于 Daft 构建,提供开箱即用的数据处理算子库,支持单机多核到多机分布式的弹性扩展,面向 AI 训练数据生产场景。
Daft 核心特性
- 弹性分布式执行。支持单机多核(Native Runner)与多机集群(Ray Runner)两种执行模式,业务代码无需修改,一行配置即可从单机无缝扩展至百节点集群,满足从开发调试到 PB 级数据生产的全场景需求。
- 惰性求值与查询优化。 采用惰性执行模型,所有数据变换操作仅构建逻辑计划,在触发
collect()/show()/write_*()时统一优化执行,自动进行谓词下推、列裁剪等优化,减少不必要的 I/O 和计算开销。 -
丰富的数据格式支持。原生支持主流数据格式的读写,包括:
- 结构化数据:Parquet、CSV、JSON、SQL 数据库
- 数据湖格式:Delta Lake、Apache Iceberg、Apache Hudi、Lance
- AI 数据集:HuggingFace Hub 数据集
- 多媒体:视频帧序列、WARC 网页归档、MCAP 机器人传感器数据
- 多模态数据类型原生支持内置
Image、Video、Audio等多媒体数据类型,支持直接在 DataFrame 列中存储和处理图像、音视频数据,无需手动序列化。 - 灵活的 UDF(用户自定义函数)系统 提供完整的 UDF 开发框架,支持声明 CPU、GPU、内存等资源需求,框架自动完成任务调度与资源分配。支持批处理模式、并发控制、进程/线程隔离,满足 CPU 密集与 GPU 推理等不同场景。
- GPU 原生调度支持 UDF 可声明所需 GPU 资源(支持小数,如
num_gpus=0.5),框架与 Ray 协同完成 GPU 感知调度,天然适配深度学习推理、向量化等 GPU 密集型算子。 - SQL 查询支持支持直接使用 SQL 语法对 DataFrame 进行查询(
daft.sql()),降低数据处理门槛,兼容熟悉 SQL 的用户习惯。 - 多种存储后端统一接入通过统一的存储抽象层,支持本地文件系统、百度对象存储(BOS)、AWS S3、HTTP(S) 等多种存储后端,使用相同 API 访问不同存储,路径前缀自动路由。
- DataFrame API 简洁直观提供类 Pandas 的 DataFrame 操作接口,支持
select、filter、groupby、join、sort、limit等常用操作,以及窗口函数(Window),学习成本低。 - 数据湖 Catalog 集成支持与 Apache Iceberg、Apache Gravitino、Unity Catalog 等主流数据湖 Catalog 集成,实现数据治理、表版本管理与跨平台数据共享。
集成aihc-daft方式
你可以通过镜像或者 pip 包的方式,集成 aihc-daft。
- 镜像
Plain Text
1 ccr-registry.baidubce.com/aihc/aihc-daft-gpu:0.5.1-cu12.1-py3.11-ubuntu22.04镜像已经预置aihc-Daft 以及多模态算子相关的依赖以及运行环境,比如 Cuda、Conda、Ray 等,推荐直接使用
-
pip包离线安装
- Aihc-daft 尚未在pypi 仓库发布,用户需要下载 aihc-daft 的离线安装包。点击下载
- 执行以下命令安装
JSON
1pip install aihc_daft-0.5.1-cp310-abi3-manylinux_2_12_x86_64.whlaihc-daft内置算子示例
这里以图片哈希计算处理器算子为例
test_image_hash.py脚本如下:
Plain Text
1from __future__ import annotations
2
3import os
4import daft
5from daft import col
6
7from daft.aihc.common.udf import aihc_udf
8from daft.aihc.functions.image.image_hash import ImageHash
9
10if __name__ == "__main__":
11 if os.getenv("DAFT_RUNNER", "native") == "ray":
12 import ray
13 ray.init(dashboard_host="0.0.0.0", ignore_reinit_error=True)
14 daft.set_runner_ray()
15 daft.set_execution_config(actor_udf_ready_timeout=6000, min_cpu_per_task=0)
16
17 samples = {
18 "image": [
19 "file:///local/sample_1.jpg",
20 "file:///mnt/pfs/sample_2.jpg",
21 "file:///mnt/bos/sample_3.jpg",
22 ]
23 }
24
25 num_datasets = len(samples["image"])
26 ds = daft.from_pydict(samples).into_partitions(num_datasets) #强制分布式切分partitions
27 ds = ds.with_column(
28 "image_hash",
29 aihc_udf(
30 ImageHash,
31 construct_args={
32 "image_src_type": "image_url",
33 "method": "phash",
34 },
35 num_cpus=0.5,
36 batch_size=1,
37 concurrency=num_datasets, # 多个数据集并发执行
38 )(col("image")),
39 )
40 ds.show()分布式数据处理执行命令
Plain Text
1#使用DAFT_RUNNER=ray基于ray分布式执行
2DAFT_RUNNER=ray python test_image_hash.py
3
4#单机执行
5python test_image_hash.pyaihc-daft 基础参数说明
aihc_udf 参数说明
| 参数 | 说明 | 默认值 | 示例 |
|---|---|---|---|
operator |
算子类(必填) | — | ImageHash |
construct_args |
传给算子初始化的参数 | {} |
construct_args={ "image_src_type": "image_url", "method": "phash", } |
num_cpus |
每实例占用 CPU 核数 | None(由调度器自动分配) |
2 |
num_gpus |
每实例占用 GPU 卡数 | None(不使用 GPU) |
1 或 0.5 |
memory_bytes |
每实例内存上限(字节) | None(不限制) |
2 * 1024^3(2GB) |
batch_size |
每次处理的数据条数 | None(由框架自动决定) |
64 |
concurrency |
同时运行的实例数 | None(由框架自动决定) |
8 |
use_process |
是否使用进程隔离(CPU 密集时建议开启) | False(使用线程) |
True |
数据读写方式
支持本地文件/挂载目录文件/BOS/HTTP等多种方式:
Python
1 samples = {
2 "image": [
3 "file:///local/sample_1.jpg", #本地数据
4 "file:///mnt/pfs/sample_2.jpg", #pfs挂载点内数据
5 "file:///mnt/bos/sample_3.jpg", #bos挂载点内数据
6 "bos://bucket/path/sample_4.jpg" #bos直接抓取数据
7 "http://url/sample_5.jpg" #http抓取数据
8 ]
9 }若使用BOS直接抓取数据的方式, 需要在数据处理代码中注入BOS相关环境变量, 如下:
Python
1os.environ["BOS_ENDPOINT"] = "http://bj.bcebos.com" #endpoint
2os.environ["BOS_ACCESS_KEY_ID"] = ""
3os.environ["BOS_SECRET_ACCESS_KEY"] = ""
4os.environ["BOS_REGION"] = "bj"最佳实践
这里我们以具身数据格式转换为例,指导用户基于百舸平台的数据处理算子,通过开发机/分布式训练任务,实现 LerobotV2.1 数据集向 V3.0 版本的格式转换。准备工作
环境准备
- 这里我们可以使用开发机来开发调试代码,关于aihc-daft集成,你可以直接使用 aihc-daft 的镜像启动开发机,也可以使用自己的镜像启动,手动安装 aihc-daft 的包
-
数据准备
- 这里我们以huggingface中开源测试数据集lerobot/pusht/ 、dataset/lerobot/pusht2/和 lerobot/aloha_sim_insertion_human/ 为例
-
我们提供了打包的数据集,点击下载。 原始数据集分布为:
- dataset/lerobot/aloha_sim_insertion_human/
- dataset/lerobot/pusht/
- dataset/lerobot/pusht2/
算子开发
- 这里我们基于原始的TarUncompress算子,实现了递归目录下Tar 文件解压等能力。脚本如下:
Python
1import json
2import os
3import tarfile
4import daft
5from daft import col
6
7from daft.aihc.common.udf import aihc_udf
8from daft.aihc.functions.process.tar_extractor_udf import TarUncompress
9from daft.aihc.functions.process.tar_extractor_udf import discover_datasets
10from daft.aihc.functions.process.tar_extractor_udf import create_tasks_from_datasets
11
12TAR_EXTENSIONS = (".tar", ".tar.gz", ".tgz", ".tar.bz2", ".tbz2", ".tar.xz", ".txz", ".tar.zst")
13
14
15def is_tar_file(filepath: str) -> bool:
16 lower = filepath.lower()
17 if not any(lower.endswith(ext) for ext in TAR_EXTENSIONS):
18 return False
19 return tarfile.is_tarfile(filepath)
20
21
22def find_tar_files(directory: str) -> list[str]:
23 tar_files = []
24 for root, _dirs, files in os.walk(directory):
25 for f in files:
26 full = os.path.join(root, f)
27 if is_tar_file(full):
28 tar_files.append(full)
29 return tar_files
30
31
32def safe_members(tf: tarfile.TarFile) -> list[tarfile.TarInfo]:
33 return [m for m in tf.getmembers() if not m.name.startswith("/") and ".." not in m.name]
34
35
36def extract_recursive(tar_path: str, output_dir: str) -> list[str]:
37 all_extracted = []
38
39 # 第一次解压
40 with tarfile.open(tar_path) as tf:
41 members = safe_members(tf)
42 tf.extractall(path=output_dir, members=members)
43 all_extracted.extend([os.path.join(output_dir, m.name) for m in members])
44
45 # 持续扫描并解压新出现的 tar 文件
46 pending = find_tar_files(output_dir)
47 processed = set()
48
49 while pending:
50 current = pending.pop(0)
51 if current in processed:
52 continue
53 processed.add(current)
54
55 extract_dir = os.path.dirname(current)
56 with tarfile.open(current) as tf:
57 members = safe_members(tf)
58 tf.extractall(path=extract_dir, members=members)
59 all_extracted.extend([os.path.join(extract_dir, m.name) for m in members])
60
61 # 删除已解压的内层 tar 包(如需保留,注释掉下面这行)
62 # os.remove(current)
63
64 new_tars = find_tar_files(output_dir)
65 for t in new_tars:
66 if t not in processed and t not in pending:
67 pending.append(t)
68
69 return all_extracted
70
71
72class RecursiveTarUncompress(TarUncompress):
73 """递归解压多层嵌套 tar 包的 UDF。"""
74
75 def __call__(self, input_path, output_path):
76 input_list = input_path.to_pylist()
77 output_list = output_path.to_pylist()
78
79 results = []
80 for inp, outp in zip(input_list, output_list):
81 os.makedirs(outp, exist_ok=True)
82 all_files = extract_recursive(inp, outp)
83 # 返回 JSON 字符串,与父类 TarUncompress 的 __return_column_type__(String) 一致
84 results.append(json.dumps({
85 "status": "success",
86 "input": inp,
87 "output": outp,
88 "extracted_files": all_files,
89 "extracted_count": len(all_files),
90 }))
91 return results
92
93
94if __name__ == "__main__":
95 if os.getenv("DAFT_RUNNER", "native") == "ray":
96 import ray
97 ray.init(dashboard_host="0.0.0.0", ignore_reinit_error=True)
98 daft.set_runner_ray()
99 daft.set_execution_config(actor_udf_ready_timeout=6000, min_cpu_per_task=0)
100
101 base_path = "/mnt/pfs/xx" # 【用户需替换】实际存放tar包的目录
102
103 # 直接扫描 base_path 下的 tar 文件
104 tar_files = find_tar_files(base_path)
105 if not tar_files:
106 raise ValueError(f"未在 {base_path} 下发现任何 tar 文件,请检查路径")
107
108 # 去除所有 tar 后缀作为输出目录,如 test_dataset.tar.gz -> test_dataset
109 def strip_tar_ext(path: str) -> str:
110 while True:
111 base, ext = os.path.splitext(path)
112 if ext.lower() in (".gz", ".bz2", ".xz", ".zst", ".tar", ".tgz", ".tbz2", ".txz"):
113 path = base
114 else:
115 break
116 return path
117
118 tasks = {
119 "input_path": tar_files,
120 "output_path": [strip_tar_ext(t) for t in tar_files],
121 }
122
123 num_tasks = len(tasks["input_path"])
124 concurrency = max(num_tasks, 1)
125
126 ds = daft.from_pydict(tasks)
127 ds = ds.into_partitions(num_tasks)
128
129 ds = ds.with_column(
130 "result",
131 aihc_udf(
132 RecursiveTarUncompress,
133 construct_args={},
134 num_cpus=1,
135 num_gpus=0,
136 batch_size=1,
137 concurrency=concurrency,
138 use_process=True,
139 )(col("input_path"), col("output_path")),
140 )
141 ds.show()- 基于ConvertDatasetV21ToV30算子,将lerobotV2.1数据集格式 转换为 lerobotV3.0数据集格式,脚本如下:
Python
1import os
2import daft
3from daft import col
4
5from daft.aihc.common.udf import aihc_udf
6from daft.aihc.functions.embodied.convert_dataset_v21_to_v30_udf import ConvertDatasetV21ToV30
7
8if __name__ == "__main__":
9 if os.getenv("DAFT_RUNNER", "native") == "ray":
10 import ray
11 ray.init(dashboard_host="0.0.0.0", ignore_reinit_error=True)
12 daft.set_runner_ray()
13 daft.set_execution_config(actor_udf_ready_timeout=6000, min_cpu_per_task=0)
14
15 tasks = {
16 "input_repoid": [
17 "lerobot/aloha_sim_insertion_human/",
18 "lerobot/pusht/",
19 "lerobot/pusht2/"
20 ],
21 "input_path": ["/mnt/pfs/xx/test_dataset/dataset/"] * 3,
22 "output_path": ["/mnt/pfs/xx/lerobotv3"] * 3 # 【用户需替换】格式转换后的输出目录
23 }
24 num_datasets = len(tasks["input_repoid"])
25 ds = daft.from_pydict(tasks).into_partitions(num_datasets)
26
27 ds = ds.with_column(
28 "convert_result",
29 aihc_udf(
30 ConvertDatasetV21ToV30,
31 construct_args={
32 },
33 num_cpus=0.1,
34 batch_size=1,
35 concurrency=num_datasets,
36 use_process=True
37 )(col("input_repoid"), col("input_path"), col("output_path")),
38 )
39 ds.show()整体处理流程:
运行pipiline.py
Python
1import json
2import os
3import tarfile
4import daft
5from daft import col
6
7from daft.aihc.common.udf import aihc_udf
8from daft.aihc.functions.process.tar_extractor_udf import TarUncompress
9from daft.aihc.functions.embodied.convert_dataset_v21_to_v30_udf import ConvertDatasetV21ToV30
10
11# ====================== 直接复用 data_convert.py 全部代码 ======================
12TAR_EXTENSIONS = (".tar", ".tar.gz", ".tgz", ".tar.bz2", ".tbz2", ".tar.xz", ".txz", ".tar.zst")
13
14def is_tar_file(filepath: str) -> bool:
15 lower = filepath.lower()
16 if not any(lower.endswith(ext) for ext in TAR_EXTENSIONS):
17 return False
18 return tarfile.is_tarfile(filepath)
19
20def find_tar_files(directory: str) -> list[str]:
21 tar_files = []
22 for root, _dirs, files in os.walk(directory):
23 for f in files:
24 full = os.path.join(root, f)
25 if is_tar_file(full):
26 tar_files.append(full)
27 return tar_files
28
29def safe_members(tf: tarfile.TarFile) -> list[tarfile.TarInfo]:
30 return [m for m in tf.getmembers() if not m.name.startswith("/") and ".." not in m.name]
31
32def extract_recursive(tar_path: str, output_dir: str) -> list[str]:
33 all_extracted = []
34 with tarfile.open(tar_path) as tf:
35 members = safe_members(tf)
36 tf.extractall(path=output_dir, members=members)
37 all_extracted.extend([os.path.join(output_dir, m.name) for m in members])
38
39 pending = find_tar_files(output_dir)
40 processed = set()
41
42 while pending:
43 current = pending.pop(0)
44 if current in processed:
45 continue
46 processed.add(current)
47
48 extract_dir = os.path.dirname(current)
49 with tarfile.open(current) as tf:
50 members = safe_members(tf)
51 tf.extractall(path=extract_dir, members=members)
52 all_extracted.extend([os.path.join(extract_dir, m.name) for m in members])
53
54 new_tars = find_tar_files(output_dir)
55 for t in new_tars:
56 if t not in processed and t not in pending:
57 pending.append(t)
58
59 return all_extracted
60
61class RecursiveTarUncompress(TarUncompress):
62 """递归解压多层嵌套 tar 包的 UDF。"""
63 def __call__(self, input_path, output_path):
64 input_list = input_path.to_pylist()
65 output_list = output_path.to_pylist()
66 results = []
67 for inp, outp in zip(input_list, output_list):
68 os.makedirs(outp, exist_ok=True)
69 all_files = extract_recursive(inp, outp)
70 results.append(json.dumps({
71 "status": "success",
72 "input": inp,
73 "output": outp,
74 "extracted_files": all_files,
75 "extracted_count": len(all_files),
76 }))
77 return results
78
79# ====================== 主 pipeline 工作流 ======================
80if __name__ == "__main__":
81 # 统一环境初始化
82 if os.getenv("DAFT_RUNNER", "native") == "ray":
83 import ray
84 ray.init(dashboard_host="0.0.0.0", ignore_reinit_error=True)
85 daft.set_runner_ray()
86 daft.set_execution_config(actor_udf_ready_timeout=6000, min_cpu_per_task=0)
87
88 base_path = "/mnt/pfs/xx"
89 convert_output_root = "/mnt/pfs/xx/lerobotv3"
90
91 # ====================== 步骤1:执行解压(原 data_convert.py) ======================
92 print("=== 步骤1:开始递归解压 tar 文件 ===")
93 tar_files = find_tar_files(base_path)
94 if not tar_files:
95 raise ValueError(f"未在 {base_path} 下发现任何 tar 文件")
96
97 def strip_tar_ext(path: str) -> str:
98 while True:
99 base, ext = os.path.splitext(path)
100 if ext.lower() in (".gz", ".bz2", ".xz", ".zst", ".tar", ".tgz", ".tbz2", ".txz"):
101 path = base
102 else:
103 break
104 return path
105
106 tasks_extract = {
107 "input_path": tar_files,
108 "output_path": [strip_tar_ext(t) for t in tar_files],
109 }
110 num_tasks = len(tasks_extract["input_path"])
111 concurrency = max(num_tasks, 1)
112
113 ds = daft.from_pydict(tasks_extract)
114 ds = ds.into_partitions(num_tasks)
115
116 ds = ds.with_column(
117 "result",
118 aihc_udf(
119 RecursiveTarUncompress,
120 construct_args={},
121 num_cpus=1,
122 num_gpus=0,
123 batch_size=1,
124 concurrency=concurrency,
125 use_process=True,
126 )(col("input_path"), col("output_path")),
127 )
128 df_extract = ds.collect()
129 print("=== 解压完成 ===")
130
131 # ====================== 步骤2:执行 v21 → v30 转换(原 lerobotv21-30.py) ======================
132 print("=== 步骤2:开始格式转换 ===")
133 tasks_convert = {
134 "input_repoid": [
135 "lerobot/aloha_sim_insertion_human/",
136 "lerobot/pusht/",
137 "lerobot/pusht2/"
138 ],
139 "input_path": ["/mnt/pfs/xx/test_dataset/dataset/"] * 3,
140 "output_path": [convert_output_root] * 3
141 }
142 num_datasets = len(tasks_convert["input_repoid"])
143
144 ds_convert = daft.from_pydict(tasks_convert).into_partitions(num_datasets)
145
146 ds_convert = ds_convert.with_column(
147 "convert_result",
148 aihc_udf(
149 ConvertDatasetV21ToV30,
150 construct_args={},
151 num_cpus=0.1,
152 batch_size=1,
153 concurrency=num_datasets,
154 use_process=True
155 )(col("input_repoid"), col("input_path"), col("output_path")),
156 )
157 ds_convert.show()
158 print("=== 全部 pipeline 执行完成 ===")分布式数据处理
在分布式训练模块中,基于上述开发的算子代码,使用 Ray 计算引擎进行分布式处理数据。
也可以直接使用开发机进行单机的数据处理
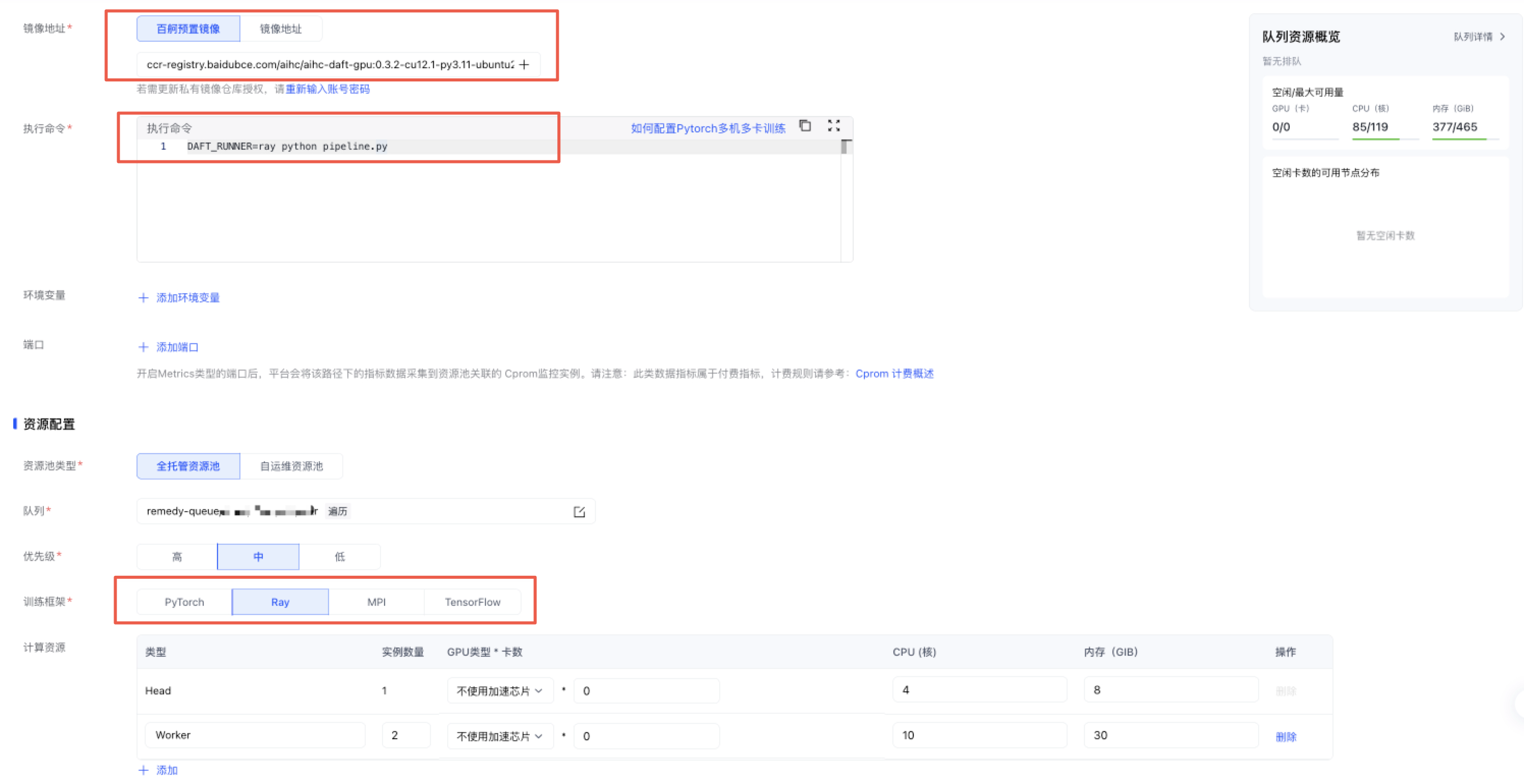
Rayjob的提交可参考 快速提交Ray任务,关键参数如下:
- 镜像地址:使用百舸预置镜像,选择aihc-daft预置镜像
- 执行命令:
DAFT_RUNNER=ray python /mnt/pfs/xx/pipeline.py,其中pipeline.py是上面开发的算子代码。 - 计算框架:选择 Ray
- 计算资源:可设置多个 worker 实例并行执行。在任务执行时,Daft + Ray 会自动调度、自动负载均衡、用满集群资源。
- 存储挂载:将源数据所在存储实例挂载到容器内
提交任务即可进行数据处理,可通过 submitter 节点的日志查询数据处理的进度
评价此篇文章