
基于百舸平台通过P800进行Qwen-2.5模型训练
AIAK-Training-LLM是百度智能云基于百度百舸·AI计算平台,面向大模型训练场景提供的最佳实践解决方案配套AI加速工具,帮助模型开发者高效完成大规模深度学习分布式训练,提升训练效率,相比开源 Megatron-LLM性能明显提升。关于AIAK-Training-LLM的使用说明,详见这里这里
这里我们以Qwen/Qwen2.5-72B-Instruct模型为示例,介绍如何使用AIAK-Training-LLM在P800上进行训练。
资源准备
算力资源
使用AIAK加速训练Qwen2.5-72B-Instruct,默认使用4台P800*8卡的节点
存储资源
为保证训练的性能,推荐使用并行文件存储PFS,以达到分布式加速训练效果。
开发机环境准备
创建开发机用于下载模型、数据集,并进行模型权重转换、数据集预处理等工作。
开发机创建:
在百度百舸.AI计算平台控制台,点击【开发机】-【创建实例】开始创建开发机并填写开发机配置信息:
-
基本信息
- 实例名称:输入您为开发机命名的名称,例如:P800-dev-test
- 资源池类型/资源池/队列:根据您的资源池类型选择已创建的资源池和队列
- 资源规格:预处理无需GPU资源,可以选择不使用加速芯片,同时最好保证内存资源不少于16GB以保证预处理脚本正常运行,此处推荐使用128核CPU与256GB以上内存保证预处理效率
-
环境配置
- 镜像地址:可以从训练任务处,通过模板创建获取,目前镜像地址为:registry.baidubce.com/aihc-aiak/aiak-training-llm:main_p800_v1.2_new
- 云磁盘:推荐预留100GiB保证开发机正常运行
- 启动命令:用于填写开发机启动自动运行命令,此处暂时留空
- 环境变量:一般用于配合启动命令使用,此处暂时留空
- 存储挂载:用于挂载云存储资源(PFS/BOS/CFS等),此处选择存储类型为PFS的资源,默认带出存储配置区,填写源路径与挂载路径,例如:源路径:/P800/test,挂载路径:/mnt/pfs/P800/test(后续相关存储路径与此高度相关)
-
访问配置&高级配置
- 可以使用默认配置,此处不做修改
完成后点击确定,即可完成开发机创建。
BOS工具验证:
在开发机中,已经预置了BOS下载工具,输入以下命令以验证下载工具是否安装:
1bcecmd产生以下输出则为可用:
1usage: bcecmd [--help] [-configure ['''] [--debug] [--conf-path CONF-PATH] [-multiupload-infos-path MULTIUPLOAD-INFOS-PATH] [-version]反之,执行以下命令:
1wget https://doc.bce.baidu.com/bos-optimization/linux-bcecmd-0.5.9.zip #下载
2unzip linux-bcecmd-0.5.9.zip #解压
3ln linux-bcecmd-0.5.9/bcecmd /usr/sbin/ #设置为全局使用模型&数据集准备
模型准备:
(1) 模型下载
huggingface地址:https://huggingface.co/Qwen/Qwen2.5-72B/tree/main
BOS地址:bos:/aihc-models-bj/Qwen/Qwen2.5-72B/
BOS参考下载指令(此处的第二个参数参考开发机创建-环境配置-存储挂载-挂载路径):
1bcecmd bos sync bos:/aihc-models-bj/Qwen/Qwen2.5-72B/ /mnt/pfs/P800/test/Qwen-2.5-72B-model/(2) 模型CKPT预处理
进入开发机/workspace/AIAK-Training-LLM/examples/qwen2.5/checkpoint_convert/convert_qwen2.5_72b_hf_to_mcore.sh目录可以找到模型权重转换脚本,调整模型权重位置与数据集输入输出位置后即可运行:
1#! /bin/bash
2
3AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
4MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
5CONVERT_CHECKPOINT_PATH="$AIAK_TRAINING_PATH/tools/convert_checkpoint"
6
7LOAD=/mnt/pfs/P800/test/model/qwen-2.5-72b
8SAVE=/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8
9
10python $CONVERT_CHECKPOINT_PATH/model.py \
11 --load_platform=huggingface \
12 --save_platform=mcore \
13 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/qwen2.5-72b.json \
14 --tensor_model_parallel_size=4 \
15 --pipeline_model_parallel_size=8 \
16 --megatron_path=$MEGATRON_PATH \
17 --load_ckpt_path=$LOAD \
18 --save_ckpt_path=$SAVE \
19 --no_load_optim \
20 --no_save_optim \
21 --safetensors运行结束后显示INFO:root:Finished convert checkpoint huggingface -> mcore即为转换成功
(3) 模型CKPT结果
输出结果应在SAVE文件夹下应有一个release文件夹,一个latest_checkpointed_iteration.txt文本文档。
数据集准备:
(1) 数据集下载
百舸平台已经在对象存储BOS中预置相关数据集,您可以从对应地域的BOS路径中下载数据,也可以从其他地方导入数据集。
百度公共数据集:
HuggingFace数据集:
https://huggingface.co/datasets/TigerResearch/tigerbot-alpaca-zh-0.5m
数据集样例:
1{"instruction": "将以下短文中的所有“is”动词改为“was”。", "input": "The cake is delicious and the pie is too. The ice cream is melting in the sun and the lemonade is refreshing.", "output": "The cake was delicious and the pie was too. The ice cream was melting in the sun and the lemonade was refreshing."}
2{"instruction": "分类以下三个国家的首都是哪个城市:", "input": "- 美国\n- 法国\n- 中国", "output": "- 美国:华盛顿特区\n- 法国:巴黎\n- 中国:北京"}
3{"instruction": "为以下数学公式提供英文翻译:", "input": "f(x) = sin(x) + cos(x)", "output": "f(x) equals sine of x plus cosine of x."}数据集样式(keys:instruction/input/output)

方法1:
开发机中通过wget工具下载:
1wget https://aihc-rdw-bj.bj.bcebos.com/huggingface.co/datasets/TigerResearch/tigerbot-alpaca-zh-0.5m/tigerbot-alpaca-zh-0.5m.json方法2:
开发机中命令行从HuggingFace下载:
1# 安装依赖库
2pip install -U huggingface_hub
3# 此处需要复制自己的huggingface网站授权
4hf auth login
5# 后边可以自己修改存储地址
6hf download TigerResearch/tigerbot-alpaca-zh-0.5m --repo-type=dataset --local-dir /方法3:
本地上传:
先通过web端点击下载符号直接下载相关模型,之后在开发机指定目录进行上传。
(2) 数据集预处理
进入/workspace/AIAK-Training-LLM/examples/qwen2.5/目录可以找到数据集预处理脚本,调整模型权重位置与数据集输入输出位置后即可运行,
1# 如果遇到依赖环境报错可尝试执行如下代码切换到最新python&cuda环境
2source /root/miniconda/etc/profile.d/conda.sh && conda activate python310_torch25_cudaPretrain预处理:
1#!/bin/bash
2
3MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
4AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
5
6TOKENIZER_PATH=${TOKENIZER_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b"}
7
8input_data=/mnt/pfs/P800/test/datasets/hf-dataset/tigerbot-alpaca-zh-0.5m.json
9output_prefix=/mnt/pfs/P800/test/datasets/hf-dataset/output/pretrain
10
11PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
12 python ${AIAK_TRAINING_PATH}/tools/data_preprocess/preprocess_pretrain_data.py \
13 --input ${input_data} \
14 --output-prefix ${output_prefix} \
15 --tokenizer-type HFTokenizer \
16 --hf-tokenizer-path $TOKENIZER_PATH \
17 --json-keys instruction input output \
18 --workers 50 \
19 --append-eod需注意:请提前将第18行--json-keys后内容改成数据集key值,例如:数据集单条为以下情况
1{"instruction": "将以下短文中的所有“is”动词改为“was”。", "input": "The cake is delicious and the pie is too. The ice cream is melting in the sun and the lemonade is refreshing.", "output": "The cake was delicious and the pie was too. The ice cream was melting in the sun and the lemonade was refreshing."}则第十八行为:
1 --json-keys instruction input output \如果出现Killed终止,请适量提升开发机内存量(>= 16GB)
训练
SFT:
在百度百舸.AI计算平台控制台,点击【分布式训练】-【创建任务】开始创建训练任务并填写训练任务配置信息:
-
基本信息
- 任务名称:输入您为本次任务命名的名称,例如:P800-SFT-test
- 可见范围:队列哪可见/仅创建人可见
-
创建方式:【基于开源模型训练模版创建】
- 模型:【qwen2.5】-> 【qwen2.5-72b】
- 芯片类型:昆仑芯
- 训练模版:AIAK加速版
- 训练模式:选择【SFT】
- 训练方法:全量更新
-
资源配置(先配置此项)
- 资源池类型/资源池/队列:根据您的资源池类型选择P800资源所在的资源池和队列
- 优先级:默认为高,无需修改
- 训练框架:PyTorch,无需修改
- 资源配额:请确保实例数为4,GPU为KUNLUNXIN-P800 * 8,CPU与内存在可配置条件下越大越好。
- 共享内存:100GiB
- 数据集挂载:本示例中为空,具体用挂载用法与存储挂载类似
- 存储挂载:此处与开发机创建配置保持一致:源路径:/P800/test,挂载路径:/mnt/pfs/P800/test
-
环境信息
- 镜像地址:由基本信息自动带出无需修改
- 执行命令:需要自行配置数据集路径,Tokenizer路径,Checkpoint加载/保存路径,可通过环境变量注入或直接替换执行命令代码进行修改,例如(替换21-24行):
1DATA_PATH=${DATA_PATH:-"/mnt/pfs/P800/test/datasets/hf-dataset/tigerbot-alpaca-zh-0.5m.json"}
2TOKENIZER_PATH=${TOKENIZER_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b"}
3CHECKPOINT_LOAD_PATH=${CHECKPOINT_LOAD_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8"}
4CHECKPOINT_SAVE_PATH=${CHECKPOINT_SAVE_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8_trained"}-
监控信息
- Tensorboard:打开,并选择PFS,将配置源路径/P800/test加入默认源路径之前,后续此路径会自动注入执行命令中
- 其余容错与诊断,监控信息可选择性打开。
点击确定,即可开始训练任务,此数据集的SFT任务在4*8卡环境下大约为2小时。
Pretrain:
在百度百舸.AI计算平台控制台,点击【分布式训练】-【创建任务】开始创建训练任务并填写训练任务配置信息:
-
基本信息
- 任务名称:输入您为本次任务命名的名称,例如:P800-Pretrain-test
- 可见范围:队列哪可见/仅创建人可见
-
创建方式:【基于开源模型训练模版创建】
- 模型:【qwen2.5】-> 【qwen2.5-72b】
- 芯片类型:昆仑芯
- 训练模版:AIAK加速版
- 训练模式:选择【Pretrain】
- 训练方法:全量更新
-
资源配置(先配置此项)
- 资源池类型/资源池/队列:根据您的资源池类型选择P800资源所在的资源池和队列
- 优先级:默认为高,无需修改
- 训练框架:PyTorch,无需修改
- 资源配额:请确保实例数为4,GPU为KUNLUNXIN-P800 * 8,CPU与内存在可配置条件下越大越好。
- 共享内存:100GiB
- 数据集挂载:本示例中为空,具体用挂载用法与存储挂载类似
- 存储挂载:此处与开发机创建配置保持一致:源路径:/P800/test,挂载路径:/mnt/pfs/P800/test
-
环境信息
- 镜像地址:由基本信息自动带出无需修改
- 执行命令:需要自行配置数据集路径,Tokenizer路径,Checkpoint加载/保存路径,可通过环境变量注入或直接替换执行命令代码进行修改,例如(替换21-24行):
1DATA_PATH=${DATA_PATH:-"/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_output_document"}
2TOKENIZER_PATH=${TOKENIZER_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b"}
3CHECKPOINT_LOAD_PATH=${CHECKPOINT_LOAD_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8"}
4CHECKPOINT_SAVE_PATH=${CHECKPOINT_SAVE_PATH:-"/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8/pretrain"}注意:此处的DATA_PATH为预处理后的文件前缀,例如预处理后生成四个文件分别为:
1/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_output_document.idx
2/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_output_document.bin
3/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_instruction_document.bin
4/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_input_document.bin则此处DATA_PATH填入地址应为idx文件不包含后缀的地址,为:
1/mnt/pfs/P800/test/datasets/hf-dataset/pretrain/pile-qwen_output_document-
监控信息
- Tensorboard:打开,并选择PFS,将配置源路径/P800/test加入默认源路径之前,后续此路径会自动注入执行命令中
- 其余容错与诊断,监控信息可选择性打开。
点击确定,即可开始训练任务,此数据集的Pretrain任务在4*8卡环境下大约为14小时。
Tensorborad:
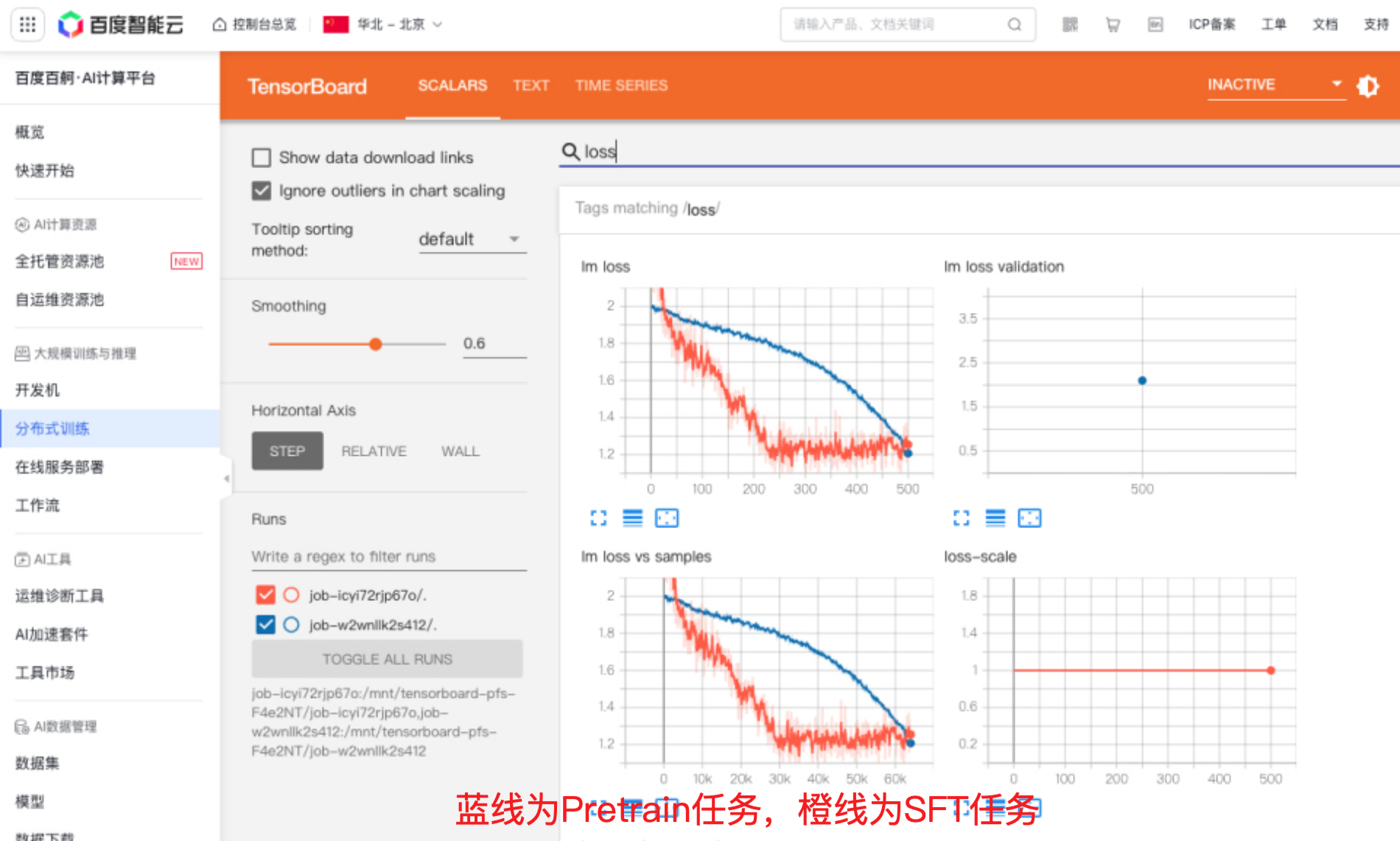
在百度百舸.AI计算平台控制台,点击【分布式训练】,多选需要查看Tensorboard的任务,点击【对比Tensorboard】即可查看对比各任务的Tensorboard,此处为本次SFT与Pretrain任务的对比图:
权重转换
在开发机使用如下脚本进行权重转换,将mcore格式训练结果转换为hf格式用于后续部署工作:
1#! /bin/bash
2
3AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
4MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
5CONVERT_CHECKPOINT_PATH="$AIAK_TRAINING_PATH/tools/convert_checkpoint"
6
7LOAD=/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8_trained/iter_0000500
8SAVE=/mnt/pfs/P800/test/model/qwen-2.5-72b/Qwen2.5_72B_mcore_tp4pp8_trained/Qwen2.5-72B-Instruct_saved_hf/
9
10
11python $CONVERT_CHECKPOINT_PATH/model.py \
12 --load_platform=mcore \
13 --save_platform=huggingface \
14 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/qwen2.5-72b.json \
15 --tensor_model_parallel_size=4 \
16 --pipeline_model_parallel_size=8 \
17 --megatron_path=$MEGATRON_PATH \
18 --load_ckpt_path=$LOAD \
19 --save_ckpt_path=$SAVE \
20 --no_load_optim \
21 --no_save_optim \
22 --safetensors注意:LOAD地址为训练结果最后一轮迭代目录(mp_rank目录的父目录),本示例最终训练轮次为500,因此LOAD文件前缀为iter_0000500
至此,输出的文件即为可直接运行的HuggingFace格式文件,可以进行后续服务部署操作。
评价此篇文章