
训练容错
更新时间:2026-01-26
背景信息
在大模型的训练场景中,大多数是多机多卡、结合多种并行策略的分布式训练,训练规模大/时间长。
在训练过程中,可能会出现由于基础设施环境的偶发异常,导致训练业务的中断。为了保障大规模分布式训练任务稳定运行,百舸AI计算平台提供了任务自动容错的能力,支持对训练任务进行异常感知、容错判断以及自动恢复。
功能说明
为了保障大规模分布式训练任务的稳定运行,百舸提供了容错监控、诊断定位和自动恢复的能力。
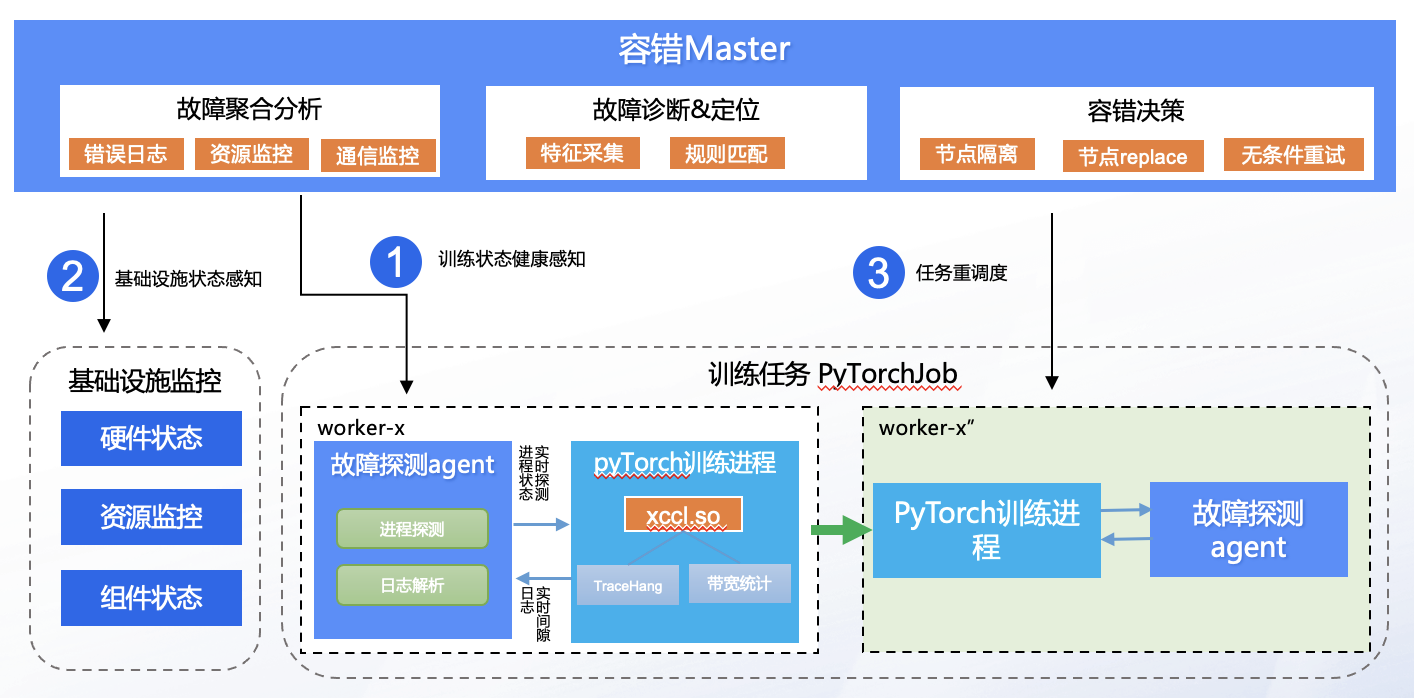
百舸容错架构由故障探测Agent和中心化的Master(资源池维度)组成:
- 故障探测Agent作为sidecar运行在客户业务Pod内,与训练进程完全独立,用于探测训练进程;
- 中心化的Master组件汇聚故障探测Agent的探测信息,从任务全局的视角去诊断、定位异常,最终做出相应的决策来使任务能够快速从异常中恢复。
目前百舸训练容错可以覆盖多类场景的故障感知定位&自动恢复能力:
- 训练进程报错异常退出
- 训练心跳失联
- NCCL/CUDA系统报错日志
- Pod被误删除/驱逐
- 训练进程hang
使用说明
使用限制
- 仅支持 Pytorch 训练框架
- 训练任务的 restartPolicy 需配置为 Never
使用前提
- 资源池已经开启 自动故障隔离能力。
-
资源池已经安装百度云 CCE Deep Learning Frameworks Operator 组件和 CCE AI Job Scheduler 组件
- CCE Deep Learning Frameworks Operator:主流深度学习框架 operator 组件,要求组件版本>=1.6.10
- CCE AI Job Scheduler :任务调度组件,支持调度管理各种AI任务,要求组件版本 >=1.7.7
百舸资源池已经默认安装以上组件,无需手动安装。
提交任务&开启容错
通过百舸控制台提交任务
在百舸控制台创建任务>容错&诊断,开启容错。示例如下:

高级配置说明
| 配置项 | 说明 |
|---|---|
| 任务hang检测 | 是否开启任务运行时的Hang异常检测,如果所有实例的Stdout和Stderr日志在指定时间内没有更新,初步判断任务hang住,并在任务事件中记录。您可以配置任务hang的告警 |
| 自定义训练异常 | 此功能适用于用户自定义训练异常,进行容错的场景。当训练进程出现自定义的异常时,您可以通过在训练日志中打印相关关键字,如"Loss nan"、"connect timeout"等。平台在训练实例的日志中匹配到预设日志关键字时(精确匹配),系统将启动训练容错。 注意:请务必合理设置,以避免任务被频繁容错重启。 |
| 无条件重试 | 任务在未检测到节点故障的场景下失败,平台提供开启无条件重试能力,尝试通过重调度任务进行容错恢复。您可以设置重试次数,来指定任务每次失败后尝试重试的次数(最大可设置为3次)。 |
| Repalce容错模式 | 百舸提供的智能容错能力,容错时仅销毁并重调度故障的Pod,正常Pod不受影响,减少任务重启恢复时长。 1. 开启Replace容错模式,百舸会尝试替换训练镜像中elastic agent ,将任务会切换为c10d 模式。 2. 开启要求:Pytorch 版本 >= 2.0.0,Python 版本 >= 3.8.0 3. 兼容性检查:开启 Replace 容错模式后,系统会自动检测 PyTorch和 Python 版本。若符合要求,则启用 Replace容错模式;否则自动使用默认容错模式。 4. 限制:如任务master0实例故障,则Replace容错模式不生效,自动退化为默认容错模式 |
通过CLI提交任务&开启容错
Plain Text
1aihc job submit --pool cce-**** \
2 --name test-pytorch \
3 --priority high \
4 --script-file /root/file.txt \
5 --image registry.baidubce.com/aihc-aiak/aiak-megatron:ubuntu20.04-cu11.8-torch1.14.0-py38_v1.2.7.12_release \
6 --label key=value \
7 --gpu baidu.com/a100_80g_cgpu=8 \
8 --env CUDA_DEVICE_MAX_CONNECTIONS=1 \
9 --env faulttolerance=true \ # 开启容错
10 --ds-type pfs \
11 --ds-name pfs-**** \
12 --ds-mountpath /mnt/cluster容错监控
容错通知
在创建任务 > 高级配置 > 告警的选项中,配置任务容错告警通知,支持通过邮件、短信、电话、钉钉、企业微信、飞书等机器人 Webhook 地址等通知方式,可参考: 配置训练任务的消息通知
容错事件
训练任务开启自动容错后,当任务异常触发容错判断时,会在任务层面生成容错的事件记录,记录容错发生的时间以及原因。
用户可以通过 百舸控制台 > 训练任务 > 任务事件 查询详细信息
评价此篇文章