
BCCL:百度自研高性能集合通信库
更新时间:2025-11-24
BCCL(Baidu Collective Communication Library) 是百度智能云推出的一款面向大模型训练场景优化的集合通信库。基于开源的 NCCL 进行了功能扩展和能力增强,针对大模型训练场景在可观测性、故障诊断、稳定性等方面进行优化,进一步提升集合通信库的可运维能力。本文为您介绍BCCL的主要特性和使用方法。
BCCL增强的特性
- 支持集合通信带宽实时统计功能,为故障诊断排除、训练性能调优等提供数据支撑。
- 支持集合通信 hang 时故障诊断能力,快速进行任务的异常检测。
- 网络故障容错能力增强,针对于偶发性异常故障场景(如单端口的偶发updown),增加相应重试重传超次机制,提升训练任务的健壮性。
使用BCCL
为了便于用户快捷使用BCCL,百舸平台支持用户在创建训练任务时,一键注入BCCL。
使用说明
- 仅支持多机的分布式训练任务开启
- 当启用此能力后,平台会对训练镜像OS和BCCL的版本进行兼容性验证。如版本兼容验证通过,会在任务训练中自动安装并使用BCCL通信库;否则不做处理,使用训练镜像中指定的通信库。您可以在训练任务事件或任务详情页面,获取BCCL是否成功安装
使用步骤
- 登录百舸AI计算平台AIHC控制台。
- 进入分布式训练列表页面,点击创建任务。
- 在 创建训练任务> BCCL通信库模块,开启使用BCCL通信库即可

支持通过open api开启,详见:创建训练任务
推荐环境变量配置
| 环境变量 | 变量说明 |
|---|---|
| NCCL_DEBUG=INFO | NCCL 日志级别。推荐 INFO |
| NCCL_DEBUG_SUBSYS=INIT,ENV,GRAPH | NCCL 日志子系统配置 |
| NCCL_DEBUG_FILE=path/to/nccl.%h.%p | NCCL 默认日志路径 |
| BCCL_ERROR_FILE=path/to/err.nccl.%h.%p | 对 NCCL ERROR 日志重定向到新路径,以便快速检索分析 |
| BCCL_IB_CONNECT_RETRY_CNT=15 | 增强任务初始化时网络连接容错能力。推荐取值:10 ~ 20 |
| BCCL_BUS_BW_CALCULATE_MODE=None/Verbose/Agg | 带宽统计功能开关:None 表示关闭带宽统计功能 Verbose 表示打印带宽统计详细日志。每个集合通信操作对应一行日志 Agg 表示打印带宽统计聚合日志。配合 BCCL_BUS_BW_CALCULATE_AGG_INTERVAL 使用 default:None |
| BCCL_BUS_BW_CALCULATE_AGG_INTERVAL=15 | 带宽统计聚合功能 interval 表示统计 interval 时间内的集合通信带宽情况 default: 15s |
| BCCL_PROFILING_FILE=path/to/profiling.nccl.%h.%p | 不配置该环境变量时,带宽统计日志默认打印到 stdout |
| BCCL_TRACE_HANG_ENABLE=1 | - TraceHang 功能开关:任务 hang 时,通过下述方法触发 traceHang 日志信息打印:find /var/run/ -type s -name "bcclsocket*" -exec sh -c 'echo "TraceHang" | nc -U {}' \; - default value:0 |
测试工具
bccl_perf 是基于 nccl-tests 扩展的集合通信测试工具,提供更丰富的测试语义。
| 选项名称 | 是否需要参数 | 选项说明 |
|---|---|---|
| -O <collective_type> | 是 | 指定需测试的通信操作,如allReduce、allGather、reduce、broadcast、reduceScatter、alltoall、sendRecv、gather、scatter |
| --split_mode | 否 | 拆分多通信组测试。默认不开启 |
| --split_step | 是 | 多通信组拆分策略,表明同一通信组 gpu rank 步长,默认为 1。例如,step=8 表示 gpu rank 0/8/16... 为一个通信组,gpu rank 1/9/17... 为一个通信组,以此类推 |
| -b |
是 | 测试所用最小 message size,与 nccl-tests 保持一致 |
| -e |
是 | 测试所用最大 message size,与 nccl-tests 保持一致 |
| -i |
是 | 最小到最大 message size 增长步长,与 nccl-tests 保持一致 |
| -f |
是 | 最小到最大message size增长的步长因子(倍数),与 nccl-tests 保持一致 |
| -n |
是 | 测试迭代的次数,与 nccl-tests 保持一致 |
| -w <warmup_iters> | 是 | warmup 迭代次数,与 nccl-tests 保持一致 |
| -t |
是 | 每个进程起的线程数,与 nccl-tests 保持一致 |
| -g |
是 | 每个线程管理的 gpu 数,与 nccl-tests 保持一致 |
| -z |
是 | 阻塞 NCCL 集合通信,确保通信组所有进程均完成集合通信操作,与 nccl-tests 保持一致 |
集合通信带宽统计
百舸平台支持实时集合通信带宽统计的功能,可以在训练过程中对集合通信性能进行实时观测,准确地展示集合通信在不同阶段的性能表现,为故障诊断排除、训练性能调优等提供数据支撑。
百舸平台已经默认集成集合通信带宽的能力,详见:训练集合通信带宽监控。
hang诊断(TraceHang)
在大规模分布式训练中,训练任务可能会因为硬件/软件等原因而出现进程挂起(Hang)的情况。此类问题的排查难点在于,无法从训练进程状态、日志上获取有效的诊断信息,且该场景一般不会立刻发生,任务可以正常启动并训练,但是在训练超过一定时间后(可能是几个小时或者数天)突然 hang 住。排查时很难稳定复现该故障,导致排查难度进一步提高。
为了应对这一挑战,BCCL提供了近乎无损的方式实现训练hang场景的在线诊断,通过记录集合通信内部的通信状态,综合分析判断是否有节点出现了问题。
使用说明
- traceHang 开启后会额外占用约 2MB 的GPU 显存,这部分显存以统一内存(unified memory)进行分配,训练任务将显存打满时,不建议开启 traaceHang。如果训练任务将 GPU 显存打满,traceHang 在访问统一内存时,会因统一内存页无法调入 GPU 显存,出现非法内存访问,即 "CUDA error: an illegal memory access was encountered"
- traceHang 开启后,请不要再启动其他占用 GPU 显存的任务。原因:模型训练时,大部分时间在计算,通信占比很小,traceHang 申请的统一内存只有在通信时使用。统一内存在不使用时,会被调出 GPU 显存,使用时再调入。如果后台启动其他 GPU 任务,可能会导致 GPU 显存打满,而显存打满后,统一内存页无法调入 GPU 显存,访问该内存空间时出现非法内存访问,即 "CUDA error: an illegal memory access was encountered"
使用步骤
目前百舸平台已经自动集成BCCL Tracehang的能力,下面将介绍使用步骤。
- 登录百舸AI计算平台AIHC控制台。
- 进入分布式训练列表页面,点击创建任务。
- 在 创建训练任务>容错&诊断模块,开启任务hang检测,您可以自行配置发起hang检测的阈值。

- 当训练任务达到您定义的hang的阈值,百舸平台会自动触发BCCL Tracehang。您可以在任务事件中,查询训练任务hang的诊断记录。
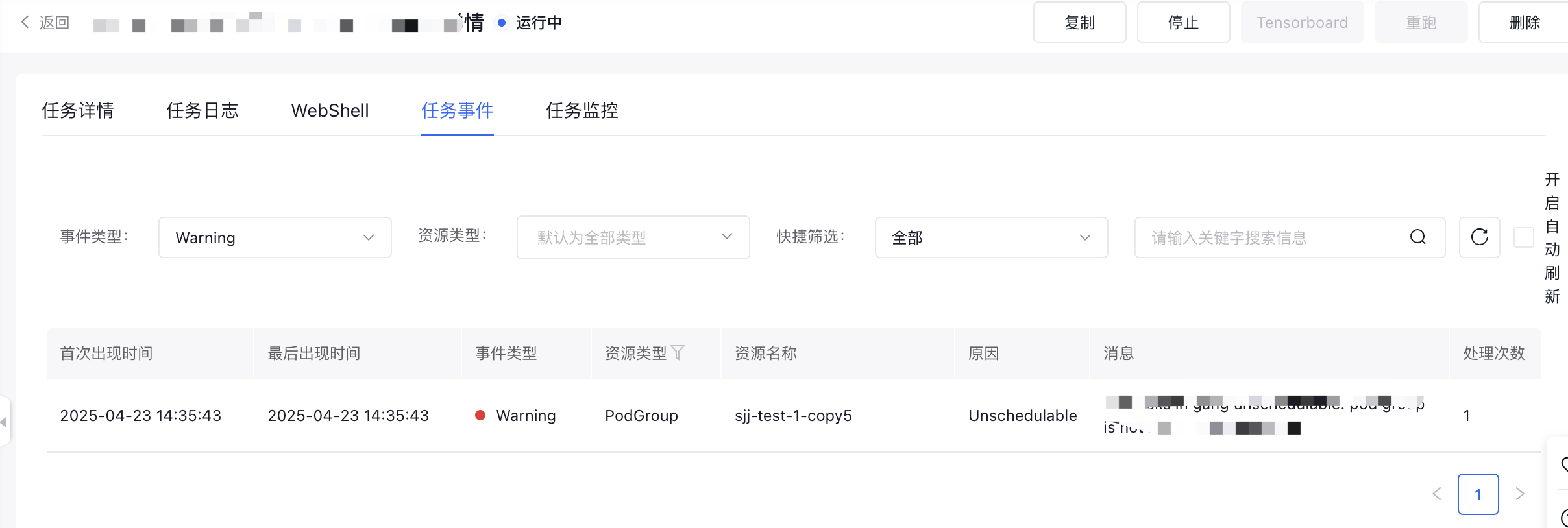
备注: 目前BCCL tracehang的能力,无论是否诊断出问题节点,当前阶段都不会主动中止您的训练任务。您需要手动进一步处理。
评价此篇文章