
LingBot-VA训推
https://technology.robbyant.com/lingbot-va lingbo-va——通用机器人控制的因果视频动作世界模型
模型概述
LingBot-VA 是一个自回归框架,它将视频世界建模与策略学习统一起来,联合学习未来帧预测和动作执行。该模型在长程操作、数据高效的后训练以及对新配置的鲁棒泛化方面展现出显著潜力。
它是一个多功能的全能型模型,在各种场景下都表现出色——从长程任务到高精度控制,再到可变形物体和关节物体的操作。
任务示例
| 类别 | 任务 |
|---|---|
| 长程任务 | 制作早餐、拆快递 |
| 高精度任务 | 插入试管、拾取螺丝 |
| 可变形物体 | 叠衣服、开抽屉 |
长程任务

高精度任务

可变形物体任务

性能结果

仿真基准测试
LingBot-VA 在两个仿真基准测试上进行了评估:RoboTwin 2.0 和 LIBERO。这些测试涵盖多种机器人构型的各种操作任务。结果表明,该模型相较于现有最先进的方法具有一致的改进。

RoboTwin 2.0
简单设置
| 视野 | 1 | 2 | 3 | 平均 |
|---|---|---|---|---|
| LingBot-VA | 50 | 65 | 80 | 100 |
| π₀ | 50 | 65 | 80 | 100 |
| π₀.₅ | 50 | 65 | 80 | 100 |
困难设置
| 视野 | 1 | 2 | 3 | 平均 |
|---|---|---|---|---|
| LingBot-VA | 50 | 65 | 80 | 100 |
| π₀ | 50 | 65 | 80 | 100 |
| π₀.₅ | 50 | 65 | 80 | 100 |
技术原理
LingBot-VA 是一个自回归扩散框架,在架构上将视觉动力学预测和动作推断统一在单个交错序列中。这使得机器人能够同时推理未来状态并执行精确的闭环控制。
大规模预训练
LingBot-VA 在大规模机器人视频动作数据集上进行预训练,学习丰富的视觉动力学,为理解物理世界的演变和在其中运行建立了坚实基础。

框架架构
该框架分为三个阶段运行:
- 自回归视频生成:根据当前观察和语言指令预测未来帧
- 逆动力学模型 (IDM):从预测的视频中解码出动作
- 闭环控制:执行后,用真实观察替换视频 KV-cache,将视频动作模型锚定在实际结果中
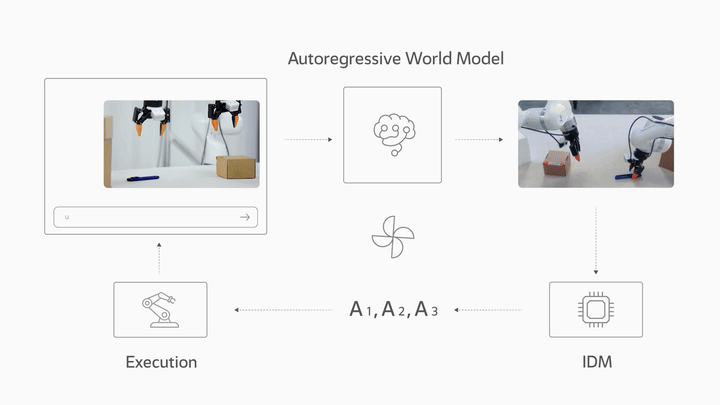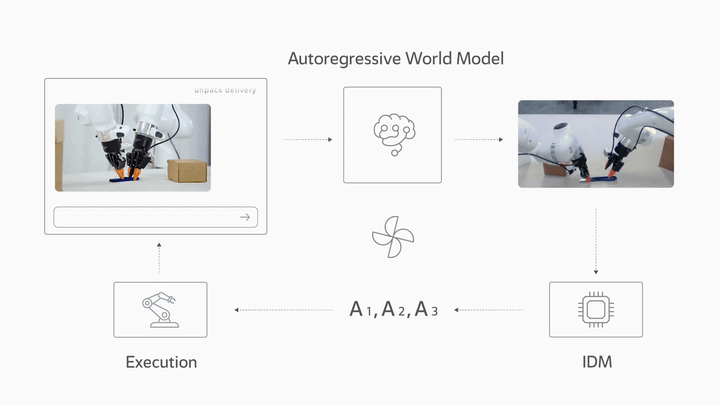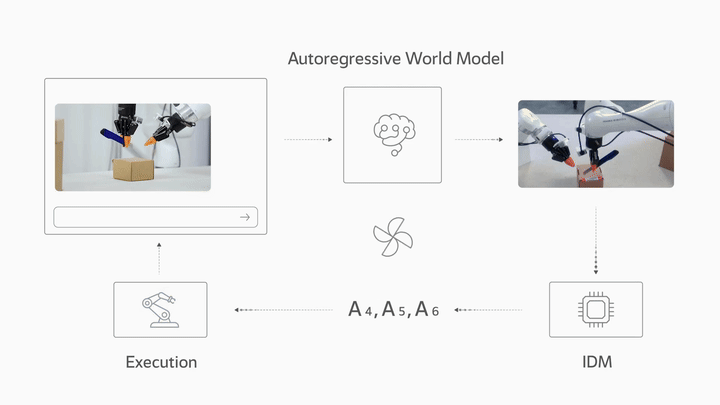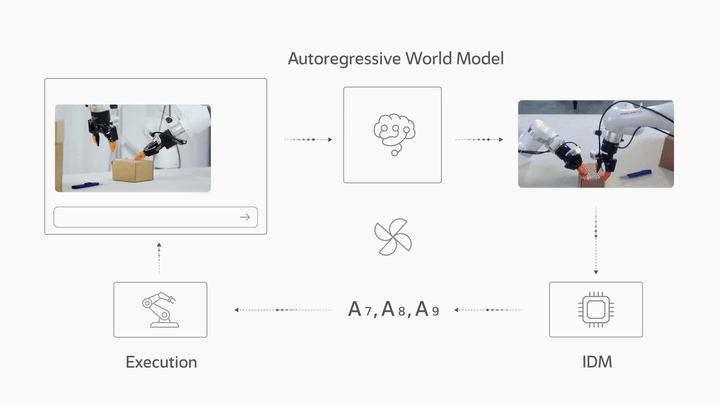
逆动力学模型
逆动力学模型 (IDM) 能够准确地从预测视频中解码动作,并在不同的环境和机器人构型中表现出良好的泛化能力。
预测与现实对比
预测的视频与机器人实际执行过程中观察到的视频高度一致。执行解码后的动作产生的真实观察与预测帧相符。
在百舸平台上快速开始
环境要求
- Python 3.10.16
- PyTorch 2.9.0
- CUDA 12.6
- GPU(推理:单卡 RTX 4090 即可;训练:需要 8 卡 A800)
镜像:ccr-registry.baidubce.com/aihc/lingbot-va:v0.2.3
数据准备
拷贝模型
1!set -e && \
2wget -q https://doc.bce.baidu.com/bos-optimization/linux-bcecmd-0.5.10.zip && \
3unzip -q linux-bcecmd-0.5.10.zip && \
4chmod +x linux-bcecmd-0.5.10/bcecmd && \
5mv linux-bcecmd-0.5.10/bcecmd /usr/local/bin/bcecmd && \
6rm -rf linux-bcecmd-0.5.10 linux-bcecmd-0.5.10.zip
7
8!bcecmd -v1bcecmd bos cp -r bos:/aihc-models-bj/robbyant/lingbot-va-base ~/workspace/lingbot-va-model
2
3cd ~/workspace/lingbot-va工作目录结构如下:

启动Python虚拟环境
1source /root/workspace/lingbot-va/.venv/bin/activate环境配置
运行 LingBot-VA 所需的环境已在镜像中完成配置
| 模式 | attn_mode 值 |
说明 |
|---|---|---|
| 训练 | "flex" |
训练必需 |
| 推理/评估 | "torch" 或 "flashattn" |
推理必需,flex 模式会报错 |
修改方法:编辑模型目录下的 transformer/config.json,找到 "attn_mode" 字段修改。
安装依赖
用户无需执行,仅做参考
1# 安装 uv
2pip install uv
3
4# 创建虚拟环境
5uv venv /root/workspace/lingbot-va/.venv
6source /root/workspace/lingbot-va/.venv/bin/activate
7
8# 安装 PyTorch 2.9.0
9uv pip install torch==2.9.0 torchvision==0.24.0 torchaudio==2.9.0 --index-url https://download.pytorch.org/whl/cu126
10
11# 安装依赖
12uv pip install diffusers==0.36.0 transformers==4.55.2 accelerate einops easydict tqdm \
13 'imageio[ffmpeg]' websockets msgpack opencv-python matplotlib ftfy safetensors Pillow
14
15
16# 安装 flash-attn(编译时间较长)
17uv pip install wheel
18uv pip install flash-attn --no-build-isolation推理测试
1. 修改模型配置
模型需要设置为推理模式:
1# 编辑 transformer config
2vim /root/workspace/lingbot-va-model/transformer/config.json
3
4# 将 "attn_mode": "flex" 改为 "attn_mode": "torch"2. 修改配置文件
更新配置文件中的模型路径:
1# 编辑配置
2vim /root/workspace/lingbot-va/wan_va/configs/va_demo_cfg.py
3
4# 修改模型路径
5wan22_pretrained_model_name_or_path = "/root/workspace/lingbot-va-model"3. 运行推理
1cd /root/workspace/lingbot-va
2source .venv/bin/activate
3
4# 单 GPU 推理
5python -m torch.distributed.run \
6 --nproc_per_node=1 \
7 --master_addr=127.0.0.1 \
8 --master_port=29501 \
9 -m wan_va.wan_va_server \
10 --config-name demo_i2av推理输出示例
1Loading checkpoint shards: 100%|██████████| 3/3 [00:00<00:00, 109.97it/s]
2USE I2AV mode
3FRAME START ID: 0
4 17%|█▌ | 1/6 [00:00<00:03, 1.37it/s]
5...
6100%|██████████| 6/6 [00:01<00:00, 4.28it/s]训练测试
配置wandb(可选)
如需使用 wandb 记录训练过程:
1export WANDB_API_KEY="your-key"
2export WANDB_BASE_URL="https://api.wandb.ai"
3export WANDB_TEAM_NAME="your-team"
4export WANDB_PROJECT="your-project"运行训练
1cd /root/workspace/lingbot-va
2source .venv/bin/activate
3
4# 8 GPU 训练
5python -m torch.distributed.run --nproc_per_node=8 --master_addr=127.0.0.1 --master_port=29501 -m wan_va.train --config-name robotwin_train训练配置参数
| 参数 | 说明 | 示例值 |
|---|---|---|
--config-name |
配置名称 | robotwin_train, demo_train |
NGPU |
GPU 数量 | 8 |
dataset_path |
训练数据路径 | /path/to/dataset |
batch_size |
Batch size | 1 |
num_steps |
训练步数 | 2000 |
目录结构
1/root/workspace/lingbot-va/
2├── .venv/ # 虚拟环境
3├── lingbot-va-model/ # 模型文件(约 23GB)
4│ ├── transformer/ # Transformer 模型
5│ ├── vae/ # VAE 模型
6│ ├── text_encoder/ # 文本编码器
7│ └── tokenizer/ # Tokenizer
8├── wan_va/ # 源代码
9│ ├── configs/ # 配置文件
10│ ├── modules/ # 模型模块
11│ ├── distributed/ # 分布式训练
12│ ├── dataset/ # 数据集处理
13│ └── train.py # 训练入口
14├── script/ # 训练脚本
15│ ├── run_va_posttrain.sh
16│ └── run_launch_va_server_sync.sh
17└── example/ # 示例数据常见问题
1. FSDP dtype 不一致错误
1AssertionError: FSDP expects uniform original parameter dtype but got {torch.float32, torch.bfloat16}解决:确保使用 PyTorch 2.9.0 和 CUDA 12.6
2. 推理提示 attn_mode 错误
1Unsupported attention mode: flex, only support torch and flashattn解决:将模型 transformer/config.json 中的 attn_mode 改为 "torch"或"flashattn"
3. 单 GPU 训练 OOM
训练需要约 8 卡 A800 才能运行,单卡会 OOM。推理可以在单卡 RTX 4090 上运行。
参考资料
评价此篇文章