
在线服务部署
更新时间:2026-05-19
百舸平台提供更灵活的部署方式,您可以将通过Docker构建的镜像使用此功能部署为推理服务,将模型文件或代码挂载到服务实例中。本文将为您介绍如何使用控制台部署及管理服务。
准备工作
- 登录百舸AI计算平台,在AI计算资源池中创建全托管资源池或自运维资源池,准备算力资源;
- 准备部署在线服务所需的信息:
- 服务镜像地址,例如:
registry-vpc.cn-shanghai.aliyuncs.com/xxx/yyy:zzz。 - 镜像的启动运行命令,例如:
/data/eas/ENV/bin/python /data/eas/app.py。 - 镜像中进程监听的网络端口号,例如:
8000。
标准服务
部署服务
- 登录百舸AI计算平台,点击左侧导航栏中的 在线服务部署 服务进入列表页面。
- 单击 部署服务 进入创建页面。
- 在创建页面填写相关参数,具体参数如下:
基础信息
| 参数名称 | 参数说明 |
|---|---|
| 服务名称 | 1.支持小写字母、数字以及 - 且开头必须是小写字母,结尾必须是小写字母或数字,长度1-50; 2.服务名称不可重复。 |
| 模型配置 | 平台支持部署自定义模型,需使用自定义镜像或平台提供的预置镜像,并自行上传模型权重;同时也支持主流开源模型权重,无需自行下载模型权重,支持vLLM、SGLang、自研AIAK加速推理引擎,并针对不同的模型提供单机、分布式、PD分离多种部署模版,提升部署效率。 |
资源配置
| 参数名称 | 参数说明 |
|---|---|
| 资源池类型 | 选择在线服务需要部署到的资源池 自运维资源池:自运维资源池,需要先创建资源池购买用于AI推理的计算资源 全托管资源池:免运维资源池,您无需运维和管理资源池和算力资源,由平台保障资源池稳定性 |
| 资源规格 | 选择部署服务所需的加速芯片类型和卡数、CPU、内存;加速芯片类型选择 “不使用加速芯片”即部署CPU服务。 |
| 分布式推理 | 模型参数量较大无法单台机器推理时,可以选择分布式推理将单实例部署在多台机器。 单实例Pod数即每个副本中的Pod数量,默认为2,可按需修改。 |
| RDMA | 分布式推理或PD分离部署时,建议开启RDMA优化跨节点之间的数据传输。注意:算力资源需支持RDMA,否则可能会调度失败。 |
| 优先级 | 支持设置在线服务的优先级,资源池开启抢占功能时会根据设置的任务抢占模式进行调度,高优先级可抢占低优先级任务的资源。 |
环境配置
| 参数名称 | 参数说明 |
|---|---|
| 镜像地址 | 支持选择百舸预置镜像或从百度云CCR镜像仓库、自建镜像仓库拉取镜像;若需私有镜像仓库授权,请输入账号密码。 |
| 启动命令 | 镜像的启动运行命令,如python /mnt/run.py |
| 环境变量 | 1.将被注入到容器实例中的环境变量; 2.变量名仅支持大小写字母、数字、下划线,且不能以数字作为开头。 |
| 存储挂载 | 设置模型权重文件存储的源路径和容器挂载的目标路径。 |
| 健康检查 | 可通过健康检查自动检测并恢复异常状态的容器,确保只有健康的实例接收流量并避免向不健康的实例分配资源。 1.可以配置存活探针、就绪探针、启动探针策略 2.三种检查方法: HTTP请求检查:通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则容器健康。 TCP连接检查:通过容器的 IP 地址和端口号执行 TCP 检查,如果能够建立 TCP 连接,则容器健康。 自定义执行命令:在容器中执行指定命令,如果执行成功后退出码为0则健康检查成功。 |
流量接入
| 参数名称 | 参数说明 |
|---|---|
| 负载均衡类型 | 支持云原生网关(7层)和传输层负载均衡(4层)两种流量接入方式。云原生网关和传输层负载均衡接入的调用方式不同,详见 API调用示例 云原生网关:为服务提供鉴权机制,能更好的保障服务安全性,提供的功能更丰富,如应用层监控指标采集、消费者鉴权、限流等功能; 传输层负载均衡: 提供更底层的流量转发能力,无应用层解析开销,转发效率更高。 |
| 云原生网关 | 点击【创建云原生网关】参考此文档创建网关实例创建网关实例 。使用网关部署服务支持设置负载均衡策略,服务部署成功后也可以在服务监控中查看流量监控。 注:使用旧版本网关部署的服务会影响后续新功能的使用,请联系技术支持人员升级至新版本,升级不会变更服务调用地址、鉴权信息。 |
| 传输层负载均衡 | 使用传输层负载均衡方式接入流量,需要选择一个BLB负载均衡实例,如您需通过公网调用服务请选择一个“支持公网”的BLB实例。仅支持绑定应用型实例,多个服务可以绑定一个BLB实例。 |
| 端口 | 云原生网关:只需要填写容器内监听端口,外部调用端口默认为容器内监听端口; 传输层负载均衡:复用同一BLB实例的服务设置的外部请求调用端口不能重复,可以使用自动分配端口功能生成端口。 |
高级配置
| 参数名称 | 参数说明 |
|---|---|
| 服务告警 | 支持对长时间未部署成功的实例监控告警,开启后可以设置告警和通知策略 |
| 网关认证鉴权 | 仅支持使用云原生网关部署的服务开启网关认证鉴权,关闭后将不提供鉴权功能。 |
| 最小实例数 | AI Job调度器开启任务抢占模式时,可设置当前服务至少要保留不被抢占的最小副本数。 |
| 优雅退出时间 | 实例退出前将等待一段时间来处理已经接收的请求,以减少实例变更带来的请求报错。无特殊需求建议使用默认值30s。 |
| 碎片迁移 | 开启后,资源池治理碎片资源时此服务将不再接收新请求,在优雅退出时间后自动删除实例并重建。关闭后,碎片整理时将不会迁移此服务。 |
| 滚动更新 | 支持为服务设置滚动更新策略,需要输入滚动更新过程中最大不可用和最大超量实例数比例。 1.最大不可用:滚动更新过程中不可用实例的数量占预期实例数的百分比,范围1%-100%。示例:预期实例数为10,最大不可用为20%,则更新过程中可用的实例数最少有8个。 2.最大超量:滚动更新过程中超出预期的实例数量占预期实例数的百分比,范围1%-100%。 示例:预期实例数为10,最大超量为10%,则更新过程中实例数最多可达11个。 |
升级服务
服务部署成功后,您可以通过 升级服务 修改镜像版本、存储挂载、健康检查、滚动更新策略等信息,填写本次变更内容的描述。 平台会记录详细的版本变更记录,您可在服务详情中查看版本变更记录。

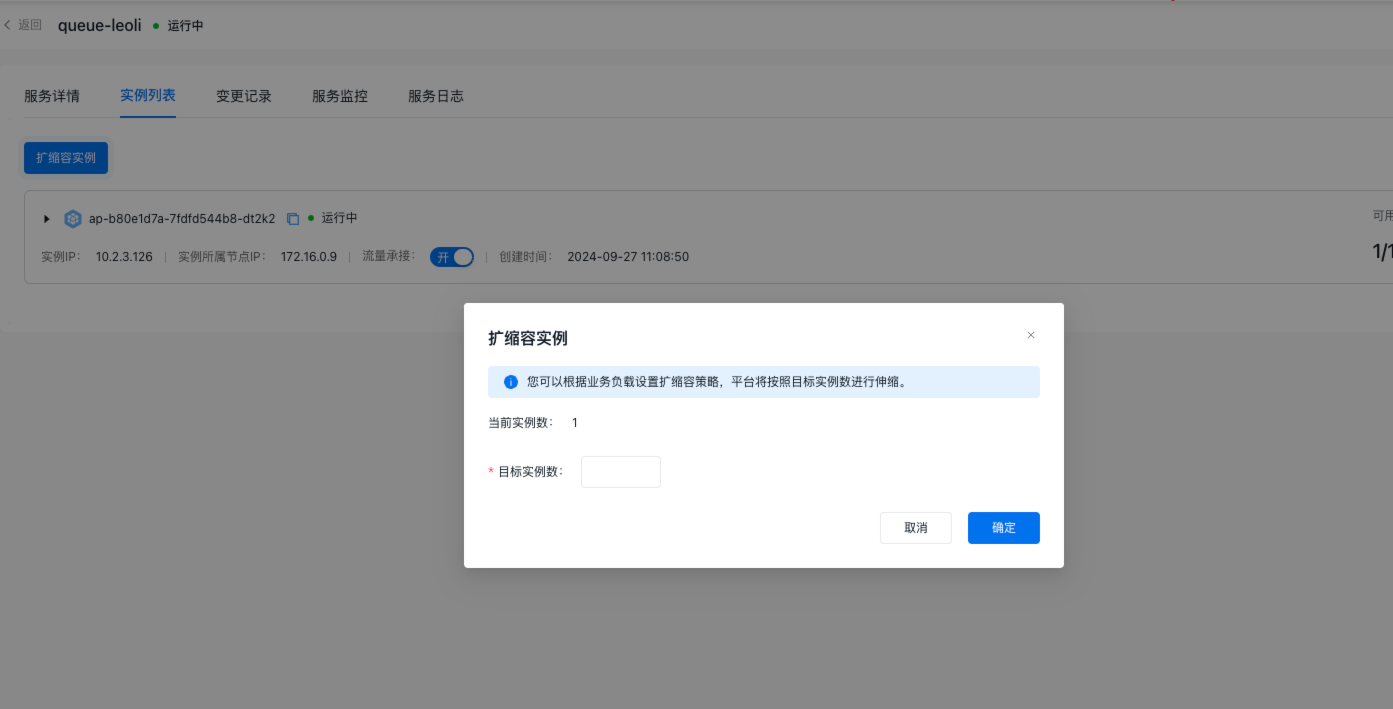
手动扩缩容
服务部署成功后,如果您的服务流量有变化,您可以进行扩缩容操作以满足您的流量负载要求。
实例摘流
当某个实例出现故障或性能问题,为了避免服务中断,可以通过实例摘流来平滑过渡。开启实例摘流后,需要等待几分钟生效。
流量接入
服务部署成功后,您可以在服务列表查看调用信息。在服务详情中修改流量接入的负载均衡实例,负载均衡类型不支持变更。
删除保护
服务部署成功后,支持开启删除保护,防止在线服务被误操作删除。
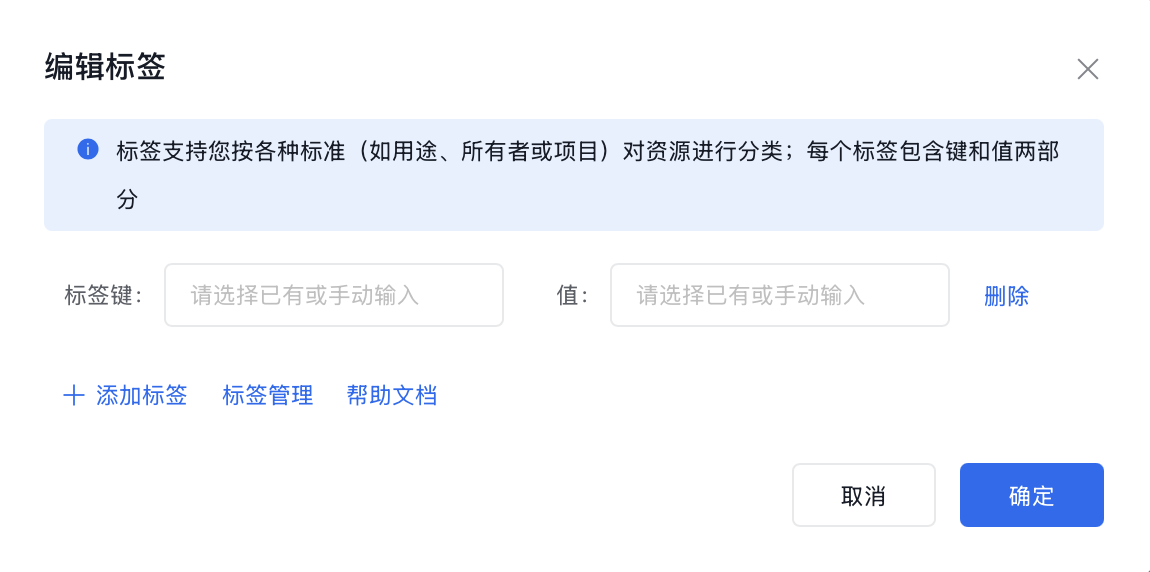
设置标签
服务部署成功后,支持为服务设置标签,用于服务筛选和统计。
多角色服务组
用于实现PD分离或更多角色服务的关联,负责部署多角色之间有复杂的调度逻辑的服务,有流量统一入口。
- PD分离必须从多角色服务组入口部署。
- 本期多角色服务组仅支持部署Prefill Decode两个角色的服务。
- 多角色服务组仅支持使用云原生网关接入流量。
- 服务组中的服务不能单独调用。
部署多角色服务组
- 登录百舸AI计算平台,点击左侧导航栏中的 在线服务部署 服务进入列表页面。
- 选择 多角色服务组 ,单击 部署多角色服务组 进入创建页面。
- 在创建页面填写相关参数,具体参数如下:
基础信息
| 参数名称 | 参数说明 |
|---|---|
| 服务名称 | 1.支持小写字母、数字以及 - 且开头必须是小写字母,结尾必须是小写字母或数字,长度1-50; 2.服务名称不可重复。 |
服务配置
| 参数名称 | 参数说明 |
|---|---|
| 资源池类型 | 选择在线服务需要部署到的资源池,仅支持全托管资源池。 全托管资源池:免运维资源池,您无需运维和管理资源池和算力资源,由平台保障资源池稳定性 |
| 服务 | 仅支持Prefill和Decode两种角色且固定角色名不能修改 |
| 资源池队列 | 不能跨资源池,一组中的多角色服务可以跨资源队列 |
| 资源规格 | 选择部署服务所需的加速芯片类型和卡数、CPU、内存;加速芯片类型选择 “不使用加速芯片”即部署CPU服务。 |
| 单实例Pod数 | 性能最优推荐P和D服务单实例Pod数为4,即分别部署到4台机器。 |
| RDMA | 分布式推理或PD分离部署时,建议开启RDMA优化跨节点之间的数据传输。注意:算力资源需支持RDMA,否则可能会调度失败。 |
| KV Cache感知调度 | 开启后平台会感知Prefill节点的缓存命中率,将请求调度到命中率高的实例,提升计算效率,降低首Token延迟。 |
| 镜像地址 | 支持选择百舸预置镜像或从百度云CCR镜像仓库、自建镜像仓库拉取镜像;若需私有镜像仓库授权,请输入账号密码。 |
| 端口 | 支持自定义监听和调用端口,开启公网访问后会自动暴露此端口。如需根据业务逻辑设置自定义的监控指标,对应的监控端口用途请选择“Metrics”。 注意:8001、8002端口已被系统占用,为了避免服务因端口冲突而无法正常完成启动,请勿设置为8001、8002。 |
| 环境变量 | 1.将被注入到容器实例中的环境变量; 2.变量名仅支持大小写字母、数字、下划线,且不能以数字作为开头。 |
| 共享内存 | 设置共享内存大小 |
| 存储挂载 | 设置模型权重文件存储的源路径和容器挂载的目标路径。 |
| 健康检查 | 可通过健康检查自动检测并恢复异常状态的容器,确保只有健康的实例接收流量并避免向不健康的实例分配资源。 1.可以配置存活探针、就绪探针、启动探针策略 2.三种检查方法: HTTP请求检查:通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则容器健康。 TCP连接检查:通过容器的 IP 地址和端口号执行 TCP 检查,如果能够建立 TCP 连接,则容器健康。 自定义执行命令:在容器中执行指定命令,如果执行成功后退出码为0则健康检查成功。 |
| 优先级 | 支持设置在线服务的优先级,资源池开启抢占功能时会根据设置的任务抢占模式进行调度,高优先级可抢占低优先级任务的资源。 |
| 最小实例数 | AI Job调度器开启任务抢占模式时,可设置当前服务至少要保留不被抢占的最小副本数。 |
| 优雅退出时间 | 实例退出前将等待一段时间来处理已经接收的请求,以减少实例变更带来的请求报错。无特殊需求建议使用默认值30s。 |
| 碎片迁移 | 开启后,资源池治理碎片资源时此服务将不再接收新请求,在优雅退出时间后自动删除实例并重建。关闭后,碎片整理时将不会迁移此服务。 |
| 滚动更新 | 支持为服务设置滚动更新策略,需要输入滚动更新过程中最大不可用和最大超量实例数比例。 1.最大不可用:滚动更新过程中不可用实例的数量占预期实例数的百分比,范围1%-100%。示例:预期实例数为10,最大不可用为20%,则更新过程中可用的实例数最少有8个。 2.最大超量:滚动更新过程中超出预期的实例数量占预期实例数的百分比,范围1%-100%。 示例:预期实例数为10,最大超量为10%,则更新过程中实例数最多可达11个。 |
流量接入
| 参数名称 | 参数说明 |
|---|---|
| 云原生网关 | 点击【创建云原生网关】参考此文档创建网关实例创建网关实例 。使用网关部署服务支持设置负载均衡策略,服务部署成功后也可以在服务监控中查看流量监控。 注:使用旧版本网关部署的服务会影响后续新功能的使用,请联系技术支持人员升级至新版本,升级不会变更服务调用地址、鉴权信息。 |
| 网关认证鉴权 | 仅支持使用云原生网关部署的服务开启网关认证鉴权,关闭后将不提供鉴权功能。 |
调用信息
多角色服务组的统一入口调用地址。
流量接入
服务部署成功后,您可以在服务列表查看调用信息。在服务详情中修改流量接入的负载均衡实例,负载均衡类型不支持变更。
删除
删除服务组和服务组中的服务。
评价此篇文章