
工作流模板示例
更新时间:2026-04-02
此文档涵盖典型业务场景工作流模板,开发者可以使用这些模板快速修改应用的自己的工作流当中。
数据集动态加载
以下工作流实现BOS冷数据动态加载至PFS并在训练后自动清理。
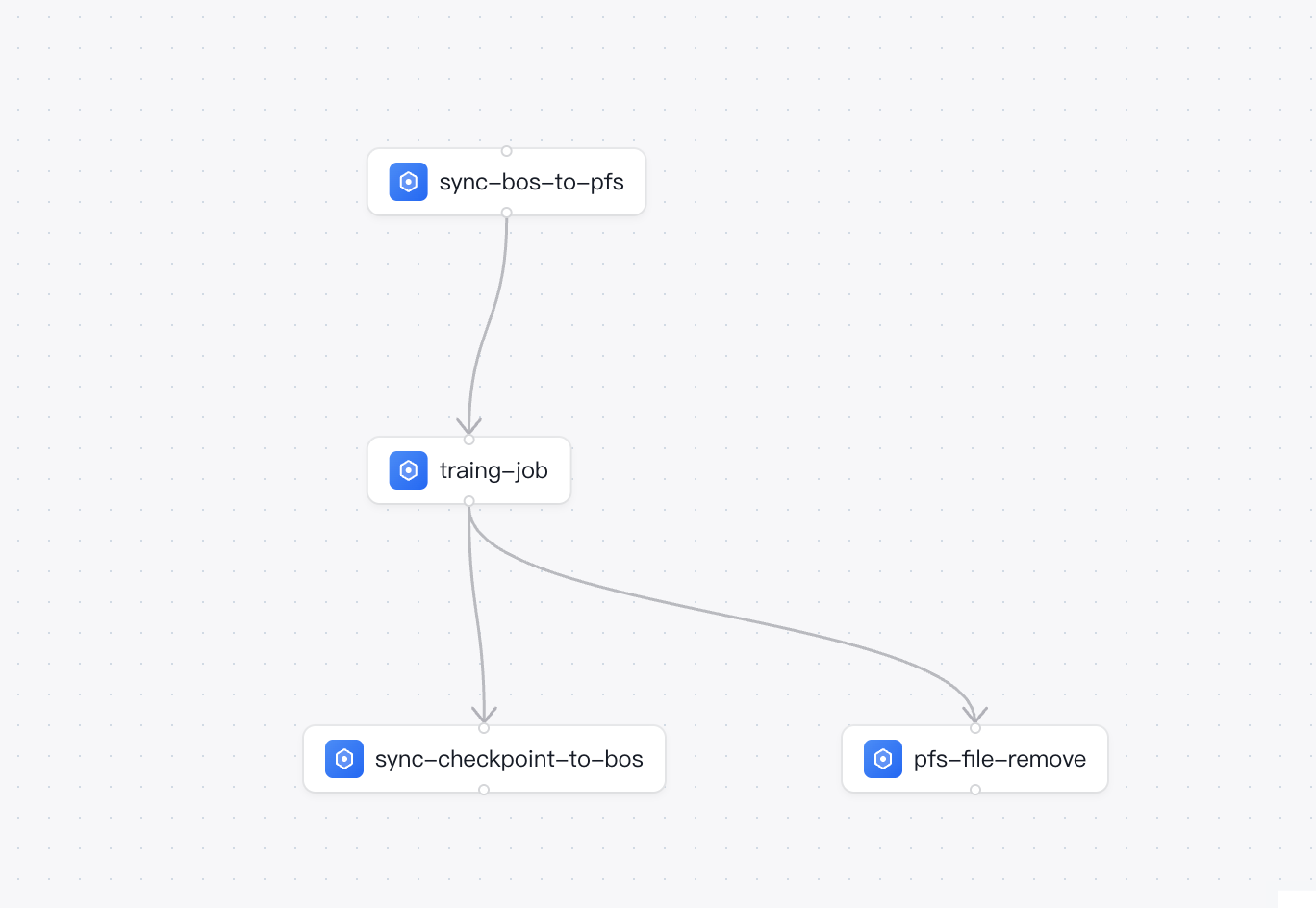
简介
背景 在模型训练场景中,由于训练程序需要极高的磁盘I/O吞吐,通常建议将训练数据集放置在并行文件存储PFS中以保障训练效率。而PFS的存储成本相对较高,不适合作为数据的长期持久化存储。因此,企业通常将海量数据集(冷数据)存放在成本更低的对象存储(BOS)中。
痛点
- 人工介入成本高:算法工程师在每次启动训练前,需要手动启动数据搬运任务将BOS的数据拷贝到PFS,待拷贝完成后再手动启动训练任务。
- 资源浪费严重:训练任务结束后,经常会忘记清理PFS上的数据集,导致昂贵的高性能存储空间被无效占用,产生不必要的成本。
方案说明
借助百舸工作流,我们可以构建一个自动化的三步串行流水线:
- 数据预热节点:挂载PFS,利用CPU节点将BOS中的冷数据自动拷贝至PFS中。
- 模型训练节点:依赖数据预热节点,待数据拷贝完成后,挂载数据预热节点相同PFS源路径执行模型训练任务。
-
checkpoint存档及数据清理(并行执行):
- checkpoint存档节点:将训练得到的权重上传到bos存档。
- 数据清理节点:依赖模型训练节点,待训练完成后,清理PFS上的数据集缓存,从而释放高性能存储空间。
YAML 配置
以下是该最佳实践的完整工作流 YAML 配置。您可以将其直接复制并根据实际环境(如队列ID、PFS实例ID、BOS路径)进行替换使用。
YAML
1version: v1
2kind: PipelineTemplate
3taskTemplates:
4 - name: bos-to-pfs
5 type: CustomTask
6 inputs:
7 - name: queue_id
8 type: string
9 hint: 队列ID
10 - name: bos_path
11 type: string
12 hint: 数据集的BOS路径
13 - name: bos_ak
14 type: string
15 hint: BOS存储桶的访问ak
16 - name: bos_sk
17 type: string
18 hint: BOS存储桶的访问sk
19 - name: pfs_path
20 type: string
21 hint: PFS源路径
22 - name: pfs_id
23 type: string
24 hint: PFS实例ID
25 spec:
26 queue: '{{inputs.parameters.queue_id}}'
27 jobType: PyTorchJob
28 command: >
29 WORK_DIR="$(pwd)"
30
31 ZIP_URL="https://doc.bce.baidu.com/bos-optimization/mac-bcecmd-0.5.10.zip"
32
33 ZIP_FILE="mac-bcecmd-0.5.10.zip"
34
35 EXTRACT_DIR="mac-bcecmd-0.5.10"
36
37 echo "正在下载 bcecmd 工具..."
38
39 curl -LO "$ZIP_URL"
40
41 if [ $? -ne 0 ]; then
42 echo "下载失败!请检查网络或 URL。"
43 exit 1
44 fi
45
46 echo "正在解压..."
47
48 unzip -o "$ZIP_FILE"
49
50 if [ $? -ne 0 ]; then
51 echo "解压失败!"
52 exit 1
53 fi
54
55 cd "$EXTRACT_DIR" || { echo " 无法进入目录 $EXTRACT_DIR"; exit 1; }
56
57 echo " 正在创建 credentials 文件..."
58
59 mkdir -p /root/.go-bcecli
60
61 cat > ~/.go-bcecli/credentials <<EOF
62
63 [Defaults]
64
65 Ak = "$BOS_AK"
66
67 Sk = "$BOS_SK"
68
69 EOF
70
71 chmod 600 ~/.go-bcecli/credentials
72
73 echo "bcecmd工具安装及配置完成,开始下载数据"
74
75 ./bcecmd bos sync {{inputs.parameters.bos_path}} /mnt/cluster/dataset
76
77 echo "数据集下载成功,已保存到PFS的{{inputs.parameters.pfs_path}}路径"
78 jobSpec:
79 image: registry.baidubce.com/inference/aibox-ubuntu:v2.0-22.04
80 replicas: 1
81 envs:
82 - name: BOS_AK
83 value: '{{inputs.parameters.bos_ak}}'
84 - name: BOS_SK
85 value: '{{inputs.parameters.bos_sk}}'
86 datasources:
87 - type: pfs
88 name: '{{inputs.parameters.pfs_id}}'
89 sourcePath: '{{inputs.parameters.pfs_path}}'
90 mountPath: /mnt/cluster/dataset
91 - name: pfs-to-bos
92 type: CustomTask
93 inputs:
94 - name: queue_id
95 type: string
96 hint: 队列ID
97 - name: bos_path
98 type: string
99 hint: 数据集的BOS路径
100 - name: bos_ak
101 type: string
102 hint: BOS存储桶的访问ak
103 - name: bos_sk
104 type: string
105 hint: BOS存储桶的访问sk
106 - name: pfs_path
107 type: string
108 hint: PFS源路径
109 - name: pfs_id
110 type: string
111 hint: PFS实例ID
112 spec:
113 queue: '{{inputs.parameters.queue_id}}'
114 jobType: PyTorchJob
115 command: >
116 WORK_DIR="$(pwd)"
117
118 ZIP_URL="https://doc.bce.baidu.com/bos-optimization/mac-bcecmd-0.5.10.zip"
119
120 ZIP_FILE="mac-bcecmd-0.5.10.zip"
121
122 EXTRACT_DIR="mac-bcecmd-0.5.10"
123
124 echo "正在下载 bcecmd 工具..."
125
126 curl -LO "$ZIP_URL"
127
128 if [ $? -ne 0 ]; then
129 echo "下载失败!请检查网络或 URL。"
130 exit 1
131 fi
132
133 echo "正在解压..."
134
135 unzip -o "$ZIP_FILE"
136
137 if [ $? -ne 0 ]; then
138 echo "解压失败!"
139 exit 1
140 fi
141
142 cd "$EXTRACT_DIR" || { echo " 无法进入目录 $EXTRACT_DIR"; exit 1; }
143
144 echo " 正在创建 credentials 文件..."
145
146 mkdir -p /root/.go-bcecli
147
148 cat > ~/.go-bcecli/credentials <<EOF
149
150 [Defaults]
151
152 Ak = "$BOS_AK"
153
154 Sk = "$BOS_SK"
155
156 EOF
157
158 chmod 600 ~/.go-bcecli/credentials
159
160 echo "bcecmd工具安装及配置完成,开始上传数据"
161
162 ./bcecmd bos sync /mnt/cluster/dataset {{inputs.parameters.bos_path}}
163
164 echo "数据集上传成功,已保存到BOS的{{inputs.parameters.bos_path}}路径"
165 jobSpec:
166 image: registry.baidubce.com/inference/aibox-ubuntu:v2.0-22.04
167 replicas: 1
168 envs:
169 - name: BOS_AK
170 value: '{{inputs.parameters.bos_ak}}'
171 - name: BOS_SK
172 value: '{{inputs.parameters.bos_sk}}'
173 datasources:
174 - type: pfs
175 name: '{{inputs.parameters.pfs_id}}'
176 sourcePath: '{{inputs.parameters.pfs_path}}'
177 mountPath: /mnt/cluster/dataset
178 - name: custom-task-template
179 type: CustomTask
180 spec:
181 queue: aihcq-xxxxx
182 jobType: PyTorchJob
183 command: sleep 30s
184 priority: normal
185 enableBccl: false
186 faultTolerance: true
187 faultToleranceArgs: >-
188 --enable-replace=true --enable-hang-detection=true
189 --hang-detection-log-timeout-minutes=7
190 --hang-detection-startup-toleration-minutes=15
191 --hang-detection-stack-timeout-minutes=3
192 --max-num-of-unconditional-retry=2 --custom-log-patterns=timeout1
193 --custom-log-patterns=timeout2
194 retentionPeriod: 1d
195 jobSpec:
196 image: >-
197 registry.baidubce.com/aihc-aiak/aiak-megatron:ubuntu20.04-cu11.8-torch1.14.0-py38_v1.2.7.12_release
198 imageConfig:
199 username: your-registry-username
200 password: your-registry-password
201 replicas: 2
202 resources:
203 - name: baidu.com/a800_80g_cgpu
204 quantity: 8
205 - name: cpu
206 quantity: 96
207 - name: memory
208 quantity: 512
209 - name: sharedMemory
210 quantity: 64
211 envs:
212 - name: NCCL_DEBUG
213 value: INFO
214 - name: NCCL_IB_DISABLE
215 value: '0'
216 - name: CUDA_VISIBLE_DEVICES
217 value: 0,1,2,3,4,5,6,7
218 enableRDMA: true
219 hostNetwork: false
220 labels:
221 - key: project
222 value: llm-training
223 - key: team
224 value: ai-platform
225 datasources:
226 - type: pfs
227 name: pfs-pxE6jz
228 sourcePath: /
229 mountPath: /mnt/cluster
230 options:
231 readOnly: false
232 - type: hostPath
233 name: host-data
234 sourcePath: /data/shared
235 mountPath: /mnt/host-data
236 options:
237 readOnly: true
238 - type: bos
239 name: ''
240 sourcePath: bos://my-bucket/datasets/
241 mountPath: /mnt/bos-data
242 options:
243 readOnly: true
244 - type: cfs
245 name: cfs-instance-id
246 sourcePath: /
247 mountPath: /mnt/cfs-data
248 options:
249 readOnly: false
250 - type: rapidfs
251 name: rapidfs-instance-id
252 sourcePath: /
253 mountPath: /mnt/rapidfs-data
254 options:
255 readOnly: false
256 - type: dataset
257 name: dataset-id
258 sourcePath: /
259 mountPath: /mnt/dataset
260 options:
261 readOnly: true
262 tensorboardConfig:
263 enable: true
264 logPath: /mnt/cluster/tensorboard-logs
265 alertConfig:
266 instanceId: your-cluster-monitor-instance-id
267 alertItems:
268 - jobRunning
269 - jobFT
270 - nodeFT
271 - jobFailed
272 - jobSucceed
273 - jobHang
274 for: 0m
275 notifyRuleId: notify-xxxxxxxx
276 - name: pfs-remove
277 type: CustomTask
278 inputs:
279 - name: queue_id
280 type: string
281 hint: 队列ID
282 - name: pfs_id
283 type: string
284 hint: PFS实例ID
285 - name: pfs_path
286 type: string
287 hint: PFS源路径
288 spec:
289 queue: '{{inputs.parameters.queue_id}}'
290 jobType: PyTorchJob
291 command: |
292 rm -r /mnt/cluster/dataset
293 echo "数据集删除成功,已删除PFS的{{inputs.parameters.pfs_path}}路径上的数据"
294 priority: normal
295 jobSpec:
296 image: registry.baidubce.com/inference/aibox-ubuntu:v2.0-22.04
297 replicas: 1
298 datasources:
299 - type: pfs
300 name: '{{inputs.parameters.pfs_id}}'
301 sourcePath: '{{inputs.parameters.pfs_path}}'
302 mountPath: /mnt/cluster/dataset
303tasks:
304 - name: sync-bos-to-pfs
305 taskTemplateName: bos-to-pfs
306 inputs:
307 - name: queue_id
308 value: aihcq-h1plvpzb5gh0
309 - name: bos_path
310 value: bos://my-bucket/datasets/
311 - name: bos_ak
312 value: <你的sk>
313 - name: bos_sk
314 value: <你的sk>
315 - name: pfs_path
316 value: /datasets/my-dataset
317 - name: pfs_id
318 value: pfs-xxxx
319 - name: traing-job
320 taskTemplateName: custom-task-template
321 inputs:
322 - name: queue_id
323 value: aihcq-h1plvpzb5gh0
324 - name: bos_path
325 value: bos://my-bucket/datasets/
326 - name: bos_ak
327 value: <你的sk>
328 - name: bos_sk
329 value: <你的sk>
330 - name: pfs_path
331 value: /datasets/my-dataset
332 - name: pfs_id
333 value: pfs-xxxx
334 dependencies:
335 - sync-bos-to-pfs
336 - name: sync-checkpoint-to-bos
337 taskTemplateName: pfs-to-bos
338 inputs:
339 - name: queue_id
340 value: aihcq-h1plvpzb5gh0
341 - name: bos_path
342 value: bos://my-bucket/checkpoints/
343 - name: bos_ak
344 value: <你的sk>
345 - name: bos_sk
346 value: <你的sk>
347 - name: pfs_path
348 value: /checkpoints/my-checkpoint
349 - name: pfs_id
350 value: pfs-xxxx
351 dependencies:
352 - traing-job
353 - name: pfs-file-remove
354 taskTemplateName: pfs-remove
355 inputs:
356 - name: queue_id
357 value: aihcq-h1plvpzb5gh0
358 - name: pfs_path
359 value: /datasets/my-dataset
360 - name: pfs_id
361 value: pfs-xxxx
362 dependencies:
363 - traing-job评价此篇文章