
快速微调NVIDIA GR00T N1.5模型
NVIDIA GR00T N1.5 是英伟达(NVIDIA)推出的开源通用人形机器人基础模型,相比 N1,N1.5 在 语言指令理解、新环境泛化 和 训练效率 上显著提升。
目前百舸异构计算平台提供了 NVIDIA GR00T N1.5 模型的训练模版,内置训练代码和镜像,您可以在平台分布式训练模块中,快速发起训练。
前置条件
算力和存储资源准备
算力资源
下表给出了不同模型在百舸默认参数和数据集的情况下,训练所依赖的最低配置:
| 模型名称 | 训练方式 | 训练资源配置 |
|---|---|---|
| nvidia/GR00T-N1.5-3B | Finetune | H800/A800*1卡 |
存储资源
为保证训练的性能,推荐使用并行文件存储PFS。
数据准备
GR00T-N1.5-3B Finetune
数据集准备
数据集要求:Huggingface LeRobot 格式。
如使用自定义数据,需要将自定义的数据集转换为LeRobot dataset,可参考Robot Data Conversion Guide
百舸平台已经在对象存储BOS中,预置NVIDIA 开源的人形机器人数据集 PhysicalAI-Robotics-GR00T-X-Embodiment-Sim/gr1_arms_only.CanSort。您可以从对应地域的BOS路径中下载数据。请参考下载百舸平台预置的公共数据到PFS
1bos:/aihc-rdw-bj/nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim/gr1_arms_only.CanSort模型权重准备
百舸平台已经在对象存储BOS中预置模型权重,方便用户快速开始。您可以从对应地域的BOS路径中下载数据。
1bos:/aihc-models-bj/nvidia/GR00T-N1.5-3B数据配置文件(DATA_CONFIG_FILE)
若您的数据集完全匹配data_config.py中 DATA_CONFIG_MAP 中的预定义配置,则无需定义数据配置文件,否则需要重新定义此文件,可参考 data_config.py
进行训练
- 登录百舸异构计算平台AIHC控制台。
-
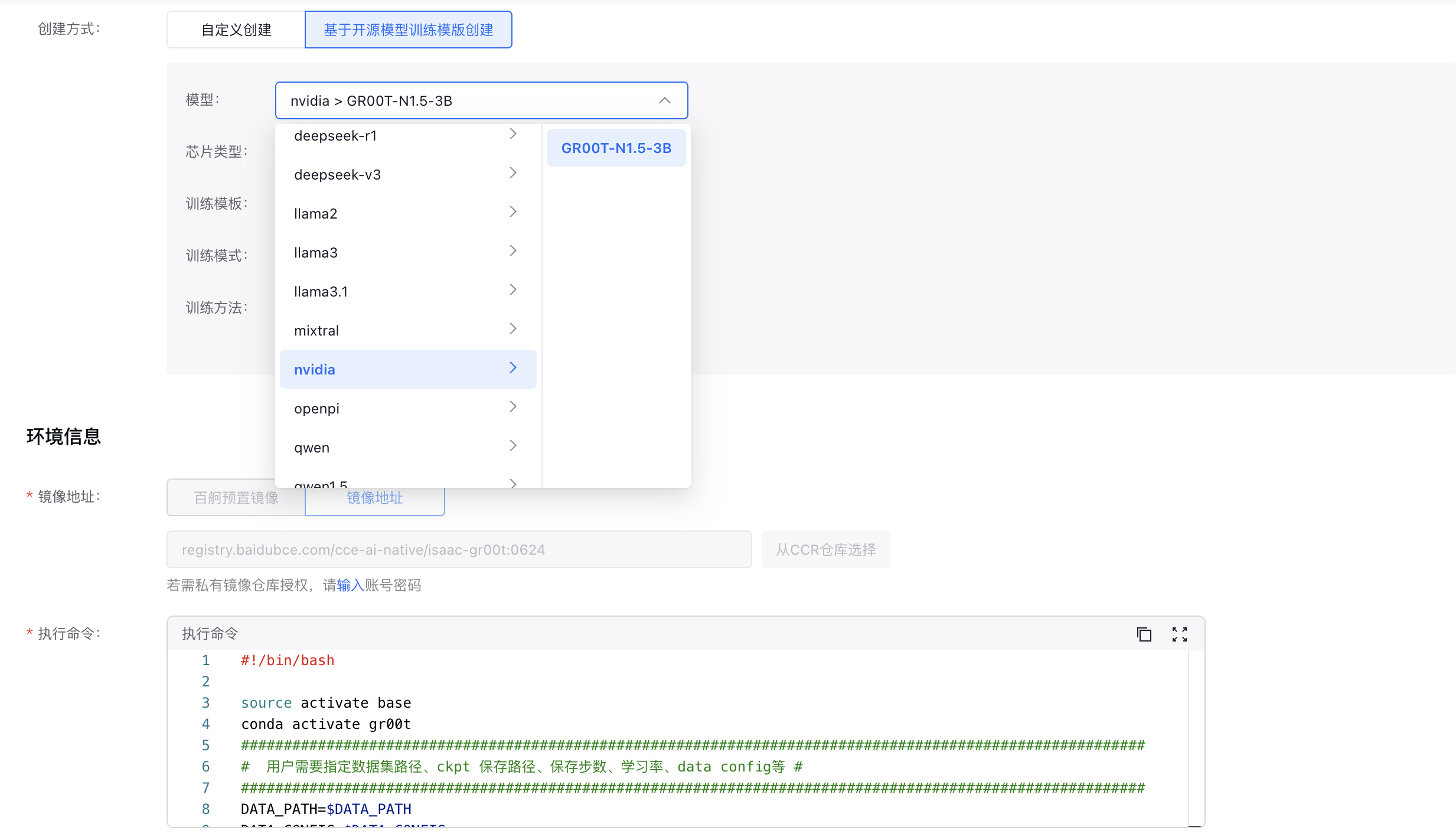
进入 分布式训练 列表页面,点击创建任务,填写任务配置信息:
-
基础信息
- 任务名称:输入您的自定义任务名称
- 可见范围:选择任务的可见范围
- 任务创建方式: 选择 基于开源模型训练模版创建
- 模型:选择对应的模型和训练方式,这里选择nvidia/GROOT-N1.5-3B
-
环境信息
- 镜像地址:无需更改,平台默认提供
-
执行命令:系统已经默认训练的启动参数,需要替换
DATA_PATH、DATA_CONFIG、DATA_CONFIG_FILE、BASE_MODEL_PATH、CHECKPOINT_SAVE_PATH等配置信息DATA_PATH:必填,可直接使用平台预置在BOS中的PhysicalAI-Robotics-GR00T-X-Embodiment-Sim/gr1_arms_only.CanSort数据集,需要提前转存至资源池所在PFS并行文件存储中DATA_CONFIG:必填,如使用上文预置的数据集PhysicalAI-Robotics-GR00T-X-Embodiment-Sim/gr1_arms_only.CanSort,则DATA_CONFIG=fourier_gr1_arms_onlyDATA_CONFIG_FILE:若您的数据集完全匹配data_config.pyDATA_CONFIG_MAP中的预定义配置,则无需填写BASE_MODEL_PATH:原始权重加载地址CHECKPOINT_SAVE_PATH:训练过程中CKPT保存地址MAX_STEPS=$MAX_STEPS:训练的迭代次数,如100000-
REPORT_TO:训练指标支持可视化工具,目前支持wandb、tensorboard。如定义为wandb,需要额外填写启动命令中的wandb的环境变量(请确保训练容器和wandb服务的网络联通性,否则会启动失败):WANDB_API_KEY:必填,Wandb 账户的认证密钥,用于身份验证和访问权限。必须设置才能与 Wandb 服务端通信WANDB_ENTITY:非必填,团队或用户名,用于控制实验数据存储的位置(个人账户或团队空间)WANDB_PROJECT:非必填,如果不存在,wandb会自动创建WANDB_MODE:必填,设置为onlineWANDB_NAME:非必填,自动使用CHECKPOINT_SAVE_PATH作为名称WANDB_RUN_ID:必填,自定义,如run1
- 环境变量:无需更改
-
资源配置
- 资源池&队列:选择已创建的资源池和队列
- 优先级:默认 中 优先级,无需更改
- 训练框架:选择Pytorch
-
资源配额
- 实例数:目前支持单机训练
- GPU类型&卡数:支持A800卡和H800卡,卡数1-8卡
- CPU/内存:按需填写
- 共享内存:默认10Gi
- RDMA:单机训练,无需开启
-
设置数据源
- 存储类型:这里选择我们提前准备的PFS
- PFS源路径:PFS的挂载路径,默认根目录,按实际情况填写
- 挂载路径:容器内的挂载路径
-
- 点击 完成,提交训练任务。
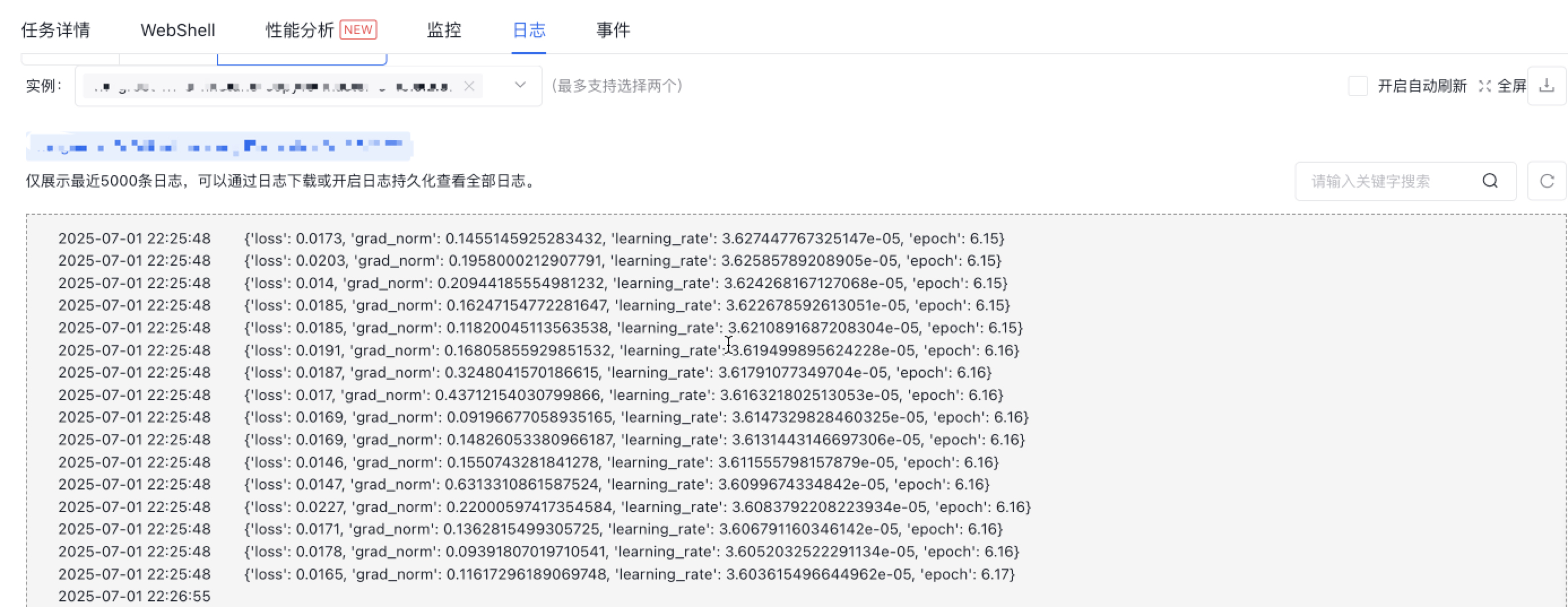
观察训练迭代
任务提交后,您可以通过任务日志观察训练的迭代情况
评价此篇文章