
导入数据到数据集
更新时间:2026-01-08
数据集提供数据导入能力,帮助用户将数据导入到已有数据集中,实现数据集、权重等文件的上传到百舸进行训练、开发等业务操作。
目前数据集支持已有数据集导入和自定义下载导入:
| 导入方式 | 概述 | 数据集存储类型支持 |
|---|---|---|
| 已有数据集导入 | 数据集管理提供存储类型为对象存储BOS和并行文件存储PFS(L2)数据集之间相互导入数据,通过已有数据导入功能可以方便的将数据在PFS和BOS之间进行转存。 | PFS(极速型L2)BOS |
| 自定义下载 | 通过编写自定义下载任务脚本,从任意百舸资源池网络可达的数据源下载或转储数据到数据集。 | 数据集支持的全部存储类型 |
进入数据集详情页,点击版本列表Tab,在版本列表中操作【导入数据】
已有数据集导入

限制条件
当前仅支持PFS L2与BOS之间进行互相转储。
操作步骤
- 将需要导入数据的目录(目标数据集)和被导入目录(源数据集)分别创建为数据集,数据集创建完成后在数据集列表中找到对应数据集,在操作列选择【导入数据】
- 在创建转储任务弹窗内选择源数据集及版本等信息。
例如将数据集B(BOS类型)的v1版本(存储路径/dataset/test)数据导入到数据集A(PFS类型)的v1版本(存储路径/dataset/test/v1),则在数据集A操作【数据导入】
| 参数 | 说明 |
|---|---|
| 任务名称 | 转储任务的名称,字母、数字、下划线_、中划线-,以字母开头,1~128个字符 |
| 源数据集 | 要导入的数据集,可选择当前用户有读权限的数据集 |
| 源数据版本 | 源数据集的数据版本,每个版本对应一个存储路径 |
| 冲突策略 | 覆盖该文件:保留源数据集中的文件 |
跳过该文件:不导入该文件 保留两者:在目标数据集中同时保存两个同名数据文件| |目标数据集|当前操作的数据集| |目标数据版本|导入数据存储的版本,每个版本对应一个存储路径|
- 提交转储任务,在数据集详情的【转储任务】Tab页可以查看转储任务记录及状态。
自定义下载导入
自定义下载是利用用户自有资源池以任务的形式下载网络上的数据到当前数据集。
- 通过编写合适的启动命令,可以实现从任意远程数据源下载数据;
- 任务使用资源池的CPU和内存资源,不需要使用GPU资源。
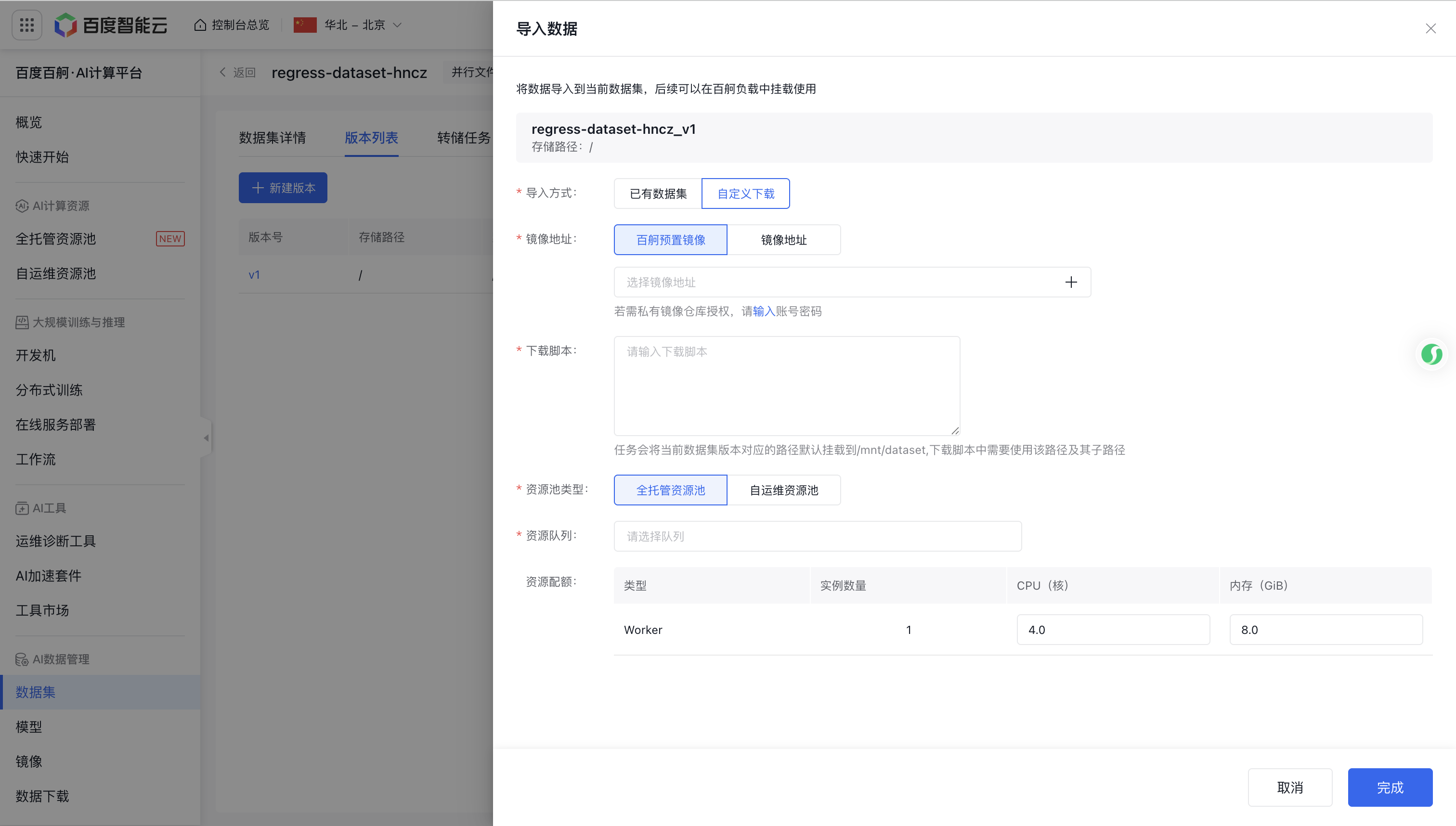
限制条件
需要资源池可以访问需要下载的远程数据源,下载HuggingFace、GitHub等国外网站资源需先自行设置资源池可以访问外网或使用国内源。
操作步骤
- 填写下载任务表单信息
| 参数 | 说明 |
|---|---|
| 镜像地址 | 下载数据需要使用的镜像,支持百舸预置镜像和自定义镜像一般情况如无特殊的需求,选择任意百舸预置镜像均可以完成下载 |
| 下载脚本 | 下载任务的执行脚本,脚本中包含下载数据的全部逻辑,包括鉴权、端点续传等 特别注意: 任务会将当前数据集版本对应的路径默认挂载到/mnt/dataset,下载脚本中需要使用该路径及其子路径保存下载的数据,同时默认注入环境变量DATASET_PATH=/mnt/dataset,也可以通过引用DATASET_PATH使用默认挂载路径 |
| 资源池类型 | 运行下载任务的资源池类型 |
| 资源队列 | 运行下载任务的资源队列 |
| 资源配额 | 运行任务的资源限制,默认值4核8G,可以根据下载脚本设置的并发数进行调整,如果不设置则不会限制 |
- 提交下载任务成功后,在【分布式训练】任务列表中可以查看任务的日志和事件观察进度和异常。
下载脚本示例
特别注意:
- 以下示例均在网络可达的前提条件下验证,使用前请先验证资源池可以访问源数据地址
- 验证使用镜像registry.baidubce.com/aihcp-public/pytorch:2.7.0-cu12.8.61-py3.12-ubuntu24.04,自定义其他镜像时可根据事件信息进行脚本调试
- 示例脚本只是方便用户理解下载方法,实际使用时需要根据需求对脚本进行修改
从魔搭下载数据集、权重
Shell
1#!/bin/sh
2
3# 设置数据集名称
4DATASET_NAME="liucong/Chinese-DeepSeek-R1-Distill-data-110k"
5
6# 构建目标存储路径,以数据集根目录/数据集名称存储
7TARGET_DIR="$DATASET_PATH/$DATASET_NAME_ESCAPED"
8
9# 检查是否已安装 modelscope
10if ! command -v modelscope >/dev/null 2>&1; then
11 echo "modelscope 未安装,正在安装..."
12 # 使用 --user 避免权限问题(可选)
13 pip install --user modelscope
14 # 将 --user 安装的 bin 加入 PATH(适用于某些环境)
15 export PATH="$HOME/.local/bin:$PATH"
16fi
17
18# 使用 modelscope CLI 下载数据集(注意:使用 --dataset 而非 --model)
19echo "正在下载数据集 $DATASET_NAME 到 $TARGET_DIR ..."
20modelscope download --dataset "$DATASET_NAME" --revision master --local_dir "$TARGET_DIR"
21
22if [ $? -eq 0 ]; then
23 echo "数据集已成功下载至: $TARGET_DIR"
24else
25 echo "下载失败!请检查网络、权限或数据集是否存在。"
26 exit 1
27fi从HuggingFace下载数据集
Shell
1#!/bin/sh
2
3# 配置
4HF_DATASET_ID="Congliu/Chinese-DeepSeek-R1-Distill-data-110k"
5
6# 构建本地目标路径
7LOCAL_DIR="$DATASET_PATH/$HF_DATASET_ID"
8mkdir -p "$LOCAL_DIR"
9
10# 检查是否已存在(简单判断)
11if [ -f "$LOCAL_DIR/.hf_download_complete" ]; then
12 echo "数据集已下载(检测到 .hf_download_complete 标记),跳过。"
13 exit 0
14fi
15
16# 安装 huggingface_hub(如果未安装)
17if ! python3 -c "import huggingface_hub" &> /dev/null; then
18 echo "正在安装 huggingface_hub..."
19 pip install --quiet huggingface_hub
20fi
21
22# 创建临时 Python 脚本
23PY_SCRIPT=$(cat <<EOF
24from huggingface_hub import snapshot_download
25import os
26
27local_dir = os.environ['LOCAL_DIR']
28repo_id = os.environ['HF_DATASET_ID']
29
30print(f"正在从 Hugging Face 下载数据集: {repo_id}")
31snapshot_download(
32 repo_id=repo_id,
33 local_dir=local_dir,
34 repo_type="dataset",
35 max_workers=8
36)
37print("下载完成!")
38EOF
39)
40
41# 导出环境变量供 Python 使用
42export LOCAL_DIR="$LOCAL_DIR"
43export HF_DATASET_ID="$HF_DATASET_ID"
44
45# 执行下载
46echo "开始从 Hugging Face Hub 下载数据集..."
47python3 -c "$PY_SCRIPT"
48
49# 检查是否成功并创建标记文件
50if [ $? -eq 0 ]; then
51 touch "$LOCAL_DIR/.hf_download_complete"
52 echo "数据集已保存至: $LOCAL_DIR"
53else
54 echo "下载失败。请检查数据集 ID、网络或访问权限。"
55 exit 1
56fi从开放网址下载
Shell
1#!/bin/bash
2
3# 配置:通过环境变量传入
4HTTP_URL="https://example.com/data/SKYLENAGE-ReasoningMATH.zip"
5DATASET_NAME="SKYLENAGE-ReasoningMATH"
6
7# 构建本地目标目录
8LOCAL_DIR="$DATASET_PATH/Alibaba-DT/$DATASET_NAME"
9mkdir -p "$LOCAL_DIR"
10
11# 推断文件名(从 URL 最后一段)
12FILENAME=$(basename "$HTTP_URL")
13TMP_FILE="$LOCAL_DIR/${FILENAME}"
14
15# 检查是否已下载
16if [ -f "$TMP_FILE" ]; then
17 echo "文件 $TMP_FILE 已存在,跳过下载。"
18 exit 0
19fi
20
21# 下载文件
22echo "正在从 $HTTP_URL 下载..."
23if command -v wget &> /dev/null; then
24 wget -O "$TMP_FILE" --progress=bar:force:noscroll "$HTTP_URL"
25elif command -v curl &> /dev/null; then
26 curl -L -o "$TMP_FILE" -# "$HTTP_URL"
27else
28 echo "错误: 未找到 wget 或 curl,请安装其中一个工具。"
29 exit 1
30fi
31
32# 检查下载是否成功
33if [ $? -ne 0 ] || [ ! -s "$TMP_FILE" ]; then
34 echo "下载失败或文件为空。"
35 rm -f "$TMP_FILE"
36 exit 1
37fi
38
39# 自动解压(如果为压缩包)
40if [[ "$FILENAME" == *.zip ]]; then
41 echo "正在解压 ZIP 文件..."
42 unzip -q -o "$TMP_FILE" -d "$LOCAL_DIR"
43 # 可选:删除压缩包
44 # rm "$TMP_FILE"
45elif [[ "$FILENAME" == *.tar.gz ]] || [[ "$FILENAME" == *.tgz ]]; then
46 echo "正在解压 TAR.GZ 文件..."
47 tar -xzf "$TMP_FILE" -C "$LOCAL_DIR"
48 # rm "$TMP_FILE"
49elif [[ "$FILENAME" == *.tar.bz2 ]]; then
50 echo "正在解压 TAR.BZ2 文件..."
51 tar -xjf "$TMP_FILE" -C "$LOCAL_DIR"
52 # rm "$TMP_FILE"
53else
54 echo "文件非压缩格式,已保存至: $TMP_FILE"
55fi
56
57echo "数据集已准备完毕,路径: $LOCAL_DIR"更多下载方式
不知道如何构建自定义数据源下载脚本,试试使用DeepSeek、ChatGPT等大语言模型编写,在Mac、Linux环境测试通过后即可在自定义导入任务中使用。
使用导入的数据
在分布式训练任务、在线服务部署、开发机中直接使用数据集或直接挂载数据集对应的存储路径。
评价此篇文章