
LingBot-Depth训推
https://technology.robbyant.com/lingbot-depth 以掩码深度建模实现超越工业级相机的稠密深度感知

模型概述
LingBot-Depth 是一种面向真实场景的深度补全模型,旨在将不完整且受噪声干扰的深度传感器数据转化为高质量、具备真实尺度的三维测量结果。该模型针对机器人与自主系统中的关键挑战:消费级深度相机在玻璃、镜面及金属等强反光表面上容易失效,而这些场景恰恰对可靠深度感知提出了更高要求。
实验结果表明,本模型在深度精度与像素覆盖率两项核心指标上均超越业界顶级工业级深度相机。在多个基准测试中,LingBot-Depth 在深度补全、单目深度估计及双目匹配任务上均达到当前最优水平,并在无需显式时序建模的情况下保持视频级时间一致性。下游任务验证进一步表明,模型能够在 RGB 与深度两种模态之间学习到对齐的潜在空间表征,从而实现对透明及反光物体的稳定机器人抓取。
为推动空间感知研究的发展,蚂蚁灵波开源了模型,以及 200 万对高质量 RGB–深度配对数据。
精准且稳定的相机深度感知


LingBot-Depth 在传统深度传感器易失效的复杂场景中,仍可输出具备真实尺度的高精度深度结果,包括透明物体、玻璃表面以及高反光材质等极具挑战性的环境。不同于依赖硬件改进的方案,本模型从视觉理解层面弥补传感器缺陷,实现对真实三维结构的可靠恢复。 除单帧精度优势外,LingBot-Depth 还表现出优异的时间一致性。在无需显式时序建模的情况下,模型即可为视频输入生成稳定、连贯的深度序列,有效避免闪烁与结构跳变问题,为机器人操作、AR/VR 以及动态场景感知等应用提供可靠的连续空间理解能力。
卓越的 3D 和 4D 环境感知能力



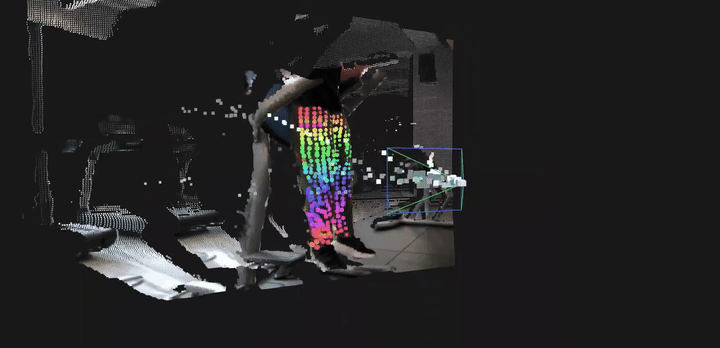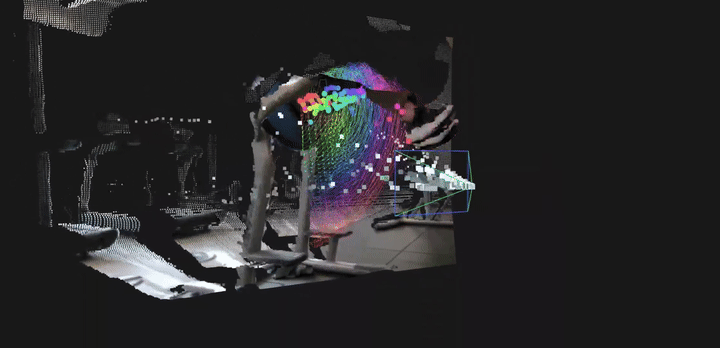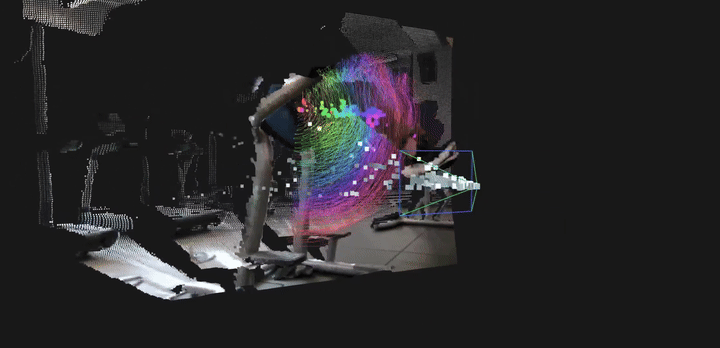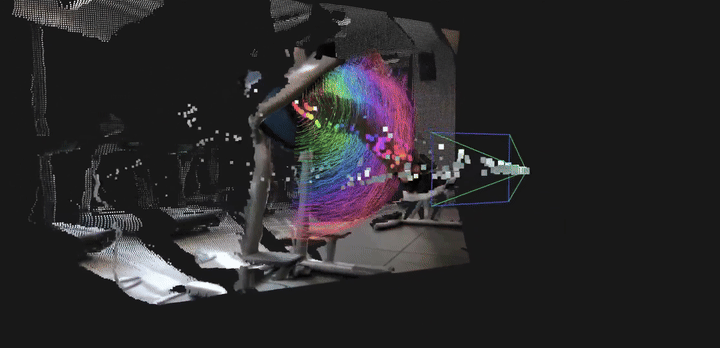


LingBot-Depth 为下游空间感知任务提供了坚实而通用的基础能力。通过将含噪且不完整的传感器深度优化为干净、稠密且具备真实尺度的三维测量结果,模型显著提升了多种高层视觉任务的稳定性与精度。具体而言,LingBot-Depth 支持:(1)更加准确的结构化室内场景建图,并有效提升相机位姿与运动轨迹估计的精度;(2)面向机器人学习的可靠 4D 点跟踪能力,在统一的真实尺度空间中同时刻画静态场景几何结构与动态物体运动。这使得系统能够在复杂真实环境中建立一致、连续且可用于决策与交互的空间理解表征。
灵巧抓取操作适用于透明与反光物体





通过在统一潜在空间中联合对齐 RGB 外观信息与深度几何结构,LingBot-Depth 使机器人在以往难以处理的复杂场景中实现稳定可靠的操作能力。基于模型优化后的高质量深度结果及跨模态对齐特征,我们进一步训练了一种基于扩散模型的抓取位姿生成策略,在透明杯、反光金属容器等具有挑战性的物体上取得了较高的抓取成功率,而在这些场景中原始传感器深度往往完全失效。
真机 Scaling Law

现有基于双目的深度相机工作方式类似人眼:两个镜头从略有差异的视角同时拍摄场景,系统通过匹配两幅图像中的对应点来计算深度。然而,这种方法存在先天缺陷——在纹理缺失区域、透明材质(如玻璃)或强反光表面(如镜子和金属)上,匹配算法往往失效,因为两路图像要么过于相似、要么发生严重畸变。结果就是:恰恰在最需要深度信息的地方,传感器反而输出空洞或错误数据。
我们的方法称为掩码深度建模(Masked Depth Modeling, MDM)。训练过程中,我们使用海量 RGB–深度图像对,但刻意遮挡其中一部分深度区域,让模型仅根据 RGB 图像去预测缺失的深度值。随着训练进行,模型逐渐学会建立“外观—几何”之间的对应关系,也就是从“物体看起来像什么”推断“它大概有多远”。
核心洞察在于:传感器失效并非随机噪声,而是在特定材质与光照条件下可预测地发生。因此,我们不再将这些区域简单视为需要滤除的坏数据,而是把它们当作有价值的学习信号。模型会逐渐掌握这样的规律:“当我看到这种类似玻璃的外观和反射模式时,对应的深度大致应落在这个范围。”
在涵盖家庭、办公环境、健身房及户外场景的上千万张图像数据上完成训练后,LingBot-Depth 已能够对受损深度图进行智能补全,填补空洞区域,并生成在几何上合理、物理上可信的深度结果。
- 把传感器深度失效视为掩码:一种自然的掩码深度建模机制
我们将原始深度图中的固有缺损不再视为噪声,而是重新诠释为揭示几何歧义的"自然掩码"信号。基于这一洞察,我们提出了一种新颖的RGB-D掩码自编码器(RGBD-MAE):模型接收完整的RGB token与仅有的有效原始深度token,学习基于视觉上下文预测缺失区域的深度信息。
- 针对MDM的大规模数据采集管线
我们构建了一套可扩展的数据整理与筛选流程,结合真实采集与高逼真模拟数据,共收集 300 万对 RGB–深度图像(其中 200 万为真实数据,100 万为合成数据)。真实数据覆盖家庭、办公室、健身房、大堂及户外等多种环境,使用多款主流商用深度相机采集。合成数据流程则渲染具备照片级真实感的场景,并模拟双目匹配伪影,从而逼真复现真实传感器的典型失效模式。在监督信号构建方面,我们为真实数据通过双目红外图像对计算高精度深度,为合成数据直接采用无误差的渲染深度作为真值,从而在传感器通常失效的区域仍能提供干净、可靠的监督目标。
- 显式几何与隐式特征表征的双重对齐
LingBot-Depth 学习到一个统一的潜在空间,使 RGB 外观信息与深度几何结构实现紧密耦合。模型不仅能够输出具备真实尺度的高精度深度图(显式几何),还可生成在不同模态间对齐的特征表示(隐式表征)。这种双重对齐机制为多种下游应用提供了强大支撑:显式深度信息可直接服务于机器人操作与抓取等任务,而跨模态对齐的特征表示则有助于三维点跟踪、场景理解等更高层次的空间感知任务。
模型测评结果

深度补全(Depth Completion)
- 在 iBims、NYUv2、DIODE、ETH3D 等标准基准上,相比现有最佳方法实现 40–50% 的误差降低
- 在稀疏 SfM 输入条件下,室内场景 RMSE 降低 47%,室外场景降低 38%
- 在从轻度到极端损坏的不同难度设置下均保持稳定领先表现
超越工业级硬件
- 在复杂场景中生成比 ZED 双目相机更完整且更精确的深度结果
- 在结构光和双目系统同时失效的区域(如玻璃幕墙、镜面、水族馆通道)成功补全深度空洞
- 在无需显式时序建模的情况下保持视频帧间的时间一致性
机器人操作能力
- 使以往无法抓取的物体成为可能——透明收纳箱抓取成功率从 0% 提升至 50%
- 在多种反光和透明物体上提升 30–78% 的抓取成功率
- 钢杯:65% → 85%,玻璃杯:60% → 80%,玩具车:45% → 80%
基础模型能力(Foundation Model)
- 作为单目深度估计的优质预训练骨干,在 10 项基准上优于 DINOv2
- 加速双目匹配模型训练——FoundationStereo 在采用本模型初始化后收敛更快
- 对齐的 RGB–深度特征支持下游 3D/4D 跟踪任务,且无需针对具体任务进行微调
应用场景


在百舸平台上快速开始
部署环境要求
| 部署要求 | 最佳实践 | |
|---|---|---|
| CPU | 4核 | 建议按表单默认值及以上 |
| 内存 | 16G | 建议按表单默认值及以上 |
| GPU | 按需 | A10/A100/V100/L20等至少一张 |
| CDS | 按需 | 建议存储资源>50G |
| 其它 | 无 | 无 |
镜像
请使用百舸官方镜像:ccr-2hpgw1bh-pub.cnc.bj.baidubce.com/aihc-private/lingbot-depth:v0.5
本镜像使用基础镜像:registry.baidubce.com/inference/aibox-cuda:v2.0-cu12.9-cudnn9-ubuntu22.04进行封装
如果不使用本示例提供的lingbot-depth:v0.5镜像,安装方法参考下文【依赖配置过程参考】
依赖配置过程参考(镜像中已完成配置)
1git clone https://github.com/robbyant/lingbot-depth
2cd lingbot-depth
3# 安装包(使用 'python -m pip' 确保使用正确环境)
4conda create -n lingbot-depth python=3.9
5conda activate lingbot-depth
6python -m pip install -e .快速开始
推理示例:
1import torch
2import cv2
3import numpy as np
4from mdm.model.v2 import MDMModel
5
6# 加载模型
7device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
8model = MDMModel.from_pretrained('robbyant/lingbot-depth-pretrain-vitl-14-v0.5').to(device)
9
10# 加载并准备输入
11image = cv2.cvtColor(cv2.imread('examples/0/rgb.png'), cv2.COLOR_BGR2RGB)
12h, w = image.shape[:2]
13image = torch.tensor(image / 255, dtype=torch.float32, device=device).permute(2, 0, 1)[None]
14depth = cv2.imread('examples/0/raw_depth.png', cv2.IMREAD_UNCHANGED).astype(np.float32) / 1000.0
15depth = torch.tensor(depth, dtype=torch.float32, device=device)[None]
16intrinsics = np.loadtxt('examples/0/intrinsics.txt')
17intrinsics[0] /= w # 按宽度归一化 fx 和 cx
18intrinsics[1] /= h # 按高度归一化 fy 和 cy
19intrinsics = torch.tensor(intrinsics, dtype=torch.float32, device=device)[None]
20
21# 执行推理
22output = model.infer(image, depth_in=depth, intrinsics=intrinsics)
23depth_pred = output['depth'] # 精化后的深度图
24points = output['points'] # 三维点云运行示例:模型首次运行时将自动从 Hugging Face 下载(无需手动下载):
1# 基本用法 - 处理示例 0
2python example.py
3# 使用不同的示例(可选 0-7)
4python example.py --example 1
5# 使用深度补全优化模型
6python example.py --model robbyant/lingbot-depth-postrain-dc-vitl14-v0.5
7# 自定义输出目录
8python example.py --output my_results
9# 查看所有选项
10python example.py --help处理结果包含:
rgb.png(输入图像)、depth_input.npy(输入深度,float32,米)、depth_refined.npy(精化深度,float32,米)、depth_input.png(输入深度可视化)、depth_refined.png(精化深度可视化)、depth_comparison.png(对比图)、point_cloud.ply(三维点云)。
examples/ 目录中内置 8 组示例场景(0-7)。
处理结果将被保存到/results文件夹下(或者其他用户指定的文件夹)
1result/
2├── rgb.png # Input RGB image
3├── depth_input.npy # Input depth (float32, meters)
4├── depth_refined.npy # Refined depth (float32, meters)
5├── depth_input.png # Input depth visualization
6├── depth_refined.png # Refined depth visualization
7├── depth_comparison.png # Side-by-side comparison
8└── point_cloud.ply # 3D point cloud模型详情
架构
- 编码器:带 RGB-D 融合的视觉 Transformer(Large)
- 解码器:多尺度特征金字塔,包含专用预测头
- 预测头:深度回归
- 训练方式:带重建目标的遮蔽深度建模
输入格式
RGB 图像
- 形状:
[B, 3, H, W],归一化至[0, 1] - 格式:PyTorch 张量,float32
深度图
- 形状:
[B, H, W] - 单位:米(可通过
scale参数配置) - 无效区域:值为
0或NaN
相机内参
- 形状:
[B, 3, 3] - 格式:归一化格式,
fx'=fx/W,fy'=fy/H,cx'=cx/W,cy'=cy/H
示例:
1[[fx/W, 0, cx/W],
2 [ 0, fy/H, cy/H],
3 [ 0, 0, 1 ]]输出格式
模型返回一个字典:
1{
2 'depth': torch.Tensor, # 精化后的深度图 [B, H, W]
3 'points': torch.Tensor, # 点云 [B, H, W, 3],相机坐标系
4}推理参数
1model.infer(
2 image, # RGB 张量 [B, 3, H, W]
3 depth_in=None, # 输入深度图 [B, H, W]
4 use_fp16=True, # 混合精度推理
5 intrinsics=None # 相机内参 [B, 3, 3]
6)评价此篇文章