
在百舸平台部署Llama-4推理服务
更新时间:2025-04-15
Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型。Llama 4 模型还针对视觉识别、图像推理、字幕生成以及回答关于图像的问题进行了优化。本文将指导您如何在百舸平台部署Llama-4模型。
前置条件
准备资源
- 购买1台H20机器并创建资源池(H20需要开通白名单,请联系百度售前工程师);
- 开通存储产品,PFS、CFS或BOS,PFS需与资源池绑定。
准备模型文件
平台已提供 Llama-4-Scout-17B-16E-Instruct 模型权重文件存储在BOS对象存储中,您可以从BOS下载模型。
- 登录节点安装BOSCMD https://cloud.baidu.com/doc/BOS/s/qjwvyqegc 并完成BOSCMD配置置 https://cloud.baidu.com/doc/BOS/s/Ejwvyqe55
- 从平台提供的BOS地址中拷贝权重文件到PFS存储中:
Plain Text
1./bcecmd bos sync bos:/aihc-models-bj/meta-llama/Llama-4-Scout-17B-16E-Instruct部署服务
- 登录百舸异构计算平台,在左侧导航中选择 在线服务部署 部署自定义服务;
- 进入自定义部署页面点击 部署服务,填写部署服务的相关参数;
- 资源申请中的加速芯片卡数设置为8;
- 服务镜像选择 CCR企业版镜像>百舸预置镜像 平台提供vLLM镜像 vllm-openai v0.8.3
- 设置端口及流量接入,填写调用时的服务访问端口,如需公网访问请开启公网开关,默认仅支持VPC内调用
- 设置存储挂载
源路径填写存储模型权重文件的CFS、PFS或BOS路径,如无特殊需求目标路径可填写为 /mnt/model;
- 设置启动命令
PATH_TO_MODEL替换为容器目标路径; PORT替换为服务端口
Plain Text
1VLLM_DISABLE_COMPILE_CACHE=1 vllm serve PATH_TO_MODEL --host 0.0.0.0 --port PORT --tensor-parallel-size 8 --max-model-len 262144 --trust-remote-code --override-generation-config='{"attn_temperature_tuning": true}' --served-model-name Llama-4-Scount-17B-16E-Instruct8.部署服务,等待服务状态为“运行中”即可调用。
调用模型服务
在服务详情中查看访问地址和服务端口
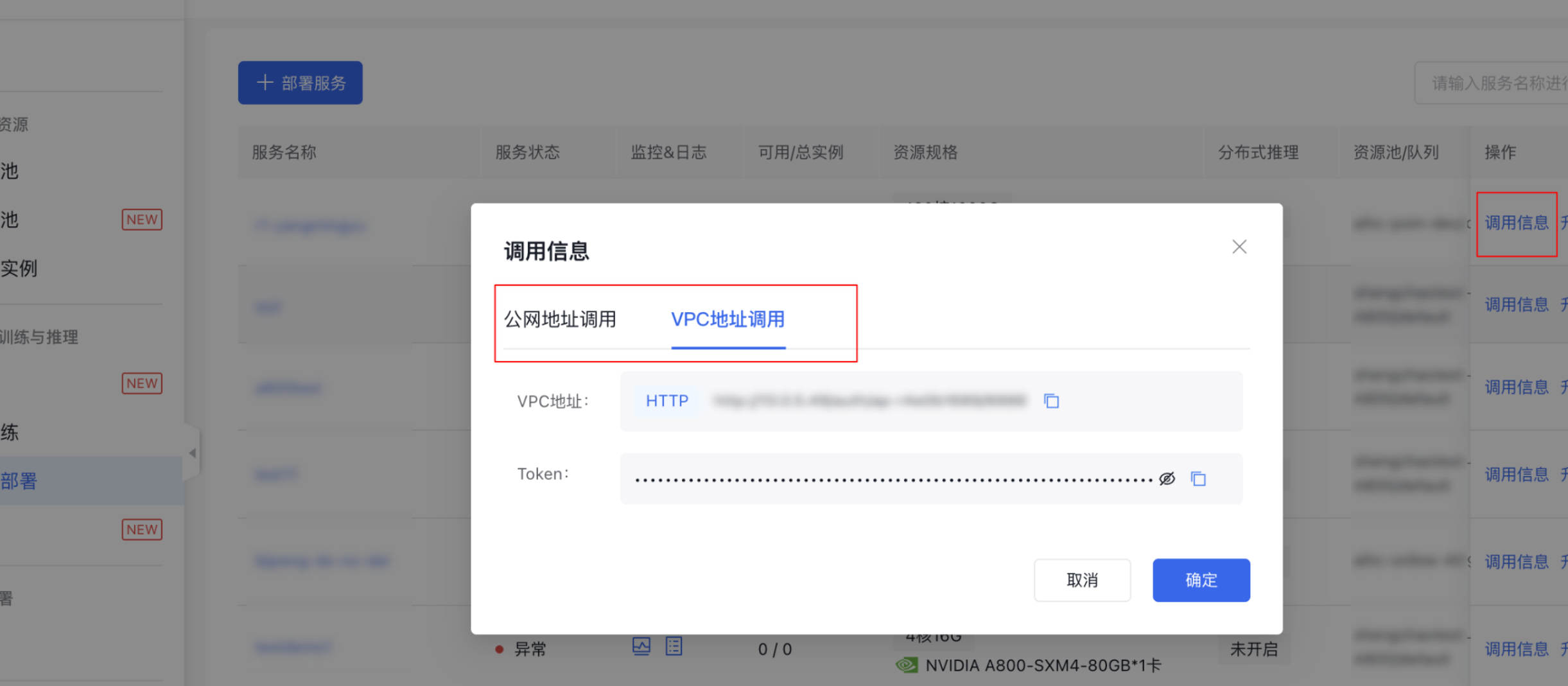
请求示例
Plain Text
1curl --location '<访问地址>/v1/chat/completions' \
2--header 'Content-Type: application/json' \
3--header 'Authorization: <TOKEN>' \
4--data '{
5 "model": "Llama-4-Scount-17B-16E-Instruct",
6 "messages": [{"role": "system", "content": "你是一名天文学家,请回答用户提出的问题。"}, {"role": "user", "content": "人类是否能登上火星?"}, {"role": "assistant", "content": "目前来看,人类登上火星是完全可能的..."}],
7 "max_tokens": 1024,
8 "temperature": 0
9}'评价此篇文章