
BEVFormer-加速版
更新时间:2026-05-09
模型介绍
BEVFusion是一个高效且通用的多任务多传感器融合模型,用于自动驾驶的3D感知。通过统一的鸟瞰图表示,它保留了几何信息和语义信息,解决了点级融合方法的局限性。
详细图文介绍:
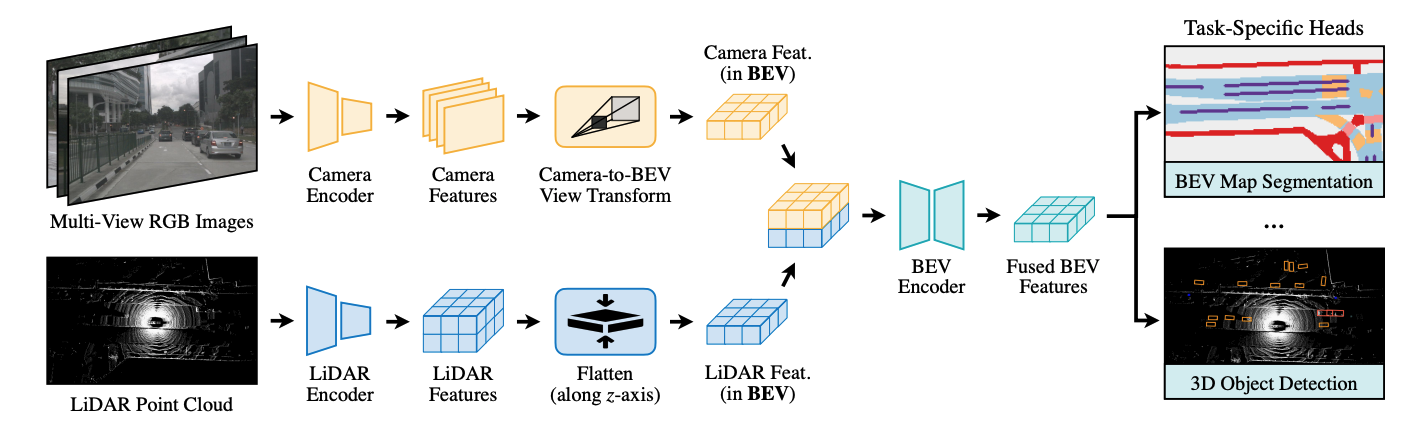
多传感器融合对于构建准确可靠的自动驾驶系统至关重要。近期的大部分方法是基于point-level的融合:使用图像特征增强LiDAR点云表示。然而,图像到LiDAR的映射舍弃了图像特征的语义密度,限制了这种方法的有效性,尤其是对于语义导向的任务(如3D场景分割)。BEVFusion提出一种高效且通用的多任务多传感器融合框架。它将多模态特征统一映射到鸟瞰视图(BEV)表示空间中,很好地保留了几何和语义信息。为实现这一目标,BEVFusion解决了视图转换中的关键效率瓶颈,通过优化的BEV pooling,将延迟降低了40倍以上。BEVFusion基本上是任务无感知的,几乎不需要进行架构改变就能无缝支持不同的3D感知任务。
部署环境要求&最佳实践建议
| 部署要求 | 最佳实践 | |
|---|---|---|
| CPU | 按需 | 建议按表单默认值及以上 |
| 内存 | 按需 | 建议按表单默认值及以上 |
| GPU | 1~8卡 H20/RTX 5090 | 建议8卡 H20/RTX 5090 |
| CDS | 按需 | 按需 |
| 其它 | 如果更改了默认的数据集、存储挂载地址、代码地址,需要同时更改对应的脚本配置 | 若想获得最佳训练性能,建议将预置数据转储至PFS或CFS,转储方式见文末 |
使用说明
1. 创建与登录开发机
根据部署环境要求成功创建开发机后,点击登录开发机,进入开发机webIDE,并打开VScode中的terminal

- 代码保存路径:/root/workspace/mmdetection3d
- 数据默认挂载路径:/mnt/dataset/autodrive
- 虚拟环境名:bevfusion
2. 启动训练
- 在试用案例之前,请确保已挂载了案例所需的数据集,否则脚本无法正常运行,可在脚本内更改数据集地址配置
- 若想获得最佳训练性能,建议将预置数据转储至PFS或CFS,转储方式见文末
2.1 一键启动训练
可以通过脚本,一键启动(单机or多机)快速训练。
Bash
1# 设置数据路径,nuscenes数据默认路径/mnt/dataset/autodrive
2export DATA_PATH=/mnt/dataset/autodrive
3# 设置训练配置文件,默认使用lidar+camera配置
4export CONFIG=projects/BEVFusion/configs/bevfusion_lidar-cam_voxel0075_second_secfpn_8xb4-cyclic-20e_nus-3d.py
5# 设置训练使用gpu卡数,默认使用全部gpu
6export GPUS=$(nvidia-smi --query-gpu=gpu_name --format=csv,noheader | wc -l)
7# 设置训练结果保存路径,默认/root/workspace/mmdetection3d/work_dir
8export WORK_DIR=/root/workspace/mmdetection3d/work_dir
9
10source /root/env_bevfusion.sh
11
12export PYTHONPATH=/root/workspace/mmdetection3d:$PYTHONPATH
13cd /root/workspace/mmdetection3d && \
14rm -rf ./data && ln -sf $DATA_PATH ./data
15
16NNODES=${WORLD_SIZE:-1}
17NODE_RANK=${RANK:-0}
18PORT=${MASTER_PORT:-29600}
19MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
20# 默认使用预训练模型进行训练
21python3 -m torch.distributed.launch \
22 --nnodes=$NNODES \
23 --node_rank=$NODE_RANK \
24 --master_addr=$MASTER_ADDR \
25 --nproc_per_node=$GPUS \
26 --master_port=$PORT \
27 tools/train.py \
28 $CONFIG \
29 --cfg-options load_from=pretrained/bevfusion_lidar_voxel0075_second_secfpn_8xb4-cyclic-20e_nus-3d-2628f933.pth \
30 --cfg-options model.img_backbone.init_cfg.checkpoint=pretrained/swint-nuimages-pretrained.pth \
31 --launcher pytorch ${@:3} 2>&1 | tee output.log2.2. 分步训练
分步进行训练任务,可以自定义训练相关参数信息。
2.2.1. 在环境变量中设置相关参数
若不修改默认配置,可跳过此步骤
Bash
1# 设置数据路径,nuscenes数据默认路径/mnt/dataset/autodrive
2export DATA_PATH=/mnt/dataset/autodrive
3# 设置训练配置文件,默认使用lidar+camera配置
4export CONFIG=projects/BEVFusion/configs/bevfusion_lidar-cam_voxel0075_second_secfpn_8xb4-cyclic-20e_nus-3d.py
5# 设置训练使用gpu卡数,默认使用全部gpu
6export GPUS=$(nvidia-smi --query-gpu=gpu_name --format=csv,noheader | wc -l)
7# 设置训练结果保存路径,默认/root/workspace/mmdetection3d/work_dir
8export WORK_DIR=/root/workspace/mmdetection3d/work_dir2.2.2. 激活模型运行虚拟环境
Bash
1source /root/env_bevfusion.sh2.2.3. 启动模型训练
Bash
1export PYTHONPATH=/root/workspace/mmdetection3d:$PYTHONPATH
2cd /root/workspace/mmdetection3d && \
3rm -rf ./data && ln -sf $DATA_PATH ./data
4
5NNODES=${WORLD_SIZE:-1}
6NODE_RANK=${RANK:-0}
7PORT=${MASTER_PORT:-29600}
8MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
9# 默认使用预训练模型进行训练
10python3 -m torch.distributed.launch \
11 --nnodes=$NNODES \
12 --node_rank=$NODE_RANK \
13 --master_addr=$MASTER_ADDR \
14 --nproc_per_node=$GPUS \
15 --master_port=$PORT \
16 tools/train.py \
17 $CONFIG \
18 --cfg-options load_from=pretrained/bevfusion_lidar_voxel0075_second_secfpn_8xb4-cyclic-20e_nus-3d-2628f933.pth \
19 --cfg-options model.img_backbone.init_cfg.checkpoint=pretrained/swint-nuimages-pretrained.pth \
20 --launcher pytorch ${@:3} 2>&1 | tee output.log3. 查看训练结果
训练结果保存在$WORK_DIR下,包含训练日志以及模型权重文件,使用其他保存路径可以修改环境变量$WORK_DIR。
Bash
1# 设置训练结果保存路径,默认/root/workspace/mmdetection3d/work_dir
2export WORK_DIR=/root/workspace/mmdetection3d/work_dir可在路径下查看:
- 完整训练日志: output.log
- 最终模型权重:latest.pth
附: BOS数据转储PFS方式
- 挂载PFS或CFS
可以在创建或者更新开发机配置时,选择存储挂载,选择集群对应的PFS或者CFS,可自定义挂载路径

- 将预置数据(BOS)拷贝到对应的PFS或CFS路径
Bash
1#命令格式 cp -rv 源路径 目标路径
2cp -rv bos路径 PFS或CFS路径
3#命令示例 假设bos挂载地址为/mnt/dataset/autodrive PFS挂载地址为/mnt/pfs/urvmsq
4cp -rv /mnt/dataset/autodrive/ /mnt/pfs/urvmsq/- 转储后,需要更改配置里的数据集变量DATA_PATH地址为/mnt/pfs/urvmsq/autodrive/文件夹
评价此篇文章