
快速部署AI绘画SDWebUI
更新时间:2025-11-24
Stable Diffusion是强大的图像生成模型,能够生成高质量、高分辨率的图像,并具有良好的稳定性和可控性。百舸的工具市场预置了Stable-Diffusion-WebUI镜像模板,您可以使用该模板快速搭建基于AIGC Stable Diffusion SDWebUI的AI-Web工具。使用该工具进行模型推理,实现基于给定文本生成相应图像的功能。
准备环境和资源
可根据资源规模、稳定性、灵活性等要求按需准备轻量计算实例或通用计算资源池,用于快速部署SDWebUI
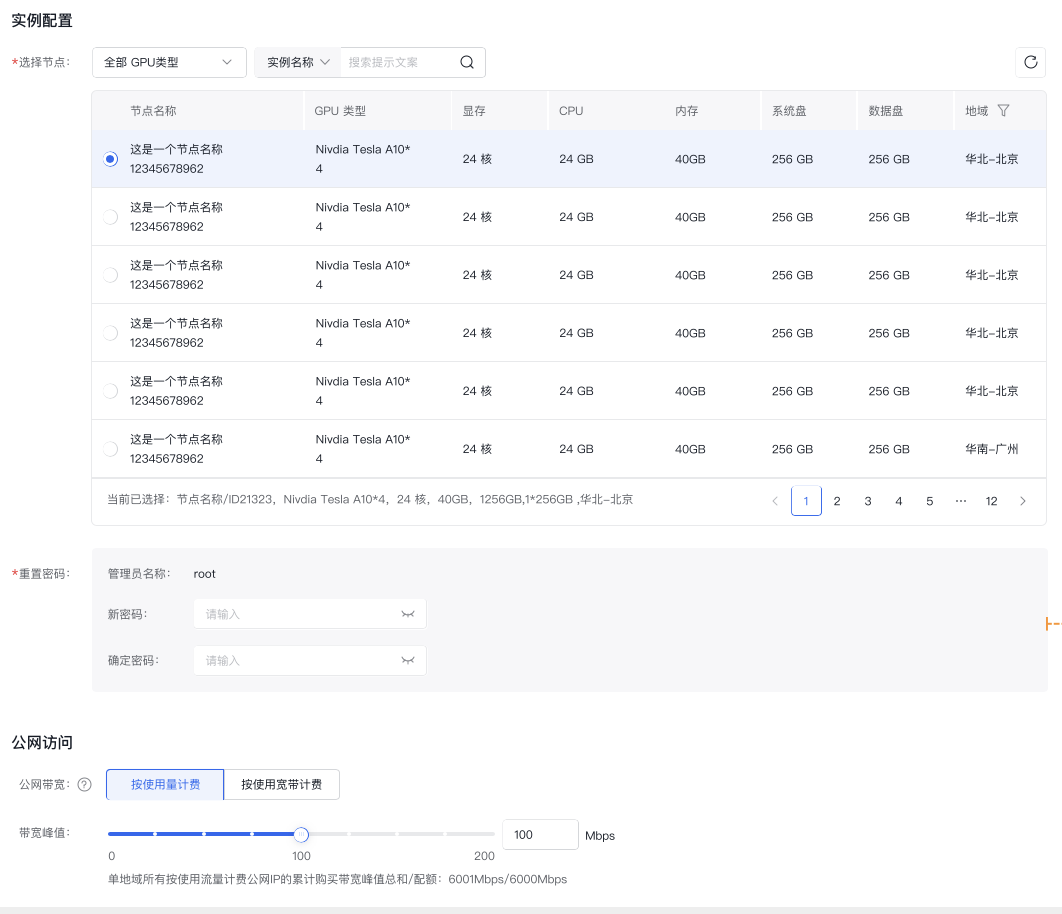
安装SDWebUI
- 在 工具市场>模版市场 中选择SDWebUI模版,点击 部署工具 按钮,快速部署SDWebUI;

- 选择为部署工具所需的实例规格和卡数;
- 完成配置后点击部署,当工具状态从创建中变为运行中,表明工具已部署成功。
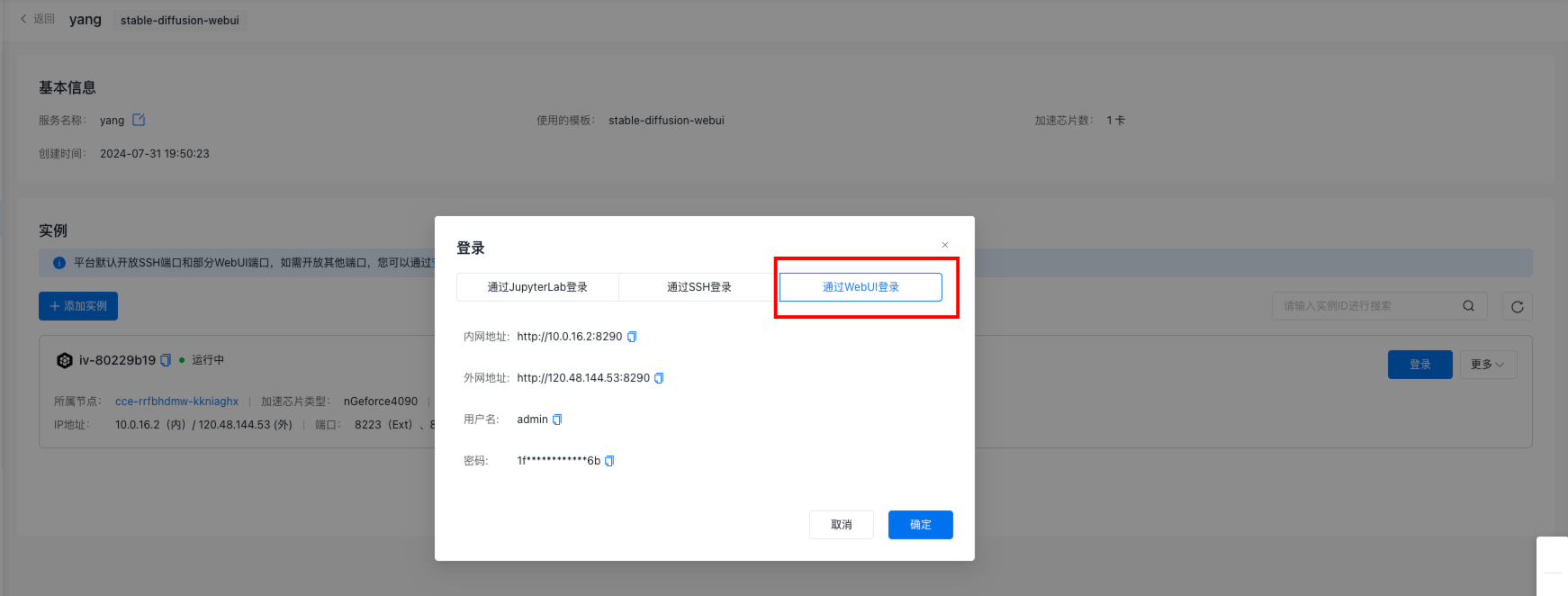
访问SDWebUI
- 工具部署成功后,您可以查看工具详情,单击 登录 查看WebUI的访问地址和用户名、密码。
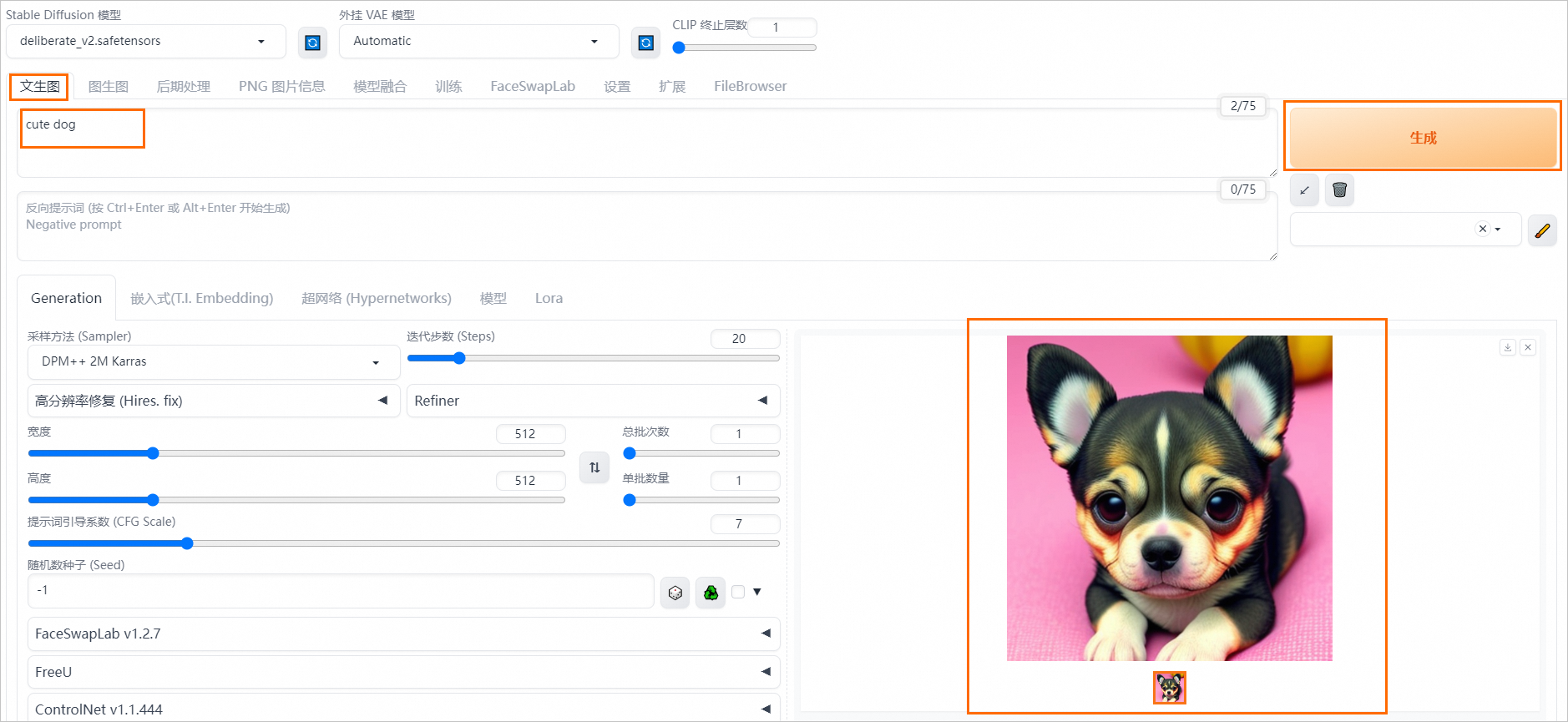
- 进行模型推理验证。在Stable Diffusion WebUI页面文生图页签中,输入正向提示词Prompt,例如
cute dog,然后单击 生成,即可完成AI绘图,效果图如下:
模型选择和下载
- 模型下载
平台内置基础模型,可以满足基础的图片生成需求。若您对推理效果和质量有更高要求,可以在 https://huggingface.co/ 或 https://civitai.com/ 搜索和下载。 SD 上常用的模型分为几类:
- Checkpoint 用于生成图片,体积一般较大,放置于 stable-diffusion-webui/models/Stable-diffusion 内。
- Lora 一般用于在生成图片的基础上固定风格或动作,放置于 stable-diffusion-webui/models/Lora 内。
- VAE VAE模型类似滤镜,对画面进行调色与微调,一般需要搭配相应的模型一起使用。目前大部分 Checkpoint 都已不需要额外添加 VAE 模型。放置于 stable-diffusion-webui/models/VAE内。
- Textual inversion(embedding) 关键词预设模型,即关键词打包,即等于预设好一篮子关键词a,b,c打包,进而来指代特定的对象/风格。也可以通过下载Textual inversion进行使用。可放置于 stable-diffusion-webui/embeddings 内。
- 通过 JupyterLab 上传模型 平台为每个工具内置了JupyterLab,您可以通过JupyterLab 上传模型;单击 登录 查看JupyterLab访问地址,登录JupyterLab。
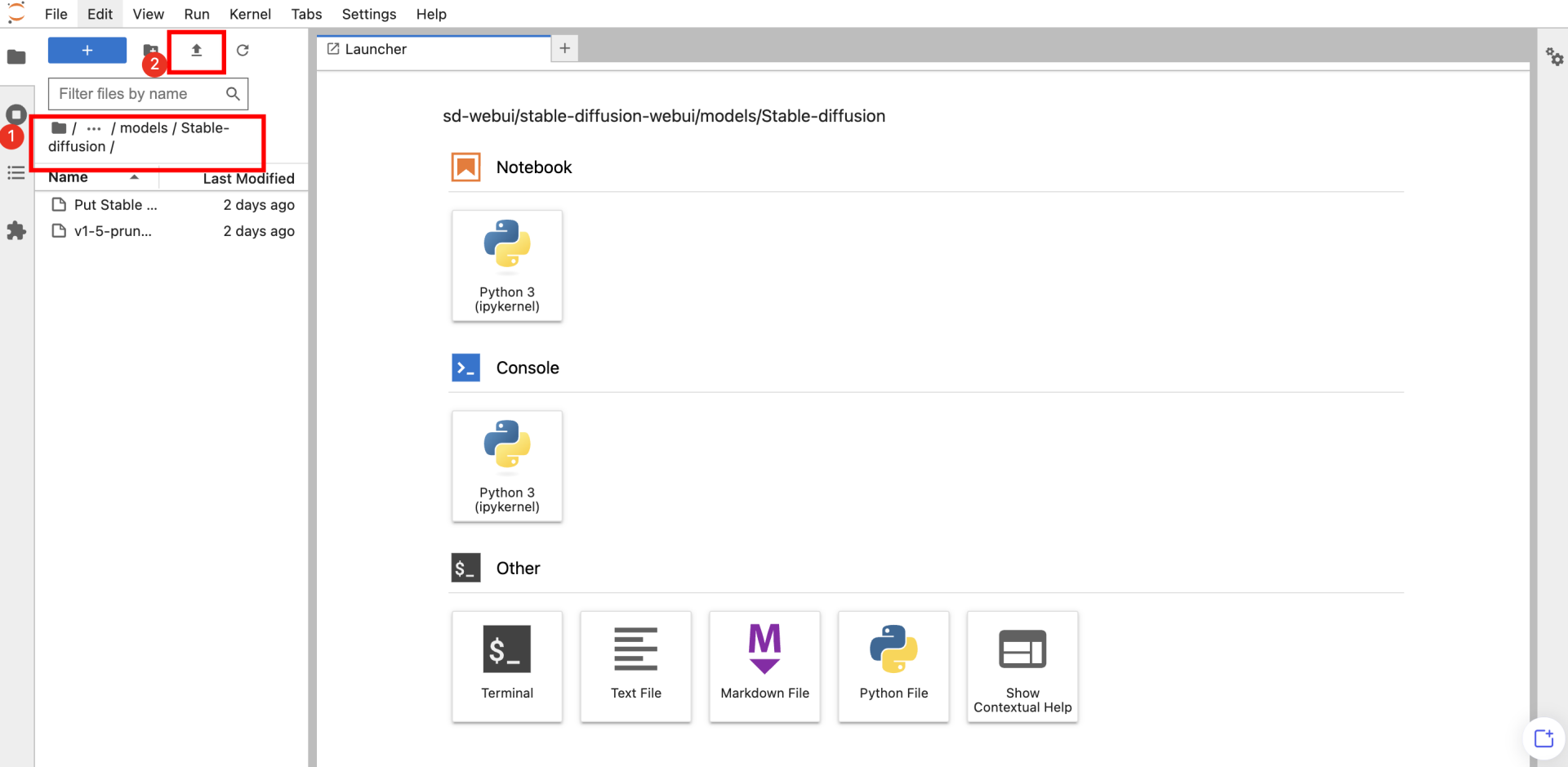 选择/sd-webui/stable-diffusion-webui/models/Stable-diffusion/路径,上传模型。
选择/sd-webui/stable-diffusion-webui/models/Stable-diffusion/路径,上传模型。
- 使用模型
在此下拉框中切换上传的模型,使用模型生成图片。
安装插件实现增强功能
您可以为Stable Diffusion WebUI配置插件,以实现更加多样化的功能。平台内置了基础插件,您可以在WebUI页面的扩展页签中,查看并安装插件。
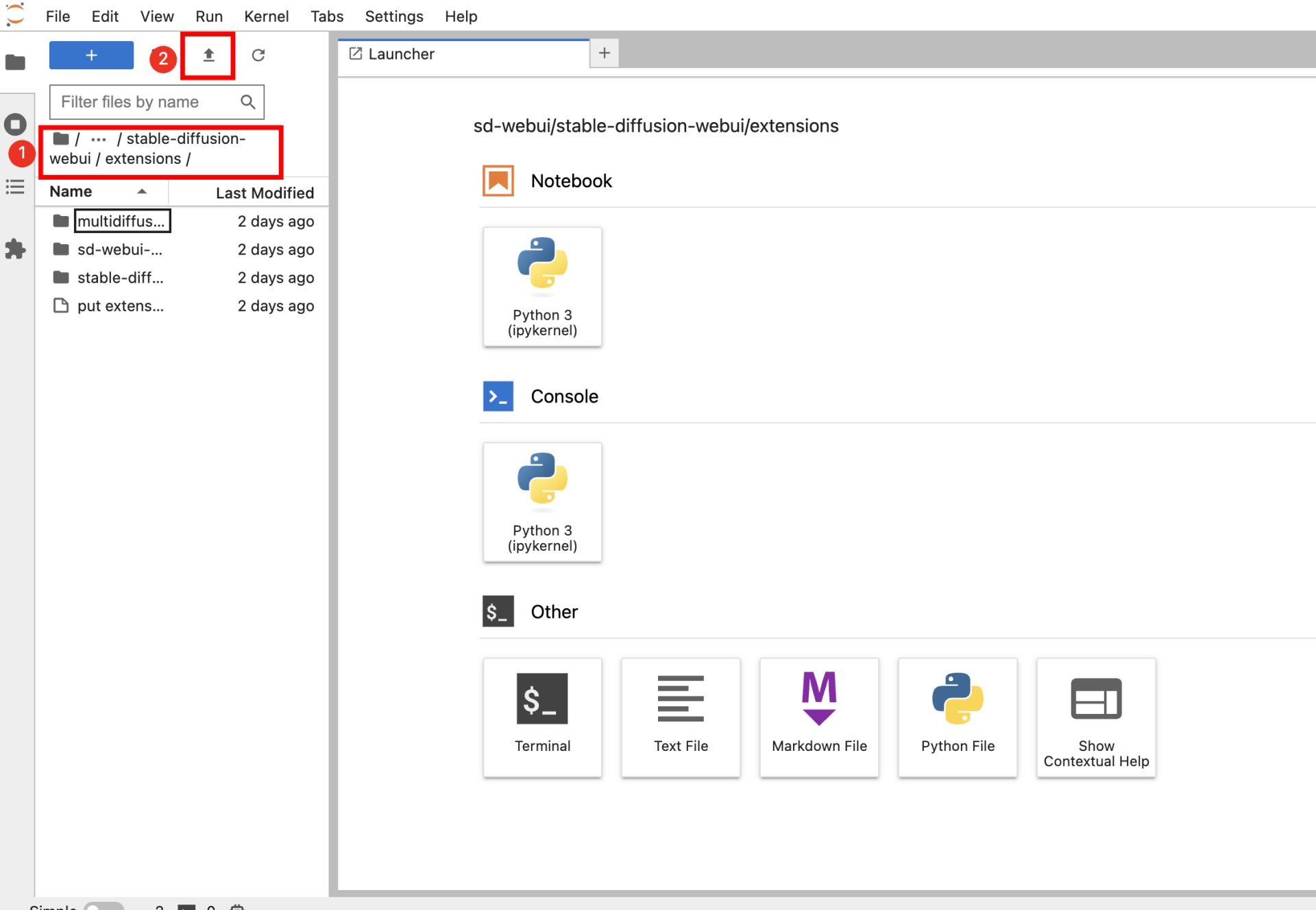
通过 JupyterLab 上传插件,将插件存储到 /sd-webui/stable-diffusion-webui/extensions/路径。
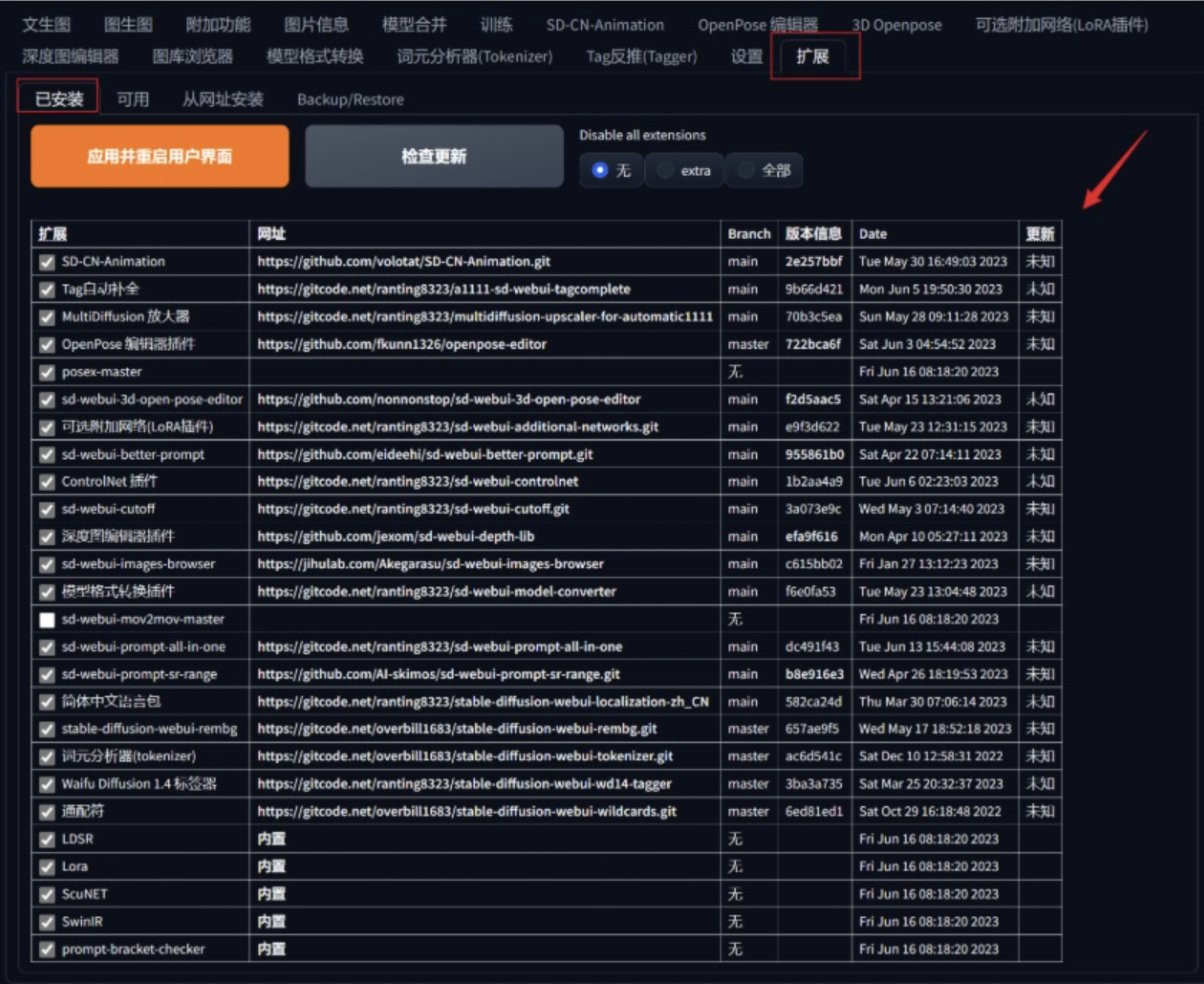
 插件安装后,在WebUI页面中的扩展页签下,可以在WebUI中查看已安装的插件,选中需要应用的插件,并单击 应用更改并重载前端,来重新加载插件。在应用插件时,WebUI页面将会自动重启,待重新加载完成后即可进行推理验证。
插件安装后,在WebUI页面中的扩展页签下,可以在WebUI中查看已安装的插件,选中需要应用的插件,并单击 应用更改并重载前端,来重新加载插件。在应用插件时,WebUI页面将会自动重启,待重新加载完成后即可进行推理验证。
评价此篇文章