
Qwen3-Next-80B-A3B-Thinking
更新时间:2026-03-04
Qwen3-Next-80B-A3B-Thinking 是通义千问团队发布的 Qwen3-Next 系列首个版本。性能表现接近参数规模更为庞大的Qwen3-235B。
模型介绍
Qwen3-Next-80B-A3B-Thinking 是 Qwen3-Next 系列的首个版本,具有以下关键增强特性。
核心技术增强
- 混合注意力机制:采用门控DeltaNet与门控注意力的组合架构,替代标准注意力机制,实现对超长上下文的高效建模
- 高稀疏性混合专家系统:在MoE层实现极低的激活比例,在保持模型容量的同时显著降低每个token的浮点运算量
- 稳定性优化:包含零中心化权重衰减层归一化及其他稳定性增强技术,确保预训练与后训练的稳健性
- 多Token预测:提升预训练模型性能并加速推理过程
性能表现
Qwen3-Next-80B-A3B 在参数效率和推理速度方面均展现出卓越性能:
- Qwen3-Next-80B-A3B-Base 在下游任务中表现超越 Qwen3-32B-Base,总训练成本降低10%,在超过32K Token的上下文场景中推理吞吐量提升10倍
- 利用 GSPO,解决了混合注意力机制与高稀疏度 MoE 架构结合在 RL 训练中的稳定性和效率挑战。 Qwen3-Next-80B-A3B-Thinking 在复杂的推理任务上表现出色,不仅超越了 Qwen3-30B-A3B-Thinking-2507 和 Qwen3-32B-Thinking,而且在多个基准测试中优于专有模型 Gemini-2.5-Flash-Thinking。
模型架构详情
Qwen3-Next-80B-A3B-Thinking 仅支持思考模式。 为了强制模型进行思考,默认聊天模板自动包含 <think>。
Qwen3-Next-80B-A3B-Thinking 可能会生成比其前身有更长的思考内容,强烈建议将其用于高度复杂的推理任务。

API调用
- 服务部署成功后,可在服务列表查看调用信息
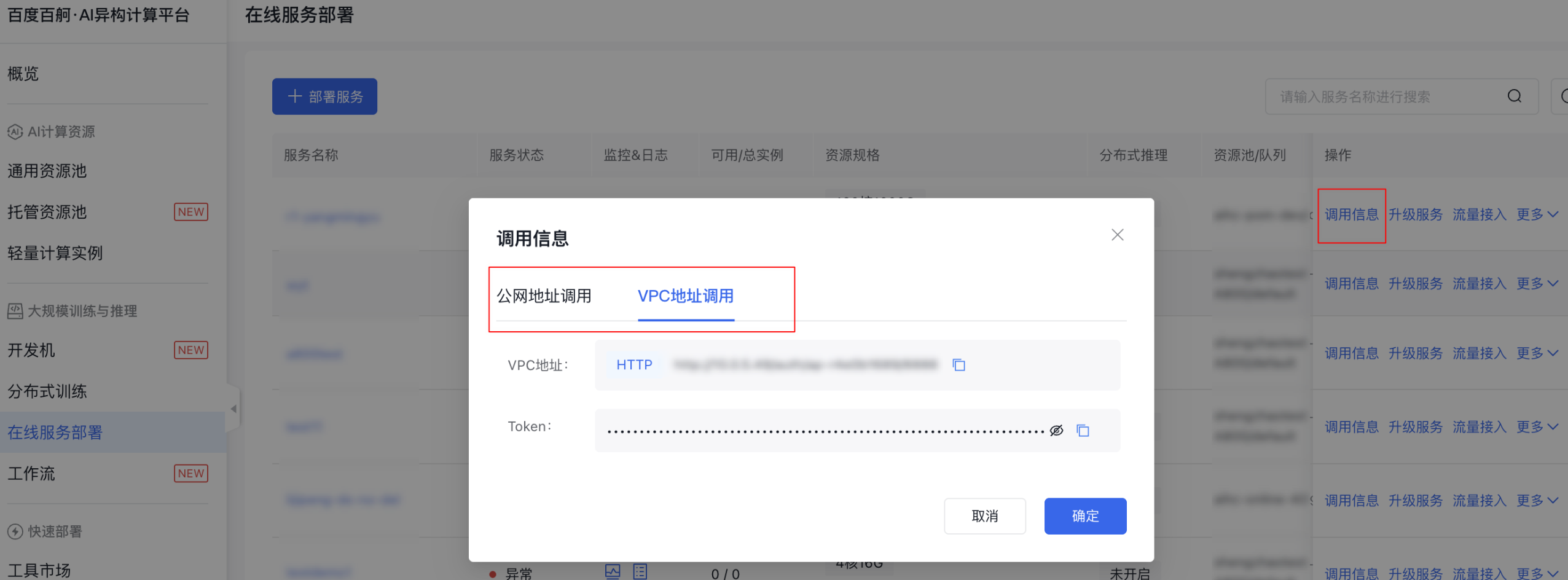
- 调用示例
Plain Text
1curl -X POST "<访问地址>/v1/chat/completions" \
2-H "Content-Type: application/json" \
3-H "Authorization: Bearer <TOKEN>" \
4-d '{
5 "model": "Qwen3-Next-80B-A3B-Thinking",
6 "messages": [{"role": "system", "content": "你是一名天文学家,请回答用户提出的问题。"}, {"role": "user", "content": "人类是否能登上火星?"}],
7 "max_tokens": 1024,
8 "temperature": 0.7
9}'评价此篇文章