
MiMo-V2-Flash
更新时间:2026-04-02
模型介绍
MiMo-V2-Flash 是一个混合专家(Mixture-of-Experts, MoE)语言模型,总参数量为 3090 亿,激活参数量为 150 亿。该模型专为高速推理和智能体工作流设计,采用了一种新颖的混合注意力架构和多词元预测(Multi-Token Prediction, MTP),在显著降低推理成本的同时实现了业界领先的性能。
主要特性
MiMo-V2-Flash 在长上下文建模能力和推理效率之间实现了新的平衡。其主要特性包括:
- 混合注意力架构:以 5:1 的比例交错使用滑动窗口注意力(Sliding Window Attention, SWA)和全局注意力(Global Attention, GA),并采用激进的 128 词元窗口。这使 KV 缓存存储需求减少了近 6 倍,同时通过可学习的 注意力汇聚偏置(attention sink bias) 保持了长上下文性能。
- 多词元预测(MTP):配备轻量级 MTP 模块(每层 0.33B 参数),使用密集前馈网络(FFN)。这使推理时的输出速度提升三倍,并有助于加速强化学习(RL)训练中的 rollout 过程。
- 高效预训练:使用 FP8 混合精度和原生 32k 序列长度,在 27T 词元上完成训练。上下文窗口最大支持 256k 长度。
- 智能体能力:后训练阶段采用多教师在线策略蒸馏(Multi-Teacher On-Policy Distillation, MOPD)和大规模智能体强化学习,在 SWE-Bench 和复杂推理任务上表现卓越。
模型架构
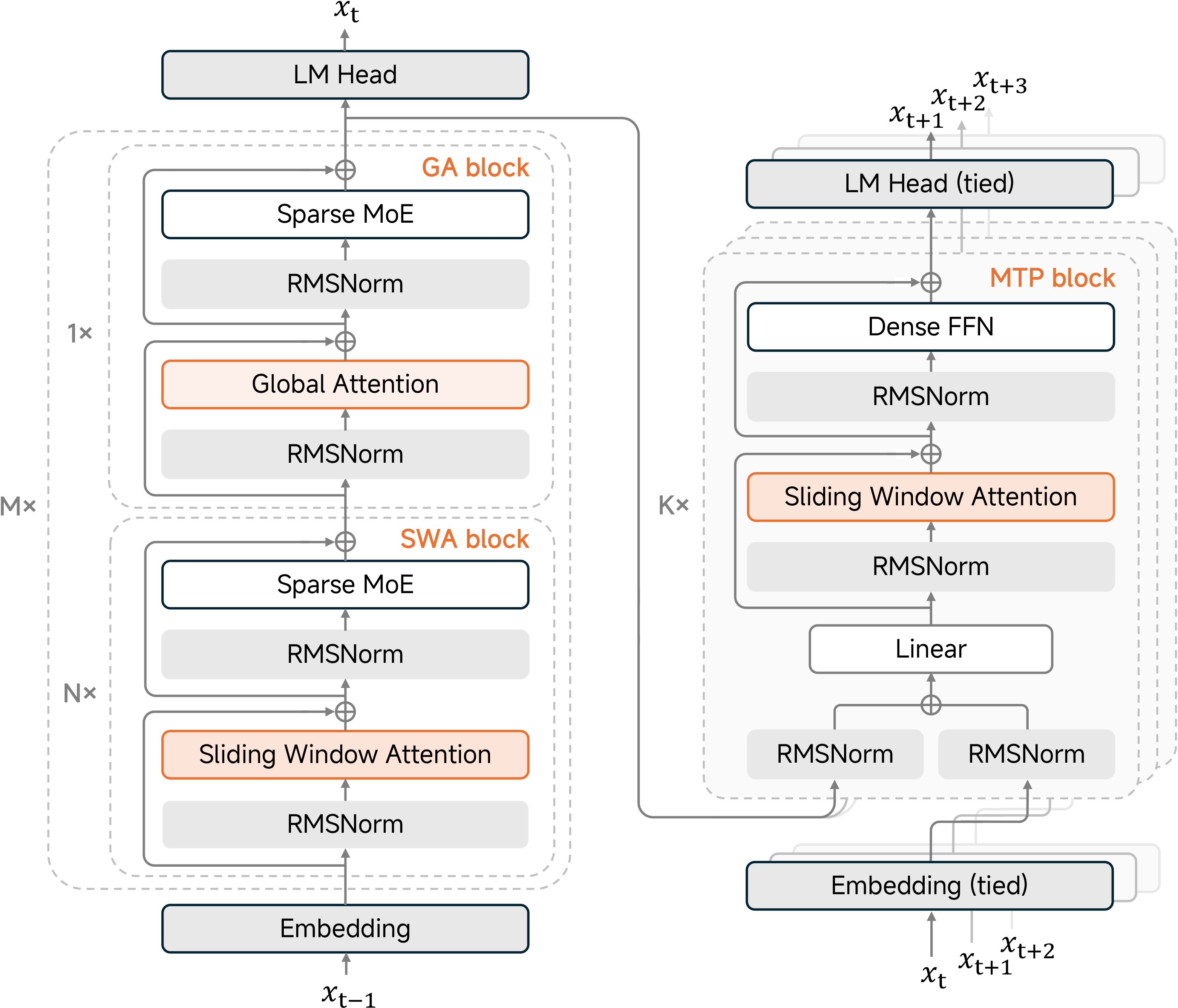
混合滑动窗口注意力机制
MiMo-V2-Flash 通过交替使用局部滑动窗口注意力(SWA)和全局注意力(GA),解决了长上下文带来的二次复杂度问题。
- 配置:堆叠 (M=8) 个混合模块。每个模块包含 (N=5) 层 SWA,随后接 1 层 GA。
- 效率:SWA 层使用 128 个 token 的窗口大小,显著减少了 KV 缓存占用。
- 汇聚偏置(Sink Bias):引入可学习的注意力汇聚偏置,以在激进的窗口大小下维持模型性能。
轻量级多 Token 预测(MTP)
与传统的推测解码不同,该模型的 MTP 模块原生集成于训练和推理过程中。
- 结构:采用密集前馈网络(FFN,而非 MoE)和滑动窗口注意力(SWA,而非 GA),以保持较低参数量(每模块 0.33B)。
- 性能:支持自推测解码,将生成速度提升三倍,并缓解小批量 RL 训练期间 GPU 空闲的问题。
API调用
- 服务部署成功后,可在服务列表查看调用信息
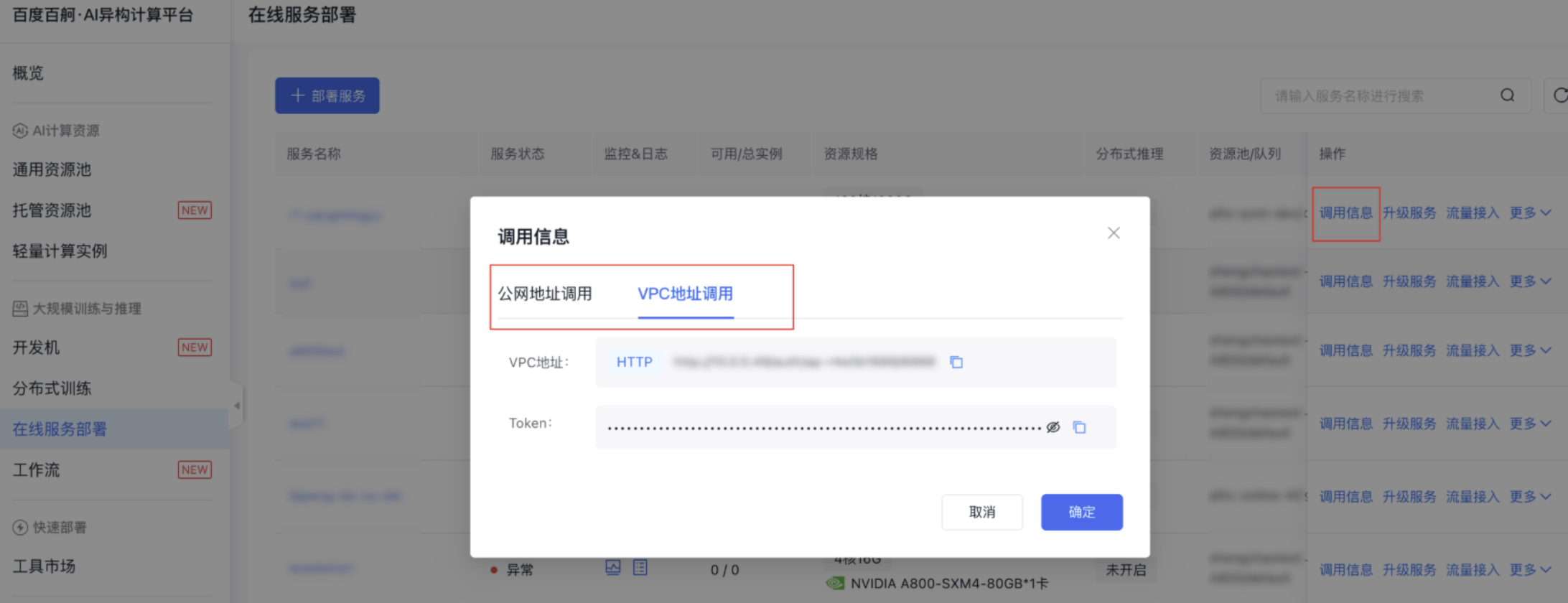
- 调用示例
Plain Text
1curl -X POST "<访问地址>/v1/chat/completions" \
2-H "Content-Type: application/json" \
3-H "Authorization: Bearer <TOKEN>" \
4-d '{
5 "model": "MiMo-V2-Flash",
6 "messages": [{"role": "system", "content": "你是一名天文学家,请回答用户提出的问题。"}, {"role": "user", "content": "人类是否能登上火星?"}],
7 "max_tokens": 1024,
8 "temperature": 0.7
9}'评价此篇文章