
GLM-4.5V
更新时间:2026-01-21
GLM-4.5V 是Z.AI基于 MOE 架构的视觉推理模型,以 106B 的总参数量和 12B 激活参数量,在各类基准测试中达到全球同级别开源多模态模型SOTA,其涵盖图像、视频、文档理解及 GUI 任务等常见任务。
模型介绍
- 开源多模态 SOTA
GLM-4.5V 基于Z.AI的旗舰产品 GLM-4.5-Air,延续 GLM-4.1V-Thinking 技术路线进行迭代升级,在42个公共视觉多模态基准测试中,其综合性能与开源最优模型处于同一水平,涵盖了图像、视频、文档理解和GUI任务等常见任务。
- 支持 Thinking 和 Non-Thinking
GLM-4.5V 引入全新的“思考模式”切换功能,使用户能够自由地在快速响应与深度推理之间切换,根据任务需求灵活平衡处理速度与输出质量
使用场景
- 前端编码
分析网页截图或屏幕录制视频,理解布局和交互逻辑,一键生成完整且可用的网页代码
- Grounding
精确识别和定位目标物体,适用于安检、质量检查、内容审查和遥感监测等实际场景
- GUI Agent
识别并处理屏幕图像,支持执行点击、滑动等指令,为智能代理完成操作任务提供可靠支持
- 复杂长文档解读
可深入分析数十页的复杂文档,支持摘要、翻译、图表提取,并能够基于内容提出见解
- 图像识别与推理
具备强大的推理能力和丰富的世界知识,能够在不使用搜索的情况下推断出图像的背景信息
- 视频理解
能够解析长视频内容,并准确推断出视频中的时间、人物、事件和逻辑关系
- 学科解题
能够解决复杂的文本-图像结合问题,适用于K12教育场景中的问题解决和讲解
API调用
- 服务部署成功后,可在服务列表查看调用信息
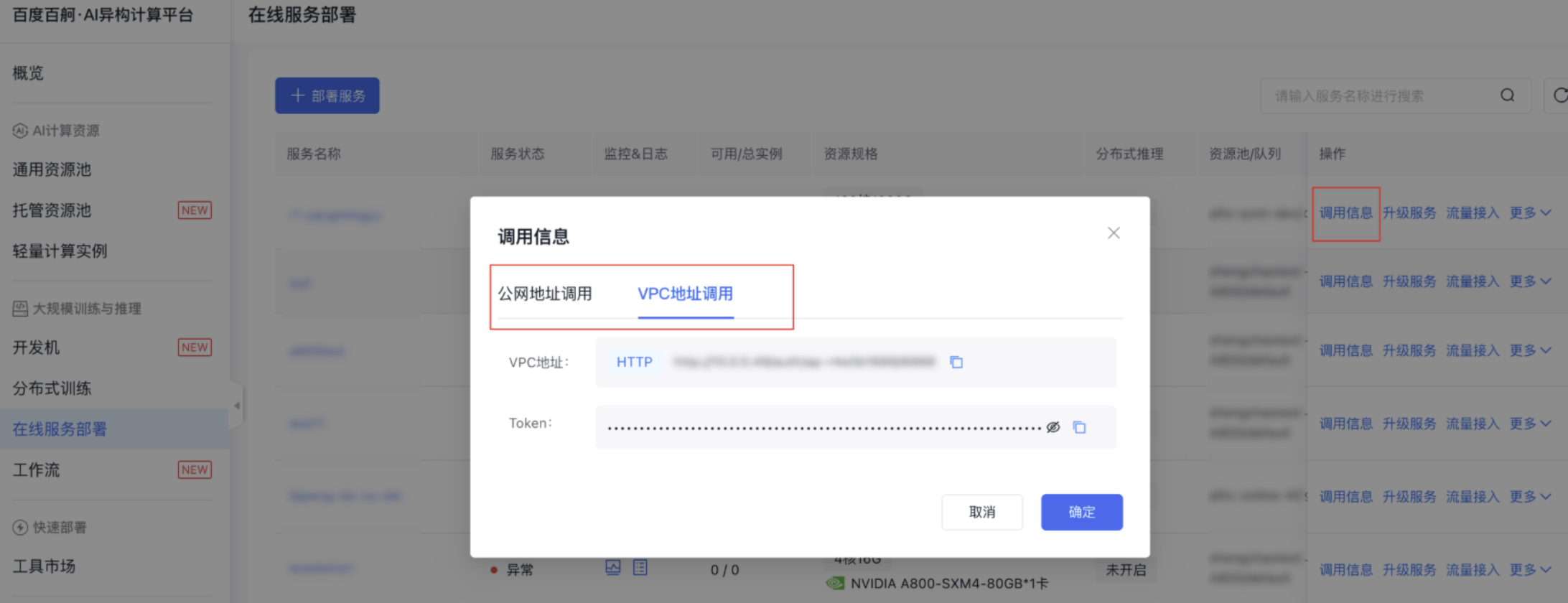
2.调用示例
Plain Text
1curl -X POST "<访问地址>/v1/chat/completions" \
2-H "Content-Type: application/json" \
3-H "Authorization: <TOKEN>" \
4-d '{
5 "model": "GLM-4.5V",
6 "messages": [{"role": "user","content": [{"type": "text", "text": "请描述这张图片的内容"},{"type": "image_url", "image_url": {"url": "https://bce.bdstatic.com/doc/bce-doc/AIHC/dog_e941a21.jpeg"}}]}],
7 "max_tokens": 1024,
8 "temperature": 0.7
9}'