
快速部署GPT-SoVITS语音合成
资源准备
可根据资源规模、稳定性、灵活性等要求按需准备轻量计算实例或通用计算资源池,用于快速部署GPT-SoVITS。
安装GPT-SoVITS
1.在百舸平台 工具市场 中选择GPT-SoVITS模版,点击 部署工具 按钮; 2.根据模型开发调试需求,选择使用卡数量,至少需要选择1张卡,点击 确定 启动工具。
前置准备
准备原始音频:原始音频建议遵从如下标准:
- 单人真人音频;
- 间隔清晰且均匀;
- 语速正常;
- 咬字发音清楚;
- 背景音和混响(可简单地理解为回声)弱;
- 时长在3-5min左右。
数据集处理
在 我的工具 中找到对应的GPT-SoVITS实例,点击 登录 查看WebUI的访问地址和账号密码,登录WebUI。 本节所展示的内容都在WebUI界面【0-前置数据集获取工具】功能下。
人声伴奏分离&去混响去延迟
可用于处理原始音频,生成更干净的人声。点击【开启UVR5-WebUI】,当【UVR5进程输出信息】出现“UVR5已开启”后,说明UVR5 UI界面已经启动了,端口信息可在终端通过echo $GRADIO_UVR_PORT查看,访问http://宿主机公网IP:GRADIO_UVR_PORT/ 即可。

UVR5 如下所示。
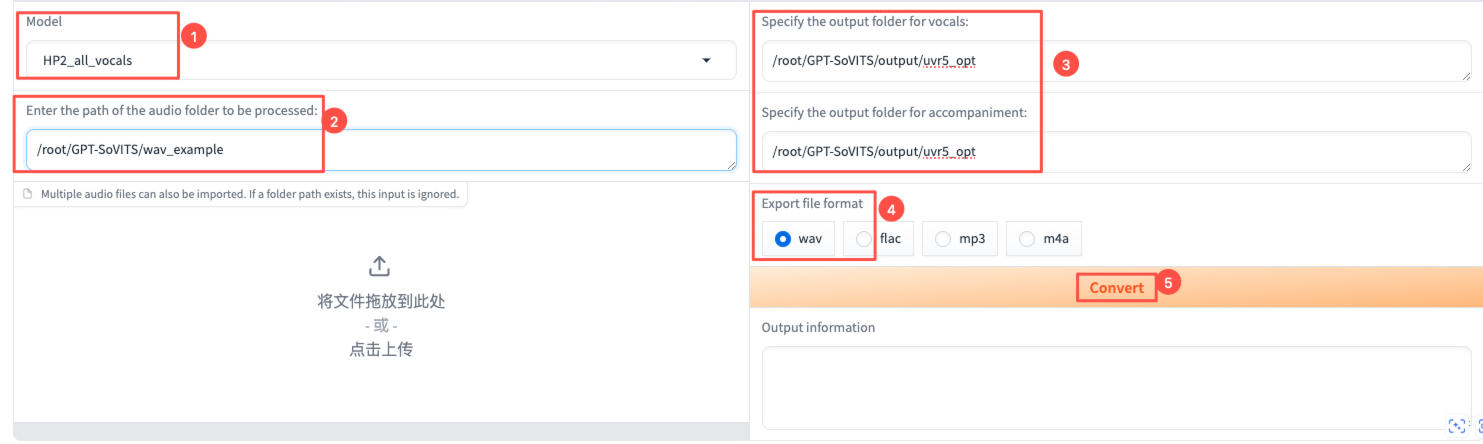
- 人声和伴奏分离:【Model】选择HP2_all_vocals,然后输入原始音频文件所在目录的路径,以及输出路径,选择自己想要的输出格式,点击【Convert】。【Output information】显示xxx.wav.reformatted.wav->Success时,说明人声伴奏分离完成。分离得到的音频存储在路径/root/GPT-SoVITS/output/uvr5_opt下,其中instrument_xxx.wav是分离得到的伴奏音频,vocal_xxx.wav则是人声音频,删除伴奏音频。
2.对人声去混响去延迟:【Model】选择onnx_dereverb_By_FoxJoy,输入文件路径选择刚刚分离得到的人声音频文件所在目录的路径,点击【Convert】。【Output information】显示xxx.wav.reformatted.wav->Success时,说明去混响去延迟完成。
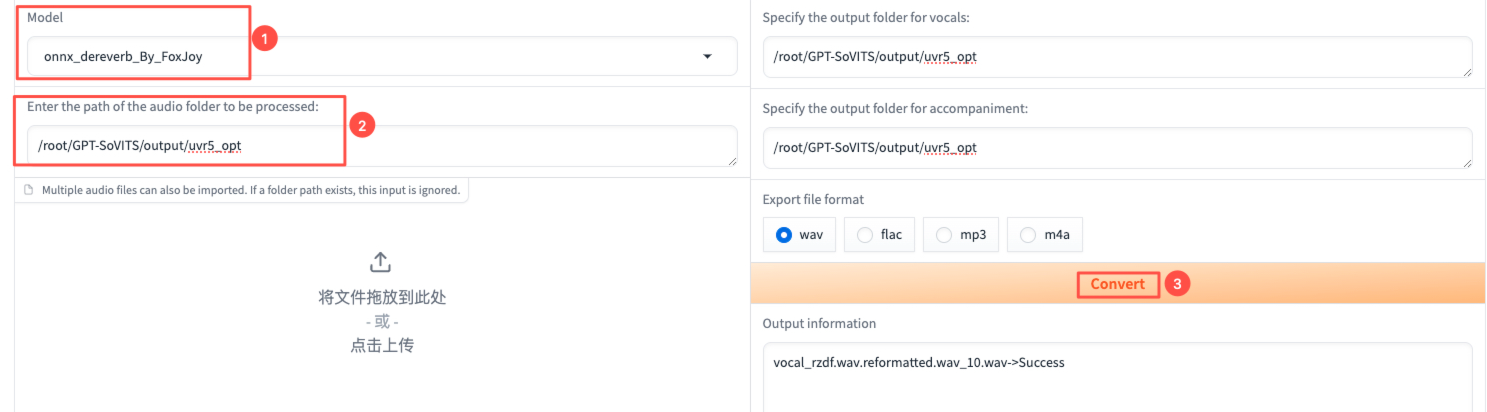
3.在输出目录/root/GPT-SoVITS/output/uvr5_opt下,可以看到处理结果如下所示。只保留xxx.wav_main_vocal.wav音频文件。

根据音频混响程度自行决定是否需要进一步去混响,不需要可跳过。如果仍然需要,在UI界面选择【Model】为VR-DeEchoAggressive,再一次去混响去延迟。等待处理结束后,在输出目录/root/GPT-SoVITS/output/uvr5_opt下,可以看到处理结果如下所示。只保留vocal_vocal_xxx.wav音频文件。
这里的模型选择可以根据音频混响程度由低到高依次选择:VR-DeEchoNormal、VR-DeEchoAggressive、VR-DeEchoDeReverb。为了便于展示,我们将最终处理得到的文件重新命名为rzdf.wav。
语音切分
语音切分界面的min_length、min_interval、max_sil_kept的计时单位都是ms。这里只更改了音频输入和输出路径,其余保持默认。然后点击【开启语音切割】,【语音切割进程输出信息】显示“切割结束”后,说明语音切分完成。
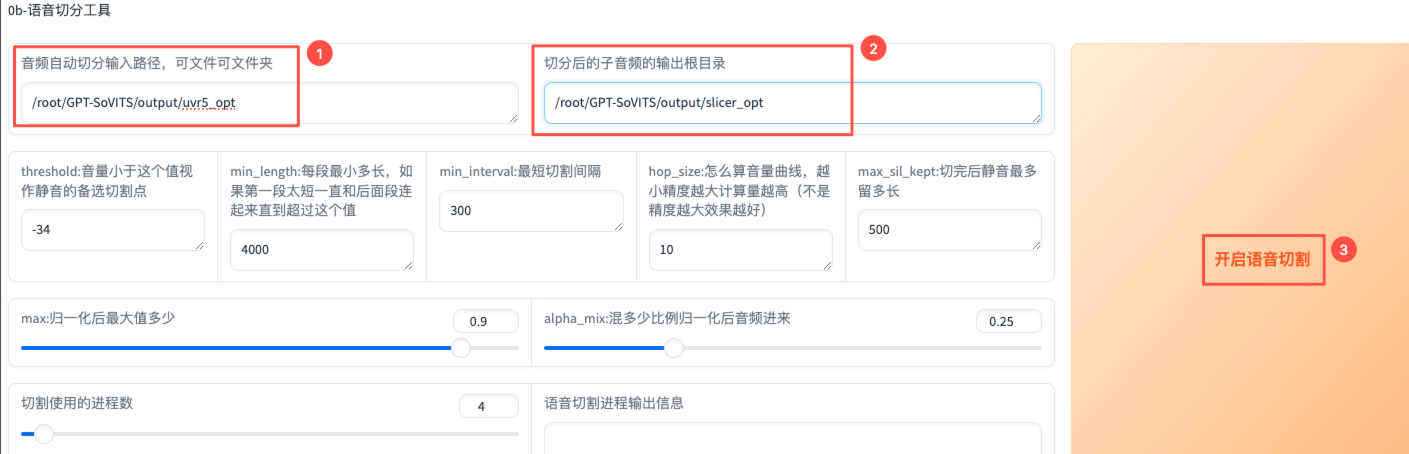
可以在指定输出目录/root/GPT-SoVITS/output/slicer_opt下看到语音切分结果。
语音降噪
对语音切分后的音频进行降噪处理,设置好音频输入、输出路径,点击【开启语音降噪】。【语音降噪进程输出信息】显示“语音降噪任务完成, 查看终端进行下一步”后,表明降噪完成。

可以在指定输出目录/root/GPT-SoVITS/output/denoise_opt下看到语音切分结果。经过测试发现,目前GPT-SoVITS的语音降噪功能对于音质损坏较大,不建议使用。
中文批量离线ASR
ASR 代表“Automatic Speech Recognition”,即自动语音识别。
我们使用语音降噪得到的切分后的音频作为ASR输入,并设置ASR输出路径。【ASR模型】按照音频的语种选择达摩ASR(中文);其他语种可选择Faster Whisper,该ASR模型对日语和英文的识别准确率较高,但速度较慢。
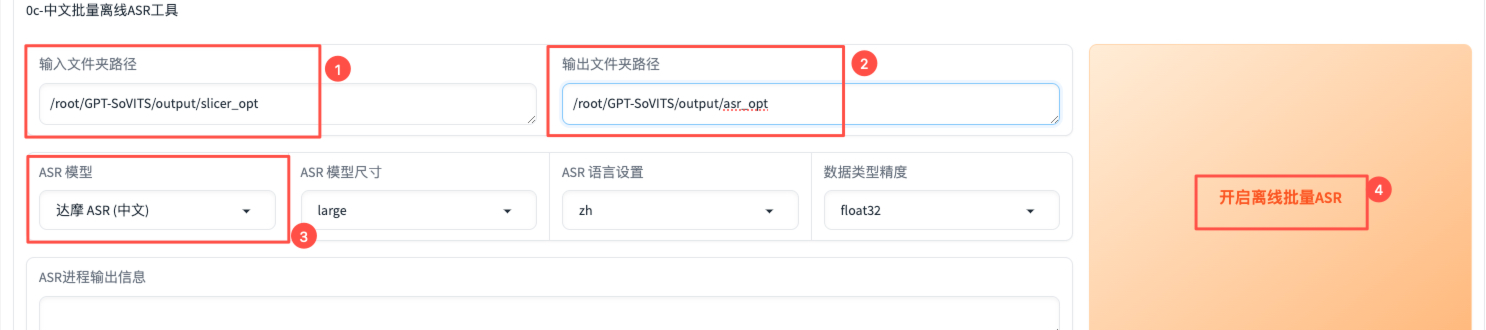
在设置的ASR输出目录下可看到结果。
语音文本校对标注
输入【.list标注文件路径】,然后点击【打开打标WebUI】,即可启动。

打标WebUI的端口可通过echo $GRADIO_SUBFIX_PORT查看,然后访问http://宿主机公网IP:GRADIO_SUBFIX_PORT/。 对于文本的校对,直接在Text n框中修改,然后点击【Submit Text】。
Text-To-Speech相关
本节所展示的内容都在WebUI界面的【1-GPT-SoVITS-TTS】功能下。
训练集格式化
输入【实验/模型名】,以及【文本标注文件】和【训练集音频文件目录】,点击【开启一键三连】,完成文本获取、SSL提取和语义token提取。
【一键三连进程输出信息】提示,表明训练集格式化完成。
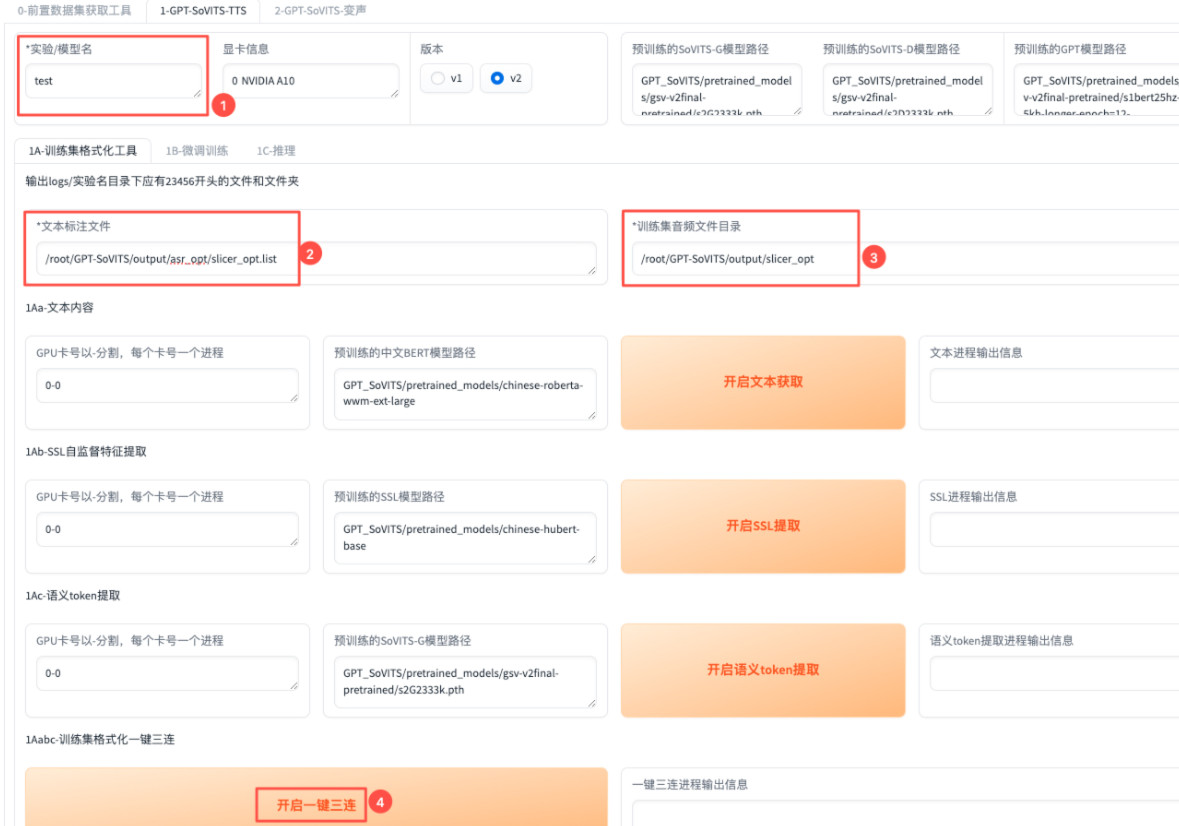
处理结果在/root/GPT-SoVITS/logs目录下。
对于中文音频,如果缺少以2、3、4、5、6开头的文件/目录,请根据运行日志/root/apps/logs/webui.log仔细排查错误。对于日/英文,缺少3开头的目录是正常的。
模型微调
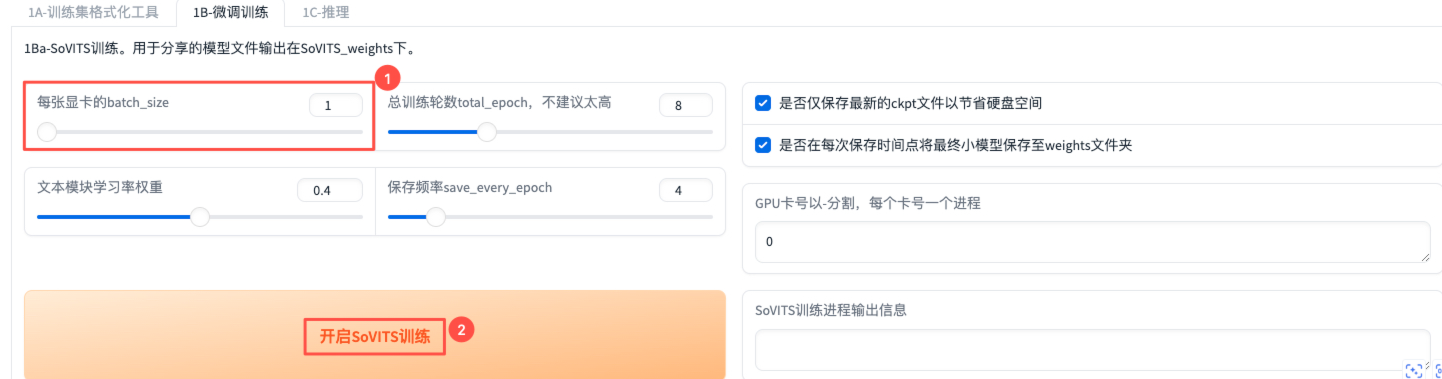
SoVITS训练
batch_size可根据实际情况自行调整,其他可保持默认,然后点击【开启SoVITS训练】。【SoVITS训练进程输出信息】显示“SoVITS训练完成”后,说明该步骤完成。
GPT训练
类似地,batch_size可根据实际情况自行调整。对于【是否开启dpo训练选项】,启用后可以改善模型吞字复读的问题,但对数据集质量要求、标注质量和显存需求更高,用户可根据情况自行决定。其他可保持默认,点击【开启GPT训练】。【GPT训练进程输出信息】显示“GPT训练完成”后,表明该步骤完成。
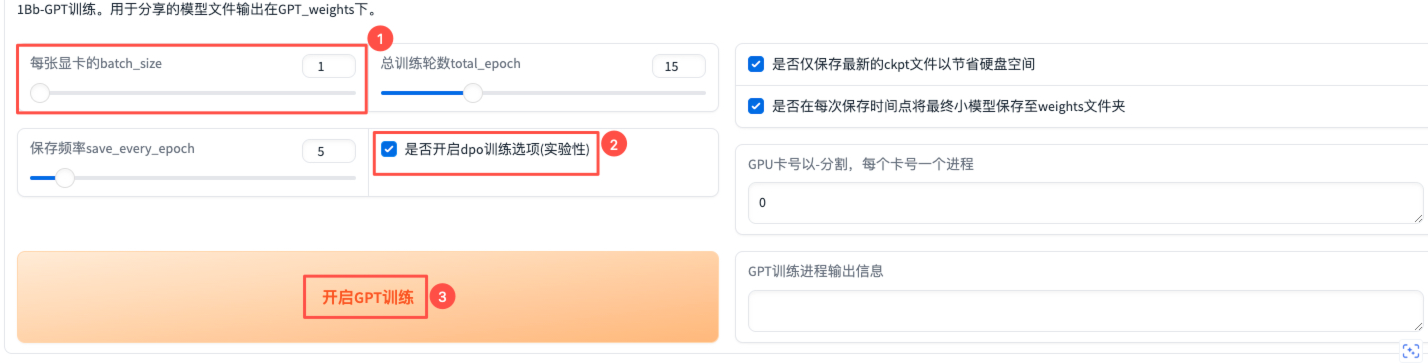
SoVITS训练和GPT训练过程中,保存的权重分别在/root/GPT-SoVITS目录的SoVITS_weights_v2/和GPT_weights_v2/下.
推理
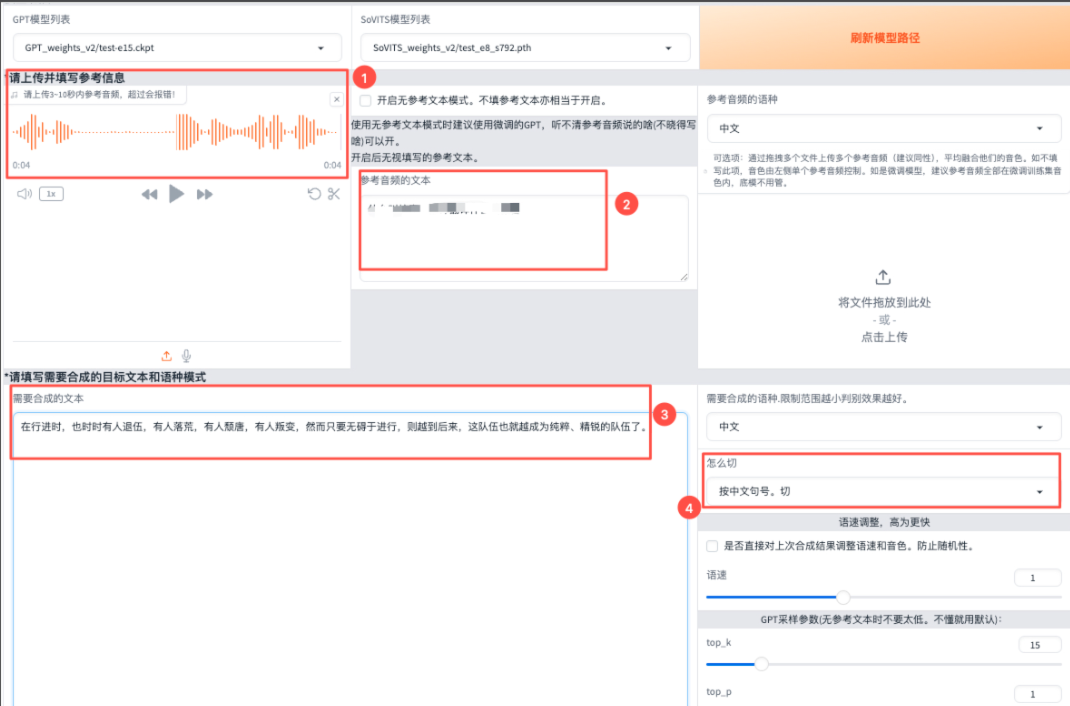
点击【刷新模型路径】,获取模型微调得到的权重路径,然后选择GPT模型和SoVITS模型,点击【开启TTS推理WebUI】。
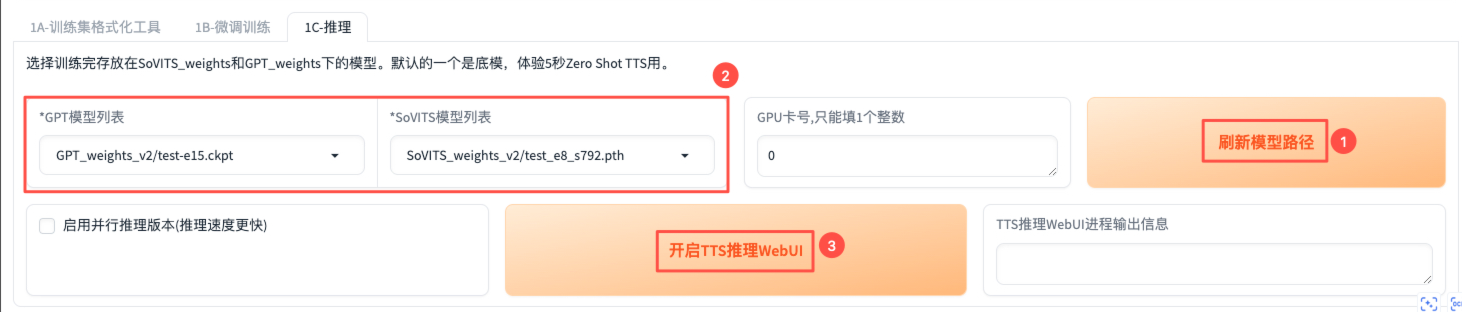
推理界面的端口信息可在终端通过echo $GRADIO_INFER_PORT查看,访问 http://宿主机公网IP:GRADIO_INFER_PORT/即可。
上传参考音频及其文本,模型将学习该参考音频的语速和语气,尽量保证参考音频和训练音频来自同一人。然后输入【需要合成的文本】,并确定切分方式,过长的切分方式会占用较大的显存。最后,点击【合成音频】。
评价此篇文章