
高级用法
混合序列并行策略加速长文本预训练
参数配置说明:序列并行参数具体见aiak_training_llm/train/arguments.py文件。
其中:
--context-parallel-size:指定序列并行维度,该维度是ulysses和ring attention两种混合序列并行策略之和。--context-parallel-ulysses-degree:在context-parallel-size基础上,设置 ulysses 并行维度,默认值为1,即仅使用 megatron 原生context parallel 算法。如果两者设置大小一样,则仅使用 ulysses 算法策略;
**LLaMA2 70B**长序列训练示例
1#! /bin/bash
2
3MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
4AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
5
6DATA_PATH=${DATA_PATH:-"/mnt/cluster/llama2/pile/pile-llama_text_document"}
7TOKENIZER_PATH=${TOKENIZER_PATH:-"/mnt/cluster/llama2/Llama-2-70b-hf/"}
8
9CHECKPOINT_PATH=${CHECKPOINT_PATH:-"/mnt/cluster/llama2/mcore_llama2_70b_tp4_pp4"}
10
11TENSORBOARD_PATH=${TENSORBOARD_PATH:-"/mnt/cluster/aiak-training-llm/tensorboard-log/llama2-70b-tp4pp4"}
12
13GPUS_PER_NODE=8
14
15# Change for multinode config
16MASTER_ADDR=${MASTER_ADDR:-"localhost"}
17MASTER_PORT=${MASTER_PORT:-"6000"}
18NNODES=${WORLD_SIZE:-"1"}
19NODE_RANK=${RANK:-"0"}
20
21DISTRIBUTED_ARGS=(
22 --nproc_per_node $GPUS_PER_NODE
23 --nnodes $NNODES
24 --node_rank $NODE_RANK
25 --master_addr $MASTER_ADDR
26 --master_port $MASTER_PORT
27)
28
29# you can setup llama2-70b maunally
30#MODEL_ARGS=(
31# --model-name llama2
32# --num-layers 80
33# --hidden-size 8192
34# --ffn-hidden-size 28672
35# --num-attention-heads 64
36# --position-embedding-type rope
37# --normalization RMSNorm
38# --swiglu
39# --attention-dropout 0
40# --hidden-dropout 0
41# --disable-bias-linear
42# --untie-embeddings-and-output-weights
43# --group-query-attention
44# --num-query-groups 8
45#)
46
47# or you can setup llama2-70b by using the following command
48MODEL_ARGS=(
49 --model-name llama2-70b # options: llama2-7b, llama2-13b, llama2-70b
50)
51
52DATA_ARGS=(
53 --tokenizer-type HFTokenizer
54 --hf-tokenizer-path $TOKENIZER_PATH
55 --data-path $DATA_PATH
56 --split 949,50,1
57)
58
59TRAINING_ARGS=(
60 --training-phase pretrain # options: pretrain, sft
61 --seq-length 32768
62 --max-position-embeddings 32768
63 --init-method-std 0.01
64 --micro-batch-size 1
65 --global-batch-size 1024
66 --lr 0.0002
67 --min-lr 1.0e-5
68 --clip-grad 1.0
69 --weight-decay 0.01
70 --optimizer adam
71 --adam-beta1 0.9
72 --adam-beta2 0.95
73 --adam-eps 1e-05
74 --norm-epsilon 1e-6
75 --train-iters 500000
76 --lr-decay-iters 500000
77 --lr-decay-style cosine
78 --lr-warmup-fraction 0.002
79 --initial-loss-scale 65536
80 --fp16
81 --load $CHECKPOINT_PATH
82 --save $CHECKPOINT_PATH
83 --save-interval 5000
84 --eval-interval 1000
85 --eval-iters 10
86 #--ckpt-step 0
87 #--no-load-optim
88 #--no-load-rng
89)
90
91MODEL_PARALLEL_ARGS=(
92 --tensor-model-parallel-size 4
93 --pipeline-model-parallel-size 4
94 --context-parallel-size 4
95 --context-parallel-ulysses-degree 2
96 --use-distributed-optimizer
97 --overlap-grad-reduce
98 --overlap-param-gather
99 --distributed-backend nccl
100 --sequence-parallel
101 #--tp-comm-overlap # require mpi envrionment
102)
103
104LOGGING_ARGS=(
105 --log-interval 1
106 --tensorboard-dir ${TENSORBOARD_PATH}
107 --log-timers-to-tensorboard
108)
109
110if [ -n "${WANDB_API_KEY}" ]; then
111 LOGGING_ARGS+=(
112 --wandb-project ${WANDB_PROJECT}
113 --wandb-exp-name ${WANDB_NAME}
114 )
115fi
116
117PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
118 torchrun ${DISTRIBUTED_ARGS[@]} \
119 $AIAK_TRAINING_PATH/aiak_training_llm/train.py \
120 ${MODEL_ARGS[@]} \
121 ${DATA_ARGS[@]} \
122 ${TRAINING_ARGS[@]} \
123 ${MODEL_PARALLEL_ARGS[@]} \
124 ${LOGGING_ARGS[@]}混合序列并行策略加速长文本SFT训练
参数配置说明:序列并行参数具体见aiak_training_llm/train/arguments.py文件。
其中:
- --context-parallel-size:指定序列并行维度,该维度是ulysses和ring attention两种混合序列并行策略之和;
- --context-parallel-ulysses-degree:在context-parallel-size基础上,设置 ulysses 并行维度,默认值为1,即仅使用 megatron 原生context parallel 算法。如果两者设置大小一样,则仅使用 ulysses 算法策略;
-
--sft-sort-batch:对整个数据集按照样本长度从小到大排序。用于解决数据并行中样本长度不一致导致的长尾问题,注意:数据顺序可能影响模型效果,谨慎分析后使用。
- 当开启--packing-sft-data时,则不再对整个数据集排序,而是对pack后的数据排序 (根据pack中包含的每个样本计算量)。
- --packing-batch-size:默认10000,用于 --packing-sft-data功能,用于决定参与单次拼接的候选样本数量;
Qwen2.5 72B + 128K长序列SFT训练示例:
1#! /bin/bash
2# The script needs to be run on at least 16 nodes.
3
4MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
5AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
6
7DATA_PATH=${DATA_PATH:-"/mnt/cluster/aiak-training-llm/dataset/sft_aplaca_zh_data.json"}
8
9#DATA_PATH=${DATA_PATH:-"/mnt/cluster/aiak-training-llm/qwen2.5/sft_aplaca_zh_tokenized"}
10
11DATA_CACHE_PATH=${DATA_CACHE_PATH:-"/mnt/cluster/aiak-training-llm/qwen2.5/sft_aplaca_zh_data_cache"}
12
13DATASET_CONFIG_PATH=${DATASET_CONFIG_PATH:-"/workspace/AIAK-Training-LLM/configs/sft_dataset_config.json"}
14
15TOKENIZER_PATH=${TOKENIZER_PATH:-"/mnt/cluster/huggingface.co/Qwen/Qwen2.5-72B"}
16
17CHECKPOINT_PATH=${CHECKPOINT_PATH:-"/mnt/cluster/aiak-training-llm/qwen2.5/Qwen2.5_72B_mcore_tp4pp8"}
18
19TENSORBOARD_PATH=${TENSORBOARD_PATH:-"/mnt/cluster/aiak-training-llm/tensorboard-log/qwen2.5-72b-sft"}
20
21GPUS_PER_NODE=8
22
23# Change for multinode config
24MASTER_ADDR=${MASTER_ADDR:-"localhost"}
25MASTER_PORT=${MASTER_PORT:-"6000"}
26NNODES=${WORLD_SIZE:-"1"}
27NODE_RANK=${RANK:-"0"}
28
29DISTRIBUTED_ARGS=(
30 --nproc_per_node $GPUS_PER_NODE
31 --nnodes $NNODES
32 --node_rank $NODE_RANK
33 --master_addr $MASTER_ADDR
34 --master_port $MASTER_PORT
35)
36
37MODEL_ARGS=(
38 --model-name qwen2.5-72b # qwen2.5 options: 0.5b, 1.5b, 3b, 7b, 14b, 32b, 72b
39 --rotary-base 1000000
40 --rotary-seq-len-interpolation-factor 1
41)
42
43DATA_ARGS=(
44 --tokenizer-type HFTokenizer
45 --hf-tokenizer-path $TOKENIZER_PATH
46 --data-path $DATA_PATH
47 --split 100,0,0
48)
49
50SFT_ARGS=(
51 --chat-template qwen
52 --sft-num-preprocess-workers 16
53 --no-check-for-nan-in-loss-and-grad
54 #--is-tokenized-data
55 --packing-sft-data
56 #--sft-sort-batch
57 #--packing-batch-size 10000
58 #--sft-data-streaming
59
60 #--train-on-prompt
61 #--eod-mask-loss
62
63 #--sft-dataset-config $DATASET_CONFIG_PATH
64 #--sft-dataset sft_aplaca_zh_data # defined in --sft-dataset-config, default: default
65 #--data-cache-path $DATA_CACHE_PATH
66)
67
68TRAINING_ARGS=(
69 --training-phase sft # options: pretrain, sft
70 --seq-length 131072
71 --max-position-embeddings 131072
72 --init-method-std 0.006
73 --micro-batch-size 1
74 --global-batch-size 128
75 --lr 1.0e-5
76 --min-lr 1.0e-6
77 --clip-grad 1.0
78 --weight-decay 0.1
79 --optimizer adam
80 --adam-beta1 0.9
81 --adam-beta2 0.95
82 --adam-eps 1e-08
83 --norm-epsilon 1e-6
84 --train-iters 5000
85 --lr-decay-iters 5000
86 --lr-decay-style cosine
87 --lr-warmup-fraction 0.002
88 --initial-loss-scale 65536
89 --bf16
90 --load $CHECKPOINT_PATH
91 --save $CHECKPOINT_PATH
92 --save-interval 500
93 --eval-interval 100
94 --eval-iters 10
95 #--ckpt-step 0
96 #--no-load-optim
97 #--no-load-rng
98 #--num-workers 8
99)
100
101MODEL_PARALLEL_ARGS=(
102 --tensor-model-parallel-size 4
103 --pipeline-model-parallel-size 8
104 --use-distributed-optimizer
105 --overlap-grad-reduce
106 --overlap-param-gather
107 --distributed-backend nccl
108 --sequence-parallel
109 --tp-comm-overlap
110 --context-parallel-size 8
111 --context-parallel-ulysses-degree 8
112 --recompute-granularity full
113 --recompute-method block
114 --recompute-num-layers 13
115 --offload-optimizer manual
116 --offload-optimizer-percent 1.0
117)
118
119LOGGING_ARGS=(
120 --log-interval 1
121 --tensorboard-dir ${TENSORBOARD_PATH}
122 --log-timers-to-tensorboard
123)
124
125if [ -n "${WANDB_API_KEY}" ]; then
126 LOGGING_ARGS+=(
127 --wandb-project ${WANDB_PROJECT}
128 --wandb-exp-name ${WANDB_NAME}
129 )
130fi
131
132PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
133 torchrun ${DISTRIBUTED_ARGS[@]} \
134 $AIAK_TRAINING_PATH/aiak_training_llm/train.py \
135 ${MODEL_ARGS[@]} \
136 ${DATA_ARGS[@]} \
137 ${TRAINING_ARGS[@]} \
138 ${SFT_ARGS[@]} \
139 ${MODEL_PARALLEL_ARGS[@]} \
140 ${LOGGING_ARGS[@]}流水线并行策略不均衡切分
-
--custom-pipeline-layers:指定流水线并行各 pp stage 具体 layer 数,不开启该功能默认均分。
- 使用方法:假设 PP=4,参数配置--custom-pipeline-layers=19,20,20,21,则表示第一个stage层数为19,最后一个stage层数为21,其余stage层数为20。
-
--custom-pipeline-recompute-layers:在开启流水线并行以及重计算情况下使用,指定流水线并行各stage 做重计算的layer数,用于均衡各stage显存(该参数主要用于长序列等对显存需要精细调整的场景)。
-
使用方法:
- 当前 PP Stage 存在显存不均衡问题,第一个stage 一般显存占用最多,需要开启更多的重计算layer数;而最后一个stage占用显存最少,可以开启最少的重计算层数或者不开重计算。
- 假设PP=4,参数配置--custom-pipeline-recompute-layers=20,15,15,0,表示第一个stage开启重计算层数为20,最后一个stage重计算层数为0,其余stage开启重计算层数为15;
-
qwen-72b长序列预训练示例:
1#! /bin/bash
2# The script needs to be run on at least 16 nodes.
3
4MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
5AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
6
7DATA_PATH=/mnt/cluster/qwen/qwen-data/qwen_00_text_document_content_sentence
8TOKENIZER_PATH=/mnt/cluster/huggingface.co/Qwen/Qwen-72B/
9CHECKPOINT_PATH=/mnt/cluster/qwen/megatron_qwen_72b_checkpoint/
10
11TENSORBOARD_PATH=/mnt/cluster/qwen/tensorboard-log/qwen-72b
12
13GPUS_PER_NODE=8
14
15# Change for multinode config
16MASTER_ADDR=${MASTER_ADDR:-"localhost"}
17MASTER_PORT=${MASTER_PORT:-"6000"}
18NNODES=${WORLD_SIZE:-"1"}
19NODE_RANK=${RANK:-"0"}
20
21DISTRIBUTED_ARGS=(
22 --nproc_per_node $GPUS_PER_NODE
23 --nnodes $NNODES
24 --node_rank $NODE_RANK
25 --master_addr $MASTER_ADDR
26 --master_port $MASTER_PORT
27)
28
29MODEL_ARGS=(
30 --model-name qwen-72b # qwen2.5 options: 0.5b, 1.5b, 3b, 7b, 14b, 32b, 72b
31 --rotary-base 1000000
32 --rotary-seq-len-interpolation-factor 1
33)
34
35DATA_ARGS=(
36 --tokenizer-type HFTokenizer
37 --hf-tokenizer-path $TOKENIZER_PATH
38 --data-path $DATA_PATH
39 --split 100,0,0
40)
41
42
43TRAINING_ARGS=(
44 --training-phase pretrain # options: pretrain, sft
45 --seq-length 32768
46 --max-position-embeddings 32768
47 --init-method-std 0.006
48 --micro-batch-size 1
49 --global-batch-size 128
50 --lr 1.0e-5
51 --min-lr 1.0e-6
52 --clip-grad 1.0
53 --weight-decay 0.1
54 --optimizer adam
55 --adam-beta1 0.9
56 --adam-beta2 0.95
57 --adam-eps 1e-08
58 --norm-epsilon 1e-6
59 --train-iters 5000
60 --lr-decay-iters 5000
61 --lr-decay-style cosine
62 --lr-warmup-fraction 0.002
63 --initial-loss-scale 65536
64 --bf16
65 --load $CHECKPOINT_PATH
66 --save $CHECKPOINT_PATH
67 --save-interval 500
68 --eval-interval 100
69 --eval-iters 10
70 #--ckpt-step 0
71 #--no-load-optim
72 #--no-load-rng
73 #--num-workers 8
74)
75
76MODEL_PARALLEL_ARGS=(
77 --tensor-model-parallel-size 4
78 --pipeline-model-parallel-size 4
79 --use-distributed-optimizer
80 --overlap-grad-reduce
81 --overlap-param-gather
82 --distributed-backend nccl
83 --sequence-parallel
84 --tp-comm-overlap
85 --context-parallel-size 2
86 --context-parallel-ulysses-degree 1
87 --recompute-granularity full
88 --recompute-method block
89 --recompute-num-layers 13
90 --custom-pipeline-recompute-layers 11,7,3,0
91 --custom-pipeline-layers 18,19,21,22
92 --offload-optimizer manual
93 --offload-optimizer-percent 1.0
94)
95
96LOGGING_ARGS=(
97 --log-interval 1
98 --tensorboard-dir ${TENSORBOARD_PATH}
99 --log-timers-to-tensorboard
100)
101
102if [ -n "${WANDB_API_KEY}" ]; then
103 LOGGING_ARGS+=(
104 --wandb-project ${WANDB_PROJECT}
105 --wandb-exp-name ${WANDB_NAME}
106 )
107fi
108
109PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
110 torchrun ${DISTRIBUTED_ARGS[@]} \
111 $AIAK_TRAINING_PATH/aiak_training_llm/train.py \
112 ${MODEL_ARGS[@]} \
113 ${DATA_ARGS[@]} \
114 ${TRAINING_ARGS[@]} \
115 ${MODEL_PARALLEL_ARGS[@]} \
116 ${LOGGING_ARGS[@]}CogVLM2模型训练指南
数据集格式和处理
当前版本主要参考 CogVLM 提供的开源数据集示例来构建训练过程,用户可以使用 CogVLM-SFT-311K 开源数据集或自行构建相同格式的数据集进行训练微调。
数据格式说明:
当前暂支持 Caption 和 VQA 格式的数据,其中 Caption 数据用于 Pretrain 阶段,VQA 数据用于 SFT 阶段;
- 两种数据集均需按照以下示例格式来组织:
1.llava_details-minigpt4_3500_formate
2├── images
3│ └── 00000001.jpg
4└── labels
5 └── 00000001.json- images文件夹中存放了图片文件,labels文件夹中存放了对应的标签文件。图片和标签文件的名称一一对应。图片文件的格式为jpg,标签文件的格式为json。
- Pretrain数据集的标签文件包含了一段说明文字,由content 字段指定
1{
2 "captions": [
3 {
4 "role": "caption",
5 "content": "这张图片是一个计算机生成的场景,画面中一名女网球运动员手里拿着网球拍。网球分布在整个网球场周围,有些在她上面,有些在下面,还有一些从左右两侧向她飞来。"
6 }
7 ]
8}- SFT数据集的标签文件中包含了一段对话,对话由user和assistant两个角色组成,每个角色的对话内容由role和content两个字段组成。如下字段所示。
1{
2 "conversations": [
3 {
4 "role": "user",
5 "content": "图片中可以看到多少人玩滑板?"
6 },
7 {
8 "role": "assistant",
9 "content": "图片中可以看到两个人拿着滑板。"
10 }
11 ...
12 ]注:对于多轮对话,训练时会随机挑选一轮或两轮对话参与训练,暂和CogVLM2开源逻辑保持一致(https://github.com/THUDM/CogVLM2/blob/cf9cb3c60a871e0c8e5bde7feaf642e3021153e6/finetune_demo/peft_lora.py#L79)
Checkpoint 转换
用户可以参考/workspace/AIAK-Training-LLM/examples/cogvlm2/checkpoint_convert目录下提供的示例脚本。实现方式说明:
- 由于 CogVLM 相比标准 LLM 新增了一些视觉的结构,为了方便处理转换,我们这里采用了【分模块独立转换和合并】的权重处理方式(未来可更方便的替换客户已有的 LLaMA、Vision Encoder权重);
将 Huggingface 权重转换到 MCore 格式:
1#! /bin/bash
2
3AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
4AIAK_MAGATRON_PATH=${AIAK_MESSAGE_PATH:-"/workspace/AIAK-Magatron"}
5CONVERT_CHECKPOINT_PATH="$AIAK_TRAINING_PATH/tools/convert_checkpoint"
6
7LOAD=/mnt/pfs/huggingface.co/THUDM/cogvlm2-llama3-chinese-chat-19B/
8SAVE=/mnt/pfs/aiak-training-llm/cogvlm2/converted_cogvlm2-llama3-chinese-chat-19B_tp4_pp1
9
10SAVE_LANGUAGE_EXPERT=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/language-expert-mcore
11SAVE_VISION_EXPERT=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/vision-expert-mcore
12SAVE_VISION_MODEL=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/vision-model-mcore
13SAVE_ADAPTER=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/adapter-mcore
14SAVE_PATCH=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/patch-mcore
15
16TP=4
17
18# 第1步:转换llama3中的语言专家权重
19python $CONVERT_CHECKPOINT_PATH/model.py \
20 --load_platform=huggingface \
21 --save_platform=mcore \
22 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/language-expert.json \
23 --tensor_model_parallel_size=$TP \
24 --load_ckpt_path=$LOAD \
25 --save_ckpt_path=$SAVE_LANGUAGE_EXPERT \
26 --safetensors \
27 --no-te \
28 --no_save_optim \
29 --no_load_optim
30
31# 第2步:转换llama3中的视觉专家权重
32python $CONVERT_CHECKPOINT_PATH/model.py \
33 --load_platform=huggingface \
34 --save_platform=mcore \
35 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-expert.json \
36 --tensor_model_parallel_size=$TP \
37 --load_ckpt_path=$LOAD \
38 --save_ckpt_path=$SAVE_VISION_EXPERT \
39 --safetensors \
40 --no-te \
41 --no_save_optim \
42 --no_load_optim
43
44# 第3步:转换视觉模型ViT中的Transformer
45python $CONVERT_CHECKPOINT_PATH/model.py \
46 --load_platform=huggingface \
47 --save_platform=mcore \
48 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-model.json \
49 --tensor_model_parallel_size=$TP \
50 --load_ckpt_path=$LOAD \
51 --save_ckpt_path=$SAVE_VISION_MODEL \
52 --safetensors \
53 --no-te \
54 --no_save_optim \
55 --no_load_optim
56
57# 第4步:转换视觉模型和语言模型的适配器adapter
58python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/adapter.py \
59 --load_platform=huggingface \
60 --save_platform=mcore \
61 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/adapter.json \
62 --tensor_model_parallel_size=$TP \
63 --load_ckpt_path=$LOAD \
64 --save_ckpt_path=$SAVE_ADAPTER
65
66# 第5步:转换视觉模型ViT中的Patch
67python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/vision_patch.py \
68 --load_platform=huggingface \
69 --save_platform=mcore \
70 --tensor_model_parallel_size=$TP \
71 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-patch.json \
72 --load_ckpt_path=$LOAD \
73 --save_ckpt_path=$SAVE_PATCH
74
75# 第6步:将以上5步的产出结果进行合并
76python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/merge_megatron.py \
77 --megatron_path $AIAK_MAGATRON_PATH \
78 --language_expert_path $SAVE_LANGUAGE_EXPERT/release \
79 --vision_expert_path $SAVE_VISION_EXPERT/release \
80 --vision_model_path $SAVE_VISION_MODEL/release \
81 --vision_patch $SAVE_PATCH/release \
82 --adapter_path $SAVE_ADAPTER/release \
83 --save_ckpt_path $SAVE/release
84
85echo release > $SAVE/latest_checkpointed_iteration.txt
86
87# 删除前5步产出的临时结果
88rm -rf $SAVE_LANGUAGE_EXPERT
89rm -rf $SAVE_VISION_EXPERT
90rm -rf $SAVE_VISION_MODEL
91rm -rf $SAVE_ADAPTER
92rm -rf $SAVE_PATCH将 MCore 权重转换到 Huggingface格式:
1#! /bin/bash
2
3AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
4AIAK_MAGATRON_PATH=${AIAK_MESSAGE_PATH:-"/workspace/AIAK-Megatron"}
5CONVERT_CHECKPOINT_PATH="$AIAK_TRAINING_PATH/tools/convert_checkpoint"
6
7SAVE=/mnt/pfs/aiak-training-llm/cogvlm2/converted_converted_cogvlm2
8LOAD=/mnt/pfs/aiak-training-llm/cogvlm2/mcore_cogvlm2_llama3_chinese_chat_19B_tp4_pp1/release/
9
10SAVE_LANGUAGE_EXPERT=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/language-expert-hf
11SAVE_VISION_EXPERT=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/vision-expert-hf
12SAVE_VISION_MODEL=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/vision-model-hf
13SAVE_ADAPTER=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/adapter-hf
14SAVE_PATCH=/mnt/pfs/aiak-training-llm/cogvlm2/tmp/patch-hf
15
16TP=4
17
18# 第1步:转换llama3中的语言专家权重
19python $CONVERT_CHECKPOINT_PATH/model.py \
20 --load_platform=mcore \
21 --megatron_path $AIAK_MAGATRON_PATH \
22 --save_platform=huggingface \
23 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/language-expert.json \
24 --tensor_model_parallel_size=$TP \
25 --load_ckpt_path=$LOAD \
26 --save_ckpt_path=$SAVE_LANGUAGE_EXPERT \
27 --safetensors \
28 --no-te \
29 --no_save_optim \
30 --no_load_optim
31
32# 第2步:转换llama3中的视觉专家权重
33python $CONVERT_CHECKPOINT_PATH/model.py \
34 --load_platform=mcore \
35 --save_platform=huggingface \
36 --megatron_path $AIAK_MAGATRON_PATH \
37 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-expert.json \
38 --tensor_model_parallel_size=$TP \
39 --load_ckpt_path=$LOAD \
40 --save_ckpt_path=$SAVE_VISION_EXPERT \
41 --safetensors \
42 --no-te \
43 --no_save_optim \
44 --no_load_optim
45
46# 第3步:转换视觉模型ViT中的Transformer
47python $CONVERT_CHECKPOINT_PATH/model.py \
48 --load_platform=mcore \
49 --save_platform=huggingface \
50 --megatron_path $AIAK_MAGATRON_PATH \
51 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-model.json \
52 --tensor_model_parallel_size=$TP \
53 --load_ckpt_path=$LOAD \
54 --save_ckpt_path=$SAVE_VISION_MODEL \
55 --safetensors \
56 --no-te \
57 --no_save_optim \
58 --no_load_optim
59
60# 第4步:转换视觉模型和语言模型的适配器adapter
61python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/adapter.py \
62 --load_platform=mcore \
63 --save_platform=huggingface \
64 --megatron_path $AIAK_MAGATRON_PATH \
65 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/adapter.json \
66 --tensor_model_parallel_size=$TP \
67 --load_ckpt_path=$LOAD \
68 --save_ckpt_path=$SAVE_ADAPTER
69
70# 第5步:转换视觉模型ViT中的Patch
71python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/vision_patch.py \
72 --load_platform=mcore \
73 --save_platform=huggingface \
74 --megatron_path $AIAK_MAGATRON_PATH \
75 --tensor_model_parallel_size=$TP \
76 --common_config_path=$CONVERT_CHECKPOINT_PATH/config/cogvlm2-19b/vision-patch.json \
77 --load_ckpt_path=$LOAD \
78 --save_ckpt_path=$SAVE_PATCH
79
80# 第6步:将以上5步的产出结果进行合并
81python $CONVERT_CHECKPOINT_PATH/custom/cogvlm/merge_huggingface.py \
82 --megatron_path $AIAK_MAGATRON_PATH \
83 --language_expert_path $SAVE_LANGUAGE_EXPERT \
84 --vision_expert_path $SAVE_VISION_EXPERT \
85 --vision_model_path $SAVE_VISION_MODEL \
86 --vision_patch $SAVE_PATCH \
87 --adapter_path $SAVE_ADAPTER \
88 --save_ckpt_path $SAVE
89
90# 删除前5步产出的临时结果
91rm -rf $SAVE_LANGUAGE_EXPERT
92rm -rf $SAVE_VISION_EXPERT
93rm -rf $SAVE_VISION_MODEL
94rm -rf $SAVE_ADAPTER
95rm -rf $SAVE_PATCH运行参数说明
新增参数具体见aiak_training_llm/train/arguments.py文件。其中关键参数:
-
--trainable-modules:用于指定可训练的模块,可多选:
- all :训练所有参数(如果仅需要训练部分参数,请指定下述参数);
- vision_model:训练视觉 Encoder 模型参数,比如 ViT Encoder
- adapter:训练视觉模型和语言模型的适配器,比如MLP Adapter
- language_model:训练语言 Decoder 模型的参数(同时包括语言模型中的 visual expert);(如果需要控制不同模态的参数训练,请指定下述参数)
- vision_expert_linear:训练视觉专家线性层参数,包括:Attention中的linear_qkv和linear_proj,和MLP中的linear_fc1、linear_fc2。
- language_expert_linear:训练语言专家线性层参数, 包括:Attention中的linear_qkv、linear_proj,和MLP中的linear_fc1、linear_fc2。
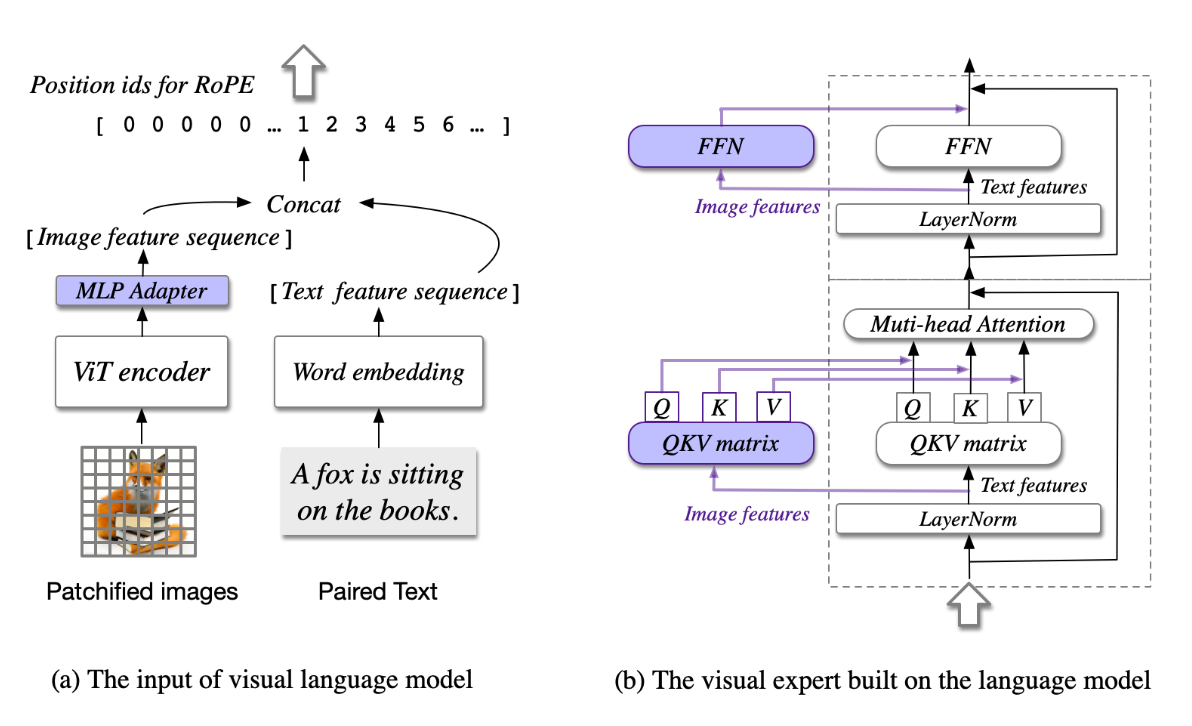
注:在原始 CogVLM1的论文中,仅 MLP Adapter和 Vision Expert参与训练,那么 --trainable-modules 可设置为 adapter vision_expert_linear(与下述示例脚本一致),此时其他的权重将会 freeze,不参与参数更新;
- --no-rope-in-fp32:可选,使语言模型的中rope参数精度与模型一致,而非默认的float32。详见 https://huggingface.co/THUDM/cogvlm2-llama3-chat-19B/blob/f592f291cf528389b2e4776b1e84ecdf6d71fbe3/util.py#L376
启动示例
pretrain
1#! /bin/bash
2
3MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
4AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
5
6DATA_PATH=${DATA_PATH:-"/mnt/pfs/aiak-training-llm/cogvlm2/CogVLM-SFT-311K/llava_details-minigpt4_3500_formate/"}
7
8TOKENIZER_PATH=${TOKENIZER_PATH:-"//mnt/pfs/huggingface.co/THUDM/cogvlm2-llama3-chinese-chat-19B/"}
9
10CHECKPOINT_PATH=${CHECKPOINT_PATH:-"/mnt/pfs/aiak-training-llm/cogvlm2/mcore_cogvlm2_llama3_chinese_chat_19B_tp4_pp1"}
11
12TENSORBOARD_PATH=${TENSORBOARD_PATH:-"/mnt/pfs/aiak-training-llm/tensorboard-log/cogvlm2-llama3-chinese-chat-19B-pretrain"}
13
14GPUS_PER_NODE=8
15
16# Change for multinode config
17MASTER_ADDR=${MASTER_ADDR:-"localhost"}
18MASTER_PORT=${MASTER_PORT:-"6000"}
19NNODES=${WORLD_SIZE:-"1"}
20NODE_RANK=${RANK:-"0"}
21
22DISTRIBUTED_ARGS=(
23 --nproc_per_node $GPUS_PER_NODE
24 --nnodes $NNODES
25 --node_rank $NODE_RANK
26 --master_addr $MASTER_ADDR
27 --master_port $MASTER_PORT
28)
29
30# or you can setup llama3-8b by using the following command
31MODEL_ARGS=(
32 --model-name cogvlm2-llama3-chinese-chat-19b
33 --rotary-base 500000
34)
35
36IMG_ARGS=(
37 --img-h 1344
38 --img-w 1344
39 --patch-dim 14
40)
41
42DATA_ARGS=(
43 --tokenizer-type HFTokenizer
44 --hf-tokenizer-path $TOKENIZER_PATH
45 --data-path $DATA_PATH
46 --split 949,50,1
47)
48
49TRAINING_ARGS=(
50 --training-phase pretrain
51 --trainable-modules vision_expert_linear adapter
52 --seq-length 4096
53 --max-position-embeddings 4096
54 --init-method-std 0.02
55 --micro-batch-size 1
56 --global-batch-size 2
57 --lr 0.0002
58 --min-lr 1.0e-5
59 --clip-grad 1.0
60 --weight-decay 0.01
61 --optimizer adam
62 --adam-beta1 0.9
63 --adam-beta2 0.95
64 --adam-eps 1e-05
65 --norm-epsilon 1e-05
66 --train-iters 50000
67 --lr-decay-iters 50000
68 --lr-decay-style cosine
69 --lr-warmup-fraction 0.002
70 --initial-loss-scale 65536
71 --bf16
72 --no-rope-in-fp32
73 --load $CHECKPOINT_PATH
74 --save $CHECKPOINT_PATH
75 --save-interval 5000
76 --eval-interval 1000
77 --eval-iters 10
78 --no-load-optim
79 --no-load-rng
80 #--ckpt-step 0
81)
82
83MODEL_PARALLEL_ARGS=(
84 --pipeline-model-parallel-size 1
85 --tensor-model-parallel-size 4
86 --use-distributed-optimizer
87 --overlap-grad-reduce
88 --overlap-param-gather
89 --distributed-backend nccl
90 #--sequence-parallel
91)
92
93LOGGING_ARGS=(
94 --log-interval 1
95 --tensorboard-dir ${TENSORBOARD_PATH}
96 --log-timers-to-tensorboard
97)
98
99if [ -n "${WANDB_API_KEY}" ]; then
100 LOGGING_ARGS+=(
101 --wandb-project ${WANDB_PROJECT}
102 --wandb-exp-name ${WANDB_NAME}
103 )
104fi
105
106PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
107 torchrun ${DISTRIBUTED_ARGS[@]} \
108 $AIAK_TRAINING_PATH/aiak_training_llm/train.py \
109 ${MODEL_ARGS[@]} \
110 ${DATA_ARGS[@]} \
111 ${IMG_ARGS[@]} \
112 ${TRAINING_ARGS[@]} \
113 ${MODEL_PARALLEL_ARGS[@]} \
114 ${LOGGING_ARGS[@]}SFT
1#! /bin/bash
2
3MEGATRON_PATH=${MEGATRON_PATH:-"/workspace/AIAK-Megatron"}
4AIAK_TRAINING_PATH=${AIAK_TRAINING_PATH:-"/workspace/AIAK-Training-LLM"}
5
6DATA_PATH=${DATA_PATH:-"/mnt/pfs/aiak-training-llm/cogvlm2/CogVLM-SFT-311K/llava_instruction_multi_conversations_formate/"}
7
8TOKENIZER_PATH=${TOKENIZER_PATH:-"//mnt/pfs/huggingface.co/THUDM/cogvlm2-llama3-chinese-chat-19B/"}
9
10CHECKPOINT_PATH=${CHECKPOINT_PATH:-"/mnt/pfs/aiak-training-llm/cogvlm2/mcore_cogvlm2_llama3_chinese_chat_19B_tp4_pp1"}
11
12TENSORBOARD_PATH=${TENSORBOARD_PATH:-"/mnt/pfs/aiak-training-llm/tensorboard-log/cogvlm2-llama3-chinese-chat-19B-pretrain"}
13
14GPUS_PER_NODE=8
15
16# Change for multinode config
17MASTER_ADDR=${MASTER_ADDR:-"localhost"}
18MASTER_PORT=${MASTER_PORT:-"6000"}
19NNODES=${WORLD_SIZE:-"1"}
20NODE_RANK=${RANK:-"0"}
21
22DISTRIBUTED_ARGS=(
23 --nproc_per_node $GPUS_PER_NODE
24 --nnodes $NNODES
25 --node_rank $NODE_RANK
26 --master_addr $MASTER_ADDR
27 --master_port $MASTER_PORT
28)
29
30# or you can setup llama3-8b by using the following command
31MODEL_ARGS=(
32 --model-name cogvlm2-llama3-chinese-chat-19b
33 --rotary-base 500000
34)
35
36IMG_ARGS=(
37 --img-h 1344
38 --img-w 1344
39 --patch-dim 14
40)
41
42DATA_ARGS=(
43 --tokenizer-type HFTokenizer
44 --hf-tokenizer-path $TOKENIZER_PATH
45 --data-path $DATA_PATH
46 --split 949,50,1
47)
48
49TRAINING_ARGS=(
50 --training-phase sft
51 --trainable-modules vision_expert_linear adapter
52 --chat-template empty
53 --seq-length 4096
54 --max-position-embeddings 4096
55 --init-method-std 0.02
56 --micro-batch-size 1
57 --global-batch-size 2
58 --lr 0.0002
59 --min-lr 1.0e-5
60 --clip-grad 1.0
61 --weight-decay 0.01
62 --optimizer adam
63 --adam-beta1 0.9
64 --adam-beta2 0.95
65 --adam-eps 1e-05
66 --norm-epsilon 1e-05
67 --train-iters 50000
68 --lr-decay-iters 50000
69 --lr-decay-style cosine
70 --lr-warmup-fraction 0.002
71 --initial-loss-scale 65536
72 --bf16
73 --no-rope-in-fp32
74 --load $CHECKPOINT_PATH
75 --save $CHECKPOINT_PATH
76 --save-interval 5000
77 --eval-interval 1000
78 --eval-iters 10
79 --no-load-optim
80 --no-load-rng
81 #--ckpt-step 0
82)
83
84MODEL_PARALLEL_ARGS=(
85 --tensor-model-parallel-size 4
86 --use-distributed-optimizer
87 --overlap-grad-reduce
88 --overlap-param-gather
89 --distributed-backend nccl
90)
91
92LOGGING_ARGS=(
93 --log-interval 1
94 --tensorboard-dir ${TENSORBOARD_PATH}
95 --log-timers-to-tensorboard
96)
97
98if [ -n "${WANDB_API_KEY}" ]; then
99 LOGGING_ARGS+=(
100 --wandb-project ${WANDB_PROJECT}
101 --wandb-exp-name ${WANDB_NAME}
102 )
103fi
104
105PYTHONPATH=$MEGATRON_PATH:$AIAK_TRAINING_PATH:$PYTHONPATH \
106 torchrun ${DISTRIBUTED_ARGS[@]} \
107 $AIAK_TRAINING_PATH/aiak_training_llm/train.py \
108 ${MODEL_ARGS[@]} \
109 ${DATA_ARGS[@]} \
110 ${IMG_ARGS[@]} \
111 ${TRAINING_ARGS[@]} \
112 ${MODEL_PARALLEL_ARGS[@]} \
113 ${LOGGING_ARGS[@]}启用BCCL通信库
AIAK镜像中已集成 BCCL 通信库,默认采用NCCL 通信库,可以通过环境变量来开启 BCCL
开启方式为:export LD_LIBRARY_PATH=$BCCL_PATH:$LD_LIBRARY_PATH;
当前版本仅支持在A800上使用BCCL,H800及其他型号的GPU暂未支持
评价此篇文章