
快速部署Swift微调大语言模型
准备环境和资源
登陆百度百舸·AI计算平台, 进入AI计算资源>轻量计算实例,点击 添加节点 按钮,将已开通的云服务器添加到百舸平台中用于快速部署Swift。若轻量资源中已添加云服务器节点,可跳过此步骤。
安装Swift
在 工具市场 中选择Swift模版,点击 创建服务 按钮,使用轻量资源快速部署Swift。
前置准备
模型导入
以baichuan2-7b-chat(https://modelscope.cn/models/baichuan-inc/Baichuan2-7B-Chat/summary) 为例,下载并导入至路径/root/swift/examples/pytorch/llm/。
创建目录/root/swift/examples/pytorch/llm/baichuan-inc,并导入大模型。
- 对于已通过百舸控制台挂载了该CFS的节点,会将该实例映射到新建容器实例的/root/data下,拷贝/root/data/model/Baichuan2-7B-Chat至目的路径;
- 未通过上述情况挂载的节点,也可手动挂载,然后通过docker cp的方式将模型导入容器的目的路径。
如无特殊情况,建议对/root/data做只读操作,否则可能导致模型丢失。
数据集导入
Swift会自动检测并从modelscope下载LLM微调所需的已注册数据集(见https://github.com/modelscope/ms-swift/blob/main/swift/llm/utils/dataset.DatasetName),并存储在/root/.cache/modelscope/hub/datasets/下。您需要结合数据集大小和来源综合考虑是否通过swift自动获取。示例中微调和推理所需的数据集advertise-gen(https://modelscope.cn/datasets/lvjianjin/AdvertiseGen)大小约18.79MB,因此直接通过swift获取。
LLM微调
使用脚本微调
单卡微调
单卡微调脚本如下:
1# Experimental environment: A10
2# 24GB GPU memory
3
4PYTHONPATH=../../.. \
5CUDA_VISIBLE_DEVICES=0 \
6torchrun \
7 llm_sft.py \
8 --model_type baichuan2-7b-chat \
9 --model_id_or_path baichuan-inc/Baichuan2-7B-Chat \
10 --model_revision master \
11 --sft_type lora \
12 --tuner_backend peft \
13 --template_type AUTO \
14 --dtype AUTO \
15 --output_dir output \
16 --dataset advertise-gen-zh \
17 --num_train_epochs 1 \
18 --max_length 2048 \
19 --check_dataset_strategy warning \
20 --quantization_bit 4 \
21 --bnb_4bit_comp_dtype bf16 \
22 --lora_rank 8 \
23 --lora_alpha 32 \
24 --lora_dropout_p 0.05 \
25 --lora_target_modules ALL \
26 --gradient_checkpointing true \
27 --batch_size 1 \
28 --weight_decay 0.1 \
29 --learning_rate 1e-4 \
30 --gradient_accumulation_steps 16 \
31 --max_grad_norm 0.5 \
32 --warmup_ratio 0.03 \
33 --eval_steps 100 \
34 --save_steps 100 \
35 --max_steps 500 \
36 --save_total_limit 2 \
37 --logging_steps 10 \
38 --deepspeed default-zero2 \执行微调的脚本:
1conda activate swift
2cd /root/swift/examples/pytorch/llm
3bash ./scripts/baichuan2_7b_chat/qlora_ddp_ds/sft_single_gpu.sh成功执行微调任务的截图如下所示,可以看到,在100轮过后,swift进行模型性能验证,并保存了checkpoint,符合脚本中定义的eval_steps和save_steps。脚本中的save_total_limit参数使得swift只会保存最新的若干个checkpoint。

训练完成后,swift会进行评测出最优checkpoint,可在output/baichuan2-7b-chat/v5-20241030-202927目录下查看训练结果。
多卡微调
多卡微调脚本如下,master_port为多卡通信端口,为了避免与百舸轻量服务发生端口冲突,建议master_port的选择避开20000-30000区间。
1# Experimental environment: 2 * A10
2# 2 * 24GB GPU memory
3nproc_per_node=2
4
5PYTHONPATH=../../.. \
6CUDA_VISIBLE_DEVICES=0,1 \
7torchrun \
8 --nproc_per_node=$nproc_per_node \
9 --master_port 4000 \
10 llm_sft.py \
11 --model_type baichuan2-7b-chat \
12 --model_id_or_path baichuan-inc/Baichuan2-7B-Chat \
13 --model_revision master \
14 --sft_type lora \
15 --tuner_backend peft \
16 --template_type AUTO \
17 --dtype AUTO \
18 --output_dir output \
19 --ddp_backend nccl \
20 --dataset advertise-gen-zh \
21 --num_train_epochs 1 \
22 --max_length 2048 \
23 --check_dataset_strategy warning \
24 --quantization_bit 4 \
25 --bnb_4bit_comp_dtype bf16 \
26 --lora_rank 8 \
27 --lora_alpha 32 \
28 --lora_dropout_p 0.05 \
29 --lora_target_modules ALL \
30 --gradient_checkpointing true \
31 --batch_size 1 \
32 --weight_decay 0.1 \
33 --learning_rate 1e-4 \
34 --gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
35 --max_grad_norm 0.5 \
36 --warmup_ratio 0.03 \
37 --eval_steps 100 \
38 --save_steps 100 \
39 --max_steps 500 \
40 --save_total_limit 2 \
41 --logging_steps 10 \
42 --deepspeed default-zero2 \执行微调的命令:
1conda activate swift
2cd /root/swift/examples/pytorch/llm
3bash ./scripts/baichuan2_7b_chat/qlora_ddp_ds/sft_multi_gpu.sh成功执行微调任务的截图如下所示,可以看到,在100轮过后,swift进行模型性能验证,并保存了checkpoint,符合脚本中定义的eval_steps和save_steps。脚本中的save_total_limit参数使得swift只会保存最新的若干个checkpoint。

训练完成后,swift会进行评测出最优checkpoint,在output/baichuan2-7b-chat/v5-20241030-202927目录下可查看训练结果。
通过WebUI微调
点击对应实例的 登录 按钮查看WebUI访问地址及账号密码,登录WebUI。此步骤将只展示通过WebUI界面执行多卡微调任务的示例。
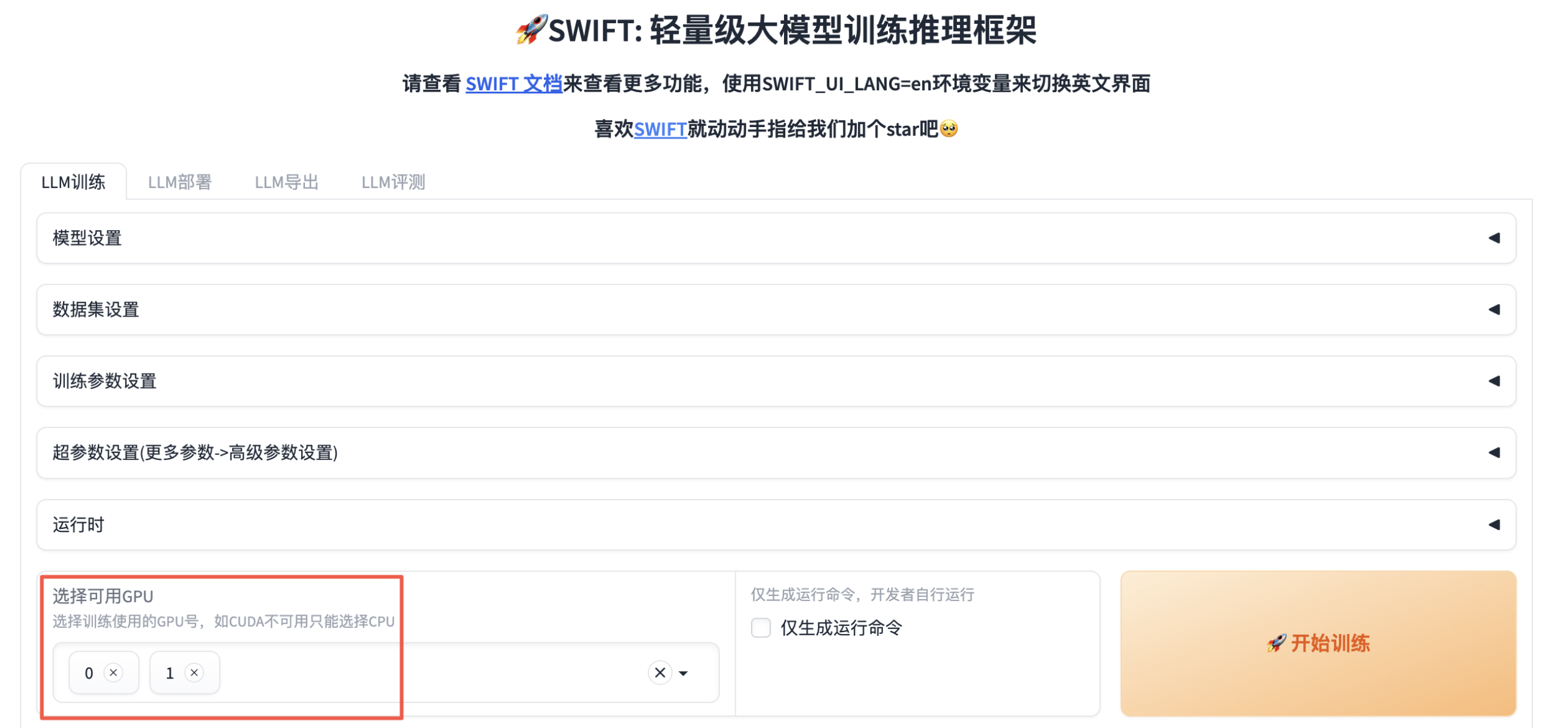
在WebUI界面中【选择可用GPU】不建议在无可用CUDA的环境下执行微调、推理等任务。
参数配置
参照多卡微调,WebUI界面选项设置如下:
- 模型设置:【选择模型】栏选择baichuan2-7b-chat,然后【模型id或路径】和【模型Prompt模板类型】会自动生成。这里修改【模型id或路径】为/root/swift/examples/pytorch/llm/baichuan-inc/Baichuan2-7B-Chat,用户可以选择其他自定义目录。这里的【模型Prompt模板类型】,也即--template_type参数值为baichuan,和脚本中的AUTO是等价的;
- 数据集设置:【数据集名称】选择advertise-gen-zh,其余保持默认;
- 训练参数设置:勾选【使用DDP】,DDP分片数量默认值为2,等同于脚本中的nproc_per_node设置。单卡训练忽略DDP设置。其余保持默认;
- 超参数设置:【交叉验证步数】和【存储步数】选择100,【梯度累计步数】选择8。这里同样修改了【存储目录】为/root/swift/examples/pytorch/llm/output,用户可以使用其他自定义存储目录。其余保持默认;
- LoRA参数设置:保持默认;
- 量化参数设置:选择【量化bit数】为4,设置bnb_4bit_comp_dtype为bf16。其余可保持默认;
- 高级参数设置:【日志打印步数】选择10,【最大迭代步数】选择500,【学习率warmup比例】选择0.03,【梯度裁剪】选择0.5,【deepspeed】选择default-zero2,单卡训练忽略deepspeed设置。通过【其他高级参数】,可以进行save_total_limit(默认2)、master_port(默认29500)等参数的设置,其余保持默认;
- 其他选项保持默认。
开始微调
- 完成上述选项配置后,点击【开始训练】,执行微调任务;
- 在训练过程中,可以打开【运行时】,点击【展示运行状态】,就能看到日志和训练、验证loss等信息。
 打开运行状态查看后,如果存在长时间等待或刷新后为空,请通过tail -f 日志路径/run.log查看训练情况。
3.可以在目录/root/swift/examples/pytorch/llm/output/下找到训练结果。
打开运行状态查看后,如果存在长时间等待或刷新后为空,请通过tail -f 日志路径/run.log查看训练情况。
3.可以在目录/root/swift/examples/pytorch/llm/output/下找到训练结果。
模型测试
使用脚本测试
脚本中采用多卡微调保存的checkpoint-500作为推理模型,如ckpt_dir参数所示。
1# Experimental environment: A10
2PYTHONPATH=../../.. \
3CUDA_VISIBLE_DEVICES=0 \
4python llm_infer.py \
5 --model_type baichuan2-7b-chat \
6 --sft_type lora \
7 --dtype bf16 \
8 --ckpt_dir "output/baichuan2-7b-chat/v5-20241030-202927/checkpoint-500" \
9 --eval_human false \
10 --dataset advertise-gen-zh \
11 --max_length 2048 \
12 --load_dataset_config true \
13 --max_new_tokens 1024 \
14 --quantization_bit 4 \
15 --bnb_4bit_comp_dtype bf16 \
16 --temperature 0.9 \
17 --top_k 50 \
18 --top_p 0.7 \
19 --repetition_penalty 1. \
20 --do_sample true \
21 --merge_lora false \执行推理的命令:
1conda activate swift
2cd /root/swift/examples/pytorch/llm
3# 复制脚本到infer.sh,注意修改ckpt_dir
4vim ./scripts/baichuan2_7b_chat/qlora_ddp_ds/infer.sh
5bash ./scripts/baichuan2_7b_chat/qlora_ddp_ds/infer.sh推理结束后,对验证集的推理结果存储在ckpt_dir所在目录下的infer_result/xxx.jsonl中, 如需实时查看每一条推理结果,可通过--verbose true实现。
模型部署
使用脚本部署模型
为避免多个LLM部署端口冲突,建议部署时指定自定义端口,以3456为例,如下所示。推荐先通过netstat -tulnp | grep 3456查看自定义端口是否被占用。
1CUDA_VISIBLE_DEVICES=0 \
2swift deploy \
3 --model_type baichuan2-7b-chat \
4 --model_id_or_path baichuan-inc/Baichuan2-7B-Chat \
5 --host 127.0.0.1 \
6 --port 3456 \
7 --log_interval 10执行部署的指令:
1conda activate swift
2cd /root/swift/examples/pytorch/llm
3vim deploy.sh # 将脚本复制到deploy.sh中
4bash deploy.sh部署成功后,终端会输出类似“INFO: Uvicorn running on http://HOST:PORT”的提示,终端会每隔10s打印一次统计信息,即log_interval所设置的间隔时长。
通过WebUI部署
参数配置
- 模型设置:【选择模型】栏选择baichuan2-7b-chat,【模型id或路径】和【模型Prompt模板类型】会自动生成。这里修改【模型id或路径】为/root/swift/examples/pytorch/llm/baichuan-inc/Baichuan2-7B-Chat,可以选择其他自定义目录;
2.其他设置:取消勾选【do_sample】,【端口】改为3456,其他保持保持默认。
开始部署
- 完成上述选项配置后,点击【部署模型】,执行部署任务;
- 在部署过程中,可以打开【运行时】,点击【展示部署状态】,就能看到部署情况和访问统计等信息。
LLM导出
Swift支持原始模型或权重推送到modelscope。
示例将给出导出存储路径为/root/swift/examples/pytorch/llm/output/baichuan2-7b-chat/v1-20241104-215649/checkpoint-500的微调checkpoint,原始模型的导出与之类似,可参考https://github.com/modelscope/ms-swift/blob/main/docs/source/Instruction/LLM%E9%87%8F%E5%8C%96%E4%B8%8E%E5%AF%BC%E5%87%BA%E6%96%87%E6%A1%A3.md。
使用脚本导出
脚本中的hub_token是推送时需要的SDK token,可以从https://modelscope.cn/my/myaccesstoken获取,hub_model_id可以更换成其他自定义值。
1# 推送原始量化模型
2CUDA_VISIBLE_DEVICES=0 swift export \
3 --ckpt_dir output/baichuan2-7b-chat/v1-20241104-215649/checkpoint-500 \
4 --push_to_hub true \
5 --hub_model_id ckpt-export-test \
6 --hub_token 'YOUR_HUB_TOKEN'推送命令执行如下:
1cd /root/swift/examples/pytorch/llm/output/baichuan2-7b-chat/v1-20241104-215649/checkpoint-500
2# 首次推送某个模型或权重时执行下面3条指令
3git init
4git config --global user.email "you@example.com"
5git config --global user.name "Your Name"
6conda activate swift
7cd /root/swift/examples/pytorch/llm
8vim export.sh
9bash export.sh执行后,权重会开始上传,如下图所示:
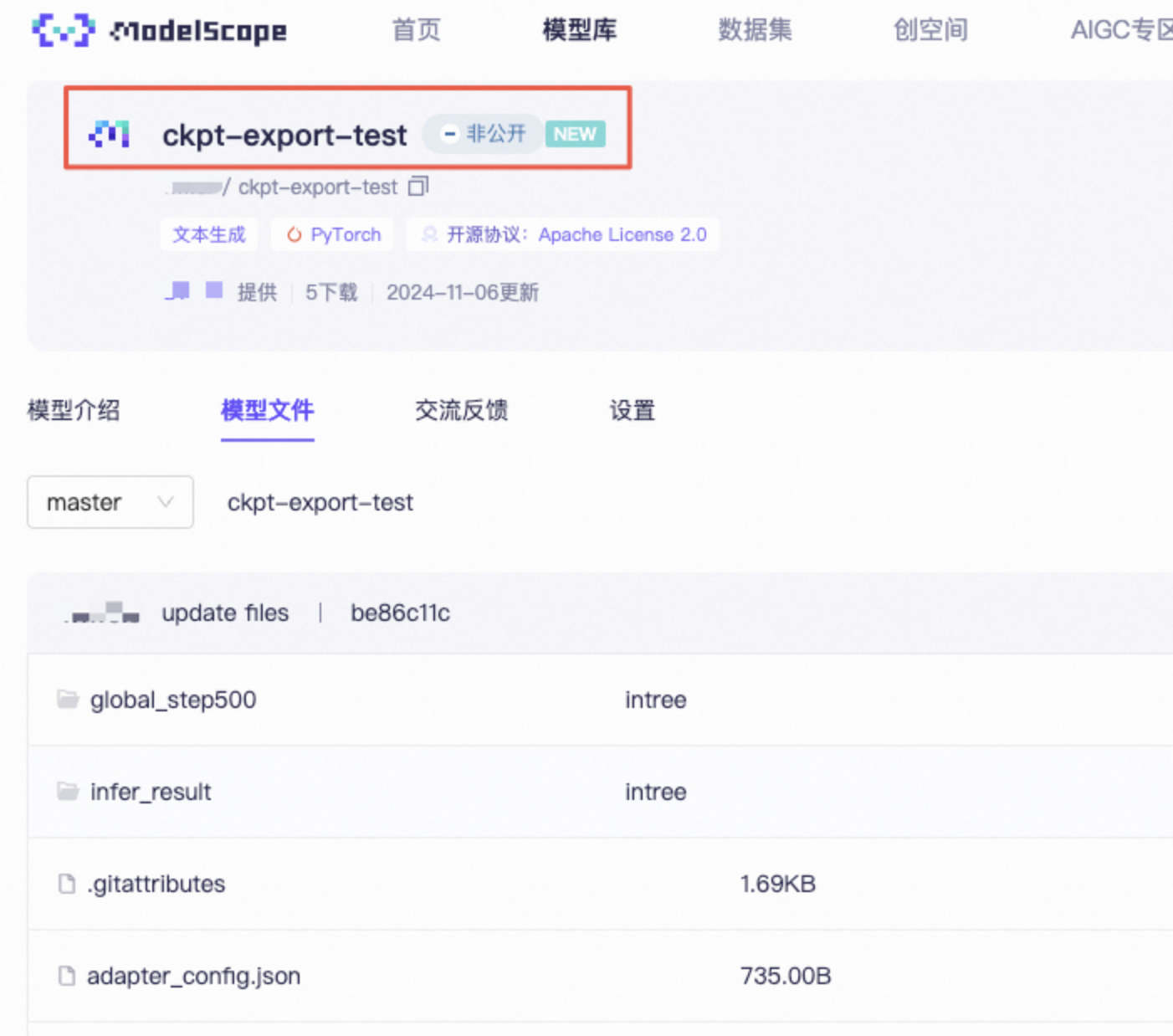
推送完成后,可以查看终端和modelscope个人主页部分:
通过WebUI导出
参数配置
- 模型设置:修改【模型id或路径】为/root/swift/examples/pytorch/llm/output/baichuan2-7b-chat/v0-20241104-210848/checkpoint-500。其余保持默认;
- 其他设置:【更多参数】中,填入--push_to_hub true --hub_model_id ckpt-export-test2 --hub_token 'YOUR_HUB_TOKEN'。其余保持默认;
开始导出
- 完成上述选项配置后,点击【开始导出】,执行导出任务;
- 在导出过程中,可以打开【运行时】,点击【展示导出状态】,查看导出信息。
模型评测
swift的评测模块基于评测框架EvalScope,以及Open-Compass,并进行了高级封装以支持各类模型的评测需求。首次评测时,如果swift未检测到本地数据集,会从modelscope下载。
使用脚本评测
LLM评测可针对原始模型和微调权重进行。
原始模型评测脚本
1CUDA_VISIBLE_DEVICES=0 swift eval \
2 --model_type baichuan2-7b-chat \
3 --model_id_or_path baichuan-inc/Baichuan2-7B-Chat \
4 --eval_dataset ARC_c\
5 --eval_output_dir output微调权重评测脚本
1# 微调后
2CUDA_VISIBLE_DEVICES=0 swift eval \
3 --ckpt_dir qwen2-7b-instruct/vx-xxx/checkpoint-xxx \
4 --eval_dataset ARC_c \
5 --merge_lora true \
6 --eval_output_dir output两个脚本执行的过程是类似的,评测执行命令如下,这里给出原始模型的评测过程。
1conda activate swift
2cd /root/swift/examples/pytorch/llm
3vim eval.sh # 将内容复制进脚本
4bash eval.sh首次执行评测时,swift会先下载预置的标准评测数据集,大小约1.79GB,评测完成评测报告存储在output/default/20241105_210022目录下。
通过WebUI评测
在评测前先部署模型,也可以先通过自定义参数部署好LLM,再基于该模型进行评测。示例将对已经在http://127.0.0.1:3456/v1部署好的模型进行评测。
参数配置
- 模型设置:【选择模型】栏选择baichuan2-7b-chat,然后【模型id或路径】和【模型Prompt模板类型】会自动生成。这里修改【模型id或路径】为/root/swift/examples/pytorch/llm/baichuan-inc/Baichuan2-7B-Chat,用户可以选择其他自定义目录;
- 数据集设置:【评测数据集】选择ARC_c,其余保持默认;
- 其他设置:【评测链接】填入http://127.0.0.1:3456/v1,【更多参数】中填入--eval_output_dir /root/swift/examples/pytorch/llm/output,其余保持默认。
开始评测
- 完成上述选项配置后,点击【开始评测】,执行评测任务;
- 在评测过程中,可以打开【运行时】,点击【展示评测状态】可以查看评测进度等信息。
- 评测结束后,可看到模型评测UI界面的运行时中,给出了评测报告和结果存储路径等信息。
其他
- 更多支持场景见https://github.com/modelscope/ms-swift/blob/main/README_CN.md
- 常见问题见https://github.com/modelscope/ms-swift/tree/main/docs/source/Instruction,该目录下包含了LLM的微调、推理、评测、量化,命令行参数解释以及自定义拓展等文档。
评价此篇文章