
使用LLaMA Factory快速微调开源大模型
准备环境和资源
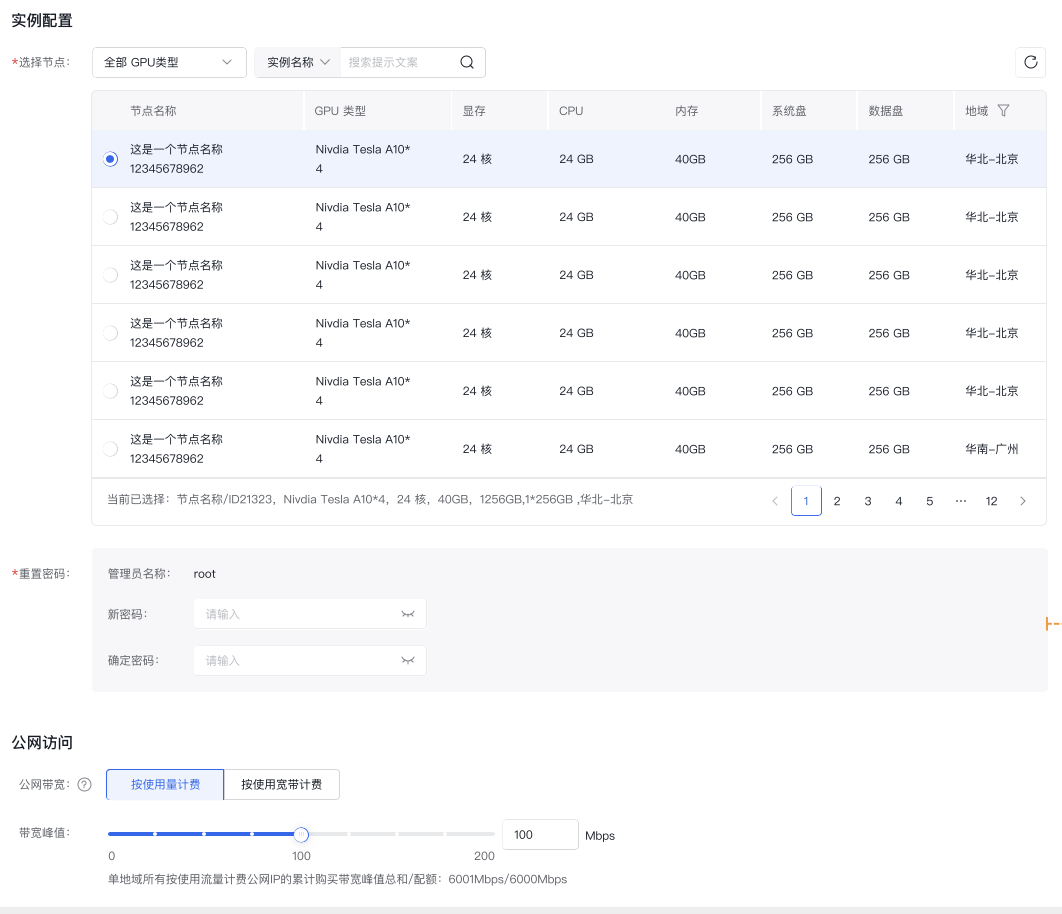
可根据资源规模、稳定性、灵活性等要求按需准备轻量计算实例或通用计算资源池,用于快速部署LLaMA Factory。
安装LLaMA Factory
- 在工具市场 选择LLaMA Factory模版,点击 部署工具 按钮,使用轻量计算实例或通用计算资源快速部署LLaMA Factory;
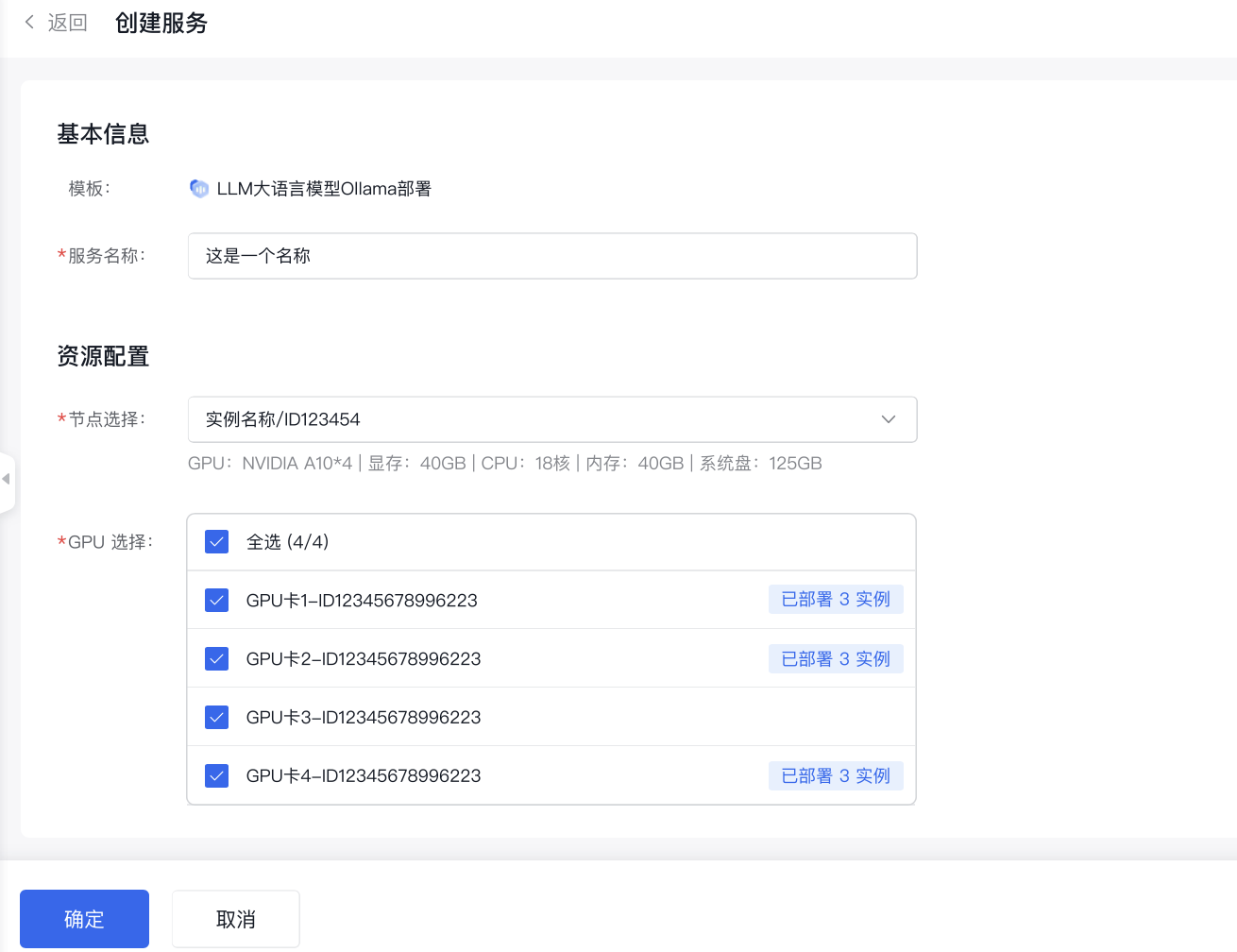
- 根据模型参数量,选择使用单机单卡、单机多卡或多机多卡进行训练。
准备数据集
LLaMA-Factory项目内置了丰富的数据集,统一存储于data目录下。您可以跳过本步骤,直接使用内置数据集。
您也可以准备自定义数据集,将数据处理为框架特定的格式。放在data下,并且修改dataset_info.json文件,具体操作步骤如下:
- 将本地数据集的json文件上传到容器实例的
LLaMA-Factory/data目录下存放。该JSON文件包含了如下格式的数据列表:
- Instruction: 模型接收的指令,明确了要执行的任务。
- Input: 模型接收的输入数据。
- Output: 模型应生成的输出数据。
- History: 累积的对话历史,用于上下文管理。
- 在
LLaMA-Factory/data/dataset_info.json中注册数据集,添加类似以下内容的字典:
1"your_dataset_name": {
2 "file_name": "dataset_name",
3 },准备模型文件
如果您在 Hugging Face 模型和数据集的下载中遇到了问题,可以通过下述方法使用魔搭社区。
1export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`将model_name_or_path设置为模型 ID 来加载对应的模型。在魔搭社区查看所有可用的模型,例如LLM-Research/Meta-Llama-3-8B-Instruct。
单机单卡、单机多卡训练
通过WebUI训练
适用于单机场景(目前多机场景还不支持使用WebUI),特别是快速测试或使用较小模型。
- 调整训练参数
根据下图红框部分调整UI界面语言后,根据所需调整训练参数即可,点击 开始 即可训练。
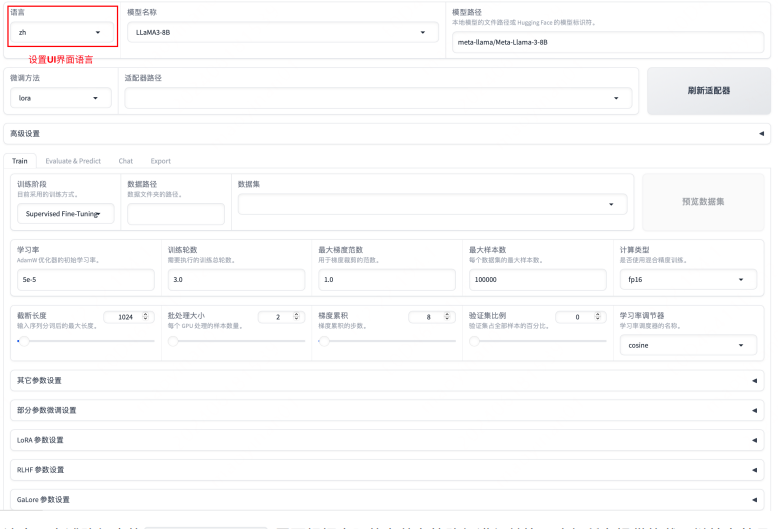
- 模型名称:选择要使用的模型模板,Llamafactory框架支持的模型见:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
- 微调方法:选择LoRA,或其他如Full-tuning、Freeze-tuning、QLoRA等
- 数据集:选择内置数据集或者之前在2.1步骤中注册的私有数据集。
-
推荐参数配置:
- 学习率:1e-4
- 计算类型:bf16(高性能方案、平衡型方案)或者fp16(性价比方案)
- 梯度积累:2
- LoRA+比率:16
- LoRA模块:all
注意:上述路径中的 _/path/to/your/_ 需要根据实际的文件存放路径进行替换。确保所有提供的截图链接有效且指向相关内容。
- 开始微调
注意: 非RDMA机型的算力资源 不支持通过 P2P (Peer-to-Peer) 或 IB (InfiniBand) 进行的更快速的通信带宽,需要禁用。
1export NCCL_P2P_DISABLE=1
2export NCCL_IB_DISABLE=1启动微调后可在界面观察到训练进度和损失曲线。当UI界面显示训练完毕时,代表模型微调成功。
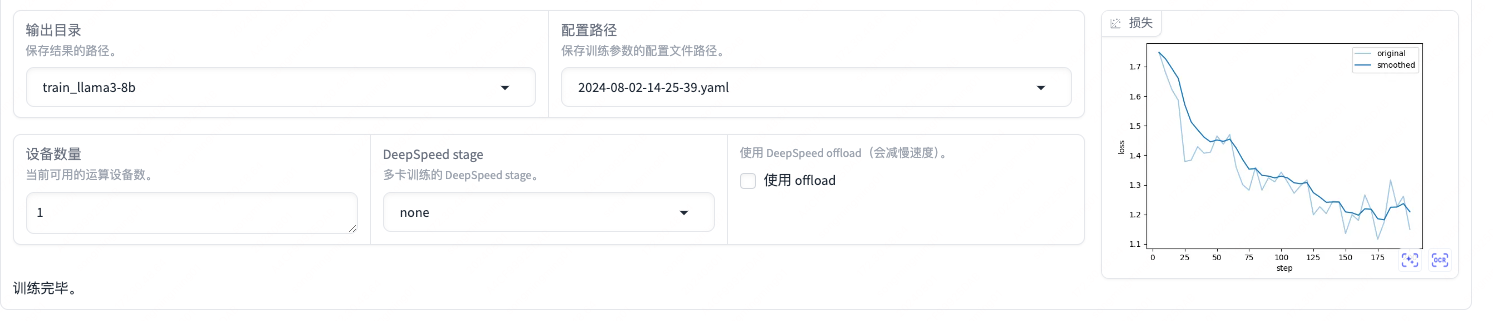
登录实例使用命令行训练
- 登录实例
在 我的工具>工具详情 中找到需要登录的实例,点击 登录 按钮,通过SSH登录实例。 如何使用SSH登录实例
- 开始微调
注意: 非RDMA机型的算力资源 不支持通过 P2P (Peer-to-Peer) 或 IB (InfiniBand) 进行的更快速的通信带宽,需要禁用。
1export NCCL_P2P_DISABLE=1
2export NCCL_IB_DISABLE=1执行:conda activate llama_factory 使用以下命令在一台机器上的多个gpu上进行训练,可以根据需求修改以下参数
1CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train \
2 --stage sft \
3 --do_train \
4 --model_name_or_path (模型位置) \
5 --dataset (数据集名称) \
6 --dataset_dir (数据集文件夹位置,即LLaMA-Factory/data) \
7 --template (llama3的话填llama3,qwen的话填qwen) \
8 --finetuning_type lora \
9 --lora_target q_proj,v_proj \
10 --output_dir (lora权重位置) \
11 --overwrite_cache \
12 --overwrite_output_dir \
13 --cutoff_len 1024 \
14 --preprocessing_num_workers 16 \
15 --per_device_train_batch_size 1 \
16 --per_device_eval_batch_size 1 \
17 --gradient_accumulation_steps 8 \
18 --lr_scheduler_type cosine \
19 --logging_steps 10 \
20 --warmup_steps 20 \
21 --save_steps 100 \
22 --eval_steps 100 \
23 --evaluation_strategy steps \
24 --load_best_model_at_end \
25 --learning_rate 5e-5 \
26 --num_train_epochs 3.0 \
27 --max_samples 3000 \
28 --val_size 0.1 \
29 --plot_loss \
30 --fp16如下是一个成功运行的示意图
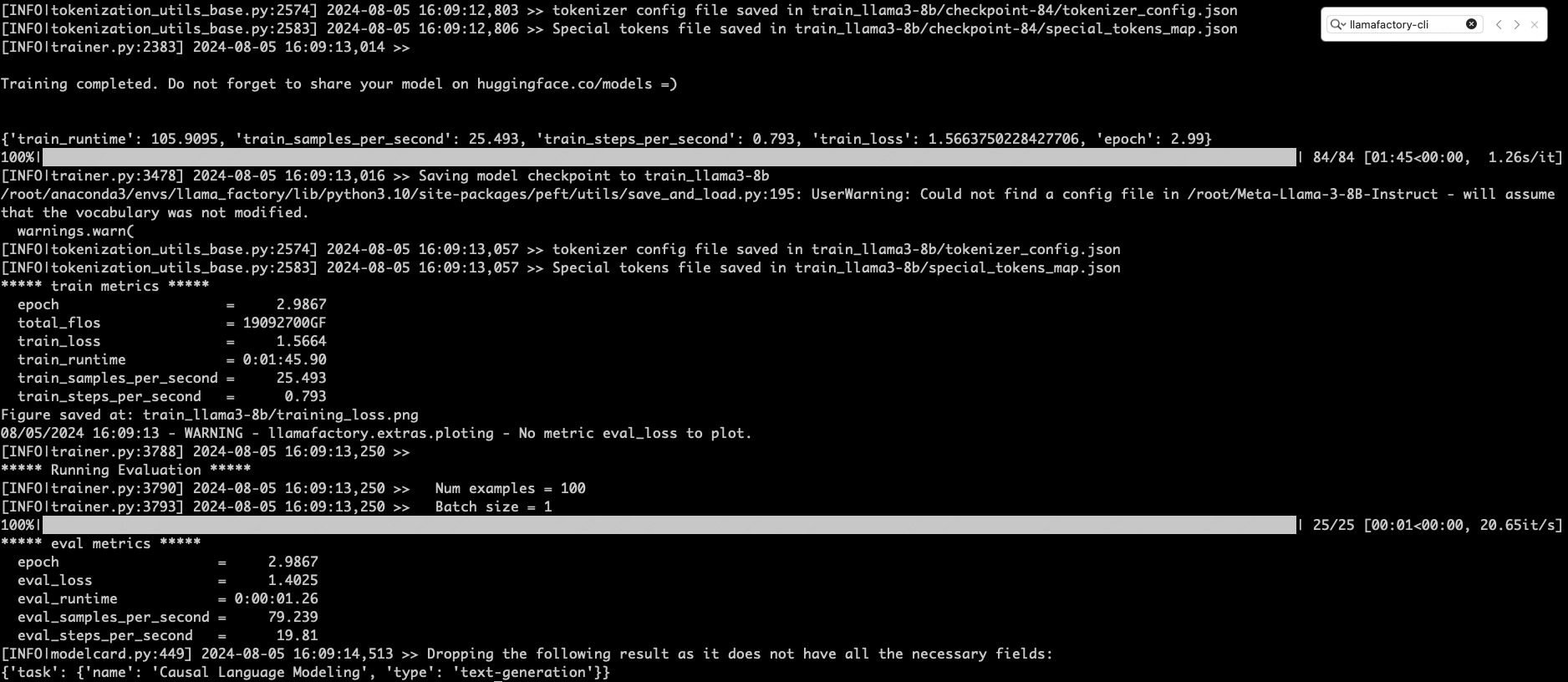
下图是验证后lora权重的存储文件夹

多机多卡训练
登录实例使用命令行训练
- 登录实例
在工具详情中找到需要登录的实例,点击 登录 按钮,通过SSH登录实例。
- 配置多机环境
使用以下命令在一台机器上的多个gpu上进行训练,可能需要配置多个节点的RANK以及MASTER的ip地址和端口。 $NPROC_PER_NODE:
- 这个值应该设置为每个节点上可用于训练的GPU数量。例如,如果你的每台服务器有4个GPU,那么这个值应该是4。
$NNODES:
- 设置为总的节点数量。如果你有两台服务器参与训练,此值应为2。
$RANK:
- 每个节点需要一个唯一的序号。一般来说,你可以在启动脚本中为每个节点分配一个序号,从0开始。例如,如果有两个节点,一个节点的rank为0,另一个为1。
$MASTER_ADDR:
- 这是主节点的IP地址。你需要选择一个节点作为主节点,并使用这个节点的IP地址。确保其他节点能够访问到这个IP地址。
$MASTER_PORT:
- 选择一个用于节点间通信的端口号。确保这个端口在所有节点上都未被占用且可以通信。
- 可以使用预留的Ext端口避免出现端口冲突
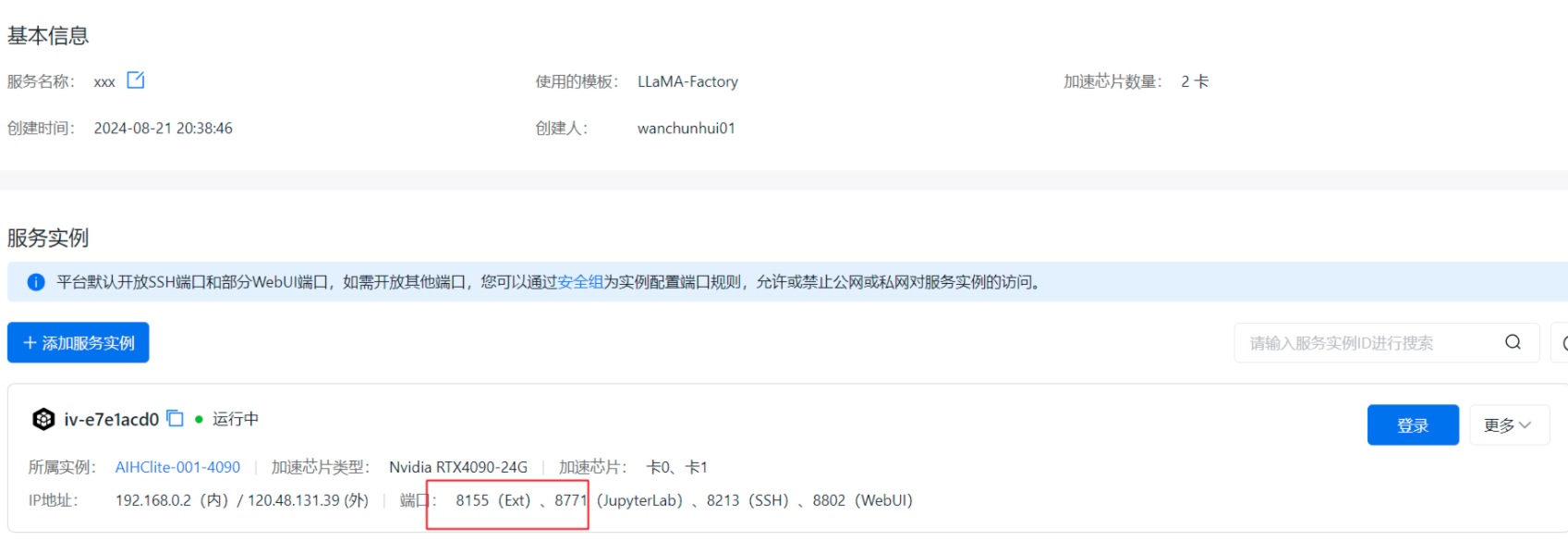
示例:
1export NPROC_PER_NODE=4
2export NNODES=2
3export RANK=0 # 这个值在不同的节点上应该不同
4export MASTER_ADDR='192.168.0.3' # 主节点的IP
5export MASTER_PORT= 31000 # 选择一个合适的端口可以使用已分配的预留端口Ext注意: 非RDMA机型的算力资源 不支持通过 P2P (Peer-to-Peer) 或 IB (InfiniBand) 进行的更快速的通信带宽,需要禁用。
1export NCCL_P2P_DISABLE=1
2export NCCL_IB_DISABLE=1- 配置多机多卡启动参数
参考./examples/train_lora/llama3_lora_sft.yaml配置启动参数存储到 /root/llama_factory/LLaMA-Factory/tools/torchrun/llama3_lora_sft.yaml
1### model
2model_name_or_path: /root/apps/model/LLM-Research/Meta-Llama-3-8B-Instruct
3
4### method
5stage: sft
6do_train: true
7finetuning_type: lora
8lora_target: all
9
10### dataset
11dataset: alpaca_zh_demo
12template: llama3
13cutoff_len: 1024
14max_samples: 1000
15overwrite_cache: true
16preprocessing_num_workers: 16
17
18### output
19output_dir: /root/apps/output/llama3-8b/lora/sft
20logging_steps: 10
21save_steps: 500
22plot_loss: true
23overwrite_output_dir: true
24
25### train
26per_device_train_batch_size: 1
27gradient_accumulation_steps: 8
28learning_rate: 1.0e-4
29num_train_epochs: 3.0
30lr_scheduler_type: cosine
31warmup_ratio: 0.1
32fp16: true
33ddp_timeout: 180000000
34
35### eval
36val_size: 0.1
37per_device_eval_batch_size: 1
38eval_strategy: steps
39eval_steps: 500- 开始微调
分别在两台机器启动训练,两台机器要有同样的配置和基础模型
1cd /root/llama_factory/LLaMA-Factory
2FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.3 MASTER_PORT=31000 llamafactory-cli train tools/torchrun/llama3_lora_sft.yaml
3
4FORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.3 MASTER_PORT=31000 llamafactory-cli train tools/torchrun/llama3_lora_sft.yaml训练完成的模型会保存在主节点
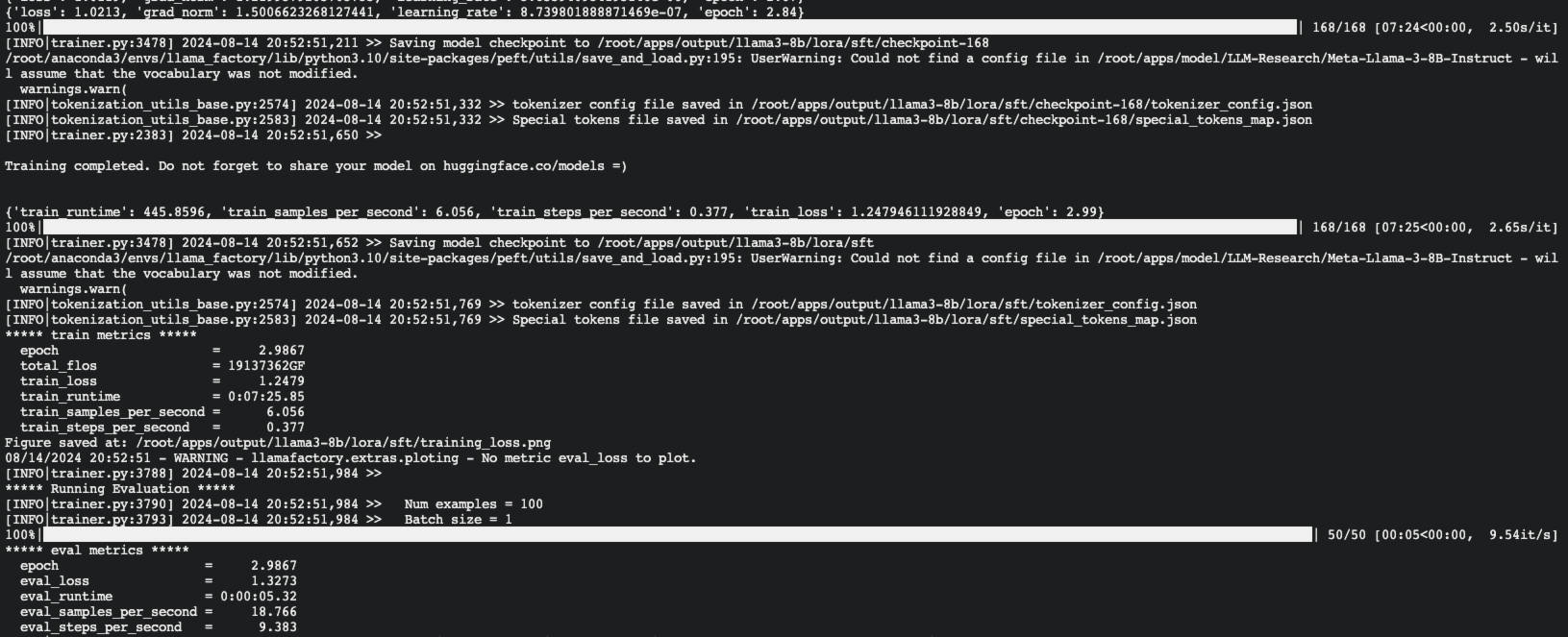
模型评估和试用
模型评估
然后将适配器路径选择之前训练的模型,点击 开始,等待模型评估结果。
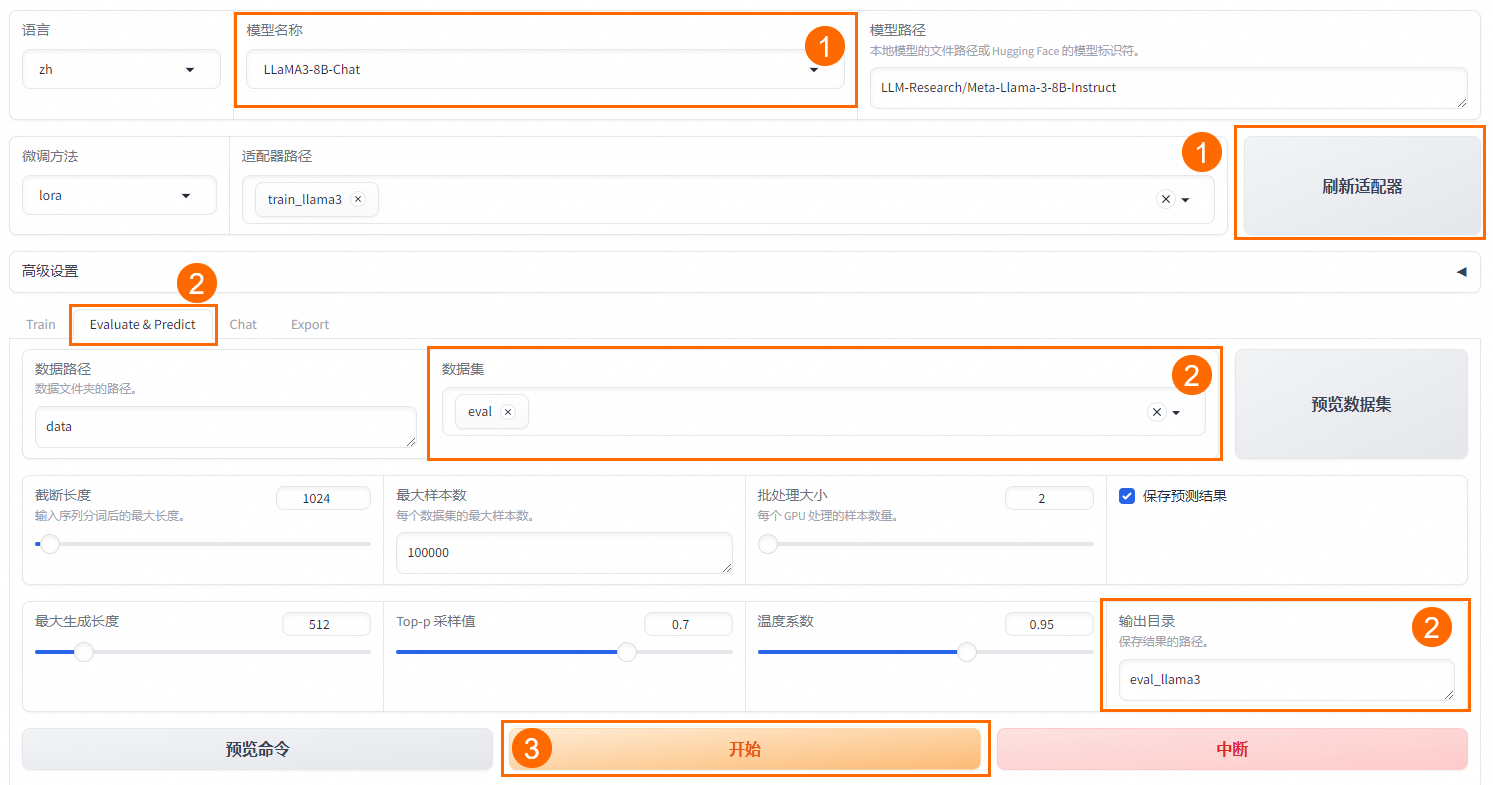
- 模型微调完成后,切换WebUI中的Train选项至Evaluate&Predict,单机页面中刷新适配器按钮,单击适配器路径,选择下拉列表中的模型,在模型启动时即可加载微调结果。
- 在Evaluate&Predict页签中,数据集选择eval(验证集)评估模型,修改输出目录,模型评估结果将会保存在该目录中。
- 单击开始,启动模型评估。模型评估大约需要5分钟,评估完成后会在界面上显示验证集的分数。其中,ROUGE分数衡量了模型输出答案(predict)和验证集中的标准答案(label)的相似度,ROUGE分数越高代表模型学习得越好。
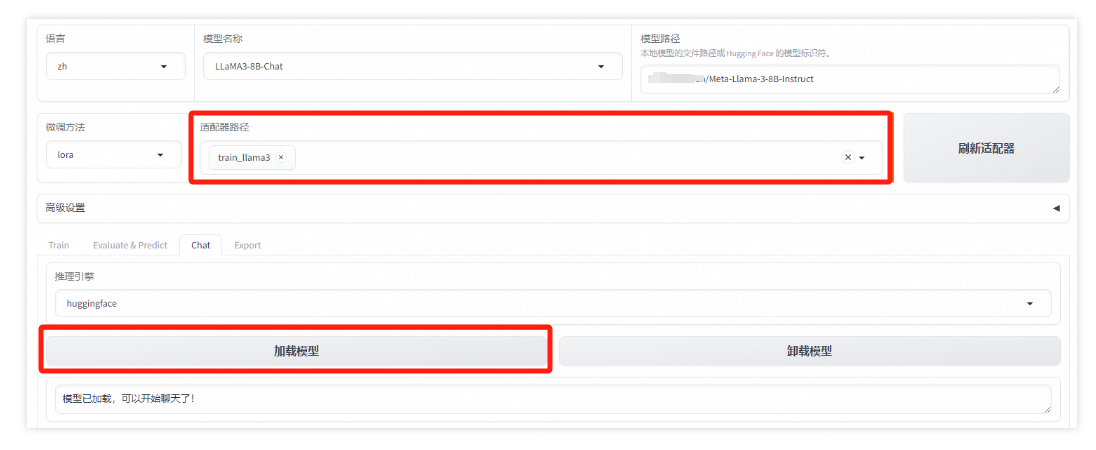
模型试用
在Chat页签中,单击页面中刷新适配器按钮,然后将适配器路径选择之前训练的模型,点击 加载模型,开始聊天。
评价此篇文章