
一键部署CosyVoice进行语音生成
CosyVoice是一款基于语音量化编码的语音生成大模型,能够根据各类文本内容生成多语言、音色和情感控制的语音。百舸工具市场预置了CosyVoice镜像模板,您可以使用该模板快速搭建基于AIGC CosyVoice的AI-Web服务。使用该服务,实现多语言语音生成和零样本语音生成等多种语音合成的功能
准备环境和资源
可根据资源规模、稳定性、灵活性等要求,在AI计算资源中,按需准备轻量计算实例或自运维计算资源池,用于快速部署CosyVoice。
安装CosyVoice
- 在 工具市场 中选择CosyVoice模版,点击 部署工具 按钮;
- 选择为部署工具所需的实例规格和卡数;
- 完成配置后点击部署,当工具状态从创建中变为运行中,表明工具已部署成功。
访问CosyVoice
目前CosyVoice镜像模板的text-to-speech推理支持WebUI、代码调用和RPC服务三种方式,功能包括:预训练音色、3s极速复刻、跨语种复刻和自然语言控制。 查看对应CosyVoice实例,点击 登录按钮,查看WebUI访问地址,登录WebUI。
预训练音色
CosyVoice预训练了中文男/女、英文男/女、日语男、粤语女和韩语女7种音色。
WebUI
【选择推理模式】勾选“预训练音色”,然后【输入合成文本】中输入想要生成语音的文本。然后点击【生成音频】,即可完成语音合成,如下所示。【选择预训练音色】、【语速调节】等可自行调整。 目前WebUI生成的音频文件下载到本地后大小为0B,该问题和gradio依赖库有关。
代码调用
通过代码调用的方式,可以利用不同预置模型、批量地执行多个语音合成推理任务。如/root/CosyVoice/test.py所示,5-10行为预训练音色TTS任务。
1from cosyvoice.cli.cosyvoice import CosyVoice
2from cosyvoice.utils.file_utils import load_wav
3import torchaudio
4
5cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT')
6# sft usage
7print(cosyvoice.list_avaliable_spks())
8# change stream=True for chunk stream inference
9for i, j in enumerate(cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女', stream=False)):
10 torchaudio.save('sft_{}.wav'.format(i), j['tts_speech'], 22050)
11
12cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M')
13# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
14prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
15for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
16 torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], 22050)
17# cross_lingual usage
18prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
19for i, j in enumerate(cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k, stream=False)):
20 torchaudio.save('cross_lingual_{}.wav'.format(i), j['tts_speech'], 22050)
21
22cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
23# instruct usage, support <laughter></laughter><strong></strong>[laughter][breath]
24for i, j in enumerate(cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.', stream=False)):
25 torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], 22050)执行:
1conda activate cosy
2python /root/CosyVoice/test.py合成的结果会保存在预设的目录下。
RPC服务
启动RPC服务端命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python server.py --port 8488 --model_dir /root/CosyVoice/pretrained_models/CosyVoice-300M-SFT成功启动服务端时,服务端输出如下所示:
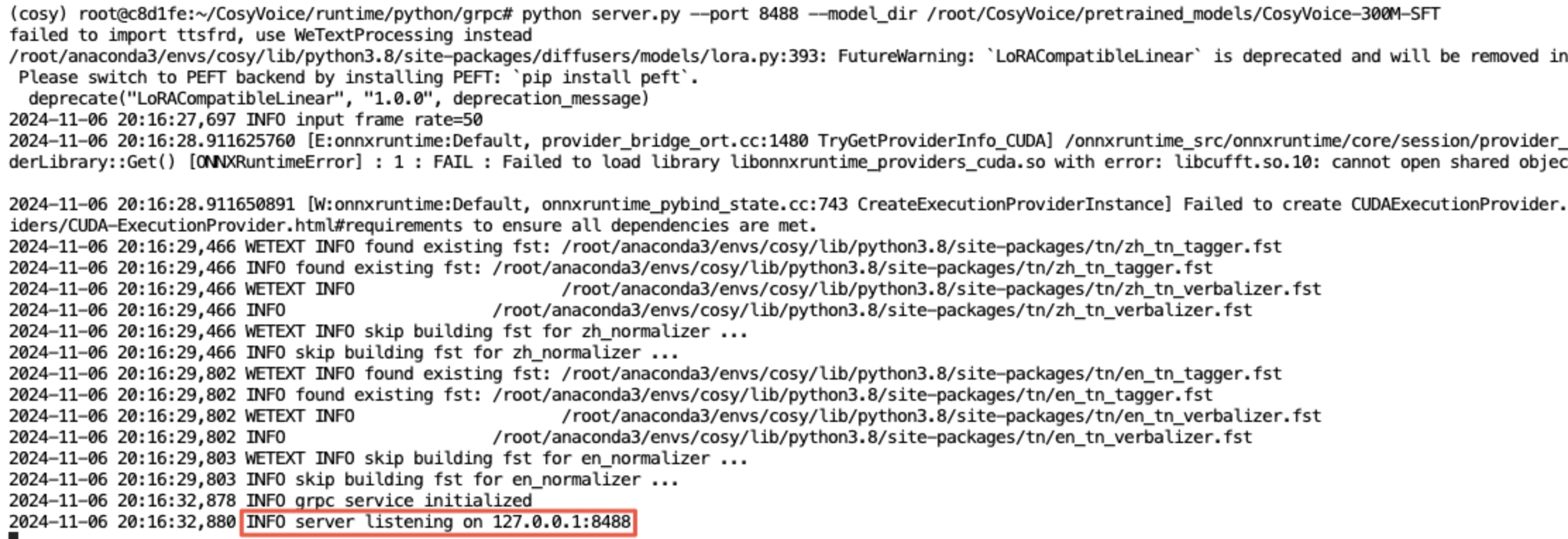
启动RPC客户端并执行预训练音色TTS任务命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python client.py --port 8488 --tts_text "用科技让复杂的世界更简单"生成的音频文件存储在默认值,即./demo.wav下

3s极速复刻
- 选择prompt音频文件或录入prompt音频,注意不超过30s,若同时提供,优先选择prompt音频文件
- 输入prompt文本
- 点击生成音频按钮
WebUI
【选择推理模式】勾选“3s极速复刻”,然后【输入合成文本】中输入想要生成语音的文本。上传prompt音频文件,并输入prompt文本。然后点击【生成音频】。
代码调用
1cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M')
2# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
3prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
4for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
5 torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], 22050)RPC服务
相关参数见 RPC参数说明
启动RPC服务端命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python server.py --port 8488 --model_dir /root/CosyVoice/pretrained_models/CosyVoice-300M启动RPC客户端并执行3s极速复刻TTS任务命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python client.py --port 8488 --tts_text "收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。" --prompt_wav "../../../zero_shot_prompt.wav" --prompt_text "希望你以后能够做的比我还好呦。" --mode zero_shot生成的音频文件存储在默认值,即./demo.wav下。
跨语种复刻
WebUI
【选择推理模式】勾选“跨语种复刻”,然后【输入合成文本】中输入想要生成语音的文本,并上传或录制prompt音频文件。虽然推荐合成文本使用和prompt音频文件不同的语言,但不满足该条件时,任务仍然能够成功执行。最后,点击【生成音频】。
跨语种复刻任务会学习音频文件的音色,然后通过该音色生成指定合成文本的音频。对于该任务,【选择预训练音色】按钮是“无效”的。
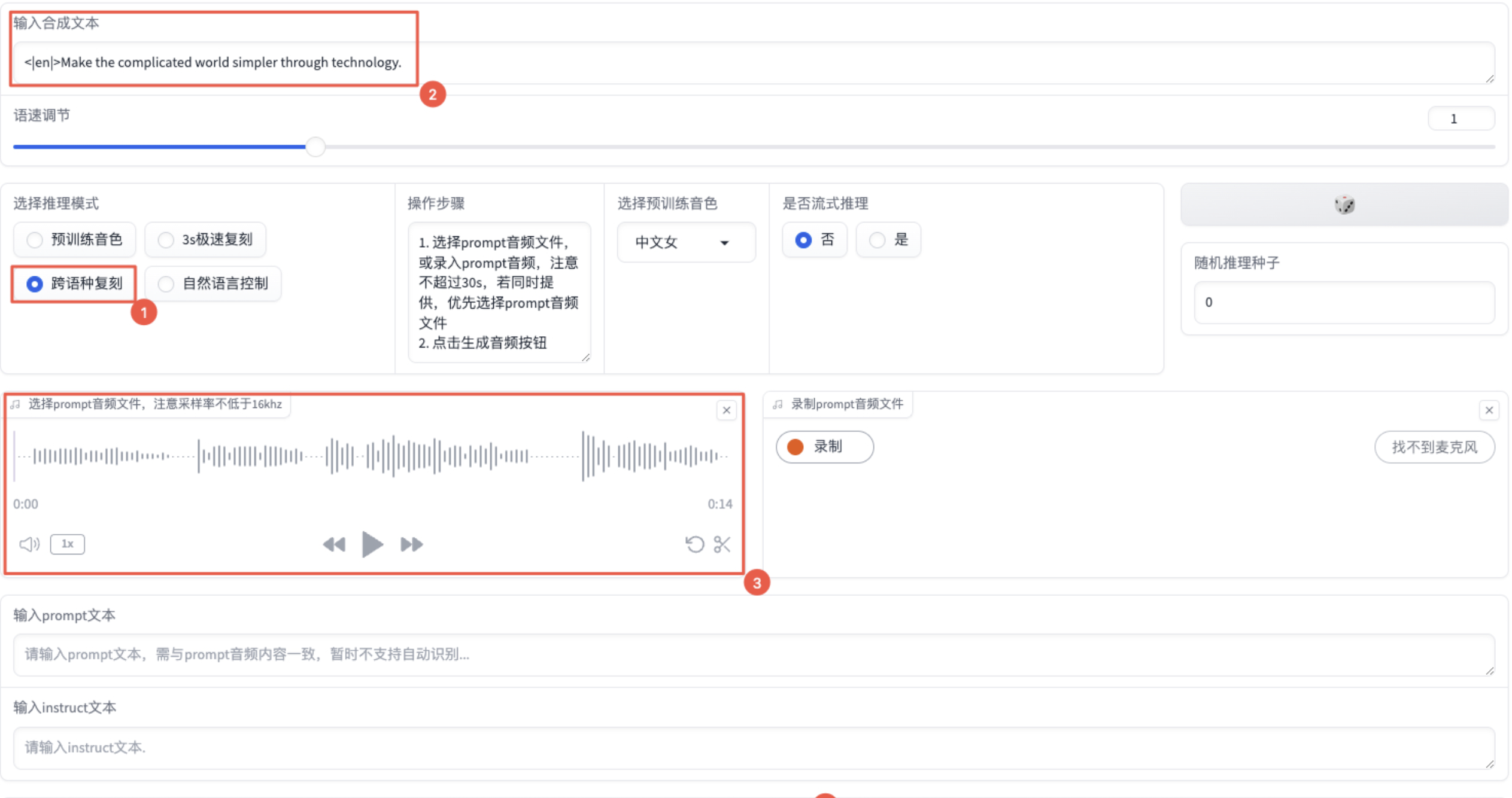
代码调用
1prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
2for i, j in enumerate(cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k, stream=False)):
3 torchaudio.save('cross_lingual_{}.wav'.format(i), j['tts_speech'], 22050)RPC服务
相关参数见 RPC参数说明
启动RPC服务端命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python server.py --port 8488 --model_dir /root/CosyVoice/pretrained_models/CosyVoice-300M成功启动服务端时,服务端输出如下所示:
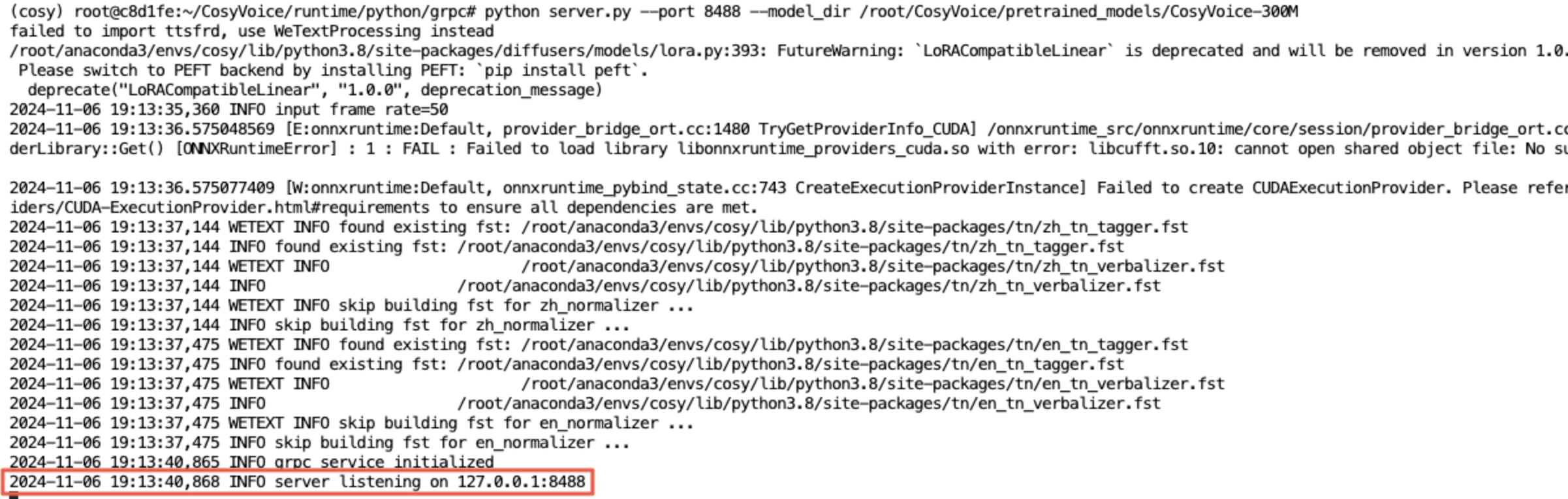
启动RPC客户端并执行跨语种复刻TTS任务命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python client.py --port 8488 --tts_text "<|en|>Make the complicated world simpler through technology" --prompt_wav "../../../cross_lingual_prompt.wav" --mode cross_lingual生成的音频文件存储在默认值,即./demo.wav下。
自然语言控制
instruct文本通常用于提供明确的指示或上下文,以便生成的语音能够更准确地反映预期的情感、语气或风格。
CosyVoice支持的富文本目前包括:
<laughter></laughter>:中间的文本带有微笑语气;<strong></strong>:中间的文本带被刻意强调;[laughter][breath]:分别是笑声和深呼吸。
WebUI
由于任务不兼容,因此需要先手动启动一个加载了CosyVoice-300M-Instruct的UI界面,如下所示。访问 http://宿主机公网IP:YOUR_PORT/。
【选择推理模式】勾选“自然语言控制”,然后【输入合成文本】中输入想要生成语音的文本,并通过【输入instruct】文本描述语境。最后,点击【生成音频】。
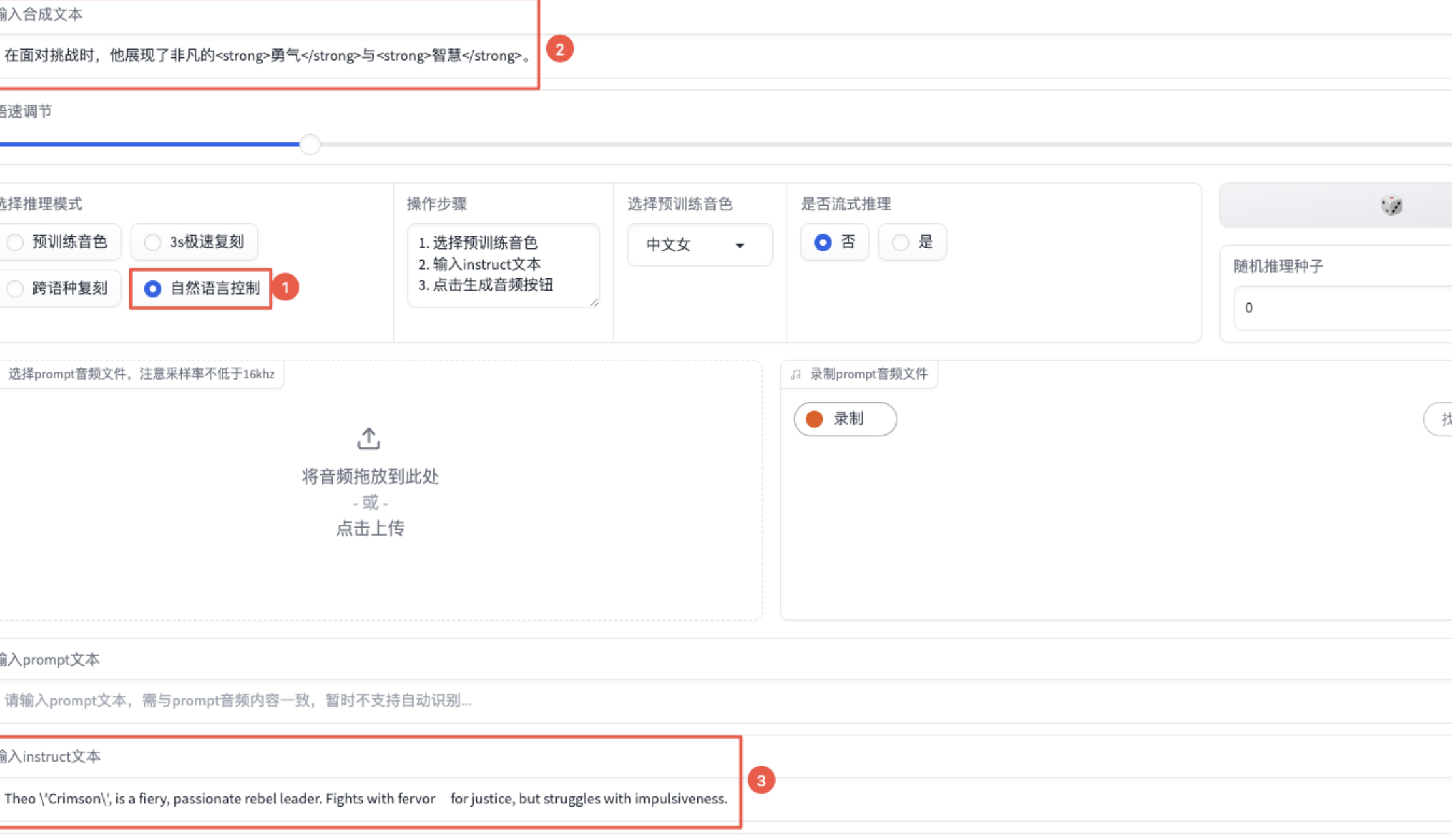
代码调用
1cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
2# instruct usage, support <laughter></laughter><strong></strong>[laughter][breath]
3for i, j in enumerate(cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.', stream=False)):
4 torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], 22050)RPC服务
相关参数见RPC参数说明
启动RPC服务端命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python server.py --port 8488 --model_dir /root/CosyVoice/pretrained_models/CosyVoice-300M-Instruct启动RPC客户端并执行跨语种复刻TTS任务命令如下所示:
1conda activate cosy
2cd /root/CosyVoice/runtime/python/grpc
3python client.py --port 8488 --tts_text "在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>" --instruct_text "Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness." --mode instruct生成的音频文件存储在默认值,即./demo.wav下。
模型选择和下载
模型下载
平台在目录下有内置基础模型,可以满足大部分语音合成需求。若对推理效果和质量有更高要求,可以在 https://huggingface.co/ 或 https://civitai.com/ 搜索和下载。
模型上传
平台为每个服务内置了JupyterLab,您可以通过JupyterLab 上传模型;单击 登录 查看JupyterLab访问地址,登录JupyterLab。选择目的路径,上传模型。
其他
模型说明
- 对于预训练音色(sft inference),推荐CosyVoice-300M-SFT模型;
- 对于3s极速复刻(zero_shot inference)/跨语种复刻(cross_lingual inference),推荐CosyVoice-300M模型;
- 对于自然语言控制(instruct inference),推荐CosyVoice-300M-Instruct模型。
WebUI启用的模型遵从源码默认值,即CosyVoice-300M,该模型无法完成自然语言控制TTS任务,如果用户需要,可自行启动webui界面,或通过代码/RPC的方式进行。
RPC参数说明
服务端
- --port,监听端口,默认值50000;
- --max_conc,最大连接数,默认值4;
- --model_dir,模型路径,默认值iic/CosyVoice-300M。
客户端
- --host,RPC服务端IP,默认值127.0.0.1;
- --port,RPC服务端端口,默认值50000;
- --mode,推理模式,默认值sft,支持sft、zero_shot、cross_lingual、instruct;
- --tts_text,输入合成文本,默认值“好,我是通义千问语音合成大模型,请问有什么可以帮您的吗?”;
- --spk_id,音色,默认值中文女;
- --prompt_text,prompt文本,默认值“希望你以后能够做的比我还好呦。”;
- --prompt_wav,prompt音频文件,默认值../../../zero_shot_prompt.wav;
- --instruct_text,instruct文本,默认值“Theo 'Crimson', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.”;
- --tts_wav,tts任务存储文件路径,默认值demo.wav。
评价此篇文章