
自适应并行策略搜索工具
产品介绍
自适应并行工具能够为大模型训练提供的根据环境配置,自动匹配适合的并行策略,从而充分利用计算资源,显著提高训练效率。本篇文档介绍自适应并行策略搜索工具的使用方式。
支持模型
| 模型系列 | 模型名称 |
|---|---|
| llama | 7B、65B、175B、540B、1800B |
| llama2 | 7B、13B、35B、70B |
| glm | 67B、130B |
| galactica | 6.7B、30B、120B |
如果您对于其他暂未支持的模型有训练需求,请提交工单或者联系您的客户经理。
使用限制
- GPU型号支持:A800、H800、昇腾910B
- 单个机器GPU数:当前限制为8
如何使用
下面基于Llama2-70B模型,GPU卡选择A800,在32机共256卡规模下,globalbatchsize为512,最大sequencelength为4096,搜索前3条最佳性能的并行策略参数为例。
- 进入控制台,点击左侧【AI加速套件】找到工具包,点击【获取地址】可以得到工具包的下载地址,在容器镜像中先使用wget下载。
注意:以下示例中的地址需替换为从控制台获取的地址
1# 下载工具
2wget https://doc.bce.baidu.com/bce-documentation/BOS/aiak-tool-apss.zip- 解压工具包
1# 解压缩工具,注意查看.zip的文件名可能与示例中不一致
2unzip aiak-tool-apss.zip
3cd aiak-tool-apss- 进入autoparallel目录,搜索最佳性能的并行策略参数,执行命令如下:
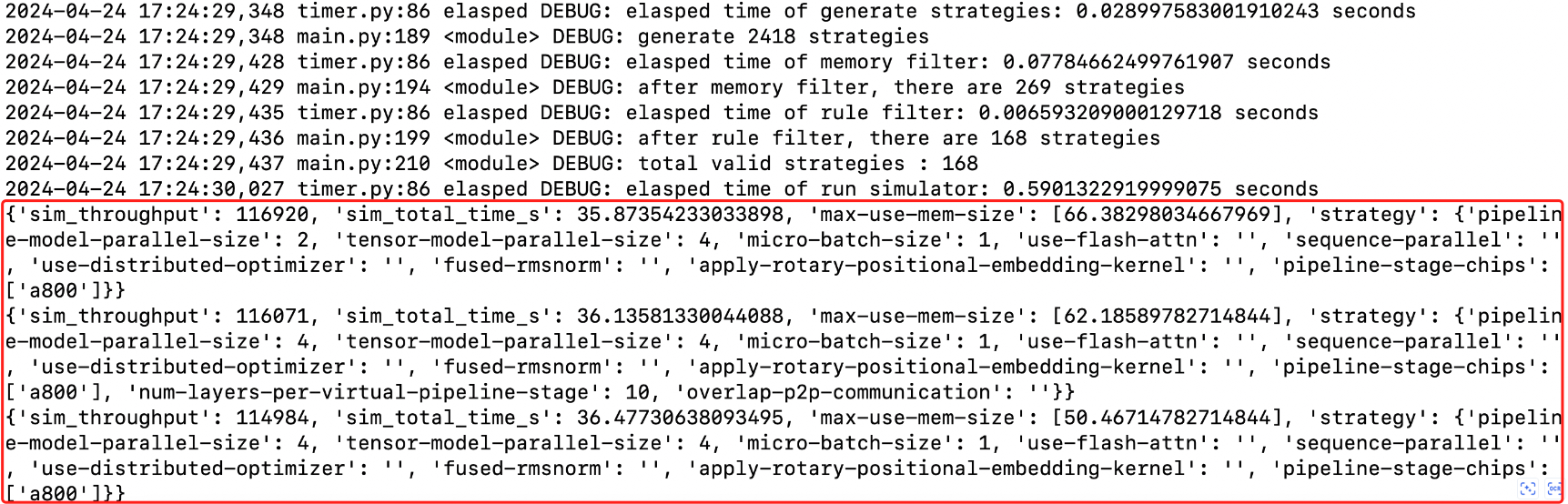
1python3 main.py --model-name llama2-70b --num-gpus 256 --nproc-per-node 8 --gpu-infos a800 --global-batch-size 512 --sequence-length 4096 --top 3- 等待搜索结果,复制返回的最优并行策略参数,更新任务配置文件后执行训练任务。
参数说明
输入参数
| 参数名称 | 取值类型 | 默认值 | 可选枚举值 | 描述 |
|---|---|---|---|---|
| --model-name | str | llama2-70b | llama-7b、llama-65b、llama-175b、llama-540b、llama-1800b、llama2-7b、llama2-13b、llama2-70b、llama2-35b、glm-130b、glm-67b、galactica-6.7b、galactica-30b、galactica-120b | 模型名称,模型系列+参数,详细见模型支持列表 |
| --num-gpus | int | 256 | 集群gpu数量,最大值为1048576 | |
| --gpu-infos | str | a800 | a800、h800、h100、kunlun3、ascend_910b | 集群使用的芯片名称以及数量限制,格式为:[gpu_type:max_num[,gpu_type:max_num...];如果不指定max_num或者max_num为-1,则对应芯片类型的数量没有限制;例如:a800:120,h800:256 表示集群使用两种芯片,a800, h800;其中a800的数量最多为120个,h800的数量最多为256个 |
| --nproc-per-node | int | 8 | 8 | 单台服务器包含的gpu卡数目,目前限定为8 |
| --global-batch-size | int | 1024 | 必须是512的整数倍,最大值为1048576 | |
| --sequence-length | int | 4096 | 必须是512的整数倍,最大值为1048576 | |
| --top | int | 5 | 输出吞吐最优的N条并行策略 | |
| --mode | str | fast | fast、analytic | 仅做内部trace使用,模式为fast时,不打印trace file;模式为analytic时,会在当前目录下建./cache目录,./cache目录下存放并行策略的trace file |
输出策略参数
| 参数名 | 描述 |
|---|---|
| pipeline-model-parallel-size | 流水线并行度 |
| tensor-model-parallel-size | 模型并行度 |
| micro-batch-size | |
| use-flash-attn | |
| sequence-parallel | |
| use-distributed-optimizer | |
| fused-rmsnorm | |
| apply-rotary-positional-embedding-kernel | |
| pipeline-stage-chips | 值为一个列表;多芯场景下,列表的元素个数等于策略的流水线并行度,每个元素表示对应的pipeline rank的gpu所属的芯片类型;单芯场景下,由于所有的gpu都是同一类型,列表只有一个元素(即gpu所属的芯片类型); |
| pipeline-stage-layers | 值为一个列表,每个pipeline rank所包含的模型layer的层数,只在多芯场景下有效;单芯场景下策略无此参数 |
| recompute-granularity | 值为一个列表,列表的元素个数等于芯片种类个数,每个元素代表每类芯片类型的重计算粒度 |
| recompute-method | 值为一个列表,列表的元素个数等于芯片种类个数,每个元素代表每类芯片类型的重计算方法 |
| recompute-num-layers | 值为一个列表,列表的元素个数等于芯片种类个数,每个元素代表每类芯片类型的重计算层数 |
以如下一条输出策略为例子: {'sim_throughput': 238013, 'sim_total_time_s': 17.62220148337528, 'max-use-mem-size': [25.00778579711914, 72.89899063110352], 'strategy': {'pipeline-model-parallel-size': 8, 'tensor-model-parallel-size': 2, 'micro-batch-size': 1, 'use-flash-attn': '', 'sequence-parallel': '', 'use-distributed-optimizer': '', 'fused-rmsnorm': '', 'apply-rotary-positional-embedding-kernel': '', 'pipeline-stage-chips': ['a800', 'h800', 'h800', 'h800', 'h800', 'h800', 'h800', 'h800'], 'pipeline-stage-layers': [3, 11, 11, 11, 11, 11, 11, 11], 'recompute-granularity': [None, 'full'], 'recompute-method': [None, 'block'], 'recompute-num-layers': [None, 3]}} 说明如下: 该输出策略的流水线并行度为8,共有两种芯片(a800与h800); pipeline-stage-chips的值列表共有8个元素,分别对应8个pipeline rank,其中第一个pipeline rank的gpu类型是a800,其余7个pipeline rank的gpu类型是h800; pipeline-stage-layers的值列表也有8个元素,分别对应8个pipeline rank,其中第一个pipeline rank包含的模型层数是3层,其余pipeline rank包含的模型层数都是11层; recompute-granularity的值列表有2个元素,分别对应a800、h800的pipeline rank,其中a800上的pipeline rank不需要重计算,而h800上的pipeline rank的重计算粒度是full;recompute-method的值列表有2个元素,分别对应a800、h800的pipeline rank,其中h800上的pipeline rank的重计算方法是block;recompute-method的值列表有2个元素,分别对应a800、h800的pipeline rank,其中h800上的pipeline rank的重计算层数是3层;
使用示例
示例一:单芯片并行策略搜索
在目录autoparallel下,输入如下命令:
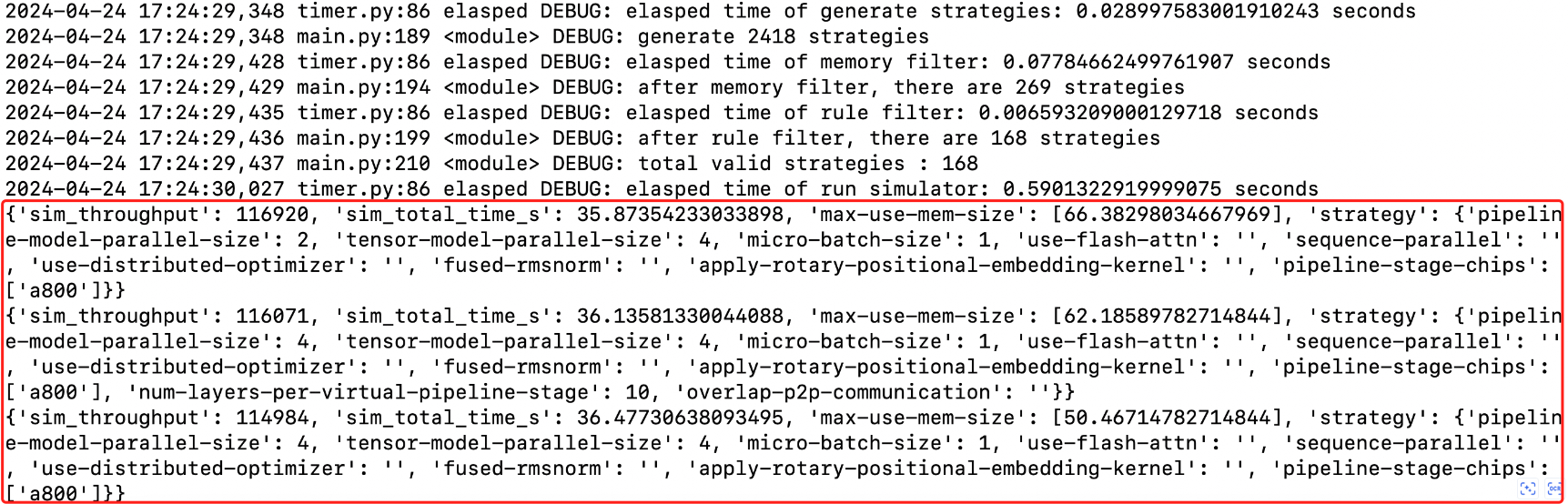
1python3 main.py --model-name llama2-70b --num-gpus 256 --nproc-per-node 8 --gpu-infos a800 --global-batch-size 512 --sequence-length 4096 --top 3输出如下:
示例二:多芯片并行策略搜索
在目录autoparallel下,输入如下命令:
1python3 main.py --model-name llama2-70b --num-gpus 256 --nproc-per-node 8 --gpu-infos a800:128,h800:160 --global-batch-size 512 --sequence-length 4096 --top 3输出如下:

评价此篇文章