
快速部署opencompass评测大语言模型
准备资源
可根据资源规模、稳定性、灵活性等要求,在AI计算资源中按需准备轻量计算实例或自运维资源池,用于快速部署opencompass。AI计算资源
部署opencompass
- 在 工具市场>工具模版 中选择opencompass模版,点击 部署工具 按钮,完成快速部署。
- 根据模型开发调试需求,选择实例类型和加速芯片设置。点击 确定 启动工具。
通过浏览器访问opencompass
在 我的工具 中找到创建的工具,进入详情页。
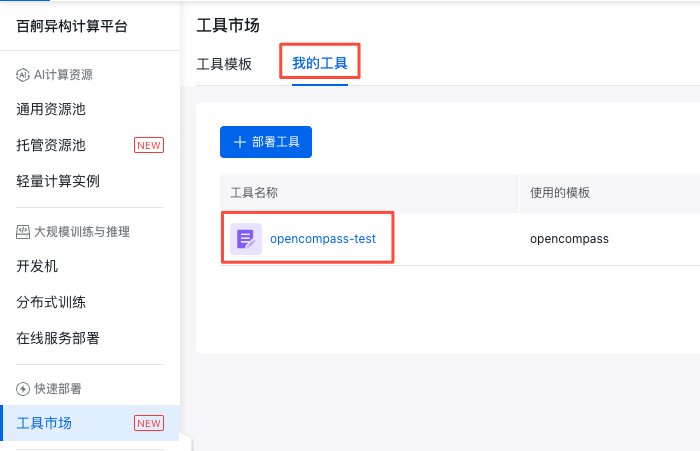
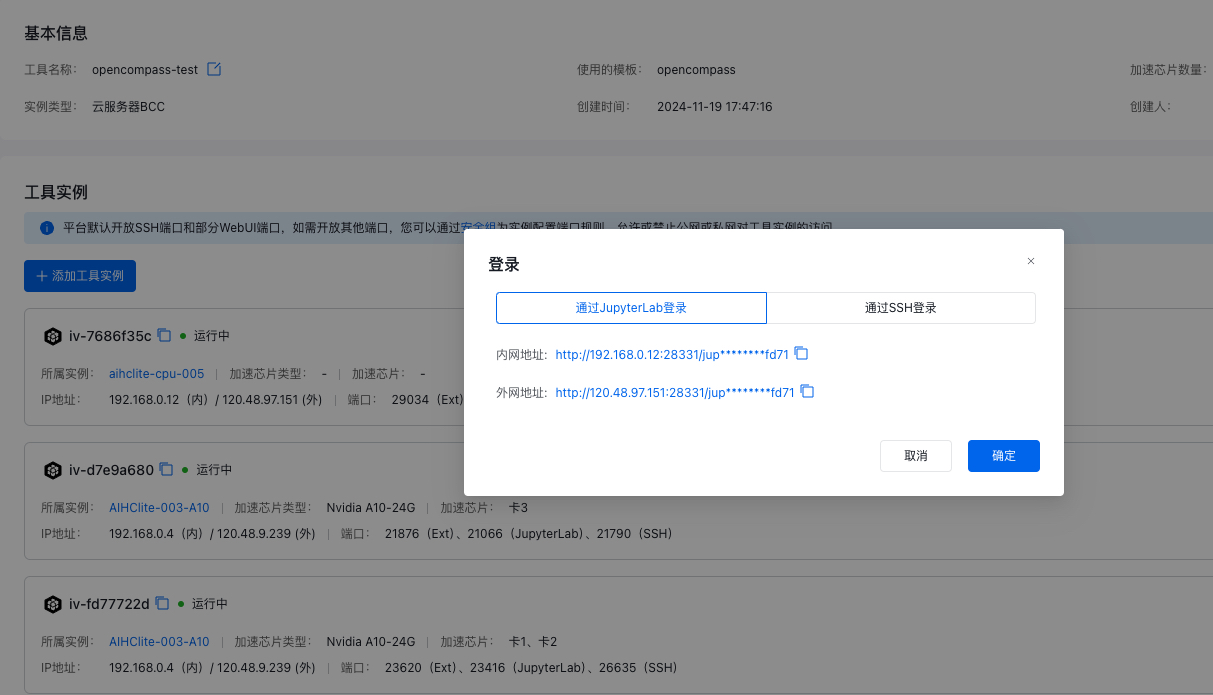
在详情页点击资源实例下的 登录 ,选择 JupyterLab 访问地址即可访问
前置准备
模型和数据集准备
示例将以命令行的形式,给出对话模型Qwen2-1.5B-Instruct在C-EVAL下的评估。C-Eval是一个全面的中国基础模型评估套件。它由13948道多项选择题组成,涵盖52个不同学科和4个难度级别。
- 模型准备:Qwen2.5-1.5B-Instruct需从modelscope或huggingface等自行下载,并导入容器实例的/root/opencompass/Qwen下;
- 数据集准备:opencompass会自动下载评估过程中的部分预置数据集,详见https://github.com/open-compass/opencompass/blob/main/README.md。
环境准备
1cd /root/opencompass
2conda activate opencompass
3# 数据集下载源
4export DATASET_SOURCE=ModelScope使用示例
模型和数据集配置查看
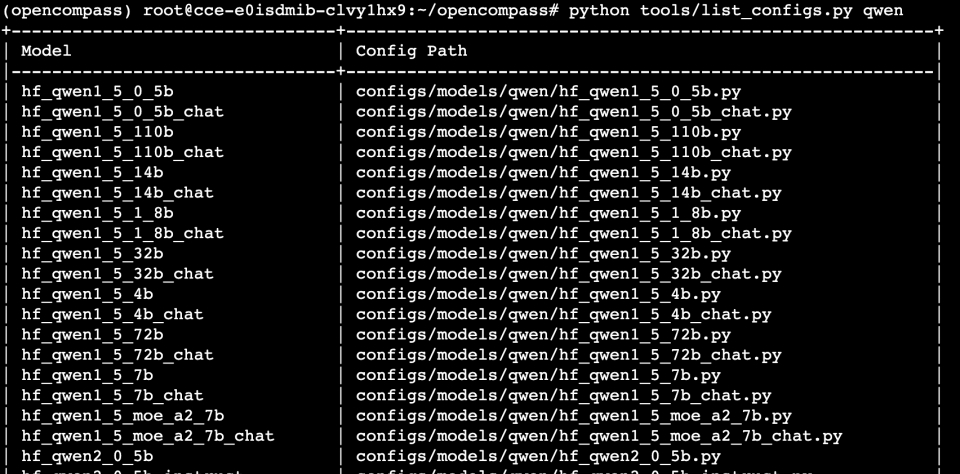
openCompass预置的模型和数据集可分别在configs/models和configs/datasets下找到。想查看某模型/数据集的配置文件时,以qwen系列为例,使用如下命令:
1python tools/list_configs.py qwen结果输出如下:
以configs/models/qwen/vllm_qwen2_1_5b_instruct.py为例,预置了模型路径、最大输出长度、batch大小等配置,如下所示:
1models = [
2 dict(
3 type=VLLMwithChatTemplate,
4 abbr='qwen2-1.5b-instruct-vllm',
5 path='Qwen/Qwen2-1.5B-Instruct',
6 model_kwargs=dict(tensor_parallel_size=1),
7 max_out_len=1024,
8 batch_size=16,
9 generation_kwargs=dict(temperature=0),
10 run_cfg=dict(num_gpus=1),
11 )
12]模型本地评测
执行如下命令:
1python run.py --models hf_qwen2_1_5b_instruct --datasets ceval_gen --debug在debug模式下,任务将按顺序执行,并实时打印输出,非必需。正常模式下,评估任务将在后台并行执行,其输出将被重定向到输出目录output/default/{TIMESTAMP},任何后端任务失败都只会在终端触发警告消息。
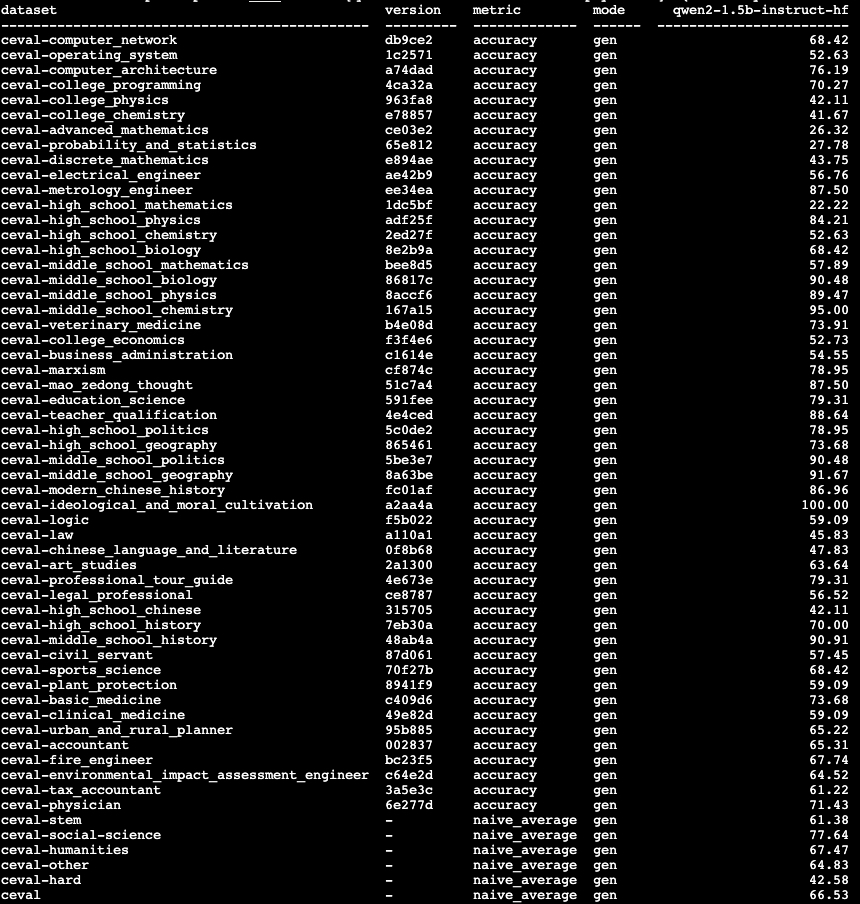
评测完成后,opencompass会给出评测结果,详细的评测记录保存在目录outputs/default/{TIMESTAMP}下,如下所示:

部署后评测
仍然以Qwen2-1.5B-Instruct为例,
推理服务实例A
使用如下命令部署vllm推理引擎:
1export VLLM_USE_MODELSCOPE=True
2# 用于控制内存分配的参数,可以帮助减少内存碎片化问题
3export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
4# 降低gpu_memory_utilization参数,可以限制 CUDA 图对显存的预分配,从而减少显存压力
5export GPU_MEMORY_UTILIZATION=0.5
6
7vllm serve Qwen/Qwen2-1.5B-Instruct --dtype auto --host 0.0.0.0 --port 3456 --served-model-name myQwen部署成功后,终端可看到相关信息:

推理请求实例B
推理请求实例可部署在无可用cuda的环境下。
复制推理请求配置代码到configs/models/qwen/qwen_remote_test.py:
1from opencompass.models import OpenAISDK
2
3api_meta_template = dict(
4 round=[
5 dict(role='HUMAN', api_role='HUMAN'),
6 dict(role='BOT', api_role='BOT', generate=True),
7 ],
8 reserved_roles=[dict(role='SYSTEM', api_role='SYSTEM')],
9)
10
11models = [
12 dict(
13 abbr='Qwen2-1.5B-Instruct',
14 type=OpenAISDK,
15 key='EMPTY', # API key
16 openai_api_base='http://192.168.0.4:3456/v1', # 服务内网IP
17 path='myQwen', # 请求服务时的 model name
18 tokenizer_path='Qwen/Qwen2-1.5B-Instruct', # 请求服务时的 tokenizer name 或 path, 为None时使用默认tokenizer gpt-4
19 rpm_verbose=True, # 是否打印请求速率
20 meta_template=api_meta_template, # 服务请求模板
21 query_per_second=10, # 服务请求速率
22 max_out_len=1024, # 最大输出长度
23 max_seq_len=4096, # 最大输入长度
24 temperature=0.01, # 生成温度
25 batch_size=8, # 批处理大小
26 retry=3, # 重试次数
27 )
28]执行python tools/list_configs.py qwen验证是否已在配置文件中,

然后,执行如下命令启动评测:
1python run.py --models qwen_remote_test --datasets ceval_gen --debug出现类似如下输出表明推理请求执行成功:

评测完成后,详细的记录会保存在目录outputs/default/{TIMESTAMP}下。
数据并行推理加速评测
使用如下命令实现数据并行推理,以加速推理过程。实际的运行任务数受到可用GPU资源和max_num_workers的限制。
1CUDA_VISIBLE_DEVICES=0,1 python run.py --models hf_qwen2_1_5b_instruct --datasets ceval_gen --max-num-workers 2评测完成后,opencompass会给出评测结果,详细的评测记录保存在目录outputs/default/{TIMESTAMP}下。
vllm推理引擎加速评测
使用如下命令利用推理引擎vllm,以加速推理过程。
1export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
2export GPU_MEMORY_UTILIZATION=0.5
3
4python run.py --models hf_qwen2_1_5b_instruct --datasets ceval_gen --debug -a vllm评测完成后,opencompass会给出评测结果,详细的评测记录保存在目录outputs/default/{TIMESTAMP}下。
评价此篇文章