
使用vLLM加速大模型推理
vLLM(Vectorized Large Language Model)是一个高性能的大型语言模型推理库,支持多种模型格式和后端加速,适用于大规模语言模型的推理服务部署
准备环境和资源
可根据资源规模、稳定性、灵活性等要求按需准备轻量计算实例或通用计算资源池,用于快速部署vLLM。
安装vLLM
- 在百舸平台工具市场>模版市场 中选择 vLLM 模版,点击 部署工具 按钮;
- 根据需要部署的模型参数量,选择使用卡数量,至少需要选择1张卡,点击 确定 启动服工具。
准备模型数据
模型默认从huggingface下载,如果您在 Hugging Face 模型和数据集的下载中遇到了问题,可以设置环境变量VLLM_USE_MODELSCOPE=True,使模型默认从modelScope下载
1export VLLM_USE_MODELSCOPE=True通过更换镜像源下载
1pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
2用法:
3import os
4from modelscope import snapshot_download
5# cache_dir 指定你的保存模型的路径
6model_dir = snapshot_download('shakechen/Llama-2-7b-hf',cache_dir="/home/rd/fanjikang/model")通过git下载
1安装并初始化 git-lfs
2apt install git-lfs -y
3git lfs install
4用法:
5git lfs clone https://www.modelscope.cn/qwen/Qwen1.5-1.8B-Chat.git部署推理服务
离线推理服务
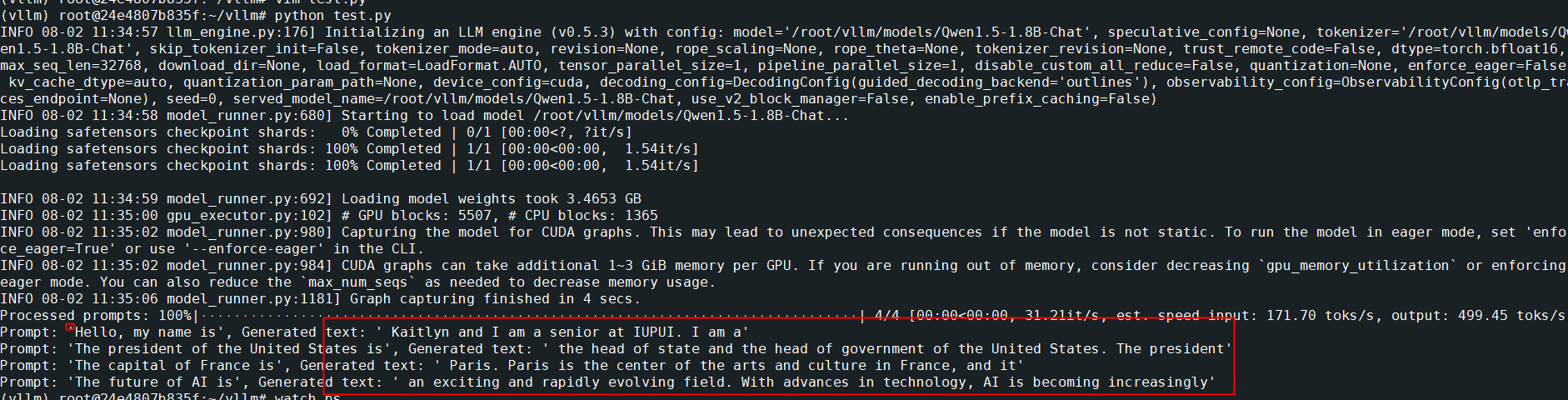
我们首先展示了一个使用vLLM对数据集进行离线批处理推理的示例。我们使用vLLM为输入提示列表生成文本,从vLLM导入LLM和采样参数。LLM类是使用vLLM引擎运行离线推理的主要类,SamplingParams类指定采样过程的参数。
1from vllm import LLM, SamplingParams定义输入提示列表和用于生成的采样参数。采样温度设置为0.8,核采样概率设置为0.95。有关采样参数的更多信息,请参阅类定义。
1# 载入 LLM 和 SamplingParams
2from vllm import LLM, SamplingParams
3# 推理数据以List[str]格式组织
4prompts = ["Hello, my name is","The president of the United States is","The capital of France is","The future of AI is",]
5# 设置采样参数
6sampling_params = SamplingParams(temperature=0.8,top_p=0.95)
7# 加载模型
8llm = LLM(model="/root/vllm/models/Qwen1.5-1.8B-Chat")
9# 执行推理
10outputs=llm.generate(prompts,sampling_params)
11# 输出推理结果
12for output in outputs:
13 prompt=output.prompt
14 generated_text=output.outputs[0].text
15 print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")成功返回结果如下:
在线推理服务
在线推理有两种接口,OpenAI兼容接口和vLLM接口,官方推荐使用OpenAI兼容接口作为生产力接口。
OpenAI Completions API
启动server
启动单卡server: 其他可配置参数参考附件,命令中传入LLM类的参数用于设置模型载入方式
1python -m vllm.entrypoints.openai.api_server \
2--model /root/vllm/models/Qwen1.5-1.8B-Chat \
3--served-model-name qwen \
4--host 0.0.0.0 \
5--port 8000启动多卡server:(启动容器时要挂在多卡,例如两卡)
1python -m vllm.entrypoints.openai.api_server \
2--model /root/vllm/models/Qwen1.5-1.8B-Chat \
3--served-model-name qwen \
4--host 0.0.0.0 \
5--port 8000 \
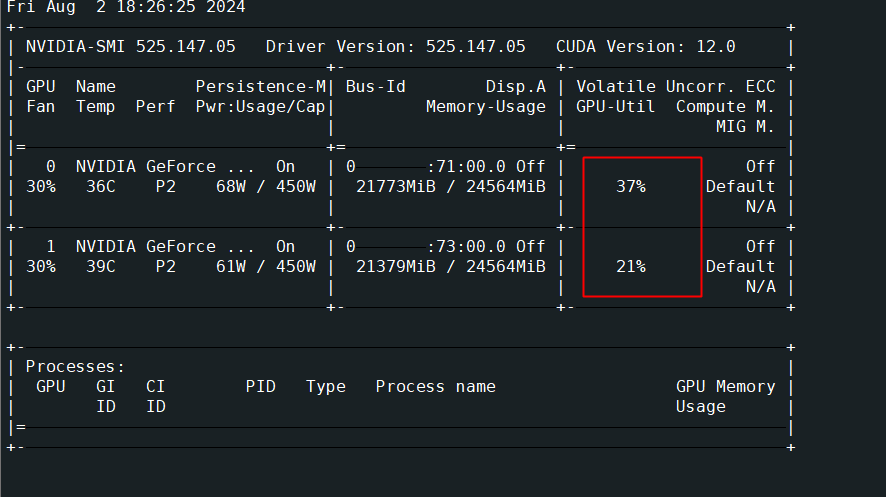
6--tensor-parallel-size 2多卡服务运行时,发送下面的http请求,通过watch nvidia-smi命令监控gpu,可以看到多张卡都被使用了。
发送请求
当前示例容器内端口8000已经在容器启动时映射到了宿主机的8028,所以外部通过使用宿主机绑定公网ip的8028端口进行访问。 API中可以传入SamplingParam的参数设置采样方式。
1curl http://120.48.131.39:8028/v1/chat/completions \
2-H "Content-Type: application/json" \
3-d '{
4"model": "qwen",
5"messages": [
6 {"role": "system", "content": "You are a helpful assistant."},
7 {"role": "user", "content": "Who won the world series in 2020?"}
8]
9}'成功返回结果如下:

OpenAI Chat API
启动server
启动单卡server: 其他可配置参数参考附件,命令中传入LLM类的参数用于设置模型载入方式
1python -m vllm.entrypoints.openai.api_server \
2--model/root/vllm/models/Qwen1/5-1/8b-Chat \
3--served-model-name qwen \
4--host 0.0.0.0 \
5--port 8000
6 #--chat-template ./examples/template_chatml.jinja 目前并没有内置聊天模板文件,可自行到官网下载使用:https://github.com/vllm-project/vllm/tree/main/examples发送请求
当前示例容器内端口8000已经在容器启动时映射到了宿主机的8028,所以外部通过使用宿主机绑定公网ip的8028端口进行访问。 API中可以传入SamplingParam的参数设置采样方式。
1curl http://120.48.131.39:8028/v1/completions \
2-H "Content-Type: application/json" \
3-d '{
4"model": "qwen",
5"prompt": "San Francisco is a",
6"max_tokens": 7,
7"temperature": 0
8}'成功返回结果如下:

其他发送请求方式
使用python发送请求
1from openai import OpenAI
2
3# Modify OpenAI's API key and API base to use vLLM's API server.
4openai_api_key = "EMPTY"
5openai_api_base = "http://120.48.131.39:8028/v1"
6client = OpenAI(
7 api_key=openai_api_key,
8 base_url=openai_api_base,
9)
10chat_response = client.chat.completions.create(
11 model="qwen",
12 messages=[
13 {"role": "system", "content": "You are a helpful assistant."},
14 {"role": "user", "content": "Tell me a joke."},
15 ]
16)
17print(chat_response)成功返回结果如下:

附录参数列表
server参数:
| 参数名 | 含义 | 备注 |
|---|---|---|
| –model <model_name_or_path> | 要使用的huggingface模型的名称或路径。 | |
| –tokenizer <tokenizer_name_or_path> | 要使用的huggingface tokenizer的名称或路径 | |
| –revision |
要使用的特定模型版本。它可以是一个分支名,一个标签名,或者一个提交id。如果未指定,将使用默认版本 | |
| –tokenizer-revision |
要使用的特定tokenizer版本。它可以是一个分支名,一个标签名,或者一个提交id。如果未指定,将使用默认版本。 | |
| –tokenizer-mode {auto,slow} | tokenizer模式。 | “auto”将在可用的情况下使用快速tokenizer。 “slow”将始终使用慢速tokenizer。 |
| –trust-remote-code | 信任来自huggingface的远程代码。 | |
| –download-dir |
下载和加载权重的目录,默认为huggingface的默认缓存目录。 | |
| –load-format {auto,pt,safetensors,npcache,dummy} | 要加载的模型权重的格式。 | “auto”将尝试以safetensors格式加载权重,如果safetensors格式不可用,则回退到pytorch bin格式。 “pt”将以pytorch bin格式加载权重。 “safetensors”将以safetensors格式加载权重。 “npcache”将以pytorch格式加载权重并存储一个numpy缓存以加速加载。 “dummy”将用随机值初始化权重,主要用于性能分析。 |
| –dtype {auto,half,float16,bfloat16,float,float32} | 模型权重和激活的数据类型 | “auto”将为FP32和FP16模型使用FP16精度,为BF16模型使用BF16精度。 “half”用于FP16。推荐用于AWQ量化。 “float16”与“half”相同。 “bfloat16”在精度和范围之间取得平衡。 “float”是FP32精度的简写。 “float32”用于FP32精度。 |
| –max-model-len |
模型上下文长度。如果未指定,将自动从模型配置中推导。 | |
| –worker-use-ray | 使用Ray进行分布式服务,当使用超过1个GPU时将自动设置。 | |
| –pipeline-parallel-size (-pp) |
管道阶段的数量。 | |
| –tensor-parallel-size (-tp) |
张量并行副本的数量。 | |
| –max-parallel-loading-workers |
以多个批次顺序加载模型,以避免在使用张量并行和大型模型时出现RAM OOM。 | |
| –block-size {8,16,32} | 连续token块的token块大小。 | |
| –enable-prefix-caching | 启用自动前缀缓存 | |
| –seed |
操作的随机种子。 | |
| –swap-space |
每个GPU的CPU交换空间大小(GiB) | |
| –gpu-memory-utilization |
用于模型执行器的GPU内存的分数,范围可以从0到1。例如,0.5的值意味着50%的GPU内存利用率。如果未指定,将使用默认值0.9。 | |
| –max-num-batched-tokens |
每次迭代的批处理token的最大数量 | |
| –max-num-seqs |
每次迭代的序列的最大数量。 | |
| –max-paddings |
一批中的最大填充数量。 | |
| –disable-log-stats | 禁用日志统计。 | |
| –quantization (-q) {awq,squeezellm,None} | 用于量化权重的方法。 |
评价此篇文章