
推理说明
更新时间:2025-11-24
使用说明
准备工作
为了帮助客户快速POC,AIAK提前缓存了模型权重、测试数据集,用户可以直接使用快速验证。
前置检查:使用命令查看CPU模式cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor,确保Mode策略使用performance进行测试,否则会影响性能!如果策略为其他类型,使用如下命令进行修改:
Bash
1cpupower idle-set -d 2 > /dev/null
2cpupower idle-set -d 3 > /dev/null
3cpupower frequency-set -g performance > /dev/null目前模型权重文件以及测试数据集缓存在对象存储BOS上,请选择百度云任一机器,执行以下命令安装BOS命令行工具:
Bash
1# 下载bcecmd程序
2wget https://doc.bce.baidu.com/bce-documentation/BOS/linux-bcecmd-0.4.5.zip
3# 解压
4unzip linux-bcecmd-0.4.5.zip
5cd linux-bcecmd-0.4.5镜像&权重&数据准备
- 拉取镜像
Bash
1docker pull registry.baidubce.com/aihc-aiak/aiak-inference-llm:ubuntu22.04-cu12.3-torch2.4.0-py310_2.0.2.2- 下载模型权重(非量化&量化)
Bash
1./linux-bcecmd-0.4.5/bcecmd bos【模型链接】【本地路径】
2# 例如下载30B模型
3./linux-bcecmd-0.4.5/bcecmd bos sync bos://cce-ai-datasets/huggyllama/llama-30b /mnt/pfs/meta-llama/llama-30b/| 模型 | 地址 |
|---|---|
| llama2-7b-hf | bos://cce-ai-datasets/huggingface.co/meta-llama/Llama-2-7b-hf |
| llama2-7b-sq | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/llama2-7b/1-gpu/ |
| llama-30b-hf | bos://cce-ai-datasets/huggyllama/llama-30b |
| llama-30b-sq(1-gpu) | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/llama-30b/1-gpu/ |
| llama-30b-sq(4-gpu) | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/llama-30b/4-gpu/ |
| llama-2-13b-hf | bos://cce-ai-datasets/huggingface.co/meta-llama/Llama-2-13b-hf |
| llama-2-13b-sq | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/llama2-13b/1-gpu/ |
| llama-2-70b-hf | bos://cce-ai-datasets/huggingface.co/meta-llama/Llama-2-70b-hf |
| llama-2-70b-sq | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/llama2-70b/8-gpu/ |
| llama-3-8b-hf | bos://cce-ai-datasets/huggingface.co/meta-llama/Meta-Llama-3-8B/ |
| llama3-8b-sq | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/Meta-Llama-3-8B/1-gpu/ |
| llama-3-70b-hf | bos://cce-ai-datasets/huggingface.co/meta-llama/Meta-Llama-3-70B/ |
| llama3-70b-sq | bos://cce-ai-datasets/aiak_quanted_models/smooth_quant/Meta-Llama-3-70B |
| qwen2-72b-Instruct | bos:/cce-ai-models/huggingface.co/Qwen/Qwen2-72B-Instruct |
| qwen2-72b-sq | bos:/cce-ai-datasets/hac-aiacc/aiak_quanted_models/qwen2-72b-instruct/smooth_quant/8-gpu |
- 下载测试数据集
Bash
1./linux-bcecmd-0.4.5/bcecmd bos cp bos://cce-ai-datasets/ShareGPT_V3_unfiltered_cleaned_split.json /mnt/pfs/data/ShareGPT_V3_unfiltered_cleaned_split.json部署推理实例的服务端
需要规模使用时,请使用标准K8S模式发起部署
Bash
1#启动docker
2docker run --gpus all -itd --name aiak2.0.1_test --shm-size=32768m --privileged --user=root --network host -v /PATH/TO/MODEL:/mnt/model registry.baidubce.com/aihc-aiak/aiak-inference-llm:ubuntu22.04-cu12.3-torch2.4.0-py310_2.0.2.2 /bin/bash
3#进入docker
4docker exec -it infer_test bash
Bash
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: aiak-inference-test
5 namespace: default
6spec:
7 progressDeadlineSeconds: 600
8 replicas: 1
9 revisionHistoryLimit: 10
10 selector:
11 matchLabels:
12 app: aiak-inference-test
13 strategy:
14 rollingUpdate:
15 maxSurge: 25%
16 maxUnavailable: 25%
17 type: RollingUpdate
18 template:
19 metadata:
20 labels:
21 app: aiak-inference-test
22 spec:
23 containers:
24 - command:
25 - /bin/bash
26 - '-c'
27 - "trap 'kill $(jobs -p)' EXIT; sleep 3d"
28 image: 'registry.baidubce.com/aihc-aiak/aiak-inference-llm:ubuntu22.04-cu12.3-torch2.4.0-py310_2.0.2.2'
29 imagePullPolicy: Always
30 name: vllm
31 resources:
32 limits:
33 baidu.com/a800_80g_cgpu: "8"
34 terminationMessagePath: /dev/termination-log
35 terminationMessagePolicy: File
36 volumeMounts:
37 - mountPath: /usr/bin/docker
38 name: docker
39 - mountPath: /var/run/docker.sock
40 name: docker-sock
41 - mountPath: /mnt/pfs
42 name: pfs
43 - mountPath: /dev/shm
44 name: cache-volume
45 dnsPolicy: ClusterFirst
46 restartPolicy: Always
47 schedulerName: volcano
48 securityContext: {}
49 terminationGracePeriodSeconds: 60
50 volumes:
51 - hostPath:
52 path: /usr/bin/docker
53 type: ''
54 name: docker详细参数查阅《参数说明-服务端主要参数》章节
使用内置量化工具(可选)
进入docker服务的命令行进行操作,量化时间与模型大小和卡数有关,需要十几分钟到1小时左右
Bash
1# 进入量化工具所在目录
2cd /workspace/aiak-model-quant-tool/
3# 示例
4weight_only_int8量化
5python3 model_quantization.py -i /input_path/ -o ./output_path/ -tp 1 -quant_type weight_only_int8 -t fp16
6smooth-quant量化默认校准数据集
7python3 model_quantization.py -i /input_path/ -o ./output_path/ -tp 1 -quant_type smooth_quant -t fp16 -sq 0.75
8smooth-quant量化自定义校准数据集
9python3 model_quantization.py -i /input_path/ -o ./output_path/ -tp 1 -quant_type smooth_quant -t fp16 -sq 0.75 --tokenids_path /XX/path_to/smooth_tokenids.txt详细参数查阅《参数说明-内置量化工具参数》章节
- 量化输出示例
Bash
1root@A800:/workspace/aiak-model-quant-tool# python3 model_quantization.py -i /input_path/ -o /output_path/ -quant_type weight_only_int8 -tp 2
2=============== Argument ===============
3out_dir: /Qwen-14B/
4in_file: /Qwen-14B/
5tensor_parallelism: 2
6model_quantization_type: weight_only_int8
7multi_query_mode: False
8========================================
9INFO 12-01 08:30:18 model_quantization.py:35] quantization an LLM engine model_config:QWenConfig {
10INFO 12-01 08:30:18 model_quantization.py:35] "architectures": [
11INFO 12-01 08:30:18 model_quantization.py:35] "QWenLMHeadModel"
12INFO 12-01 08:30:18 model_quantization.py:35] ],
13INFO 12-01 08:30:18 model_quantization.py:35] "attn_dropout_prob": 0.0,
14INFO 12-01 08:30:18 model_quantization.py:35] "auto_map": {
15INFO 12-01 08:30:18 model_quantization.py:35] "AutoConfig": "configuration_qwen.QWenConfig",
16INFO 12-01 08:30:18 model_quantization.py:35] "AutoModelForCausalLM": "modeling_qwen.QWenLMHeadModel"
17INFO 12-01 08:30:18 model_quantization.py:35] },
18INFO 12-01 08:30:18 model_quantization.py:35] "bf16": false,
19INFO 12-01 08:30:18 model_quantization.py:35] "emb_dropout_prob": 0.0,
20INFO 12-01 08:30:18 model_quantization.py:35] "fp16": false,
21INFO 12-01 08:30:18 model_quantization.py:35] "fp32": false,
22INFO 12-01 08:30:18 model_quantization.py:35] "hidden_size": 5120,
23INFO 12-01 08:30:18 model_quantization.py:35] "initializer_range": 0.02,
24INFO 12-01 08:30:18 model_quantization.py:35] "intermediate_size": 27392,
25INFO 12-01 08:30:18 model_quantization.py:35] "kv_channels": 128,
26INFO 12-01 08:30:18 model_quantization.py:35] "layer_norm_epsilon": 1e-06,
27INFO 12-01 08:30:18 model_quantization.py:35] "max_position_embeddings": 8192,
28INFO 12-01 08:30:18 model_quantization.py:35] "model_type": "qwen",
29INFO 12-01 08:30:18 model_quantization.py:35] "no_bias": true,
30INFO 12-01 08:30:18 model_quantization.py:35] "num_attention_heads": 40,
31INFO 12-01 08:30:18 model_quantization.py:35] "num_hidden_layers": 40,
32INFO 12-01 08:30:18 model_quantization.py:35] "onnx_safe": null,
33INFO 12-01 08:30:18 model_quantization.py:35] "rotary_emb_base": 10000,
34INFO 12-01 08:30:18 model_quantization.py:35] "rotary_pct": 1.0,
35INFO 12-01 08:30:18 model_quantization.py:35] "scale_attn_weights": true,
36INFO 12-01 08:30:18 model_quantization.py:35] "seq_length": 2048,
37INFO 12-01 08:30:18 model_quantization.py:35] "tie_word_embeddings": false,
38INFO 12-01 08:30:18 model_quantization.py:35] "tokenizer_class": "QWenTokenizer",
39INFO 12-01 08:30:18 model_quantization.py:35] "transformers_version": "4.34.0",
40INFO 12-01 08:30:18 model_quantization.py:35] "use_cache": true,
41INFO 12-01 08:30:18 model_quantization.py:35] "use_dynamic_ntk": true,
42INFO 12-01 08:30:18 model_quantization.py:35] "use_flash_attn": "auto",
43INFO 12-01 08:30:18 model_quantization.py:35] "use_logn_attn": true,
44INFO 12-01 08:30:18 model_quantization.py:35] "vocab_size": 152064
45INFO 12-01 08:30:18 model_quantization.py:35] }
46INFO 12-01 08:30:18 model_quantization.py:35] quantization tp_size is: 2,
47INFO 12-01 08:33:29 model_quantization.py:35] ==quantization= state_dict===key: transformer.h.0.attn.c_proj.qscale ==value.shape: torch.Size([2, 5120])
48INFO 12-01 08:33:29 model_quantization.py:35] ==quantization= state_dict===key: transformer.h.0.attn.c_proj.qweight ==value.shape: torch.Size([5120, 1280])
49INFO 12-01 08:33:29 model_quantization.py:35] ==quantization= state_dict===key: transformer.h.0.ln_1.weight ==value.shape: torch.Size([5120])
50INFO 12-01 08:33:29 model_quantization.py:35] ==quantization= state_dict===key: transformer.h.0.ln_2.weight ==value.shape: torch.Size([5120])
51INFO 12-01 08:33:29 model_quantization.py:35] ==quantization= state_dict===key: transformer.wte.weight ==value.shape: torch.Size([152064, 5120])
52('json_quant_config: ', {'w_bit': 8})
53……
54INFO 12-01 08:33:54 model_quantization.py:35] Quantization model save path: /output_path/2-gpu启动推理服务的服务端
支持直接以入参形式来部署容器运行:
Bash
1python3 -m vllm.entrypoints.openai.api_server --model=<MODEL_PATH> --tensor-parallel-size 1 --dtype=float16 --port 8888 --enable-prefix-caching详细参数查阅《参数说明-服务端主要参数》章节;
目前只支持huggingface的checkpoint类型,如果需要使用Megatron的checkpoint,需要先将其转换为HF格式。
测试推理服务的客户端
使用curl命令进行功能单测
流式请求
客户端发送请求时,stream设置为True。
- 确保启动服务端,如未启动服务端,可使用以下命令启动
Plain
1python3 -m vllm.entrypoints.openai.api_server --model=/path/to/your/model/ --tensor-parallel-size=1 --dtype=float16 --gpu_memory_utilization=0.8- 客户端请求示例
Plain
1curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
2 "model": "/path/to/your/model/",
3 "prompt": ["中国的首都是"],"stream":"True"
4}'注意: 详细参数查阅《参数说明-客户端输入参数》章节;
- 得到返回
非流式请求
客户端发送请求时,stream设置为False,或者不设置(默认值为False)
- 确保启动服务端,如未启动服务端,可使用以下命令启动
Bash
1python3 -m vllm.entrypoints.openai.api_server --model=/path/to/your/model/ --tensor-parallel-size=1 --dtype=float16 --gpu_memory_utilization=0.8- 客户端请求示例
Bash
1curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
2 "model": "/path/to/your/model/",
3 "prompt": ["中国的首都是"],"stream":"False"
4}'注意: 详细参数查阅《参数说明-客户端输入参数》章节;
- 得到返回

使用内置数据集进行性能压测
进入容器使用以下方式可以查看推理服务性能
Bash
1# 使用docker或k8s进入容器的命令分别如下
2# docker进入容器
3docker exec -it <container_id_or_name> /bin/bash
4
5# kubectl进入容器
6kubectl exec -it <pod-name> -- /bin/bash
7
8# 性能测试客户端快速启动命令:
9cd /workspace/performance-tool/
10
11# 30b:
12# 以下命令,修改-c模型地址,与-d数据集地址即可
13nohup bash run.sh -c /mnt/pfs/meta-llama/llama-30b/ -m aiak_triton -d /mnt/pfs/data/ShareGPT_V3_unfiltered_cleaned_split.json -w 256 -n 10000 -g 8001 > client.log &
14
15# 如果需要测试定长的性能,增加如下参数:
16# -z 1000 -l 1000 -f true, -z是输入长度,-l是输出长度,-f是忽略休止符,注意目前支持的输入输出总长度不能超过32k
17
18# 参数说明:
19# 参数-n:【必选】客户端请求数(aiak_triton模式下需设置为batch size的整数倍)
20# 参数-p:【可选】是否开启泊松分布模拟排队等待时间,True表示开启,False表示关闭
21# 参数-w:【必选】客户端并发数,建议选取1*BS,2*BS等进行测试
22# 参数-c:【必选】模型的checkpoint路径
23# 参数-t:【可选】模型tokenizer路径,一般情况和checkpoint路径相同
24# 参数-s:【可选】dataset类型,默认数据集为sharegpt(json格式),可选 【booksum(csv格式),自定义input-instruction(json格式)】
25# 参数-d:【必选】dataset路径,默认数据集为ShareGPT_V3_unfiltered_cleaned_split.json,booksum数据集只需要指定到具体路径即可
26# 参数-u:【可选】是否加载本地cache加速测试数据预处理过程,默认false,true表示开启,模型首次测试,-u参数设置为false,后续测试可置为true进行加速,更换模型测试时,首次需要设置成false
27# 参数-q:【可选】是否执行量化模式,支持weight_only_int8, smooth_quant
28# 参数-g:【可选】grpc端口,默认8001
29# 参数-h:【可选】http端口,默认8002使用performance tool进行性能测试示例
- 确保启动服务端,如未启动服务端,可使用以下命令启动
Bash
1python3 -m vllm.entrypoints.openai.api_server \
2 --model=<path_to_your_model_directory> \
3 --tensor-parallel-size 1 \
4 --dtype=float16 \
5 --gpu_memory_utilization=0.8- 使用performance_tool进行测试
Bash
1bash run.sh \
2 -c <path_to_model_directory> \
3 -d /mnt/pfs/datasets/ShareGPT_V3_unfiltered_cleaned_split.json \
4 -m openai_api_server \
5 -n 10000 \
6 -w 256 \
7 -v true \
8 -h 8000- 获得测试结果
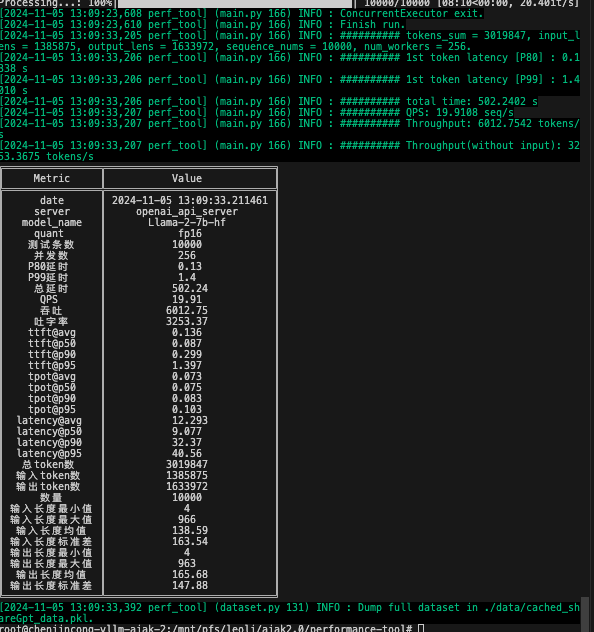
| 数据集特征 | 含义 | 计算方法 |
|---|---|---|
| 数量 | 数据集包含条数 | |
| 输入长度最小值 | 数据集中单条prompt长度最小值 | |
| 输入长度最大值 | 数据集中单条prompt长度最大值 | |
| 输入长度均值 | 数据集中所有prompt长度的平均数 | |
| 输入长度标准差 | 数据集中所有prompt的标准差分布 | |
| 输出长度最小值 | 数据集中单条prompt生成结果长度最小值 | |
| 输出长度最大值 | 数据集中单条prompt生成结果长度最大值 | |
| 输出长度均值 | 数据集中所有prompt生成结果长度的平均数 | |
| 输出长度标准差 | 数据集中所有prompt的生成结果标准差分布 | |
| 指标 | 含义 | 计算方法 |
|---|---|---|
| quant | 量化精度,具体为fp16或Smoothquant等 | |
| 测试条数 | 数据集包含条数 | |
| 并发数 | 同时响应的请求数量 | |
| P80延时 | 首token延时,80分位 | 从输入prompt的第一个token到生成第一个token,这段时间为首token延时,将所有句子的首token延时从小到大排序,第80%条为80分位值 |
| P99延时 | 首token延时,99分位 | 同上,99% |
| 总延时 | 所有任务处理完成总耗时 | |
| QPS | 端到端并发量(每秒处理完成几条) | QPS = sequence_nums / total time |
| 吞吐 | 每秒处理token数(包括输入) | Throughput = tokens_sum / total time |
| 吐字率 | 每秒处理token数(不包括输入) | Throughput = output_lens / total time |
评价此篇文章