
Qwen2-VL-72B-Instruct
更新时间:2026-04-08
模型介绍
Qwen2-VL-72B-Instruct 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen2-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen2-VL 系列模型的特点包括:
在视觉理解基准测试中取得了最先进的性能,包括 MathVista、DocVQA、RealWorldQA、MTVQA 等。
能够理解超过 20 分钟的视频,用于高质量的基于视频的问答、对话、内容创作等。
可以集成到手机、机器人等设备中,根据视觉环境和文本指令进行自动操作。
为了服务全球用户,除了英语和中文,现在还支持理解图像中不同语言的文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
多图片/视频支持
模型部署后支持的最大 Token 长度为 32768,最大支持 10图片+10视频推理。当使用多图片/视频进行推理时,由于图片、视频会被编码为 Token,对应的 Token 长度会受到模型最大支持 Token 长度(32768)的限制。
API调用
- 服务部署成功后,可在服务列表查看调用信息
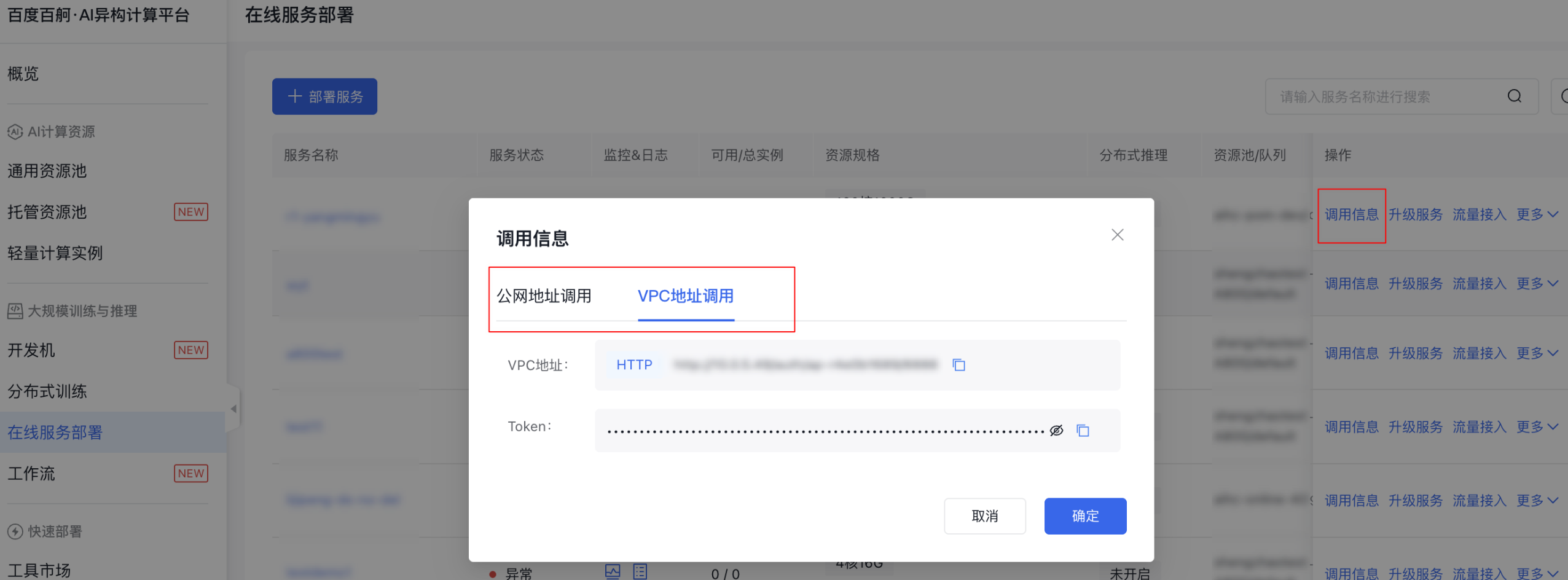
- 调用示例
Plain Text
1curl -X POST "<访问地址>/v1/chat/completions" \
2-H "Content-Type: application/json" \
3-H "Authorization: Bearer <TOKEN>" \
4-d '{
5 "model": "Qwen2-VL-72B-Instruct",
6 "messages": [{"role": "system", "content": "你是一名天文学家,请回答用户提出的问题。"}, {"role": "user", "content": "人类是否能登上火星?"}],
7 "max_tokens": 1024,
8 "temperature": 0.7
9}'评价此篇文章