
Qwen3-VL-8B-Instruct
更新时间:2025-11-12
Qwen3-VL 是阿里巴巴 Qwen 团队推出的多模态视觉语言模型,在文本理解、视觉感知、推理能力和长上下文处理等多个维度都实现了显著升级。这个系列提供了从轻量到旗舰的多种规格,并具备视觉智能体、空间感知等前沿能力,旨在让 AI 不仅能“看到”,更能真正“理解”世界。
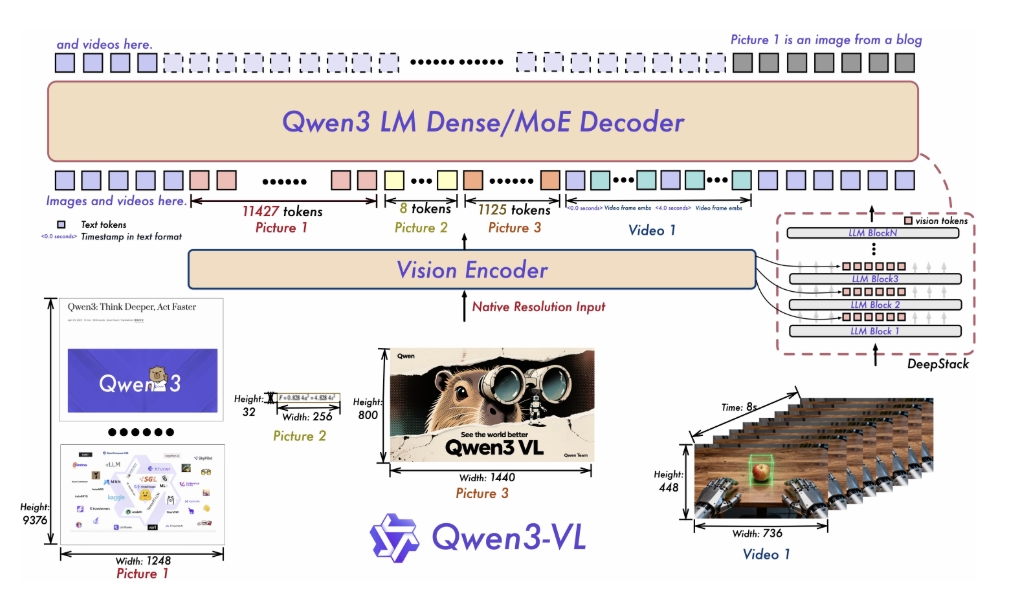
核心升级亮点
- 视觉智能体
可操作PC/移动端图形界面——识别元素、理解功能、调用工具、完成任务
- 视觉编程增强
根据图像/视频生成Draw.io图表/HTML/CSS/JS代码
- 进阶空间感知
判断物体位置、视角与遮挡关系,提供更强2D定位并支持3D空间推理与具身智能
- 长上下文与视频理解
原生256K上下文(可扩展至1M),可处理书籍和数小时视频,实现完整记忆与秒级索引
- 增强多模态推理
在STEM/数学领域表现突出——支持因果分析与基于证据的逻辑解答
- 升级视觉识别
经更广范围、更高质量预训练,可实现“万物识别”——涵盖名人、动漫、商品、地标、动植物等
- 扩展OCR能力
支持32种语言(原为19种),在弱光、模糊、倾斜场景下表现稳健,更好处理生僻字/古文字及专业术语,提升长文档结构解析能力
- 媲美纯文本大模型的理解力
通过无缝图文融合实现无损统一理解
API调用
- 服务部署成功后,可在服务列表查看调用信息
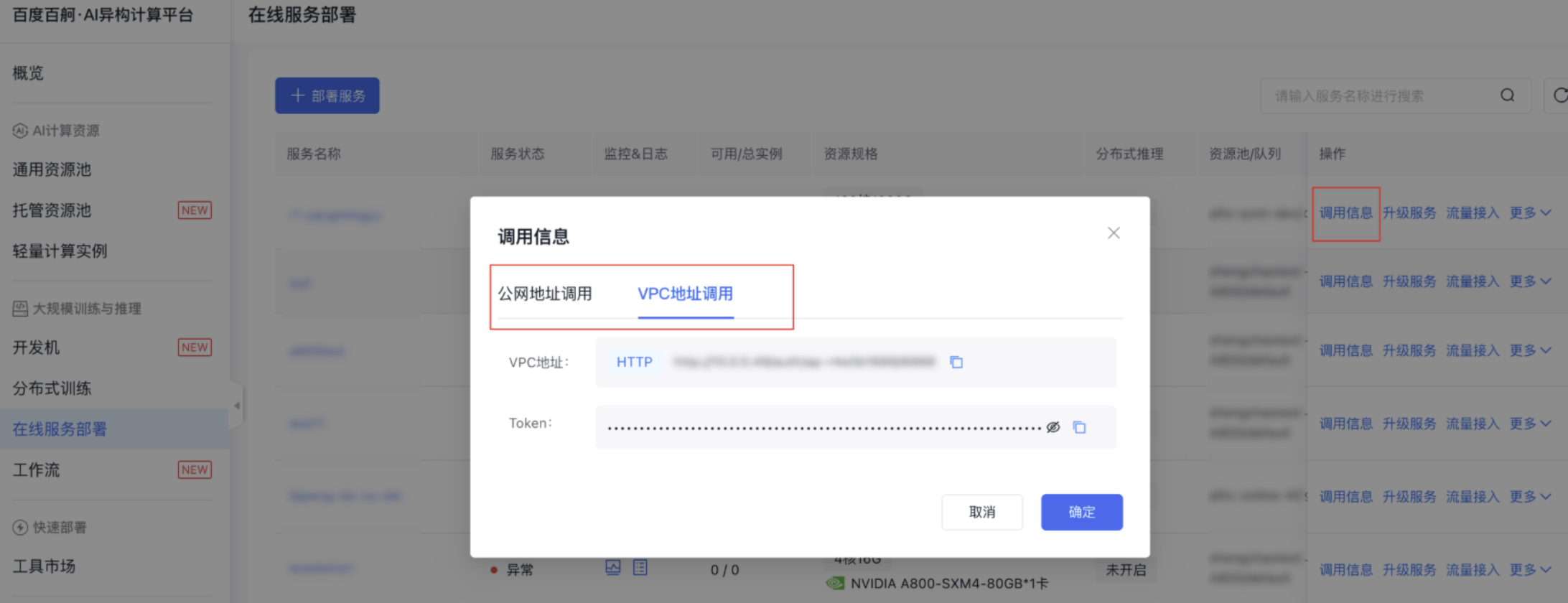
2.调用示例
Plain Text
1curl -X POST "<访问地址>/v1/chat/completions" \
2-H "Content-Type: application/json" \
3-H "Authorization: Bearer TOKEN" \
4-d '{
5 "model": "Qwen3-VL-8B-Instruct",
6 "messages": [
7 {
8 "role": "user",
9 "content": [
10 {"type": "text", "text": "请描述这张图片的内容"},
11 {"type": "image_url", "image_url": {"url": "https://example.com/path/to/image.jpg"}}
12 ]
13 }
14 ],
15 "max_tokens": 1024,
16 "temperature": 0.7
17}'