
新建TensorFlow任务
更新时间:2025-05-30
您可以新建一个TensorFlow类型的任务。
前提条件
- 您已成功安装CCE AI Job Scheduler和CCE Deep Learning Frameworks Operator组件,否则云原生AI功能将无法使用。
- 若您是子用户,队列关联的用户中有您才能使用该队列新建任务。
- 安装组件CCE Deep Learning Frameworks Operator时,系统安装了TensorFlow深度学习框架。
操作步骤
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击云原生AI > 任务管理。
- 在任务管理页面单击新建任务。
- 在新建任务页面中,完成任务基本信息配置:
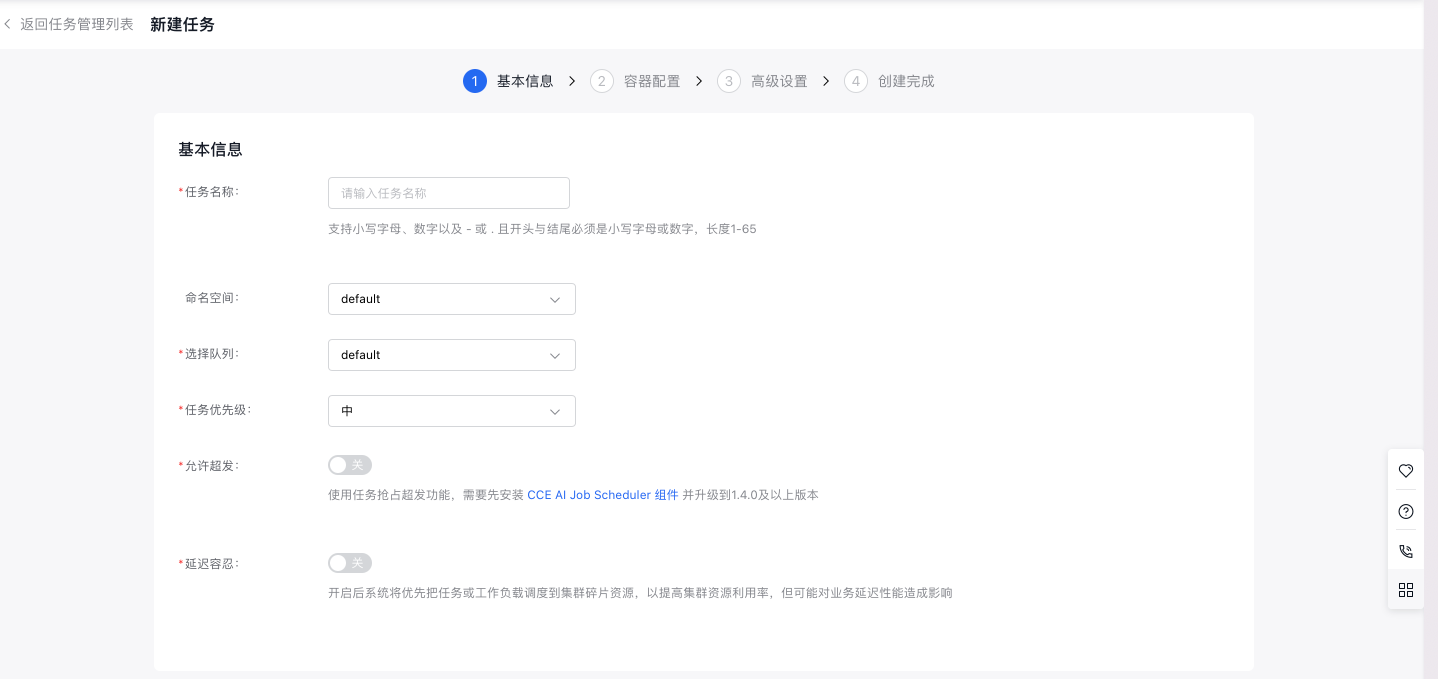
- 任务名称:自定义任务名称,支持小写字母、数字、以及-或.且开头与结尾必须是小写字母或者数字,长度 1-65。
- 命名空间:选择新建任务所在的命名空间。
- 队列:选择新建任务关联的队列。
- 任务优先级:选择任务对应的任务优先级。
- 允许超发:允许超发将使用任务抢占超发功能,需要先安装CCE AI Job Scheduler组件并升级到1.4.0及以上版本。
- 延迟容忍:系统将优先把任务或工作负载调度到集群碎片资源,以提高集群资源利用率,但可能对业务延迟行能造成影响。
- 完成代码基本信息配置:
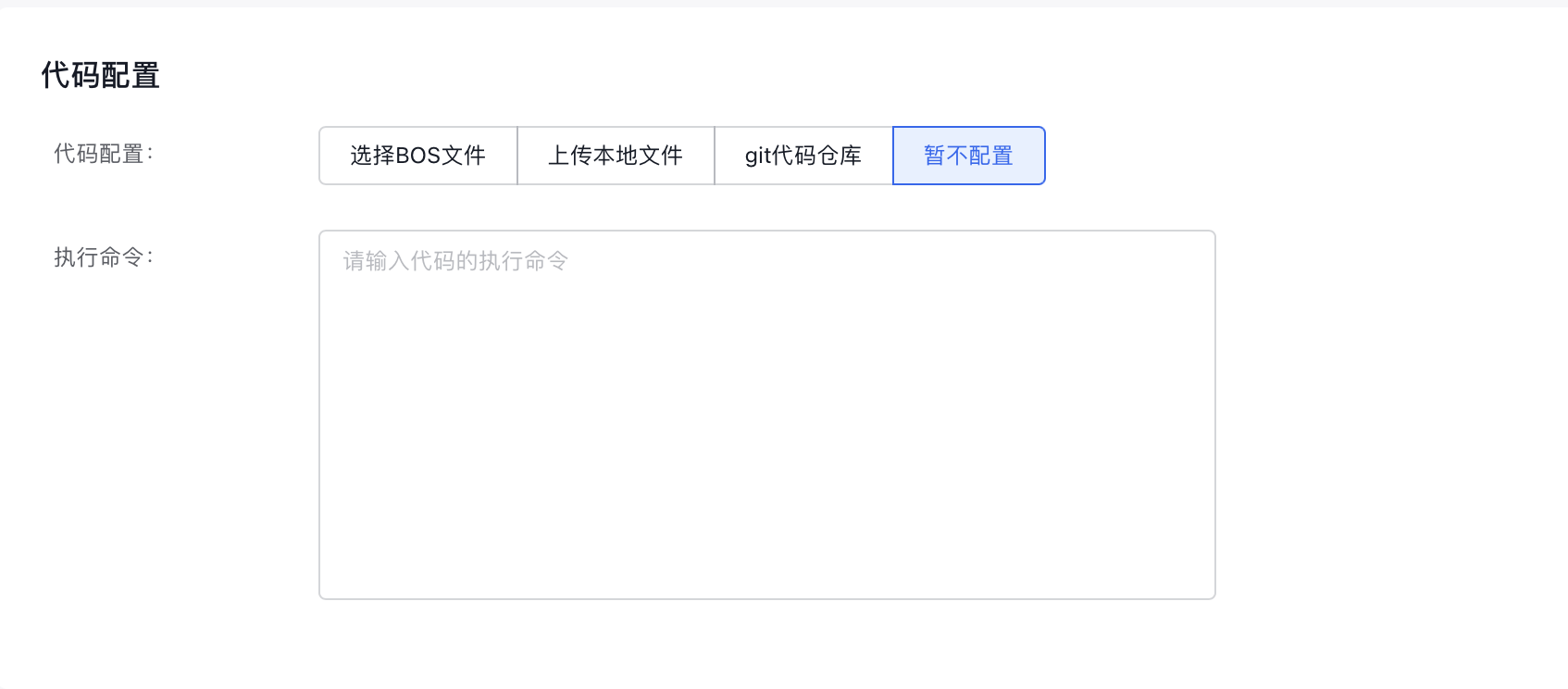
- 代码配置类型:指定代码配置方式,目前支持“BOS文件”、“本地文件上传”、“git代码仓库“与“暂不配置”。
-
执行命令:指定代码的执行命令。
9.完成数据相关信息配置:

-
设置数据源:当前支持数据集、持久卷声明、选择临时路径和选择主机路径。选择数据集时列出所有可用的数据集,选择后会同时选择与数据集同名的持久卷声明;使用持久卷声明时直接选择即可。
10.点击“下一步”,进入容器相关配置。
11.完成任务类型相关信息配置:
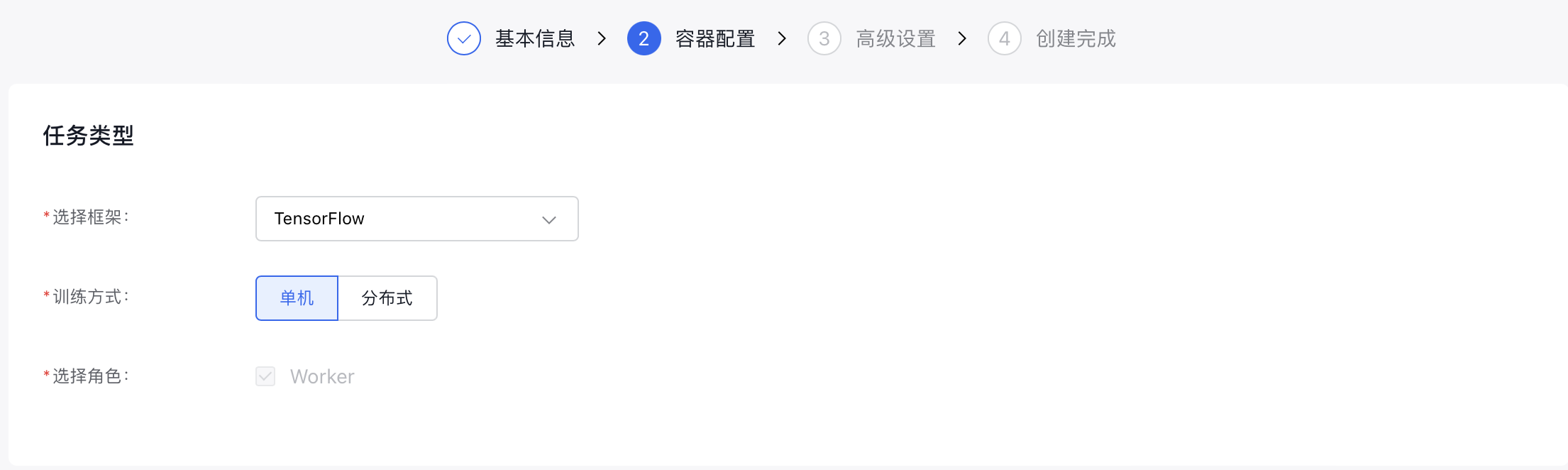
- 选择框架:选择“ TensorFlow ”。
- 训练方式:指定训练方式为“单机”或“分布式”。
-
选择角色:训练方式为“单机”时,只能选择“Woker”;训练方式为“分布式”时,可额外选择“PS”、“Chief”、“Evaluator”。
12.完成容器组相关信息配置,可以根据需要同时进行高级设置。
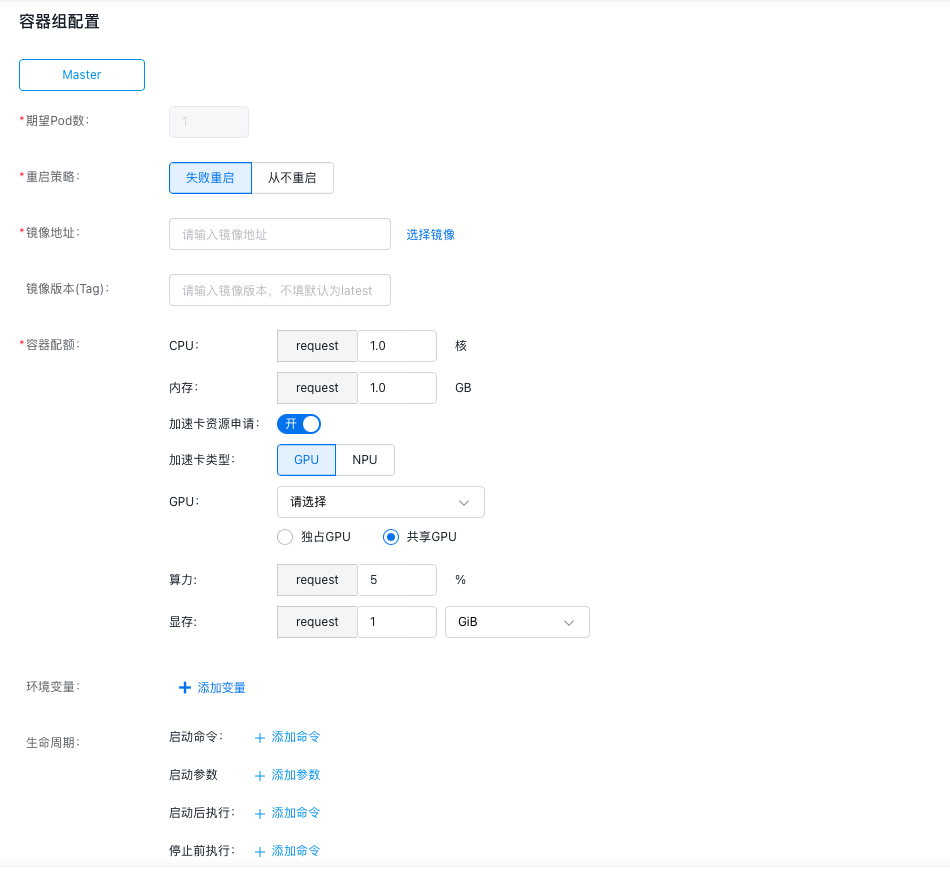
- 期望Pod数:指定容器组的Pod数目。
- 重启策略:指定容器组的重启策略,可选择的策略有“失败重启”或“从不重启”。
- 镜像地址:指定容器的镜像拉取地址,也可以直接点击“选择镜像”,选择需要使用的镜像。
- 镜像版本:指定镜像的版本,若不指定默认拉取latest版。
- 容器配额:指定容器的CPU、内存、GPU/NPU资源相关信息。
- 环境变量:填写变量名和变量值。
-
生命周期:包含启动命令、启动参数、启动后执行和停止前执行,可根据需要添加。
13.完成任务高级信息相关配置。
- 私有仓库凭证:若需要使用私有镜像仓库,请在此处添加对应镜像仓库的访问凭证。
- Tensorboard:若需要任务可视化时,可开启Tensorboard功能,开启后需要指定“服务类型”与“ 训练日志读取路径”。
- K8S标签:指定任务对应的K8S Label。
- 注释:指定任务对应的Annotation。
- 点击“完成”按钮,完成任务的新建。
Yaml创建任务示例
Plain Text
1apiVersion: "kubeflow.org/v1"
2kind: "TFJob"
3metadata:
4 name: "tfjob-dist-mnist-for-e2e-test"
5spec:
6 tfReplicaSpecs:
7 PS:
8 replicas: 2
9 restartPolicy: Never
10 template:
11 metadata:
12 annotations:
13 sidecar.istio.io/inject: "false"
14 # if your libcuda.so.1 is in custom path, set the correct path with the following annotation
15 # kubernetes.io/baidu-cgpu.nvidia-driver-lib: /usr/lib64
16 spec:
17 schedulerName: volcano
18 containers:
19 - name: tensorflow
20 image: registry.baidubce.com/cce-public/kubeflow/tf-dist-mnist-test:1.0
21 resources:
22 requests:
23 cpu: 1
24 memory: 1Gi
25 limits:
26 baidu.com/v100_32g_cgpu: "1"
27 # for gpu core/memory isolation
28 baidu.com/v100_32g_cgpu_core: 10
29 baidu.com/v100_32g_cgpu_memory: "2"
30 # if gpu core isolation is enabled, set the following preStop hook for graceful shutdown.
31 # ${'`'}dist_mnist.py${'`'} needs to be replaced with the name of your gpu process.
32 lifecycle:
33 preStop:
34 exec:
35 command: [
36 "/bin/sh", "-c",
37 "kill -10 `ps -ef | grep dist_mnist.py | grep -v grep | awk '{print $2}'` && sleep 1"
38 ]
39 Worker:
40 replicas: 4
41 restartPolicy: Never
42 template:
43 metadata:
44 annotations:
45 sidecar.istio.io/inject: "false"
46 # if your libcuda.so.1 is in custom path, set the correct path with the following annotation
47 # kubernetes.io/baidu-cgpu.nvidia-driver-lib: /usr/lib64
48 spec:
49 schedulerName: volcano
50 containers:
51 - name: tensorflow
52 image: registry.baidubce.com/cce-public/kubeflow/tf-dist-mnist-test:1.0
53 env:
54 # for gpu memory over request, set 0 to disable
55 - name: CGPU_MEM_ALLOCATOR_TYPE
56 value: “1”
57 resources:
58 requests:
59 cpu: 1
60 memory: 1Gi
61 limits:
62 baidu.com/v100_32g_cgpu: "1"
63 # for gpu core/memory isolation
64 baidu.com/v100_32g_cgpu_core: 20
65 baidu.com/v100_32g_cgpu_memory: "4"
66 # if gpu core isolation is enabled, set the following preStop hook for graceful shutdown.
67 # ${'`'}dist_mnist.py${'`'} needs to be replaced with the name of your gpu process.
68 lifecycle:
69 preStop:
70 exec:
71 command: [
72 "/bin/sh", "-c",
73 "kill -10 `ps -ef | grep dist_mnist.py | grep -v grep | awk '{print $2}'` && sleep 1"
74 ]评价此篇文章