基于 NCCL的RDMA分布式训练示例
概述
RDMA(Remote Direct Memory Access)是新一代的网络通信技术,它允许计算机之间直接进行内存对内存的数据传输,而不需要经过操作系统或中央处理器的处理。在大规模的分布式训练中,通过使用RDMA有效解决网络传输中服务器端数据处理的延迟问题,从而实现高吞吐、低延迟的网络通信,提升训练效率。
本文档用于介绍在云原生AI的环境下使用 RDMA 网络进行分布式训练。
说明:
1、由于 RDMA 网络的特殊性,以下示例在自建k8s集群中可能无法适用。
2、IB和RoCE在使用上几乎无区别,如无特别说明以下均以RoCE为例,IB在应用侧无需更改。
3、业务镜像中需要使用 nccl 依赖库,这里推荐使用 NVIDIA GPU Cloud(NGC)提供的基础镜像。NGC 提供的基础镜像通常会包含 nccl 依赖库,并且已经预先配置和优化了许多常用的深度学习框架和工具。使用 NGC 基础镜像可以简化您的设置和配置过程,并确保您能够顺利使用 nccl 进行 GPU 加速计算和深度学习任务。
使用前提
- 已经创建集群,且集群中至少有2台具有RDMA网络的GPU实例。
- GPU实例镜像中包含ofed和nvidia驱动,这里推荐使用百度智能云提供的GPU镜像,已包含OFED驱动,无需手动安装。
- 集群已安装 云原生AI CCE RDMA Device Plugin、 CCE GPU Manager 、 CCE AI Job Scheduler 和 CCE Deep Learning Frameworks Operator 组件。
环境验证
登录集群内具有 RDMA 网络的GPU节点,运行以下命令验证主机环境。
- 验证 ofed 驱动
1$ ofed_info -s #roce驱动版本
2MLNX_OFED_LINUX-5.8-1.1.2.1:- 验证 Nvidia GPU 驱动
1$ nvidia-smi #nvidia gpu驱动
2+-----------------------------------------------------------------------------+
3| NVIDIA-SMI 470.141.03 Driver Version: 470.141.03 CUDA Version: 11.4 |
4|-------------------------------+----------------------+----------------------+
5| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
6| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
7| | | MIG M. |
8|===============================+======================+======================|
9| 0 NVIDIA A100-SXM... On | 00000000:53:00.0 Off | 0 |
10| N/A 29C P0 64W / 400W | 0MiB / 81251MiB | 0% Default |
11| | | Disabled |
12+-------------------------------+----------------------+----------------------+
13| 1 NVIDIA A100-SXM... On | 00000000:59:00.0 Off | 0 |
14| N/A 32C P0 61W / 400W | 0MiB / 81251MiB | 0% Default |
15| | | Disabled |
16+-------------------------------+----------------------+----------------------+
17| 2 NVIDIA A100-SXM... On | 00000000:6E:00.0 Off | 0 |
18| N/A 33C P0 67W / 400W | 0MiB / 81251MiB | 0% Default |
19| | | Disabled |
20+-------------------------------+----------------------+----------------------+
21| 3 NVIDIA A100-SXM... On | 00000000:73:00.0 Off | 0 |
22| N/A 29C P0 60W / 400W | 0MiB / 81251MiB | 0% Default |
23| | | Disabled |
24+-------------------------------+----------------------+----------------------+
25| 4 NVIDIA A100-SXM... On | 00000000:8D:00.0 Off | 0 |
26| N/A 29C P0 60W / 400W | 0MiB / 81251MiB | 0% Default |
27| | | Disabled |
28+-------------------------------+----------------------+----------------------+
29| 5 NVIDIA A100-SXM... On | 00000000:92:00.0 Off | 0 |
30| N/A 32C P0 65W / 400W | 0MiB / 81251MiB | 0% Default |
31| | | Disabled |
32+-------------------------------+----------------------+----------------------+
33| 6 NVIDIA A100-SXM... On | 00000000:C9:00.0 Off | 0 |
34| N/A 33C P0 64W / 400W | 0MiB / 81251MiB | 0% Default |
35| | | Disabled |
36+-------------------------------+----------------------+----------------------+
37| 7 NVIDIA A100-SXM... On | 00000000:CF:00.0 Off | 0 |
38| N/A 28C P0 62W / 400W | 0MiB / 81251MiB | 0% Default |
39| | | Disabled |
40+-------------------------------+----------------------+----------------------+
41
42+-----------------------------------------------------------------------------+
43| Processes: |
44| GPU GI CI PID Type Process name GPU Memory |
45| ID ID Usage |
46|=============================================================================|
47| No running processes found |
48+-----------------------------------------------------------------------------+- 查询 RDMA 网卡
1$ show_gids
2DEV PORT INDEX GID IPv4 VER DEV
3--- ---- ----- --- ------------ --- ---
4mlx5_0 1 0 fe80:0000:0000:0000:f820:20ff:fe28:c769 v1 eth0
5mlx5_0 1 1 fe80:0000:0000:0000:f820:20ff:fe28:c769 v2 eth0
6mlx5_0 1 2 0000:0000:0000:0000:0000:ffff:0a00:3c03 10.0.60.3 v1 eth0
7mlx5_0 1 3 0000:0000:0000:0000:0000:ffff:0a00:3c03 10.0.60.3 v2 eth0
8mlx5_1 1 0 fe80:0000:0000:0000:eaeb:d3ff:fecc:c920 v1 eth1
9mlx5_1 1 1 fe80:0000:0000:0000:eaeb:d3ff:fecc:c920 v2 eth1
10mlx5_1 1 2 0000:0000:0000:0000:0000:ffff:190b:8002 25.11.128.2 v1 eth1
11mlx5_1 1 3 0000:0000:0000:0000:0000:ffff:190b:8002 25.11.128.2 v2 eth1
12mlx5_2 1 0 fe80:0000:0000:0000:eaeb:d3ff:fecc:c921 v1 eth2
13mlx5_2 1 1 fe80:0000:0000:0000:eaeb:d3ff:fecc:c921 v2 eth2
14mlx5_2 1 2 0000:0000:0000:0000:0000:ffff:190b:8022 25.11.128.34 v1 eth2
15mlx5_2 1 3 0000:0000:0000:0000:0000:ffff:190b:8022 25.11.128.34 v2 eth2
16mlx5_3 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe6c:51d2 v1 eth3
17mlx5_3 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe6c:51d2 v2 eth3
18mlx5_3 1 2 0000:0000:0000:0000:0000:ffff:190b:8042 25.11.128.66 v1 eth3
19mlx5_3 1 3 0000:0000:0000:0000:0000:ffff:190b:8042 25.11.128.66 v2 eth3
20mlx5_4 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe6c:51d3 v1 eth4
21mlx5_4 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe6c:51d3 v2 eth4
22mlx5_4 1 2 0000:0000:0000:0000:0000:ffff:190b:8062 25.11.128.98 v1 eth4
23mlx5_4 1 3 0000:0000:0000:0000:0000:ffff:190b:8062 25.11.128.98 v2 eth4
24mlx5_5 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe33:1366 v1 eth5
25mlx5_5 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe33:1366 v2 eth5
26mlx5_5 1 2 0000:0000:0000:0000:0000:ffff:190b:8082 25.11.128.130 v1 eth5
27mlx5_5 1 3 0000:0000:0000:0000:0000:ffff:190b:8082 25.11.128.130 v2 eth5
28mlx5_6 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe33:1367 v1 eth6
29mlx5_6 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe33:1367 v2 eth6
30mlx5_6 1 2 0000:0000:0000:0000:0000:ffff:190b:80a2 25.11.128.162 v1 eth6
31mlx5_6 1 3 0000:0000:0000:0000:0000:ffff:190b:80a2 25.11.128.162 v2 eth6
32mlx5_7 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe6c:68ae v1 eth7
33mlx5_7 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe6c:68ae v2 eth7
34mlx5_7 1 2 0000:0000:0000:0000:0000:ffff:190b:80c2 25.11.128.194 v1 eth7
35mlx5_7 1 3 0000:0000:0000:0000:0000:ffff:190b:80c2 25.11.128.194 v2 eth7
36mlx5_8 1 0 fe80:0000:0000:0000:eaeb:d3ff:fe6c:68af v1 eth8
37mlx5_8 1 1 fe80:0000:0000:0000:eaeb:d3ff:fe6c:68af v2 eth8
38mlx5_8 1 2 0000:0000:0000:0000:0000:ffff:190b:80e2 25.11.128.226 v1 eth8
39mlx5_8 1 3 0000:0000:0000:0000:0000:ffff:190b:80e2 25.11.128.226 v2 eth8提交任务
NCCL是NVIDIA的集合通信库,能实现Collective通信和点对点通信,NCCL内部已经实现了RDMA通信,同时NCCL可以根据环境中网卡类型和拓扑关系,自行选择一个最优的通信路径,目前主流的分布式训练框架都已支持NCCL。
下面介绍将介绍如何在云原生AI 上通过 YAML或者控制台的方式,提交基于NCCL的RDMA分布式训练任务。
YAML方式提交任务
准备
已通过kubectl连接kubernetes集群。具体操作,请参见通过Kubectl连接集群。
任务示例
以下是一个swin-transformer基于NCCL的Pytorch分布式训练任务的示例:
1apiVersion: "kubeflow.org/v1"
2kind: "PyTorchJob"
3metadata:
4 name: "pytorch-swin-transformer-nccl"
5spec:
6 pytorchReplicaSpecs:
7 Master:
8 replicas: 1
9 restartPolicy: OnFailure
10 template:
11 metadata:
12 annotations:
13 sidecar.istio.io/inject: "false"
14 spec:
15 containers:
16 - name: pytorch
17 image: registry.baidubce.com/cce-ai-native/swin-transformer-torch:v2.0
18 imagePullPolicy: IfNotPresent
19 command:
20 - /bin/sh
21 - -c
22 - python -m torch.distributed.launch --nproc_per_node 8 --nnodes $WORLD_SIZE --node_rank $RANK --master_addr $HOSTNAME --master_port $MASTER_PORT main.py --cfg configs/swin/swin_large_patch4_window7_224_22k.yaml --pretrained swin_large_patch4_window7_224_22k.pth --data-path /imagenet --batch-size 128 --accumulation-steps 2
23 env:
24 - name: NCCL_DEBUG
25 value: "INFO"
26 - name: NCCL_IB_DISABLE
27 value: "0"
28 securityContext:
29 capabilities:
30 add: [ "IPC_LOCK" ]
31 resources:
32 limits:
33 baidu.com/a100_80g_cgpu: 8
34 rdma/hca: 1
35 volumeMounts:
36 - mountPath: /imagenet
37 name: dataset
38 - mountPath: /dev/shm
39 name: cache-volume
40 schedulerName: volcano
41 volumes:
42 - name: dataset
43 persistentVolumeClaim:
44 claimName: imagenet-22k-pvc
45 - emptyDir:
46 medium: Memory
47 name: cache-volume
48 Worker:
49 replicas: 1
50 restartPolicy: OnFailure
51 template:
52 metadata:
53 annotations:
54 sidecar.istio.io/inject: "false"
55 spec:
56 containers:
57 - name: pytorch
58 image: registry.baidubce.com/cce-ai-native/swin-transformer-torch:v2.0
59 imagePullPolicy: IfNotPresent
60 command:
61 - /bin/sh
62 - -c
63 - python -m torch.distributed.launch --nproc_per_node 8 --nnodes $WORLD_SIZE --node_rank $RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT main.py --cfg configs/swin/swin_large_patch4_window7_224_22k.yaml --pretrained swin_large_patch4_window7_224_22k.pth --data-path /imagenet --batch-size 128 --accumulation-steps 2
64 env:
65 - name: NCCL_DEBUG
66 value: "INFO"
67 - name: NCCL_IB_DISABLE
68 value: "0"
69 securityContext:
70 capabilities:
71 add: [ "IPC_LOCK" ]
72 resources:
73 limits:
74 baidu.com/a100_80g_cgpu: 8
75 rdma/hca: 1
76 volumeMounts:
77 - mountPath: /imagenet
78 name: dataset
79 - mountPath: /dev/shm
80 name: cache-volume
81 volumes:
82 - name: dataset
83 persistentVolumeClaim:
84 claimName: imagenet-22k-pvc
85 - emptyDir:
86 medium: Memory
87 name: cache-volume
88 schedulerName: volcano
89---
90apiVersion: v1
91kind: PersistentVolume
92metadata:
93 name: imagenet-22k-pv
94spec:
95 accessModes:
96 - ReadWriteMany
97 storageClassName:
98 capacity:
99 storage: 100Gi
100 csi:
101 driver: csi-clusterfileplugin
102 volumeHandle: data-id
103 volumeAttributes:
104 parentDir: / #必填,自定义路径
105 path: "" #必填,pfs 挂载路径,这里需要填写相对于 parentDir 的路径
106 clusterIP: "" #必填,pfs实例的endpoint
107 clusterPort: "8888" #必填,当前端口固定为8888
108 clientID: "" #非必填,pfs实例的id
109
110---
111kind: PersistentVolumeClaim
112apiVersion: v1
113metadata:
114 name: imagenet-22k-pvc
115 namespace: default
116spec:
117 accessModes:
118 - ReadWriteMany
119 storageClassName:
120 resources:
121 requests:
122 storage: 100Gi关键参数说明
-
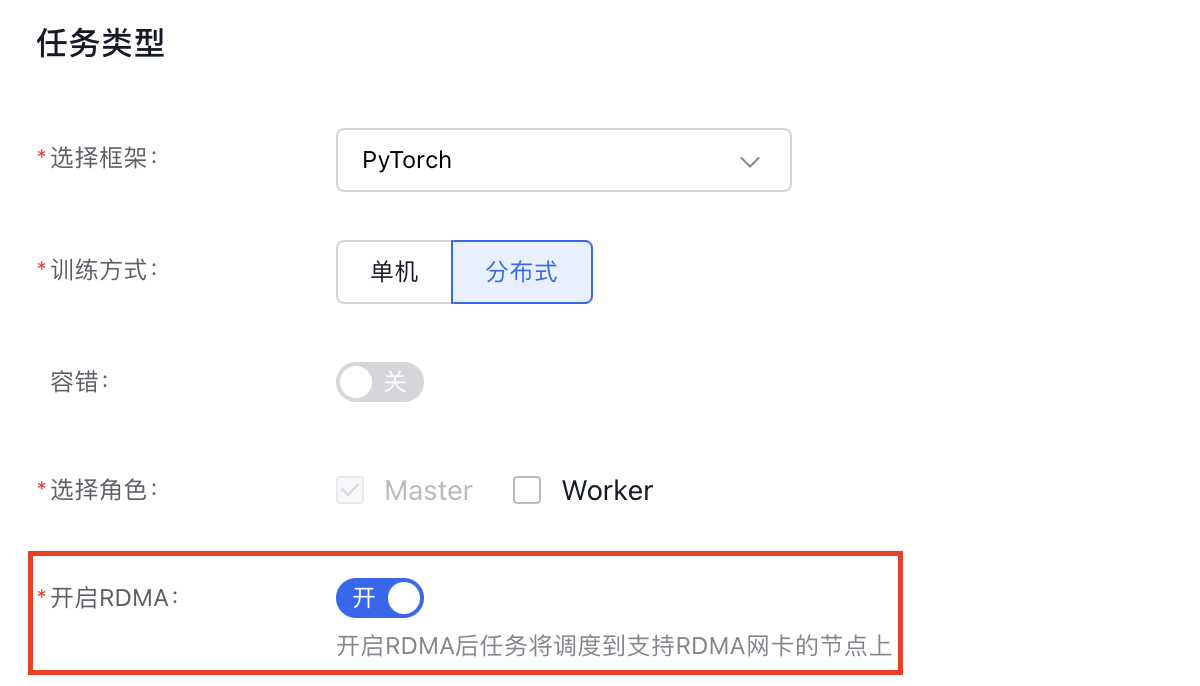
NCCL需要输入环境变量来使能RDMA特性,具体包括以下环境变量:
备注:带 * 号的环境变量,云原生AI会基于百度智能云内部大规模分布式训练经验,在任务运行时会自动注入推荐的值,无需手动填写
| 键 | 值 | 含义 | 备注 |
|---|---|---|---|
| NCCL_IB_DISABLE | 0,1 | 0代表NCCL使用的IB/RoCE传输; 1代表禁止NCCL使用的IB/RoCE传输。此时NCCL将退回到使用IP套接字 |
-- |
| NCCL_IB_HCA* | mlx5_1 ~ mlx5_8 | NCCL_IB_HCA 变量指定使用哪些RDMA接口进行通信。 根据套餐类型填对应的值,例如:8卡的roce套餐填mlx5_1~mlx5_8,4卡为mlx5_1~mlx5_4,以此类推。 注:mlx5_0通常为tcp网络的主网卡 |
云原生AI在任务运行时,会自动检测容器的roce环境,并为容器PID为1的进程自动注入NCCL_IB_HCA 、NCCL_SOCKET_IFNAME 、 NCCL_IB_GID_INDEX、NCCL_IB_TIMEOUT 和 NCCL_IB_QPS_PER_CONNECTION 环境变量;通过PID1创建的子进程会继承这个环境变量,但是如果是通过sh启动的进程则无法继承。 如果用户在yaml中声明了这几个环境变量,容器运行时则不再自动注入 |
| NCCL_SOCKET_IFNAME* | eth0 | NCCL_SOCKET_IFNAME变量指定使用哪个IP接口进行通信; 注:容器内默认是eth0 |
|
| NCCL_IB_GID_INDEX* | 动态值 | NCCL_IB_GID_INDEX变量定义了RoCE模式中使用的全局ID索引。设置方法请参见ib show_gids命令。 注:如果是通过容器网络使用RoCE网卡,CCE的CNI插件会为容器创建对应数量的子网卡,roce网卡的GID INDEX会动态生成。如果容器内有show_gids命令,可以看到对应的值。 |
|
| NCCL_IB_TIMEOUT* | 22 | 网络断点重连超时时间。 | |
| NCCL_IB_QPS_PER_CONNECTION* | 8 | 每个IB qp连接的连接数。 | |
| NCCL_DEBUG | INFO | NCCL_DEBUG变量控制从NCCL显示的调试信息。此变量通常用于调试。 |