
接入监控实例并开启采集任务
更新时间:2026-03-23
概述
若您需要使用云原生 AI 资源观测功能,需先将集群接入 CProm 监控实例并开启采集任务。本文档介绍集群接入监控实例、校验监控状态,以及启用 GPU/NPU 大盘所需采集任务的操作方法。
前提条件
- 已登录 容器引擎CCE控制台。
- 账号已开通 CProm 服务,且具备目标集群与监控实例的查看和操作权限。
- 目标 CCE 集群处于可用状态。## 操作步骤
- 登录容器引擎CCE控制台。
集群接入 CProm 监控实例并校验状态
导航路径:容器引擎 CCE 控制台->【集群管理】->【集群列表】->目标集群->【更多】->【Prometheus 监控】
步骤 1:从集群列表进入 Prometheus 监控页面
- 登录 容器引擎CCE控制台,进入 【集群管理】 -> 【集群列表】。
- 在目标集群的操作菜单中点击 【更多】 -> 【Prometheus 监控】。
- 进入 Prometheus 监控 页面后,确认存在 【跳转到 Prometheus 监控服务】 入口。
步骤 2:检查 CProm 实例关联与监控状态
- 在 Prometheus 监控 页面检查 CProm 实例关联状态。若已关联,则继续查看监控数据并执行后续采集配置;若未关联,则页面显示 【接入实例】 入口。
- 检查监控状态。若监控状态正常,可切换到预置监控面板页面;若监控状态异常或处理中,页面会显示状态信息并提示继续检查或重试。
- 若流程中出现 【确定】 确认弹窗,系统会先校验 CProm 产品开通状态和当前用户权限;若不满足条件,则报错并停止接入流程。


步骤 3:执行重试并校验接入流程继续
- 当页面出现接入异常或超时提示时,点击 【重试】,触发系统重新执行接入流程。
- 点击后页面状态切换为“接入中”等提示,表示系统已继续执行接入与监控状态检查。1. 在 CCE 集群的 Prometheus 监控 页面,点击 【跳转到 Prometheus 监控服务】,进入 Prometheus 监控服务实例列表页。

- 在 监控实例 列表中选择 CCE 集群型实例,点击 实例名称,进入实例详情页。
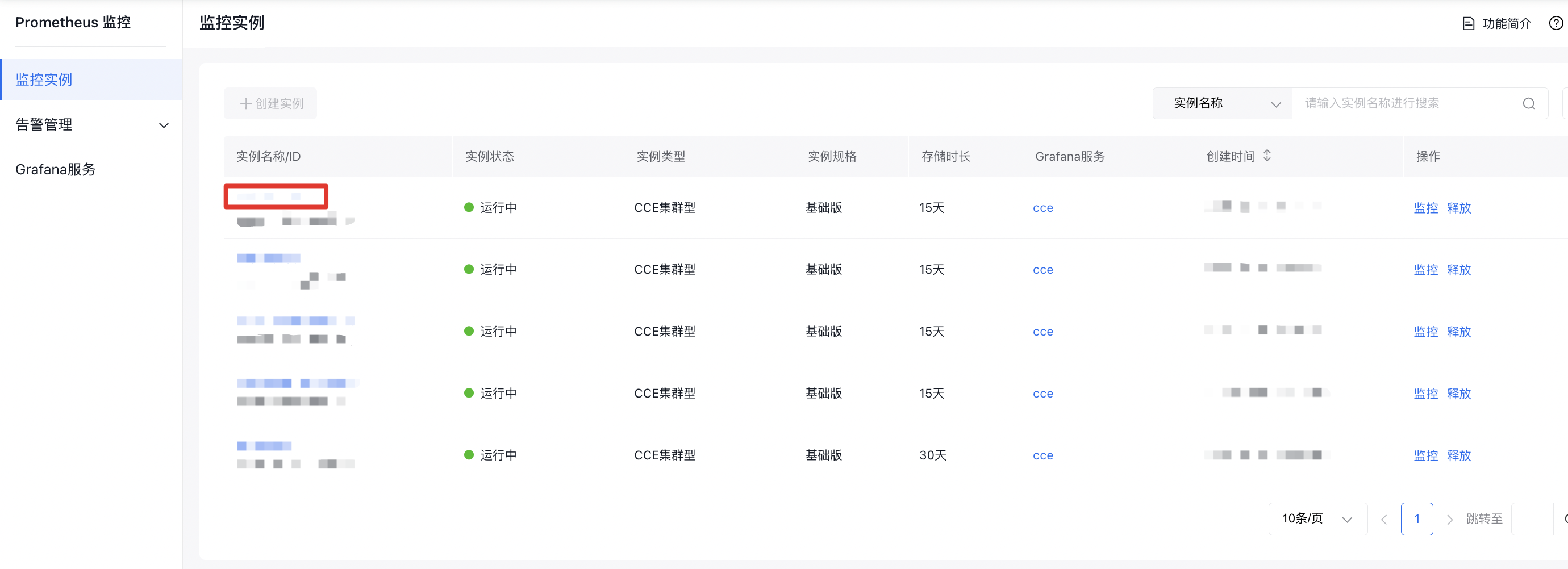
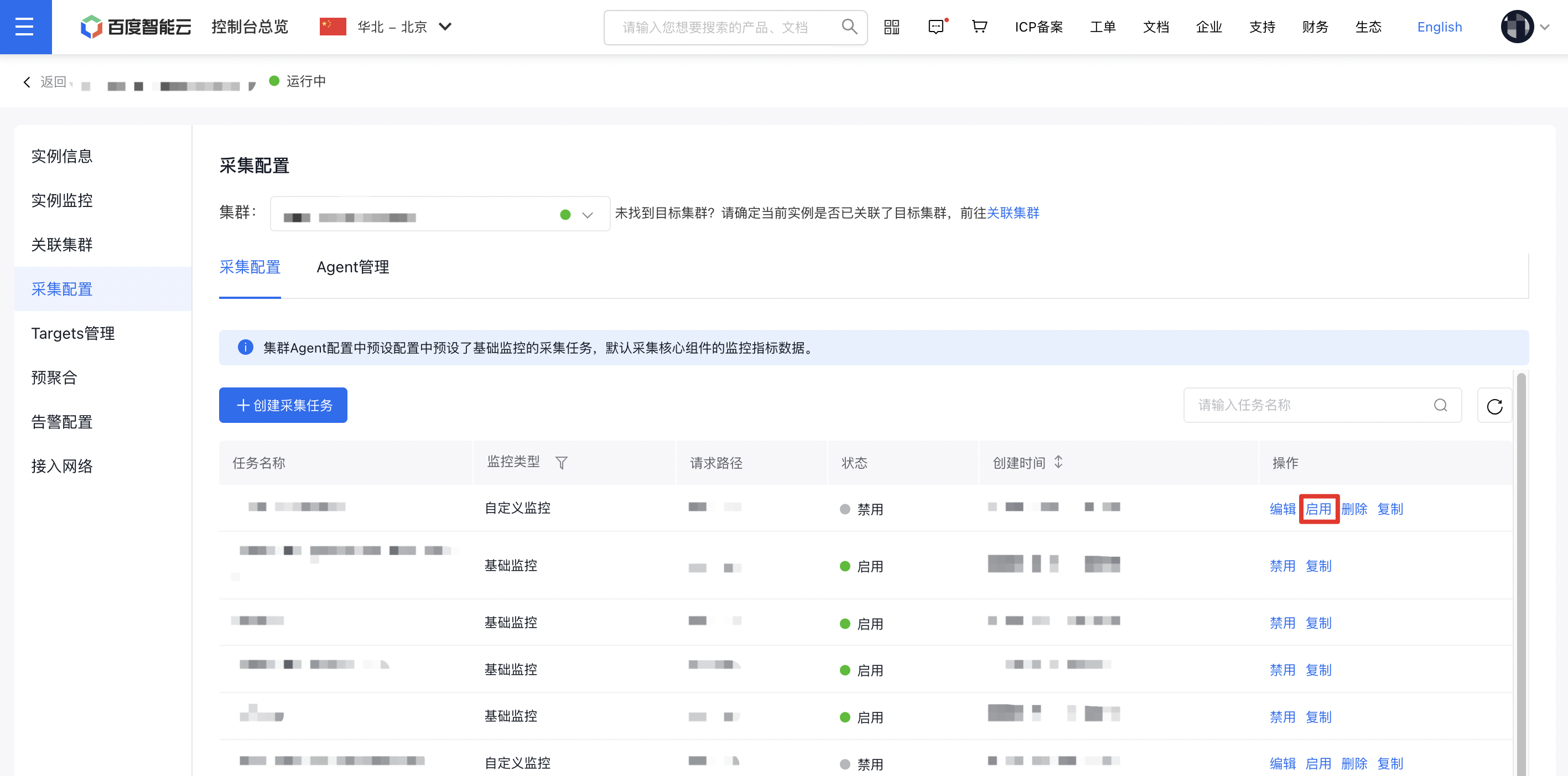
步骤 3:进入采集配置并确认任务启用
- 在实例详情页点击 【采集配置】,并选择目标集群。
- 在采集配置列表中检查以下任务:
volcano、kubelet、gpu-dcgm、kubernetes-pods、cadvisor、kubernetes-pods-kube-state-metrics。 - 若任务状态为“禁用”,在 【操作】 中点击 【启用】,使任务状态变为“启用”。
步骤 4:按 Nvidia GPU 大盘要求核对任务清单
- 按本文“GPU/NPU 大盘需开启的采集任务”中的 Nvidia GPU 芯片采集项核对任务。
- 重点确认
kubernetes-pods-kube-state-metrics已启用,以满足 GPUManager 组件采集要求。
启用昇腾 Ascend NPU 大盘采集任务
导航路径:容器引擎 CCE 控制台->【集群管理】->【集群列表】->目标集群->【更多】->【Prometheus 监控】->【跳转到 Prometheus 监控服务】->监控实例->目标实例->【采集配置】
步骤 1:跳转到 Prometheus 监控服务
- 在 CCE 的 Prometheus 监控 页面点击 【跳转到 Prometheus 监控服务】,进入 Prometheus 监控服务 的 监控实例 列表页。
步骤 2:选择实例并进入实例详情
- 在 监控实例 列表中选择目标实例,点击 实例名称 进入详情页。
步骤 3:进入采集配置并选择目标集群
- 在实例详情页点击 【采集配置】。
- 选择目标集群后,在任务列表中按任务名称检查状态。
- 若任务状态为“禁用”,在 【操作】 中点击 【启用】。
步骤 4:按 Ascend NPU 大盘要求核对采集任务
- 依次核对
npu-exporter、kubelet、cadvisor、kubernetes-pods-kube-state-metrics四项任务。 - 确认上述任务均为“启用”状态后,完成 Ascend NPU 大盘采集任务配置。## GPU/NPU大盘需开启的采集任务
Nvidia GPU芯片采集项
| 大盘名称 | volcano | kubelet | gpu-dcgm | kubernetes-pods | cadvisor | kubernetes-pods-kube-state-metrics |
|---|---|---|---|---|---|---|
| GPU资源池总览 | √ | √ | √ | √ | √ | √ |
| GPU节点资源 | √ | √ | √ | √ | √ | √ |
| GPU工作负载资源 | √ | √ | √ | √ | √ | √ |
| AI Job Scheduler组件 | √ | √ | √ | √ | √ | √ |
| GPUManager组件 | — | — | — | — | — | √ |
昇腾 AscendNPU芯片采集项
| 大盘名称 | npu-exporter | kubelet | cadvisor | kubernetes-pods-kube-state-metrics |
|---|---|---|---|---|
| 昇腾资源池总览 | √ | √ | √ | √ |
| 昇腾节点资源 | √ | √ | √ | √ |
| 昇腾工作负载资源 | √ | √ | √ | √ |
评价此篇文章