
CCE Node Remedier 说明
组件介绍
CCE 节点故障自愈系统(CCE-Node-Remedier)是集群节点故障自愈组件,可以根据 CCE-Node-Problem-Detector 上报的故障自动进行节点故障维修。
当 CCE-Node-Problem-Detector(简称 NPD)组件完成节点故障检测后,会以 Condition 或者 Event 的方式上报给 Kubernetes 集群。用户在集群中安装 CCE-Node-Remedier 后,组件会以 Deployment 作为工作负载运行,实时监听每个节点的故障信息,并根据用户自定义的故障处理规则对节点发起相应的维修操作。
CCE-Node-Remedier 在发起对故障节点的维修后,会通过 CRD 向用户暴露对节点的维修进度,同时也会在节点事件中记录维修操作。
组件功能
- 提供根据节点故障自愈功能
- 支持的故障上报方式为:Node Condition
-
故障节点维修信息查询:
- 利用 自定义对象(CRD)记录故障节点的维修进度
- 利用 事件(Event)记录故障节点的维修操作
使用场景
实时监听每个节点的故障信息,并根据用户自定义的故障处理规则对节点发起相应的维修操作。
使用限制
- 集群版本在 1.18.9 以上
- 已经安装了 CCE-Node-Problem-Detector。安装步骤见:CCE Node Problem Detector 说明
- 能够使用 kubectl 访问集群,操作步骤见:通过kubectl连接集群
安装组件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 组件管理 。
- 在组件管理列表中选择 CCE Node Remedier 组件单击“安装”。
- 在组件配置页面中完成节点故障自愈策略配置。
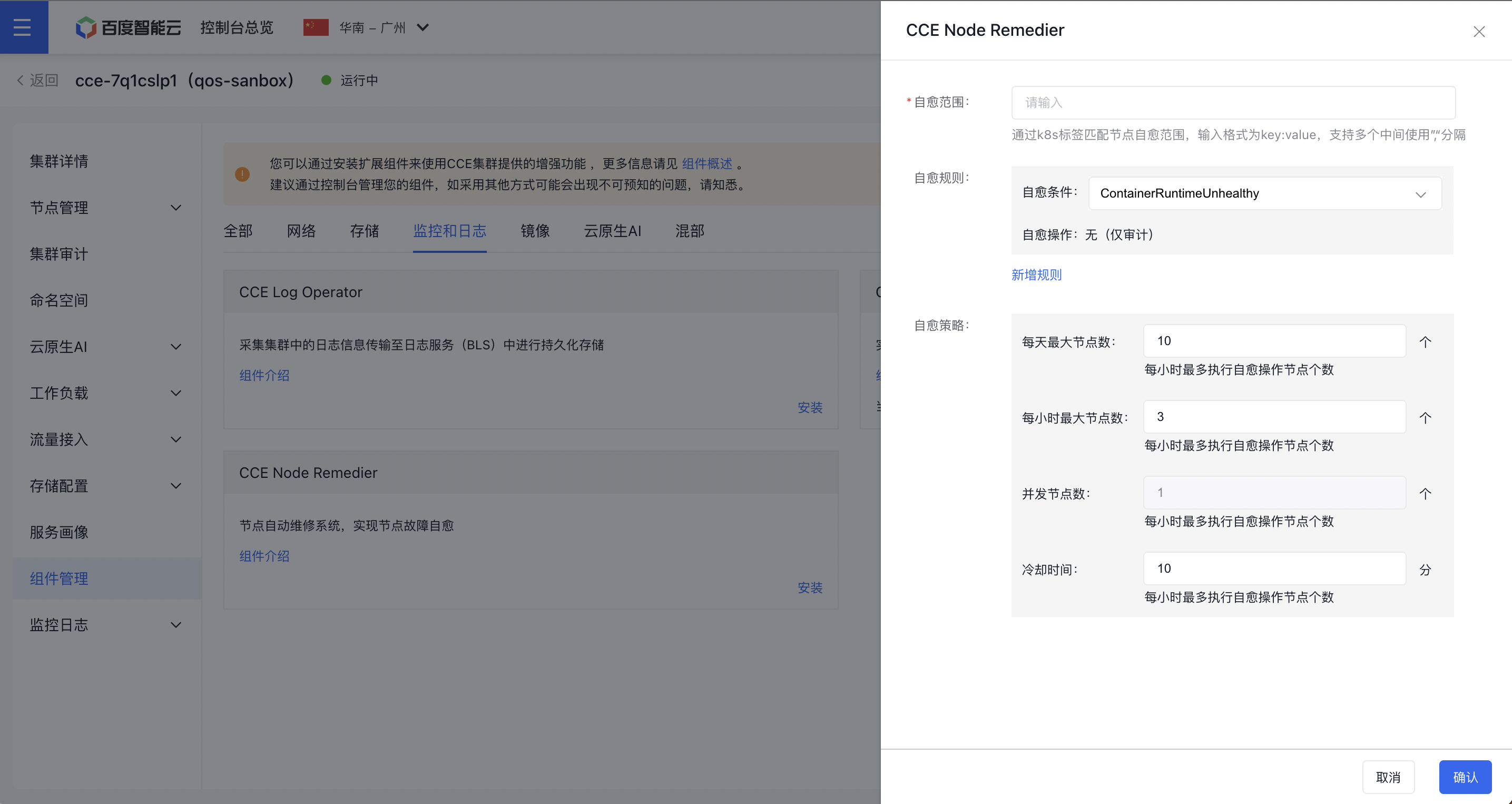
- 点击“确定”按钮完成组件的安装。
配置故障自愈策略
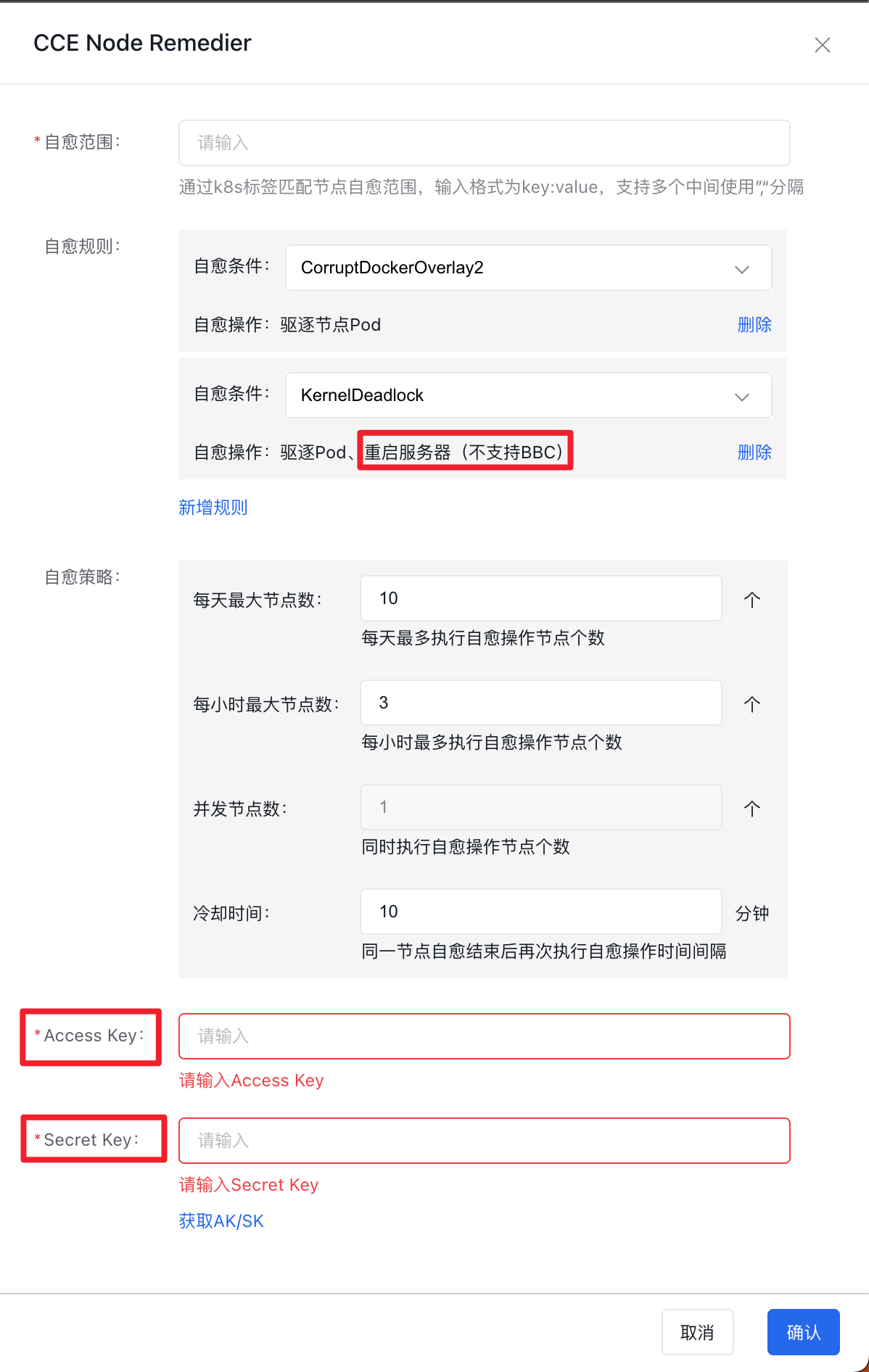
组件配置项如下图:
-
自愈范围:通过k8s标签匹配节点自愈范围,输入格式为 key:value,支持多个中间使用”,“分隔。如:
app:nginx,component:backend;- 用户需要提前在节点上添加期望的 label,或使用默认存在的 label。参考:管理节点标签
-
自愈规则:可配置多组规则,用户可以通过点击“新增规则”添加自愈规则,每组规则包含:
- 自愈条件:指由 CCE-Node-Problem-Detector 上报的,保存在 Node 对象 Condition 中的故障类型;
- 自愈操作:指针对自愈条件,自愈系统所要执行的具体动作,目前暂不支持自定义自愈操作;
支持的自愈条件及自愈操作如下:
| 自愈条件 | 自愈规则 |
|---|---|
| ContainerRuntimeUnhealthy | 无(仅审计) |
| FrequentKubeletRestart | 无(仅审计) |
| FrequentContainerRuntimeRestart | 无(仅审计) |
| InodesPressure | 无(仅审计) |
| CorruptDockerOverlay2 | 驱逐节点Pod |
| KernelDeadlock | 驱逐Pod、重启服务器(不支持BBC) |
| ReadonlyFilesystem | 驱逐Pod、重启服务器(不支持BBC) |
| GPUUnhealthy | 仅冻结(Cordon) |
| NICUnhealthy | 仅冻结(Cordon) |
-
自愈策略:
- 每天最大节点数:每天最多执行自愈操作节点个数,数据类型为整数,默认为 10;
- 每小时最大节点数:每小时最多执行自愈操作节点个数,数据类型为整数,默认为 3;
- 并发节点数:同时执行自愈操作节点个数,数据类型为整数,默认为 1,暂不支持修改;
- 冷却时间:同一节点自愈结束后再次执行自愈操作时间间隔,数据类型为整数,单位为 分钟,默认为 10;
-
Access/Secret Key:当用户选择包含 重启服务器 的自愈条件时,需要填写用户百度云账号的 AccessKey 和 SecretKey
- 了解如何创建、查看和下载 Access Key(AK) 和 Secret Key(SK), 请参考 管理您的AK/SK.
查看节点故障状态及故障维修信息
查看节点故障状态
节点故障状态由 CCE-Node-Problem-Detector 组件上报,故障详情可参考:查看集群健康检查状态
查看节点故障维修信息
CCE-Node-Remedier 在集群中安装了三种自定义资源(CustomResourceDefinition,CRD),名称及作用如下:
NodeRemedier:简写为nr,用于保存节点故障维修策略,对象名称为default-remedier, 查询命令为:
1kubectl -n cce-node-remedier get noderemediers default-remedier -o yaml
2
3kubectl -n cce-node-remedier get nr default-remedier -o yamlMachineRemediationTemplate: 简写为mrtpl,保存节点故障维修的步骤模板,对象名称为default-remediation-template, 查询命令为:
1kubectl -n cce-node-remedier get machineremediationtemplates default-remediation-template -o yaml
2
3kubectl -n cce-node-remedier get mrtpl default-remediation-template -o yamlRemedyMachine: 简写为rm,保存故障节点的具体维修故障和维修详情,每个对象对应一个故障节点,查询命令为:
1kubectl -n cce-node-remedier get remedymachines
2
3kubectl -n cce-node-remedier get rms示例的 RemedyMachine 的 yaml 为:
1apiVersion: apps.baidu.com/v1
2kind: RemedyMachine
3metadata:
4 creationTimestamp: "2023-03-30T01:35:00Z"
5 generation: 1
6 name: cce-node-remedier-default-remedier-cce-covdy1t9-192.168.96.52
7 namespace: cce-node-remedier
8 ownerReferences:
9 - apiVersion: apps.baidu.com/v1
10 blockOwnerDeletion: true
11 controller: true
12 kind: NodeRemedier
13 name: default-remedier
14 uid: 0fe02c17-b344-4c0b-8b4d-f7ed1d21e064
15 resourceVersion: "5442036"
16 uid: 9c15873d-1ffb-4a18-b063-4a2e55328d01
17spec:
18 clusterName: cce-covdy1t9
19 nodeName: 192.168.96.52
20 nodeProvider: baiducloud
21 paused: false
22 reconcileSteps:
23 - CordonNode
24 - DrainNode
25 - RebootNode
26status:
27 healthy: true
28 message: Check step time intervals, latest step is RebootNode, the time internal
29 is left 885 second, please wait
30 reconcileSteps:
31 CordonNode:
32 finish: true
33 finishedTime: "2023-03-30T01:35:00Z"
34 retryCount: 1
35 startTime: "2023-03-30T01:35:00Z"
36 successful: true
37 DrainNode:
38 finish: true
39 finishedTime: "2023-03-30T01:35:45Z"
40 retryCount: 1
41 startTime: "2023-03-30T01:35:45Z"
42 successful: true
43 RebootNode:
44 costSeconds: 27
45 finish: true
46 finishedTime: "2023-03-30T01:36:41Z"
47 retryCount: 1
48 startTime: "2023-03-30T01:36:14Z"
49 successful: true如上查询的到的 RemedyMachine,
-
spec.reconcileSteps:保存针对该节点具体的需要执行的自愈步骤,分别为:CordonNode: 冻结节点,防止新的 Pod 被调度到该节点;DrainNode:执行节点排水,驱逐该节点上 Pod,目前不会驱逐由 DaemonSet 管理的 Pod;RebootNode:重启节点,重启该 Worker 节点所对应的 BCC 节点,暂不支持重启 BBC 节点;
-
status: 保存针对该节点的故障自愈状态healthy:表示目前该节点是否健康;-
reconcileSteps:针对该节点的各维修步骤的执行结果,每个元素包含:finish: 该步骤是否执行结束successful: 该步骤是否执行成功retryCount:该步骤的重试次数startTime:该步骤的开始执行时间finishedTime:该步骤的结束时间
查看节点故障维修事件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 节点管理 > Worker, 进入节点管理界面。
- 点击 节点名称 查看节点详情:
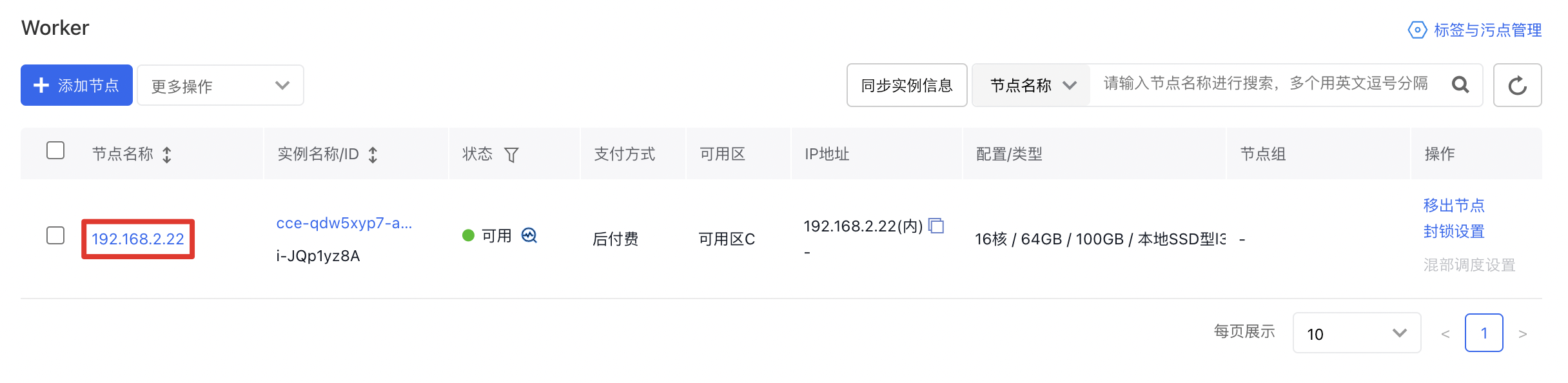
- 点击 事件,可进入事件中心查看该节点相关的事件:

版本记录
| 版本号 | 适配集群版本 | 更新时间 | 更新内容 | 影响 |
|---|---|---|---|---|
| 0.1.0 | CCE v1.18 及以上 | 2023.04.12 | 首次上线 | - |
| 0.1.5 | CCE v1.18 及以上 | 2024.01.18 | 新增三个自愈条件:CPUUnhealthyExt、MemoryUnhealthyExt 和 MainboardUnhealthyExt | - |
| 0.1.6 | CCE v1.18 及以上 | 2024.01.24 | 新增两个自愈操作:重启 Kubelet 和 重启容器运行时 | - |
评价此篇文章