
新建AITraining任务
更新时间:2025-06-06
您可以新建一个AITraining类型的任务。AITrainingJob是一种优化的AI训练作业任务,在算力浪费、资源供给、容错与弹性调度上进行了优化改进。
前提条件
- 您已成功安装CCE AI Job Scheduler和CCE Deep Learning Frameworks Operator组件,否则云原生AI功能将无法使用。
- 若您是子用户,队列关联的用户中有您才能使用该队列新建任务。
- 安装组件CCE Deep Learning Frameworks Operator时,系统安装了Pytorch深度学习框架。
操作步骤
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击云原生AI > 任务管理。
- 在任务管理页面单击新建任务。
- 在新建任务页面中,完成任务基本信息配置:
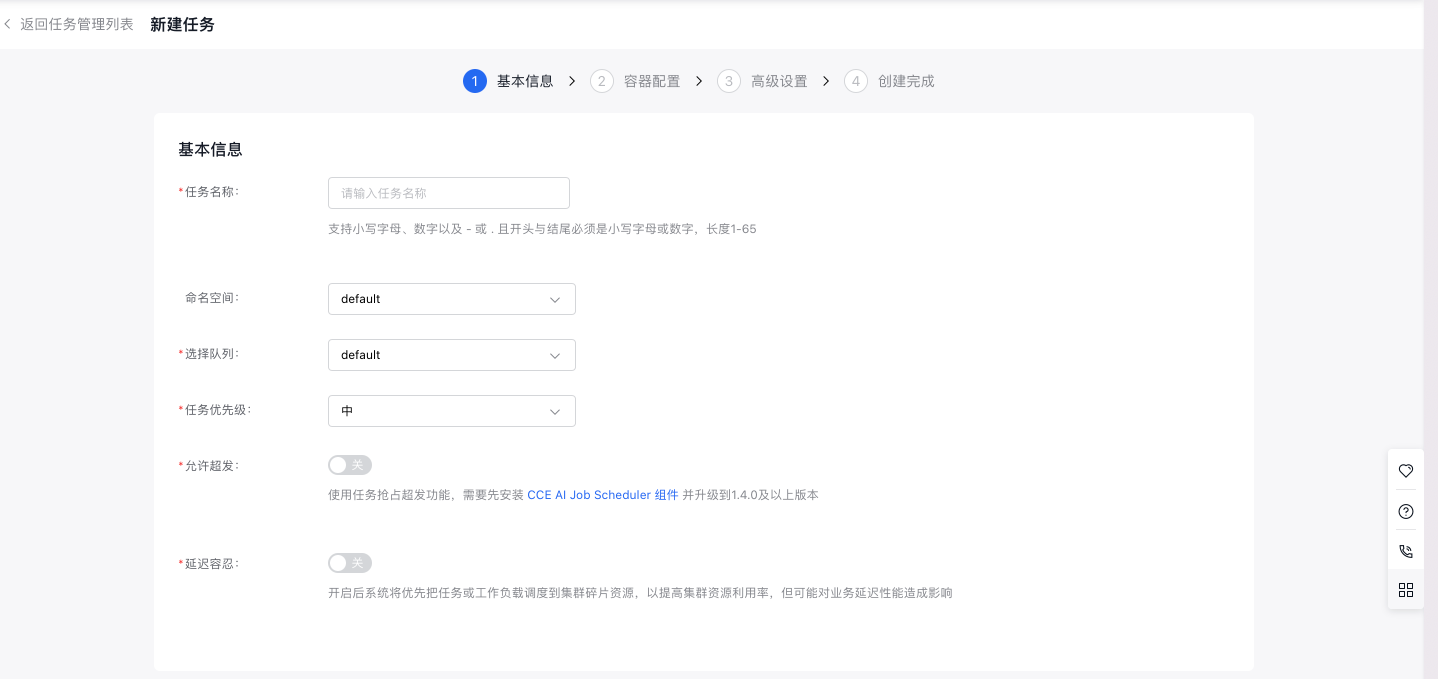
- 任务名称:自定义任务名称,支持大小写字母、数字、以及-_ /.特殊字符,必须以中文或字母开头,长度 1-65。
- 命名空间:选择新建任务所在的命名空间。
- 选择队列:选择新建任务关联的队列。
- 任务优先级:选择任务对应的任务优先级。
- 允许超发:允许超发将使用任务抢占超发功能,需要先安装CCE AI Job Scheduler组件并升级到1.4.0及以上版本。
- 延迟容忍:系统将优先把任务或工作负载调度到集群碎片资源,以提高集群资源利用率,但可能对业务延迟行能造成影响。
- 完成代码基本信息配置:
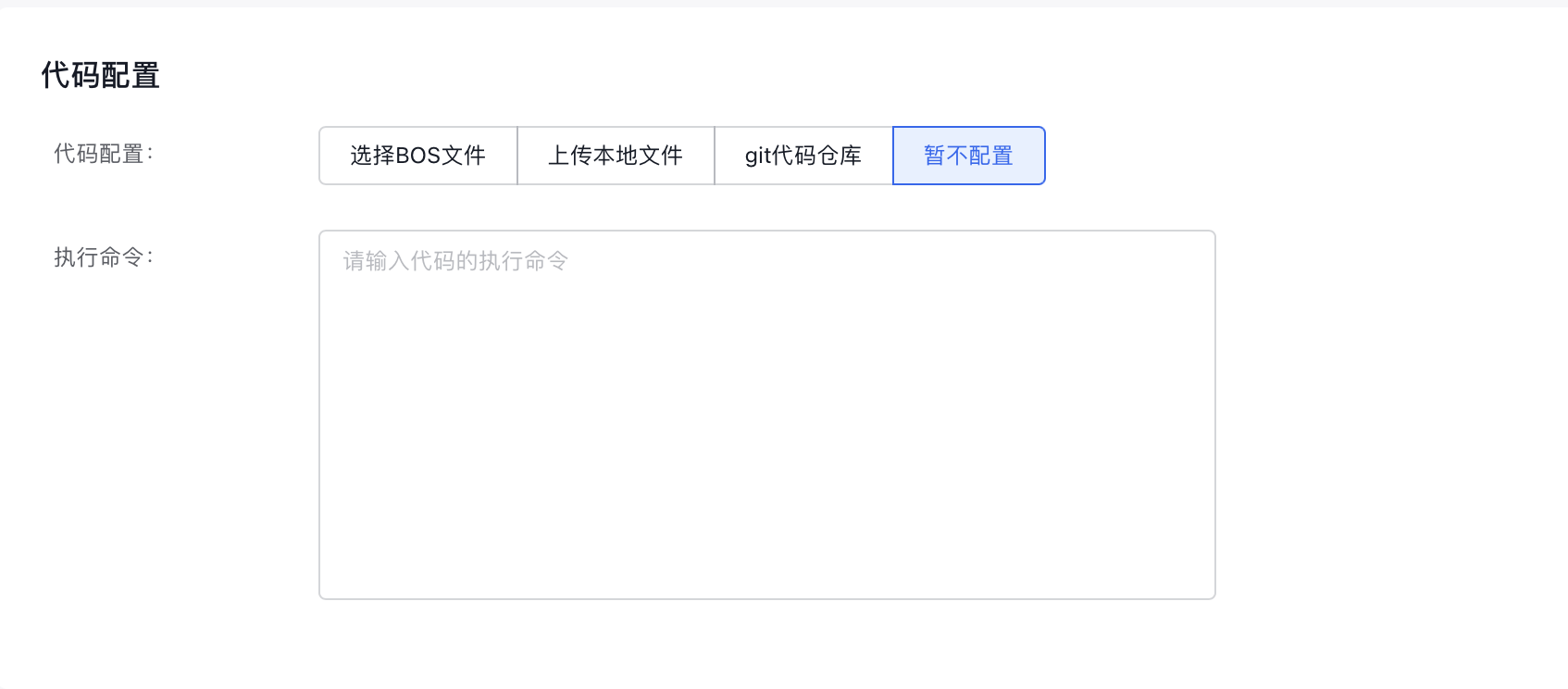
- 代码配置类型:指定代码配置方式,目前支持“BOS文件”、“本地文件上传”与“暂不配置”。
-
执行命令:指定代码的执行命令。
9.完成数据相关信息配置:

-
设置数据源:当前支持数据集、持久卷声明、选择临时路径和选择主机路径。选择数据集时列出所有可用的数据集,选择后会同时选择与数据集同名的持久卷声明;使用持久卷声明时直接选择即可。
10.点击“下一步”,进入容器相关配置。
11.完成任务类型相关信息配置:
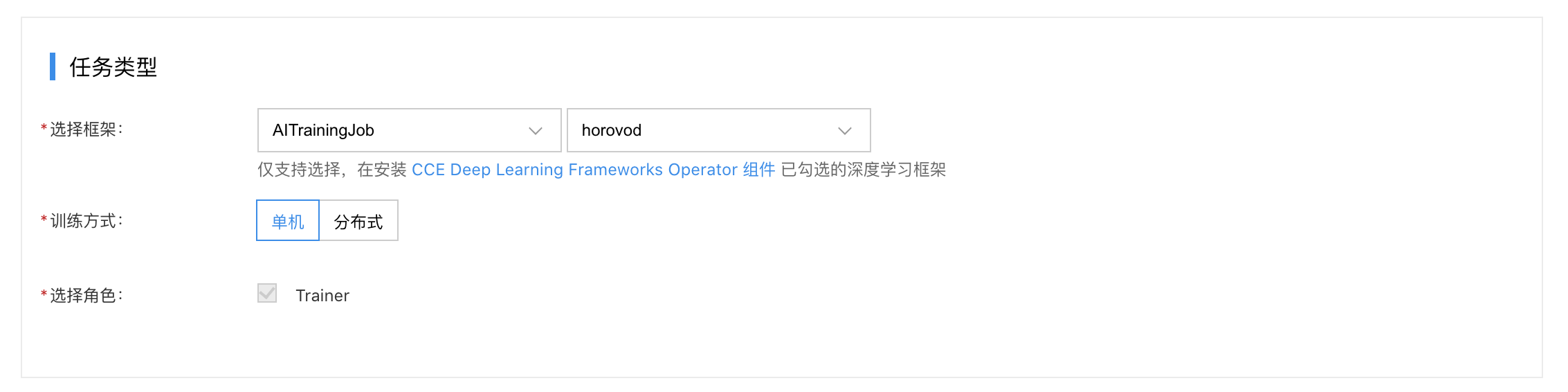
- 选择框架:选择“ AITrainingJob ”,同时指定训练机制,目前可以选择“horovod”或“paddle”。
- 训练方式:指定训练方式为“单机”或“分布式”。
-
选择角色:训练方式为“单机”时,只能选择“Trainer”;训练方式为“分布式”时,可额外选择“Launcher”,同时需要指定pod的弹性范围。
12.完成容器组相关信息配置,可以根据需要同时进行高级设置。
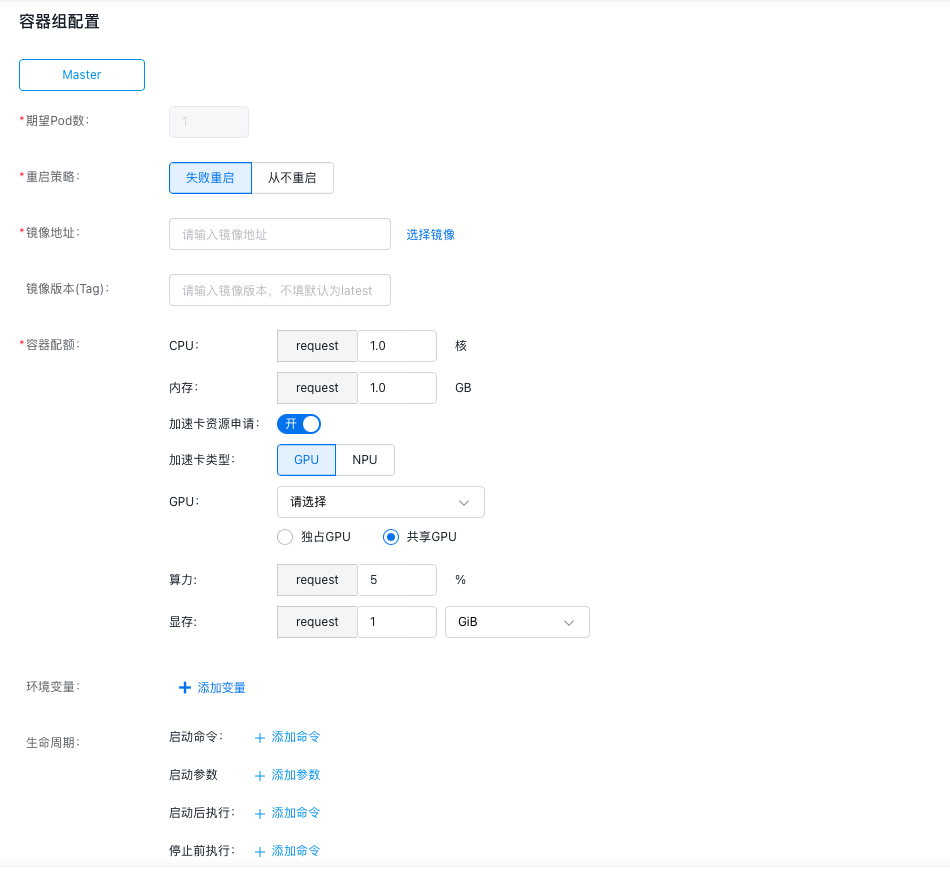
- 期望Pod数:指定容器组的Pod数目。
- 重启策略:指定容器组的重启策略,可选择的策略有“失败重启”或“从不重启”。
- 镜像地址:指定容器的镜像拉取地址,也可以直接点击“选择镜像”,选择需要使用的镜像。
- 镜像版本:指定镜像的版本,若不指定默认拉取latest版。
-
容器配额:指定容器的CPU、内存、GPU资源相关信息。
13.完成任务高级信息相关配置。
- 最大训练时长:指定允许的最大训练时长,若不指定,则为不限制时间。
- 私有仓库凭证:若需要使用私有镜像仓库,请在此处添加对应镜像仓库的访问凭证。
- Tensorboard:若需要任务可视化时,可开启Tensorboard功能,开启后需要指定“服务类型”与“ 训练日志读取路径”。
- K8S标签:指定任务对应的K8S Label。
- 注释:指定任务对应的Annotation。
- 点击“完成”按钮,完成任务的新建。
Yaml创建任务示例
Plain Text
1apiVersion: kongming.cce.baiudbce.com/v1
2kind: AITrainingJob
3metadata:
4 name: job-horovod-test
5 namespace: default
6spec:
7 # 任务结束时,pod的清理策略,All表示所有pod,none表示不清理
8 cleanPodPolicy: All
9 # 完成策略,All表示所有pod完成即任务完成,Any表示任何pod完成即任务完成
10 completePolicy: Any
11 # 失败策略,All表示所有pod失败即任务失败,Any表示任何pod完成即任务完成
12 failPolicy: Any
13 # 支持horovod与paddle框架
14 frameworkType: horovod
15 # 弹性选项,true表示开启弹性,false不开启,开启时需开启trainer容器的容错选项
16 faultTolerant: true
17 plugin:
18 ssh:
19 - ""
20 discovery:
21 - ""
22 priority: normal
23 replicaSpecs:
24 launcher:
25 completePolicy: Any
26 failPolicy: Any
27 maxReplicas: 1
28 minReplicas: 1
29 replicaType: master
30 replicas: 1
31 restartLimit: 100
32 restartPolicy: OnNodeFailWithExitCode
33 restartTimeLimit: 60
34 restartTimeout: 864000
35 template:
36 metadata:
37 creationTimestamp: null
38 spec:
39 initContainers:
40 - args:
41 - --barrier_roles=trainer
42 - --incluster
43 - --name=$(TRAININGJOB_NAME)
44 - --namespace=$(TRAININGJOB_NAMESPACE)
45 image: registry.baidubce.com/cce-plugin-dev/jobbarrier:v0.9
46 imagePullPolicy: IfNotPresent
47 name: job-barrier
48 resources:
49 limits:
50 cpu: "1"
51 memory: 1Gi
52 requests:
53 cpu: "1"
54 memory: 1Gi
55 restartPolicy: Never
56 schedulerName: volcano
57 terminationMessagePath: /dev/termination-log
58 terminationMessagePolicy: File
59 securityContext: {}
60 containers:
61 - command:
62 - /bin/bash
63 - -c
64 - horovodrun -np 3 --min-np=1 --max-np=5 --verbose --log-level=DEBUG --host-discovery-script /etc/edl/discover_hosts.sh python /horovod/examples/elastic/pytorch/pytorch_synthetic_benchmark_elastic.py
65 env:
66 image: registry.baidubce.com/cce-plugin-dev/horovod:v0.1.0
67 imagePullPolicy: Always
68 name: aitj-0
69 resources:
70 securityContext:
71 capabilities:
72 add:
73 - SYS_ADMIN
74 volumeMounts:
75 - mountPath: /dev/shm
76 name: cache-volume
77 dnsPolicy: ClusterFirstWithHostNet
78 terminationGracePeriodSeconds: 30
79 volumes:
80 - emptyDir:
81 medium: Memory
82 sizeLimit: 1449Gi
83 name: cache-volume
84 trainer:
85 completePolicy: None
86 failPolicy: None
87 # 容错配置,控制器将会以下面的配置作为容错判断条件进行容错
88 faultTolerantPolicy:
89 # 程序退出码
90 - exitCodes: 129,10001,127,137,143,129
91 restartPolicy: ExitCode
92 restartScope: Pod
93 # 集群异常事件
94 - exceptionalEvent: "nodeNotReady,PodForceDeleted"
95 restartPolicy: OnNodeFail
96 restartScope: Pod
97 # 开启弹性的最大副本数
98 maxReplicas: 5
99 # 开启弹性的最小副本数
100 minReplicas: 1
101 replicaType: worker
102 replicas: 3
103 restartLimit: 100
104 restartPolicy: OnNodeFailWithExitCode
105 restartTimeLimit: 60
106 restartTimeout: 864000
107 template:
108 metadata:
109 creationTimestamp: null
110 spec:
111 containers:
112 - command:
113 - /bin/bash
114 - -c
115 - /usr/sbin/sshd && sleep 40000
116 image: registry.baidubce.com/cce-plugin-dev/horovod:v0.1.0
117 imagePullPolicy: Always
118 name: aitj-0
119 resources:
120 # limit与request需保持一致
121 limits:
122 baidu/gpu_p40_8: "1"
123 requests:
124 baidu/gpu_p40_8: "1"
125 securityContext:
126 capabilities:
127 add:
128 - SYS_ADMIN
129 volumeMounts:
130 - mountPath: /dev/shm
131 name: cache-volume
132 dnsPolicy: ClusterFirstWithHostNet
133 terminationGracePeriodSeconds: 300
134 volumes:
135 - emptyDir:
136 medium: Memory
137 sizeLimit: 1449Gi
138 name: cache-volume
139 schedulerName: volcano评价此篇文章