
视图命令行场景示例
概述
本文档介绍使用 kubectl 与 cce-volcano-cli 排查 CCE AI Job Scheduler 调度异常的方法。一般的问题定位流程可以分为五个阶段:问题发现 => 数据导出 => 关键错误提取 => 视图分析 => 问题处理
本文档覆盖以下两类典型场景:
- 资源超配额
- 亲和性、污点、GPU 资源不足
前提条件
- 已登录百度智能云控制台,并可进入 容器引擎 CCE -> 集群管理 -> 集群列表 查看目标集群信息。
- 已在可访问目标集群的环境中配置
kubectl与cce-volcano-cli,并准备可用的kubeconfig。 - 已确认待排查的训练作业名称、关联 Pod 名称,以及导出的快照文件与日志文件存放位置。## 场景 1:资源超配额
导航路径:容器引擎 CCE -> 集群管理 -> 集群列表
-
问题发现:
PyTorchJob没有进入Running状态,对应的 Pod 长时间处于Pending。执行命令
Bash1kubectl get pytorchjob 2kubectl get pod执行结果
Text1训练任务状态:Created 2关联 Pod 状态:Pending -
数据导出: 调整日志级别,导出调度快照与日志文件,完成后恢复日志级别。
执行命令
Bash1cce-volcano-cli log -v 4 2cce-volcano-cli dump -l <日志行数> 3cce-volcano-cli log -v 3 -k <kubeconfig 文件>执行结果
Text1日志级别已调整为 4 2快照文件导出成功 3日志文件导出成功 4日志级别已恢复为 3 -
关键错误提取: 通过 Job 日志提取关键错误;若日志中出现
ExceedQueueResource,说明需要继续分析队列配额分配情况。执行命令
Bash1cce-volcano-cli log job -f <日志文件> -j <训练任务名称>执行结果
Text1关键错误:ExceedQueueResource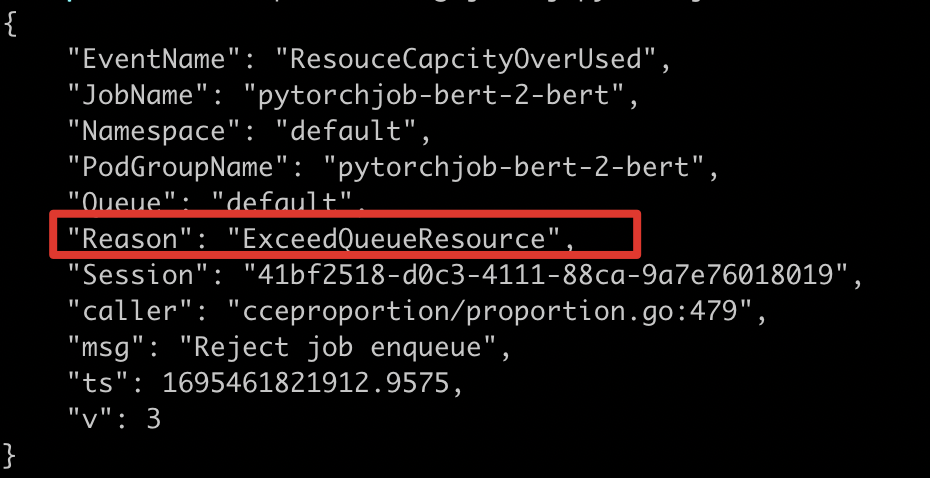
得到配额不足的错误信息后,可以使用 cce-volcano-cli queue 命令对队列配额进行分析,常见情况如下。
case 1:队列配额不足
-
使用快照文件查看队列资源分配情况,重点检查目标 GPU 资源类型的总量、已分配量与排队量。
执行命令
Bash1cce-volcano-cli queue -f <快照文件>分析结论
当目标 GPU 资源类型的已分配量与排队量之和超过总量时,说明当前队列配额不足,任务会继续处于
Pending状态。
case 2:混合卡调度
-
对于混合申请的场景,使用队列视图重点关注
totalGPU字段,用于统计不同 GPU 资源名折算后的实际剩余卡数。执行命令
Bash1cce-volcano-cli queue -f <快照文件>分析结论
若
totalGPU为负值,说明从总卡量角度看队列已经超配。此时需要结合baidu.com/a800_80g_cgpu与nvidia.com/gpu的已分配量、排队量综合判断是否存在混合卡调度下的队列资源超配额问题。
case 3:PodGroup 残留
-
查看队列视图,重点关注
inqueue状态资源是否异常堆积。执行命令
Bash1cce-volcano-cli queue -f <快照文件>分析结论
若
inqueue状态资源较多,但实际仍有空闲 GPU 未被使用,则通常说明存在残留PodGroup或异常 Job 持续占用队列配额。
-
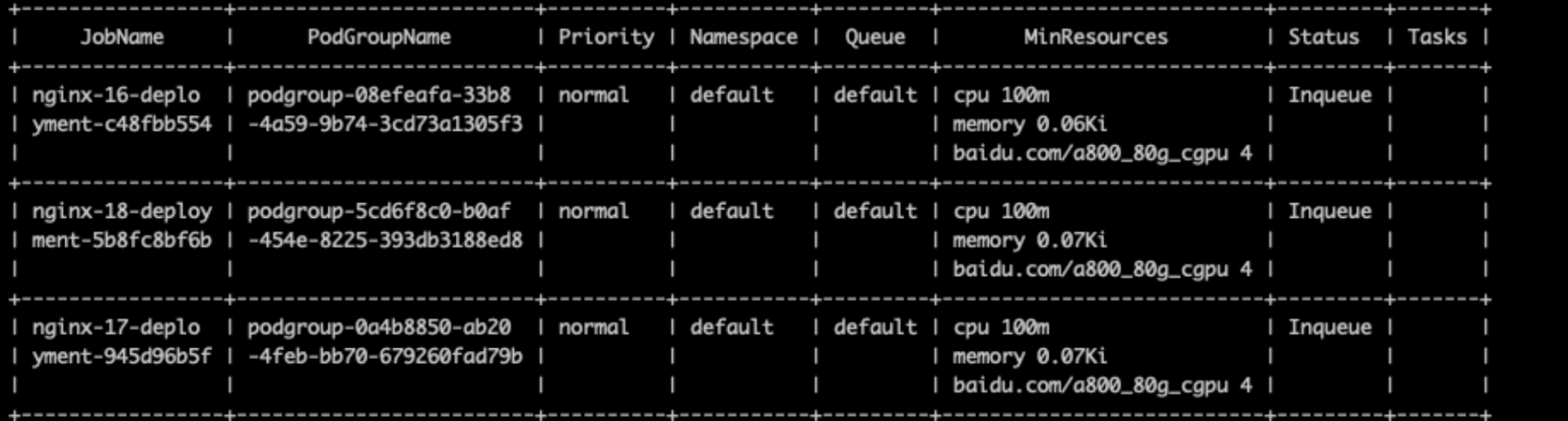
使用 Job 视图查看
inqueue状态的 Job 列表,并筛选异常 Job。注意: 清理异常 Job 或残留
PodGroup前,请先确认该任务不再使用,避免误删仍需保留的作业。执行命令
Bash1cce-volcano-cli job -f <快照文件> -a 2cce-volcano-cli job -f <快照文件> -t分析结论
-a用于查看全量 Job 视图,-t用于快速筛选疑似残留的异常 Job。确认后清理对应异常 Job,可释放被占用的队列配额。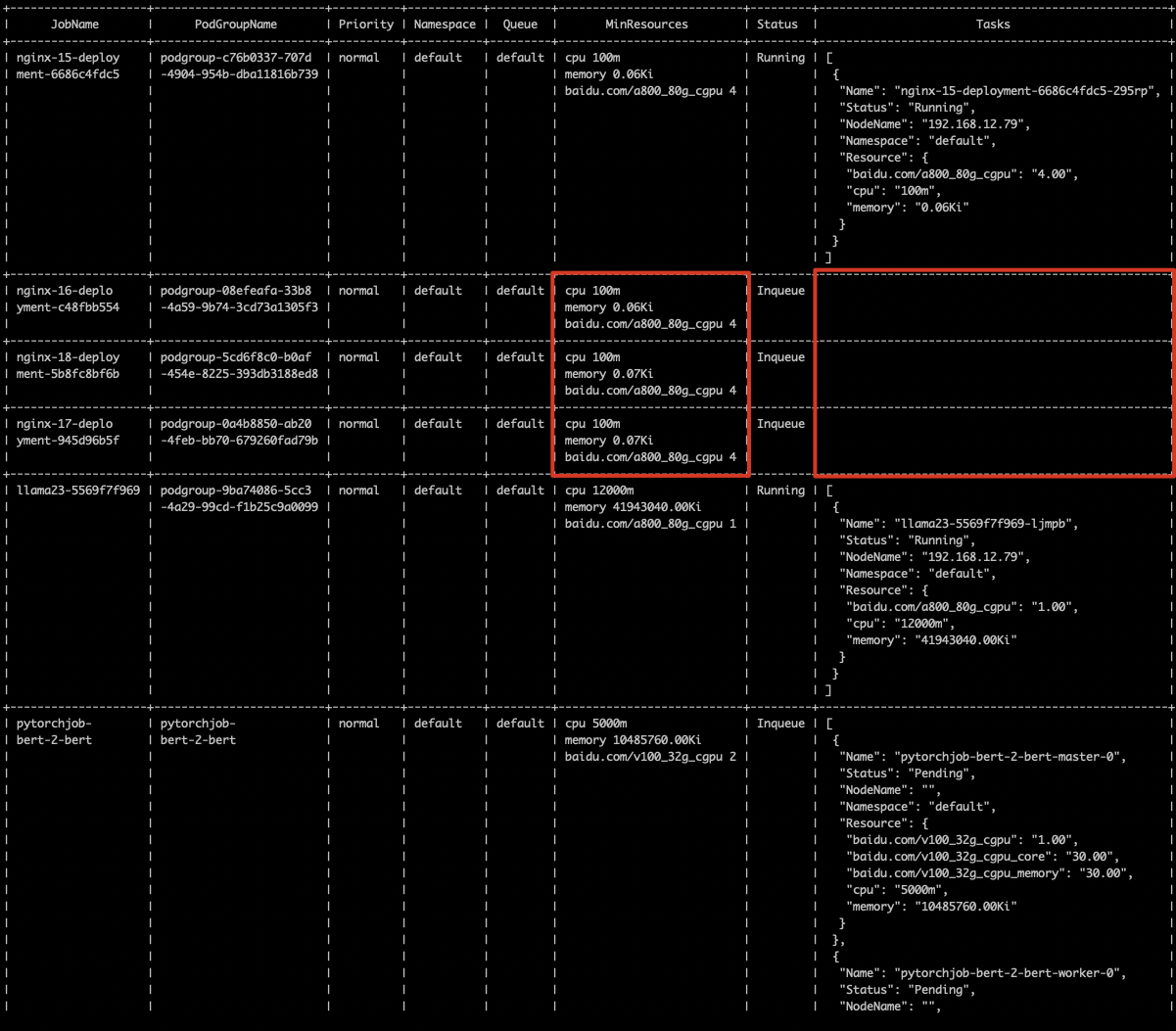
场景 2:亲和性、污点、GPU 资源不足
导航路径:容器引擎 CCE -> 集群管理 -> 集群列表
-
问题发现: Job 一直是
Created状态,对应 Pod 处于Pending。执行命令
Bash1kubectl get pytorchjob 2kubectl get pod执行结果
Text1训练任务状态:Created 2关联 Pod 状态:Pending -
关键错误提取: 通过 Job 日志提取关键错误;若出现
GangUnschedulable,说明当前 Job 不满足 gang 调度,需要继续查看 Pod 调度失败原因。执行命令
Bash1cce-volcano-cli dump -l <日志行数> 2cce-volcano-cli log job -f <日志文件> -j <训练任务名称>执行结果
Text1关键错误:GangUnschedulable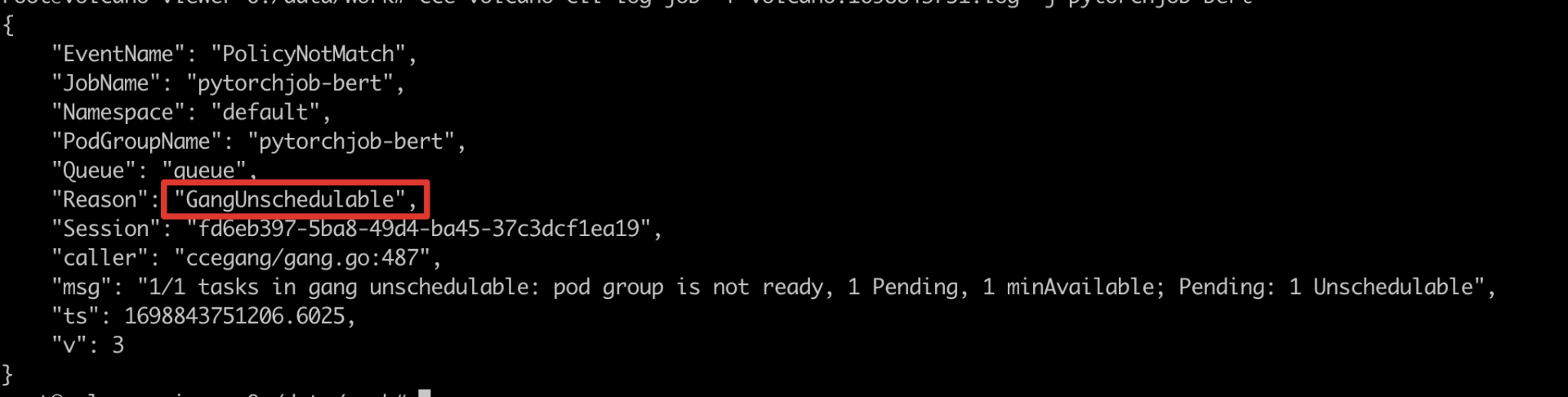
-
通过 Pod 级日志区分封锁节点、普通资源不足和污点导致的调度失败原因。
执行命令
Bash1cce-volcano-cli log pod -f <日志文件> -p <Pod 名称>
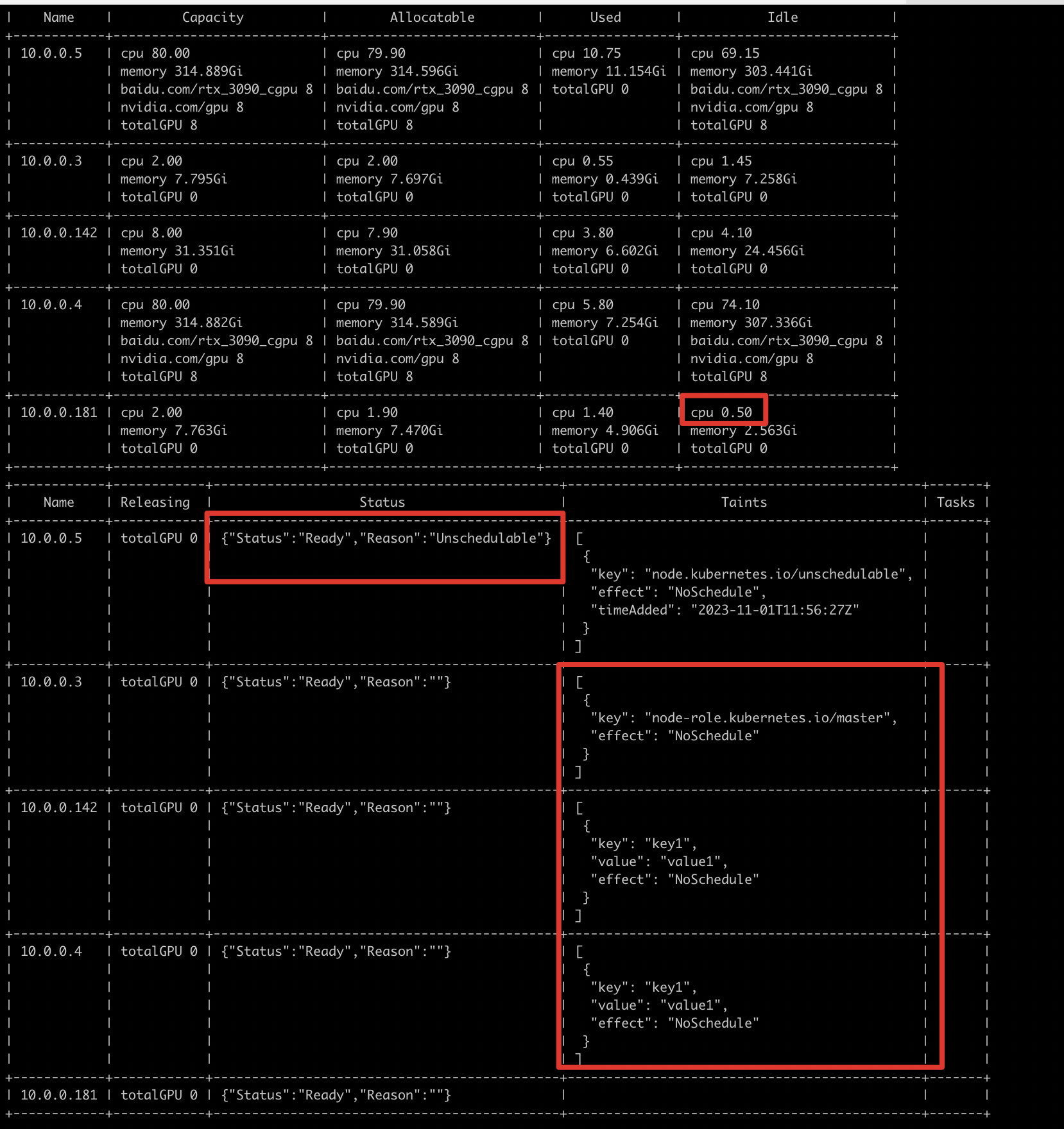
若日志显示部分节点为封锁节点、部分节点 CPU 或 memory 资源不足、部分节点存在污点,则需要继续结合 node 视图判断最终阻塞点。
case 1:亲和性匹配
-
使用
node视图统一分析 CPU、GPU、污点和节点可调度状态。执行命令
Bash1cce-volcano-cli node -f <快照文件>分析结论
- 若某些节点 CPU 剩余量低于 Job 的 CPU 申请量,则这些节点无法承载当前任务。
- 若某些节点具备 GPU 资源但存在污点,则需要确认当前任务是否允许调度到这些节点。
- 若某些节点状态为
Unschedulable,则这些节点不会参与调度。
因此,该场景可判定为典型的亲和性或污点匹配问题;处理时应优先核对 CPU 申请量、节点污点容忍配置,以及节点是否处于可调度状态。
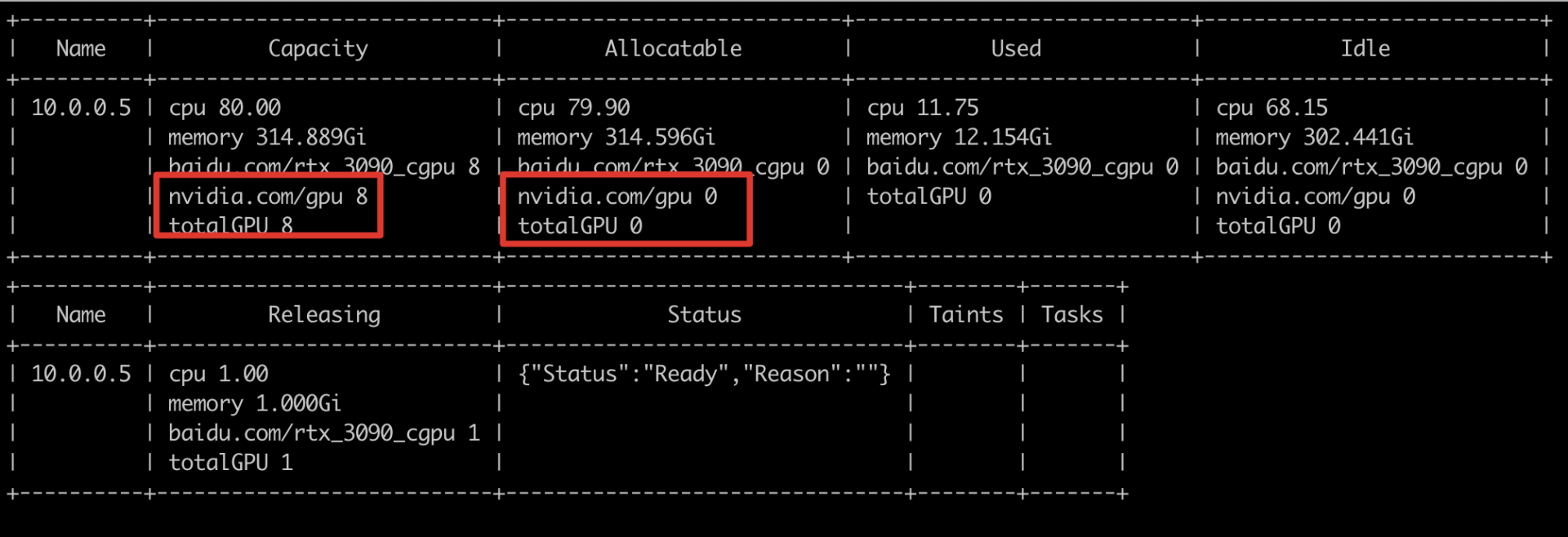
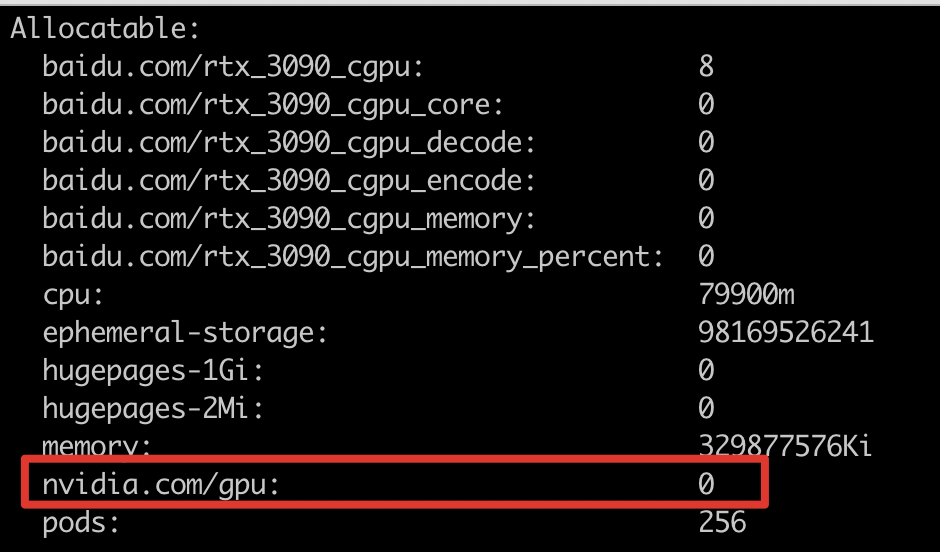
case 2:GPU 掉卡
-
如果节点具备 GPU 资源,且任务申请卡数不超过节点卡数,但仍然无法调度,可先查看
node视图,判断是否存在掉卡。执行命令
评价此篇文章