
GPU虚拟化之隔离性最优型的最佳实践
1. 概述
本文档介绍如何在百度智能云容器引擎 CCE 中使用 GPU 虚拟化的隔离性最优型能力。通过本文档,您可以了解如何选择和配置 GPU 资源,按需使用 GPU 独占或共享模式,并在任务创建、镜像构建、运行验证与节点维护等环节中保证任务的稳定性和安全性。
2. 业务流程

3. 前提条件
在开始使用 GPU 虚拟化的隔离性最优型服务前,请先完成以下准备工作:
- 已注册并登录百度智能云账号,且已创建可用的 CCE 集群。
- 已在目标集群中安装
CCE GPU Manager、CCE Deep Learning Frameworks Operator和CCE AI Job Scheduler组件。 - 已按业务需求完成 GPU 节点的显存共享或 GPU 虚拟化配置。
- 若您需要通过
YAML创建任务或工作负载,请提前获取目标集群凭证,并确保对目标命名空间具备相应的工作负载创建权限。 - 若您是子用户,请先完成所需的 IAM 与 RBAC 授权。
3.1 集群创建
可参考 集群创建 相关文档。
导航路径:产品服务->云原生->容器引擎 CCE->集群管理->集群列表
- 登录百度智能云平台:
- 登录成功后,选择“产品服务>云原生>容器引擎 CCE”,进入“集群管理>集群列表”页面。
- (可选)“集群列表”页面会显示所有已创建的 CCE 集群名称/ID、状态、版本等信息,并且用户可以通过集群名称进行搜索集群的操作。
- (可选)选择区域,请根据实际需求进行选择切换。容器引擎 CCE 服务目前支持华北—北京、华北—保定、华南-广州、华东-苏州、中国香港等区域。
- 点击“创建集群”,进入“选择模板”界面,根据模板介绍结合业务需求选择模板。
- 默认单一区域下集群配额为20个,每个集群内节点配额为200个。
- 如有需求,可以提工单提升配额。
- 点击“确认”,根据集群创建导航并结合业务需求配置。
- 付费及地域
- 基础配置
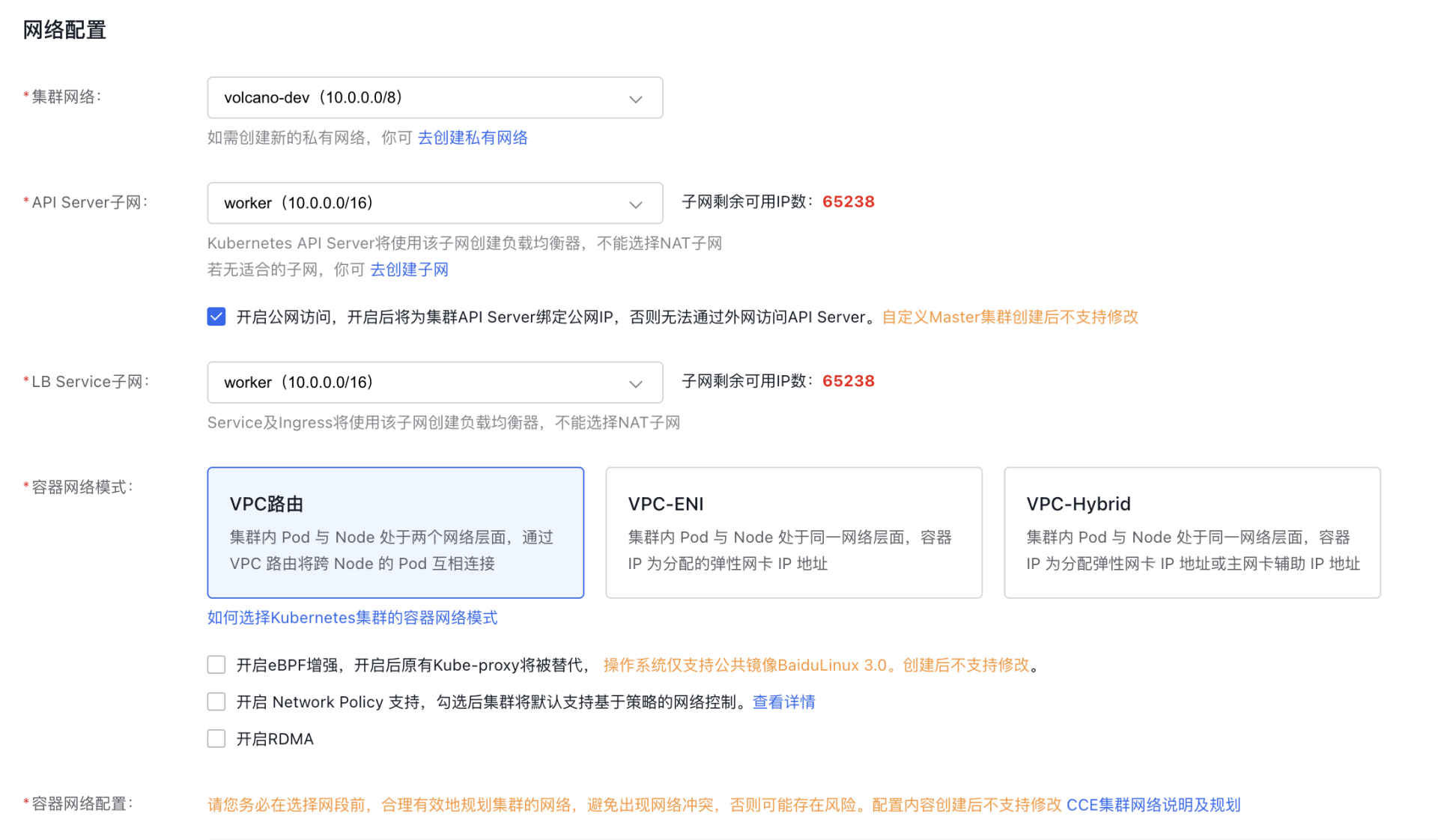
- 网络配置
容器网络为独立的地址空间,须与节点网络、节点子网、其他集群的容器网络相互独立。
- 节点配置
- 用户可以选择“新建节点”。
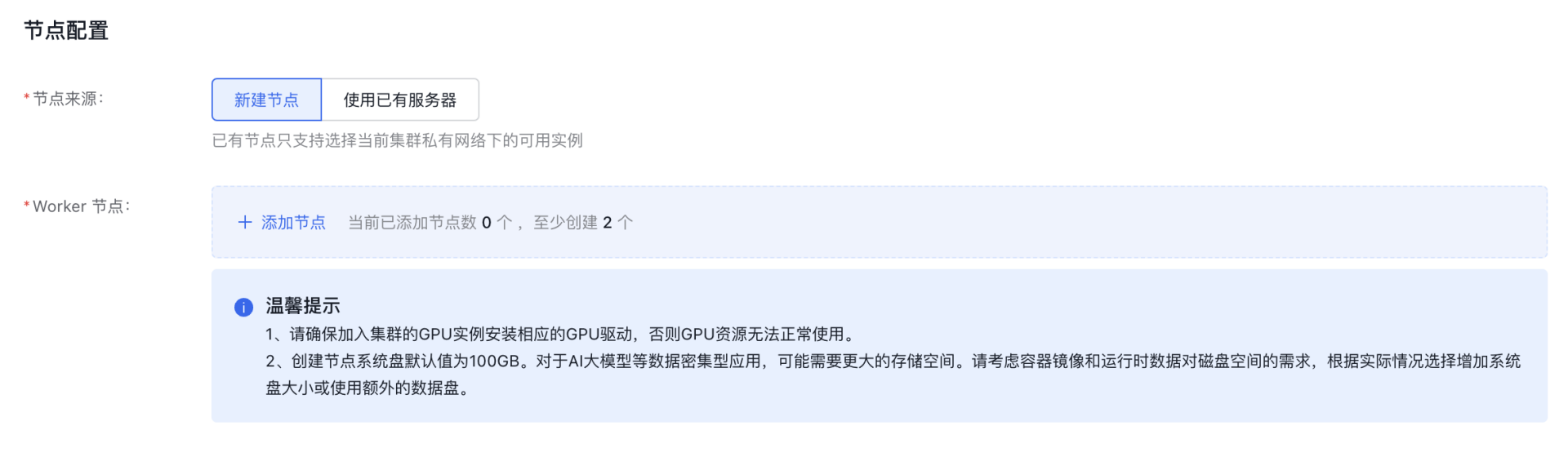
- 选择后点击添加节点,弹出“添加节点”对话框。
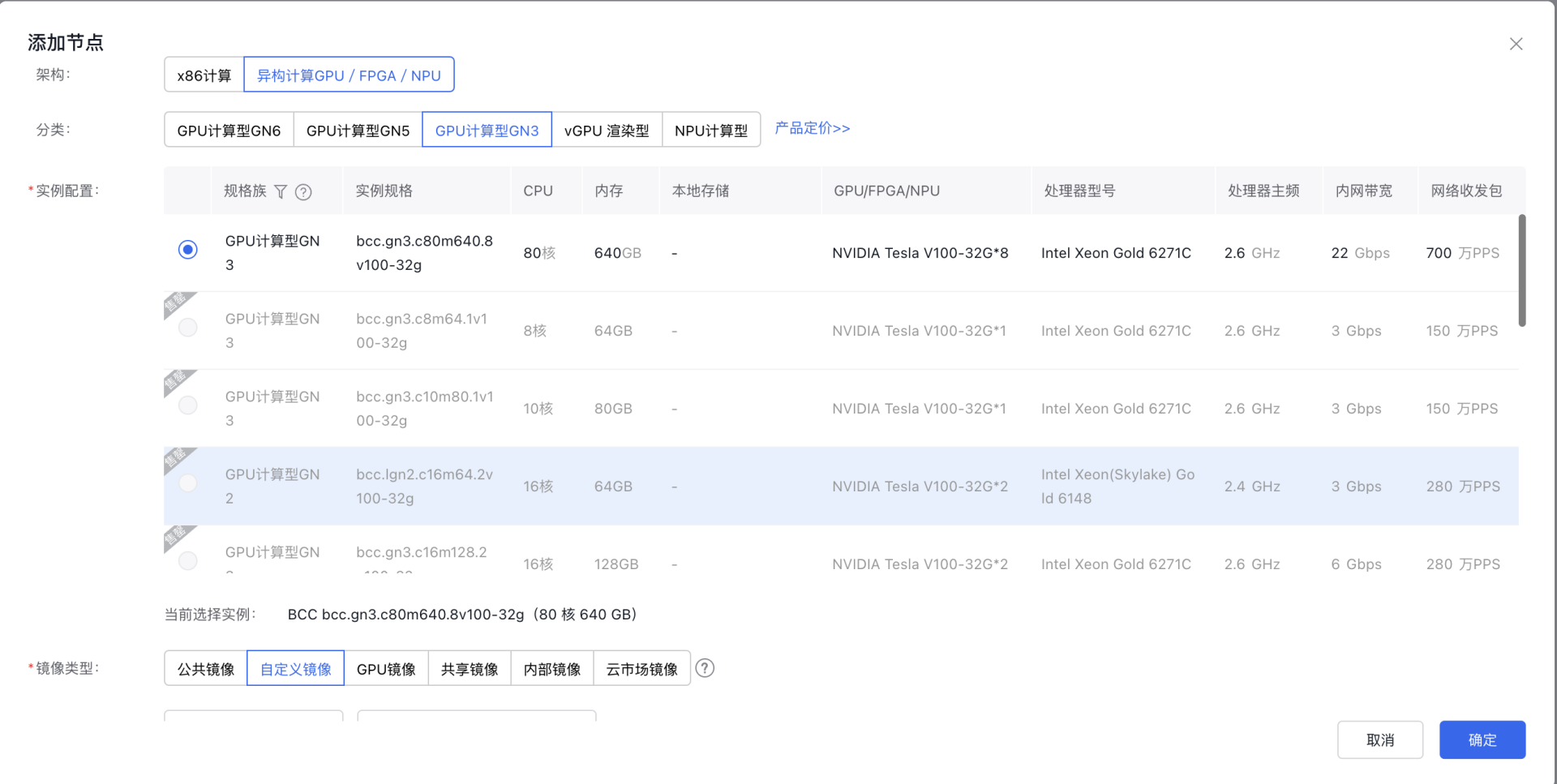
注意:在实例配置部分,若该节点想使用GPU虚拟化功能,配置时请参考隔离性最优型对应的GPU虚拟化适配表。为确保任务能够顺利创建,请根据适配表选择合适的实例,否则创建任务时识别不到不适配的GPU。
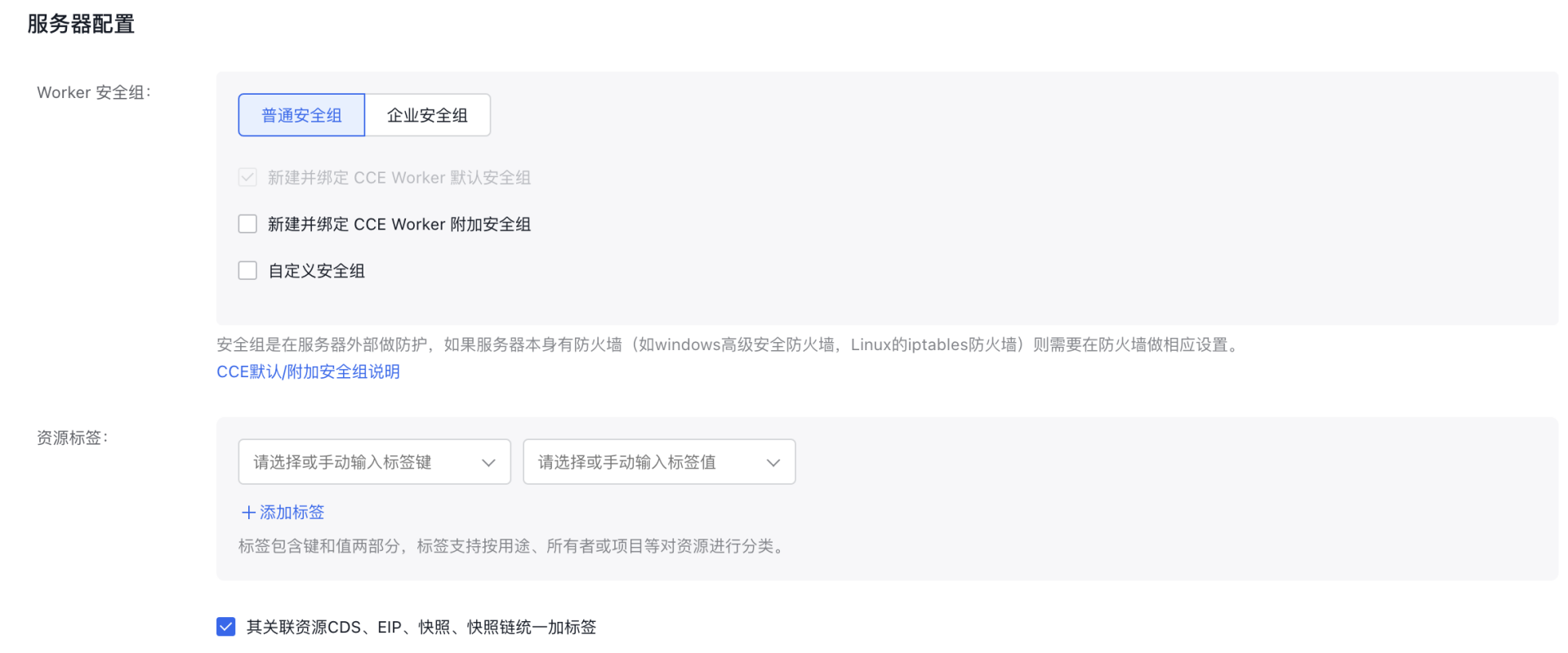
- 服务器配置
3.2 安装必要组件:
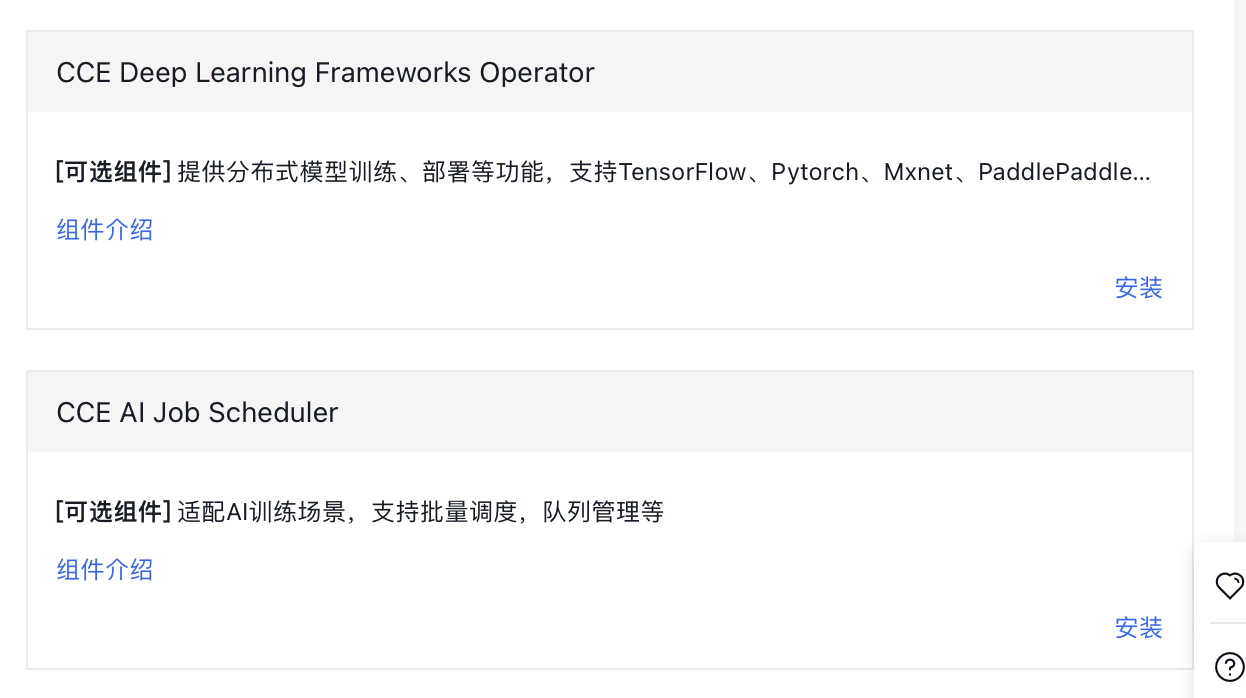
导航路径:产品服务->云原生->容器引擎 CCE->集群管理->集群列表->目标集群->组件管理->云原生 AI
您需要在 【组件管理->云原生 AI】 中安装 CCE GPU Manager、CCE Deep Learning Frameworks Operator 和 CCE AI Job Scheduler 组件。
3.2.1 CCE GPU Manager组件:
组件参数说明:
| 参数 | 可选值 | 必填 | 说明 |
|---|---|---|---|
| 组件类型 | 隔离性最优型 | 是 | 请注意对应的 GPU 虚拟化适配表。 |
| GPU 显存共享单位 | GiB | 是 | GPU 显存切分的最小单位,目前仅支持 GiB。 |
| 精细化调度 | 开启 / 关闭 | 否 | 关闭后,资源上报不区分具体 GPU 型号;开启后,创建队列和任务时均支持选择具体 GPU 型号。 |

3.2.2 CCE Deep Learning Frameworks Operator和CCE AI Job Scheduler 组件
进入组件管理部分安装即可
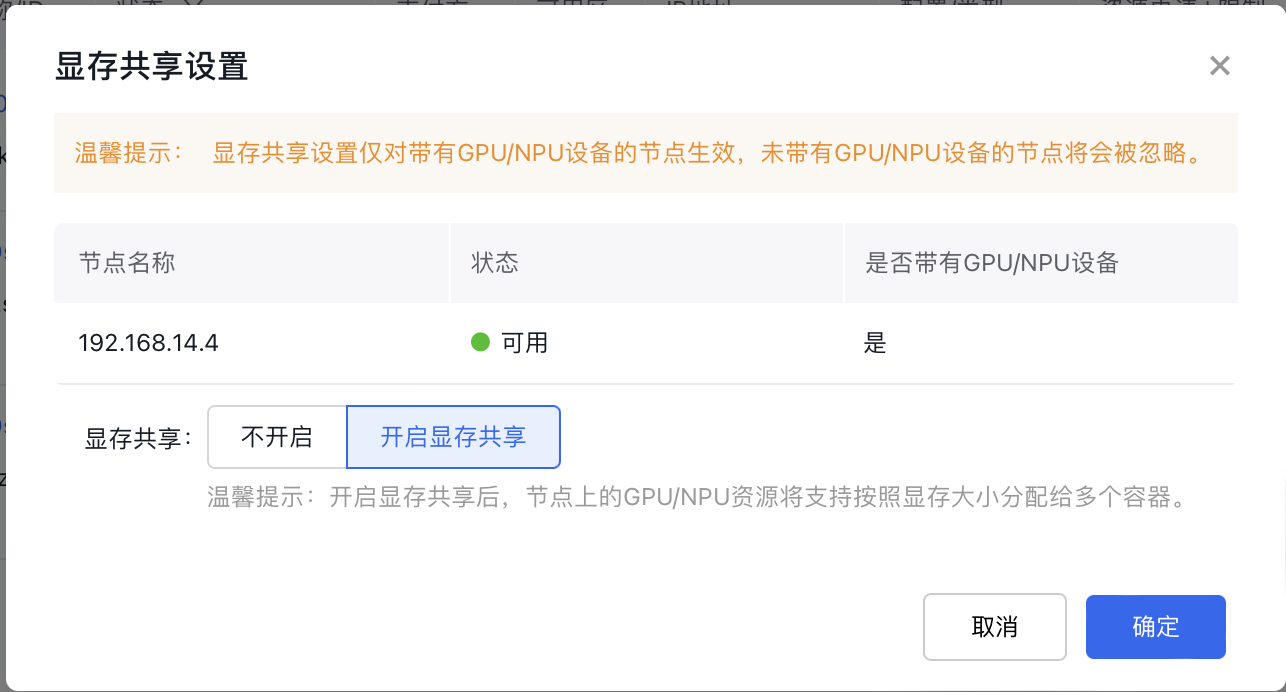
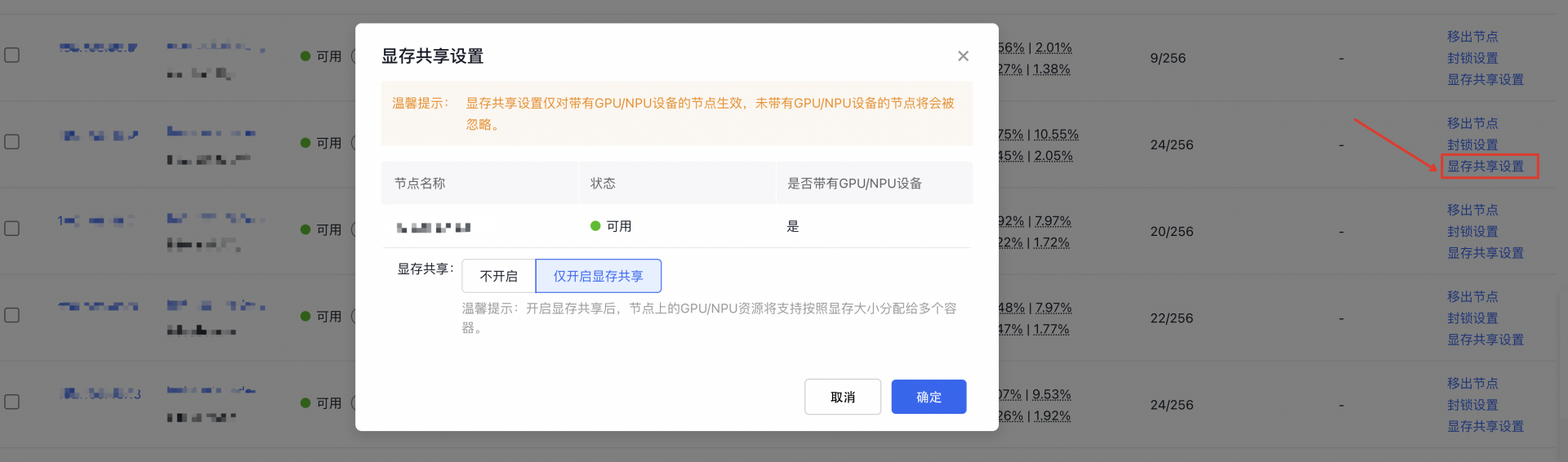
3.3 节点开启显存共享步骤:
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,进入 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 选择页面左侧 节点管理 > Worker ,进入节点列表页面。
- 在节点列表中,选择需要设置显存共享的 GPU 节点,单击 开启显存共享。
- 打开显存共享开关后单击 确定,完成设置显存共享。
3.4 批量打开节点的GPU虚拟化功能
方法一:批量针对已有节点添加虚拟化节点标签
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,进入 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 选择页面左侧 节点管理 > Worker ,进入节点列表页面。
- 点击标签与污点管理进入
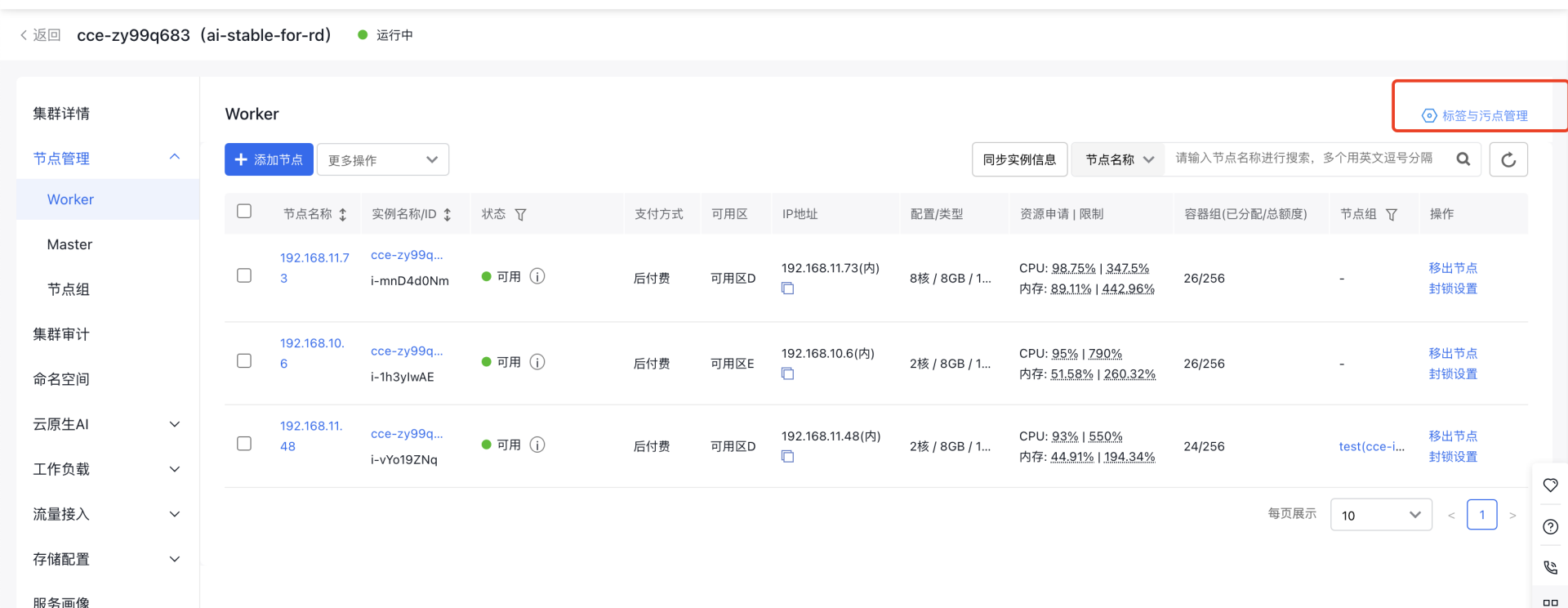
- 点击编辑标签,输入标签键和值,点击确定
1标签键:cce.baidubce.com/gpu-share-device-plugin
2值:enable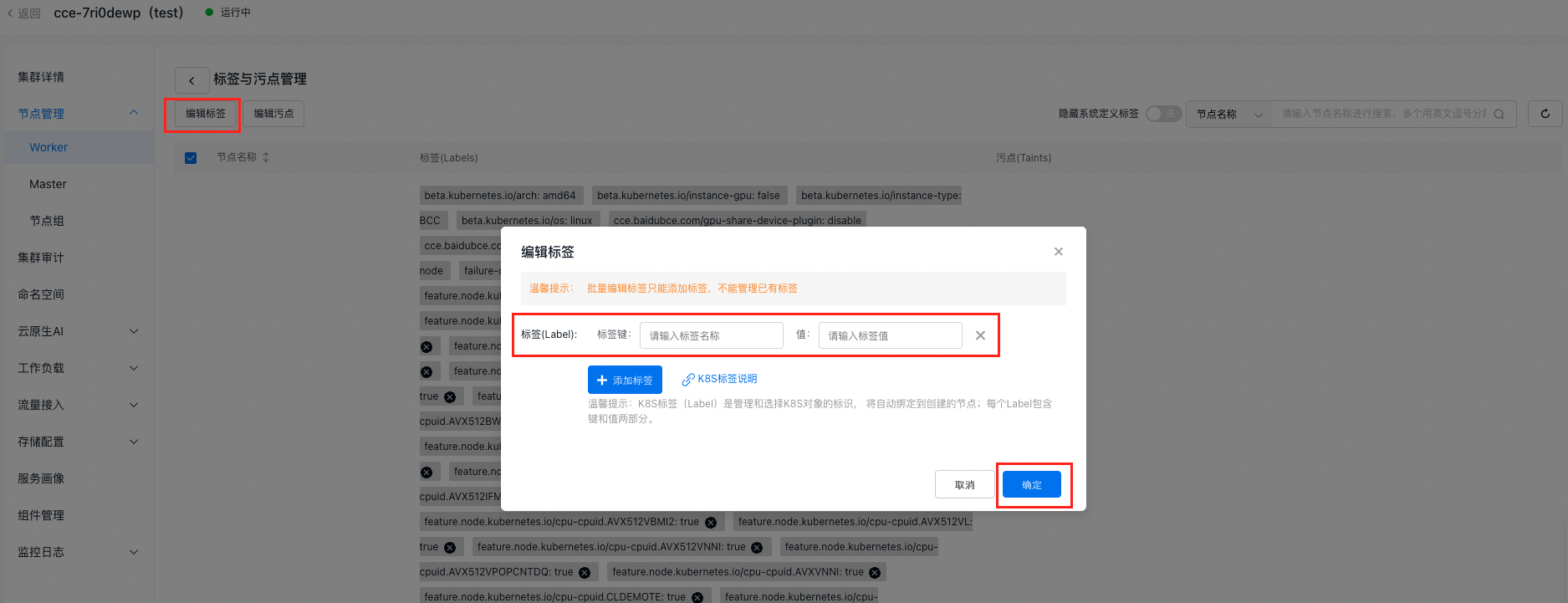
方法二:使用节点组默认添加节点标签
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,进入 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 选择页面左侧 节点管理 > 节点组,进入节点组页面。
- 点击 【创建节点组】。
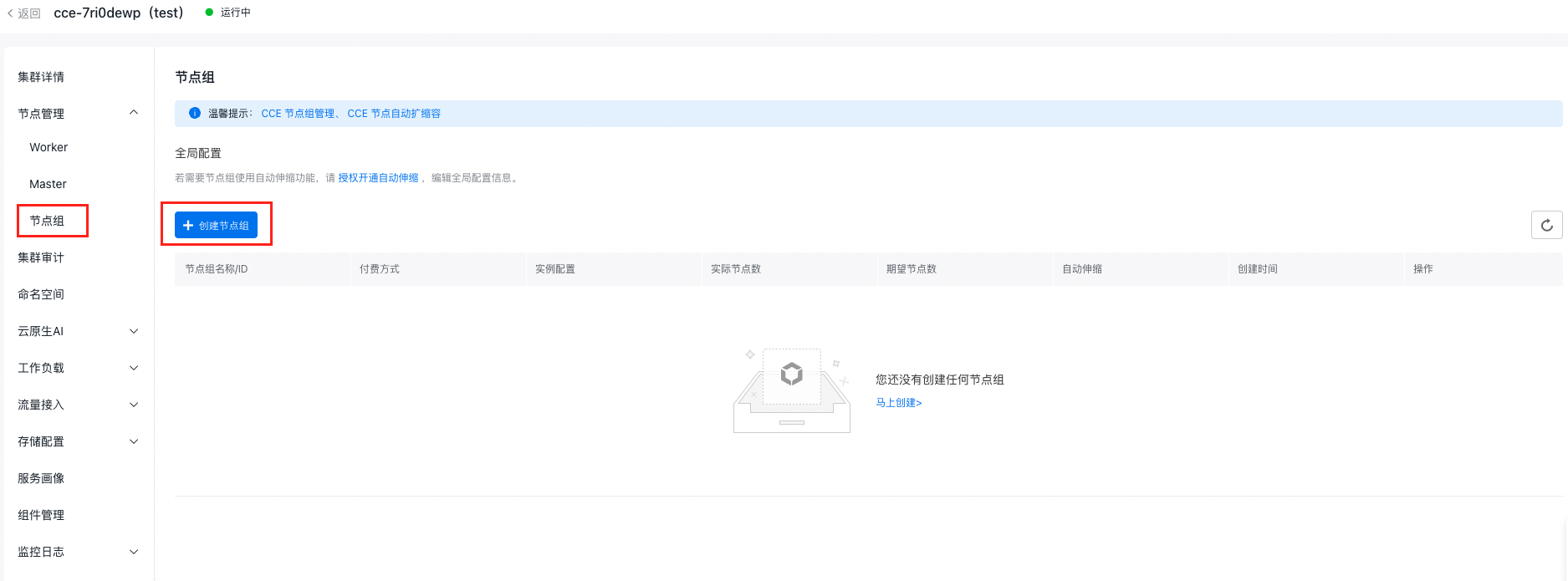
- 填写节点组基本配置。
| 参数 | 必填 | 说明 |
|---|---|---|
| 节点组名称 | 是 | 自定义填写,支持大小写字母、数字、中文以及 - _ / .,必须以字母开头,长度为 1 - 65。 |
| VPC 网络 | 是 | 选择集群所属的 VPC 网络。 |
| 节点配置 | 是 | 配置可用区、节点子网、实例规格等信息。后续扩容节点组将以此配置作为创建节点的模板。创建节点时填写的节点数量即初始设置的期望节点数。 |
| 自动伸缩 | 否 | 启用后,系统会根据节点配置和自动伸缩配置,在符合扩容条件时自动扩容,并自动计算节点费用、生成订单。扩容完成后,可自行查看节点和订单信息。 |
| 高级设置 | 否 | 支持对扩缩容策略、kubelet 数据目录、容器数据目录、部署前执行脚本、部署后执行脚本、自定义 kubelet 参数、封锁节点(cordon)、资源标签、K8S 标签、污点设置(Taints)、注释(Annotations)等参数进行设置。 |
配置 K8S 标签 时,请填写以下内容:
1标签键:cce.baidubce.com/gpu-share-device-plugin
2值:enable
3.5 获得RBAC授权
导航路径:请根据 配置 IAM 预置权限策略 与 配置预置 RBAC 权限策略 的指引进入对应授权页面。
注意: 若您是子用户,需先获得主账号或具有管理员权限的子用户授予的 RBAC 权限后,才能新建任务;若不是子用户,则无需执行本步骤。
- 获得IAM授权。子用户需要先在IAM中至少被授予CCE的只读权限,详细的授权流程请参考配置IAM预置权限策略
- 获得RBAC授权。详细的授权流程请参考配置预置RBAC权限策略
4. GPU 资源描述
4.1 GPU卡型号和资源名称
正确指定 GPU 卡型号对应的资源名称是使用 GPU虚拟化的隔离性最优型 的关键,在创建任务前,了解GPU资源配置和适配才可以正确的创建任务。若需指定 GPU 卡算力资源或显存资源,请在资源名称后加上“_core”或“_memory”。
以下是常见 GPU 卡型号及其对应的资源名称:
| GPU卡型号 | 资源名称 |
|---|---|
| NVIDIA V100 16GB | baidu.com/v100_16g_cgpu |
| NVIDIA V100 32GB | baidu.com/v100_32g_cgpu |
| NVIDIA T4 | baidu.com/t4_16g_cgpu |
| NVIDIA A100 80GB | baidu.com/a100_80g_cgpu |
| NVIDIA A100 40GB | baidu.com/a100_40g_cgpu |
| NVIDIA A800 80GB | baidu.com/a800_80g_cgpu |
| NVIDIA A30 | baidu.com/a30_24g_cgpu |
| NVIDIA A10 | baidu.com/a10_24g_cgpu |
| NVIDIA RTX3090 | baidu.com/rtx_3090_cgpu |
| NVIDIA RTX4090 | baidu.com/rtx_4090_cgpu |
| NVIDIA H800 | baidu.com/h800_80g_cgpu |
| NVIDIA L20 | baidu.com/l20_cgpu |
| NVIDIA H20 96GB | baidu.com/h20_96g_cgpu |
| NVIDIA H20 141GB | baidu.com/h20_141g_cgpu |
| NVIDIA H20z | baidu.com/h20z_141g_cgpu |
4.2 资源描述
| 参数(资源名称) | 类型 | 单位 | 必填 | 说明 |
|---|---|---|---|---|
| baidu.com/xxx_xxx_cgpu | int64 | 1 | 否 | GPU 卡数量。共享场景下请填写 1;单容器多卡场景下表示申请的 GPU 共享卡个数。 |
| baidu.com/xxx_xxx_cgpu_core | int64 | 5% | 否 | GPU 卡算力资源,最小单位为 5%。 |
| baidu.com/xxx_xxx_cgpu_memory | int64 | GiB | 否 | GPU 卡显存资源。 |
| baidu.com/xxx_xxx_cgpu_memory_percent | int64 | 1% | 否 | 按百分比申请 GPU 卡显存,最小单位为 1%。 |
5. 创建任务
用户可通过CCE控制台创建任务/工作负载或者YAML 创建任务/工作负载,可根据您的需求选择不同的方式创建。创建的细节如下文所示。
注意: 共享 GPU 场景下的镜像构建注意事项,请参考第 6 部分。
5.1. 在控制台创建任务
操作步骤(可参考云原生AI任务管理)
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击云原生AI > 任务管理。
- 在任务管理页面单击新建任务。
- 在新建任务页面中,完成任务基本信息配置:
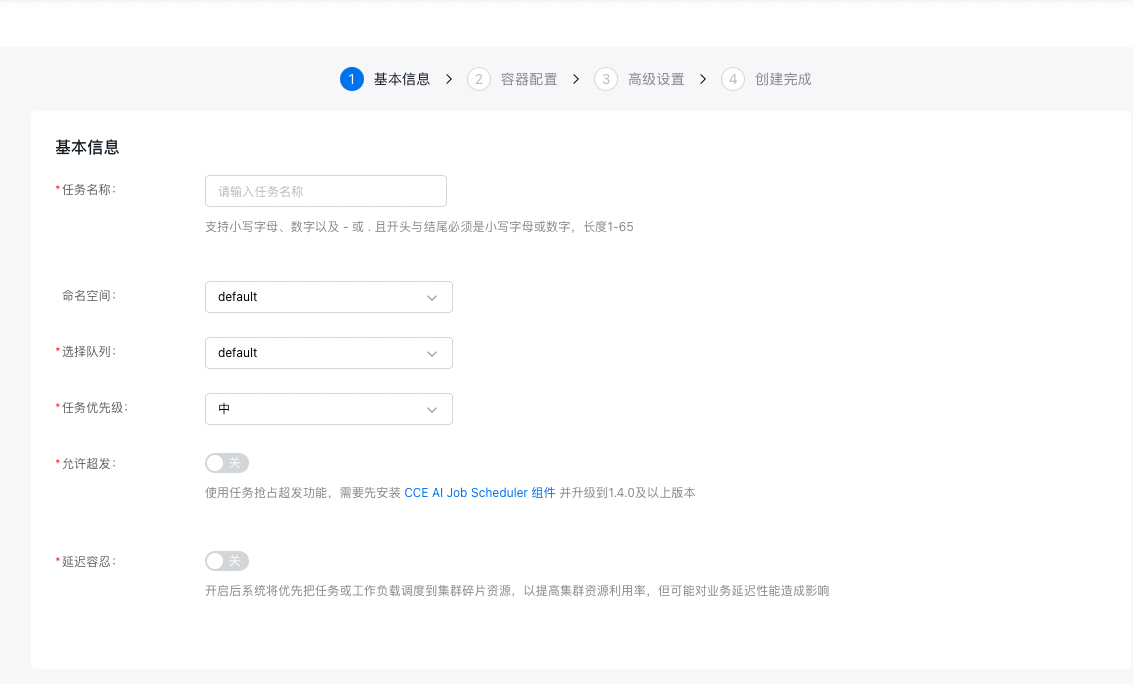
- 配置任务基本信息。
| 参数 | 必填 | 说明 |
|---|---|---|
| 任务名称 | 是 | 自定义任务名称,支持大小写字母、数字以及 - _ / .,必须以中文或字母开头,长度为 1 - 65。 |
| 命名空间 | 是 | 选择新建任务所属的命名空间。 |
| 选择队列 | 是 | 选择新建任务关联的队列。 |
| 任务优先级 | 否 | 选择任务对应的优先级。 |
| 允许超发 | 否 | 开启后可使用任务抢占超发能力,需先安装 CCE AI Job Scheduler 组件并升级到 1.4.0 及以上版本。 |
| 延迟容忍 | 否 | 开启后,系统将优先把该任务或工作负载调度到集群碎片资源。 |
- 配置代码信息。
| 参数 | 必填 | 说明 |
|---|---|---|
| 代码配置类型 | 否 | 指定代码配置方式,目前支持 【BOS 文件】、【本地文件上传】 与 【暂不配置】。 |
| 执行命令 | 否 | 指定代码执行命令。 |
9.完成数据相关信息配置:
-
设置数据源:当前同时支持数据集和持久卷声明。选择数据集时列出所有可用的数据集,选择后会同时选择与数据集同名的持久卷声明;使用持久卷声明时直接选择即可。
10.点击“下一步”,进入容器相关配置。
- 配置任务类型信息。
| 参数 | 必填 | 说明 |
|---|---|---|
| 选择框架 | 是 | 选择 【TensorFlow】。 |
| 训练方式 | 是 | 指定为 【单机】 或 【分布式】。 |
| 选择角色 | 是 | 训练方式为 【单机】 时,仅可选择 【Worker】;训练方式为 【分布式】 时,还可选择 【PS】、【Chief】、【Evaluator】。 |
- 配置容器组信息,必要时可同时完成高级设置。
| 参数 | 必填 | 说明 |
|---|---|---|
| 期望 Pod 数 | 是 | 指定容器组的 Pod 数量。 |
| 重启策略 | 是 | 可选 【失败重启】 或 【从不重启】。 |
| 镜像地址 | 是 | 指定容器镜像拉取地址,也可通过 【选择镜像】 选择所需镜像。共享 GPU 场景下的镜像构建注意事项见第 6 部分。 |
| 镜像版本 | 否 | 指定镜像版本;若不指定,默认拉取 latest。 |
| 容器配额 | 是 | 指定容器的 CPU、内存、GPU 资源信息。您可在此处选择 GPU 类型为独占或共享。 |
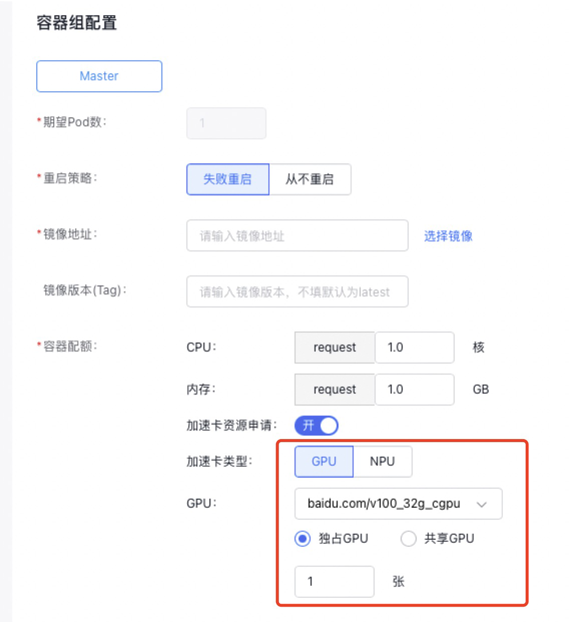
5.1.1 单卡/多卡独占
- 当您指定GPU类型为独占GPU时,若希望任务使用整张GPU卡资源,操作步骤如下:
- 选择 GPU 卡型号。
- 输入 GPU 卡数量,范围为 [1~当前集群中单节点所含 GPU 卡最大数量]。
- 若希望任务仅使用CPU和内存资源,无需使用GPU资源,操作步骤如下:
GPU卡型号保持为空,仅输入所需CPU和内存资源量。
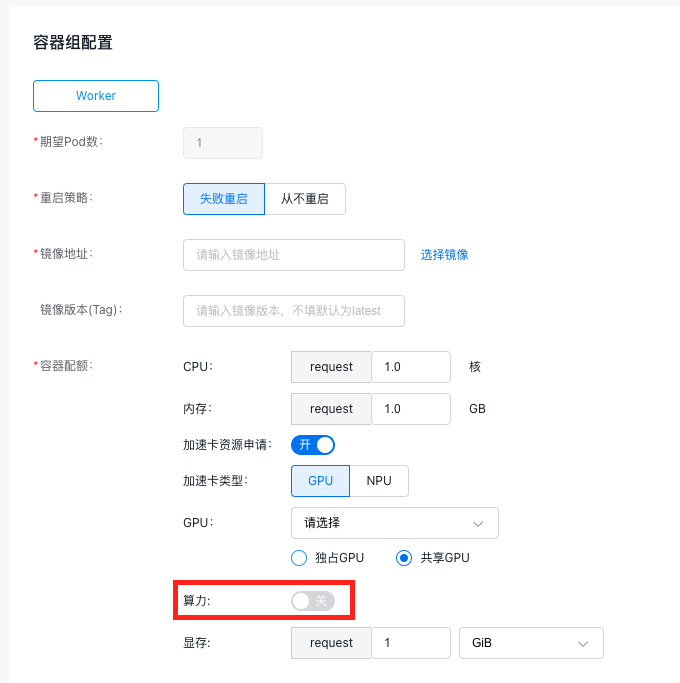
5.1.2 单卡共享(不进行算力隔离,仅显存隔离)
当您指定GPU类型为共享GPU时,若希望任务只进行显存隔离,算力无需隔离,操作步骤如下:
- 选择 GPU 卡型号。
- 算力开关关闭。
- 输入所需 GPU 显存,范围为 [1~所选 GPU 卡显存大小]。
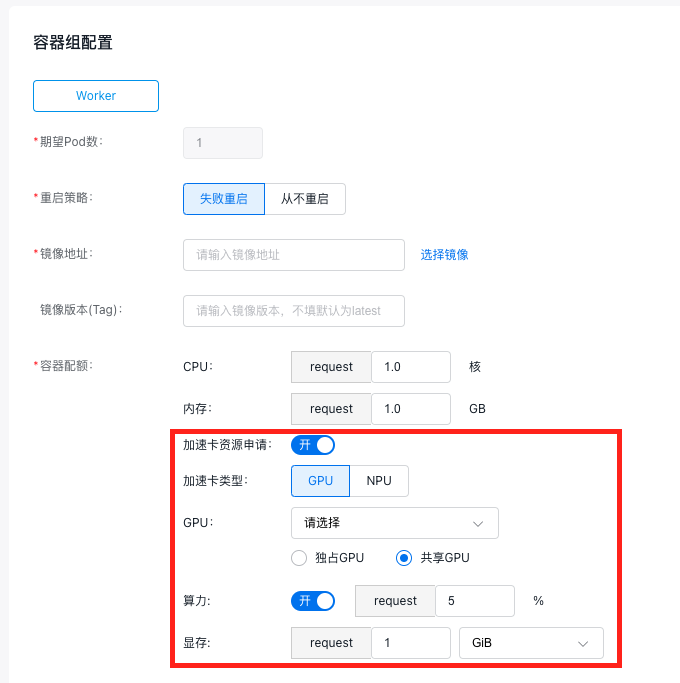
5.1.3 单卡共享(显存隔离和算力隔离)
当您指定GPU类型为共享GPU时,若希望任务同时进行显存隔离和算力隔离,操作步骤如下:
- 选择GPU卡型号。
- 打开算力开关,输入所需算力值百分比,百分比大小应为[5~100正整数]。
- 再输入所需GPU显存,显存大小应为正整数,范围为[1~所选GPU卡显存大小]。
- 配置任务高级信息。
| 参数 | 必填 | 说明 |
|---|---|---|
| 最大训练时长 | 否 | 指定允许的最大训练时长;若不指定,则表示不限制时间。 |
| 私有仓库凭证 | 否 | 若需要使用私有镜像仓库,请在此处添加对应镜像仓库的访问凭证。 |
| Tensorboard | 否 | 若需要任务可视化,可开启该功能;开启后需指定 服务类型 与 训练日志读取路径。 |
| K8S 标签 | 否 | 指定任务对应的 K8S Label。 |
| 注释 | 否 | 指定任务对应的 Annotation。 |
- 点击“完成”按钮,完成任务的新建。
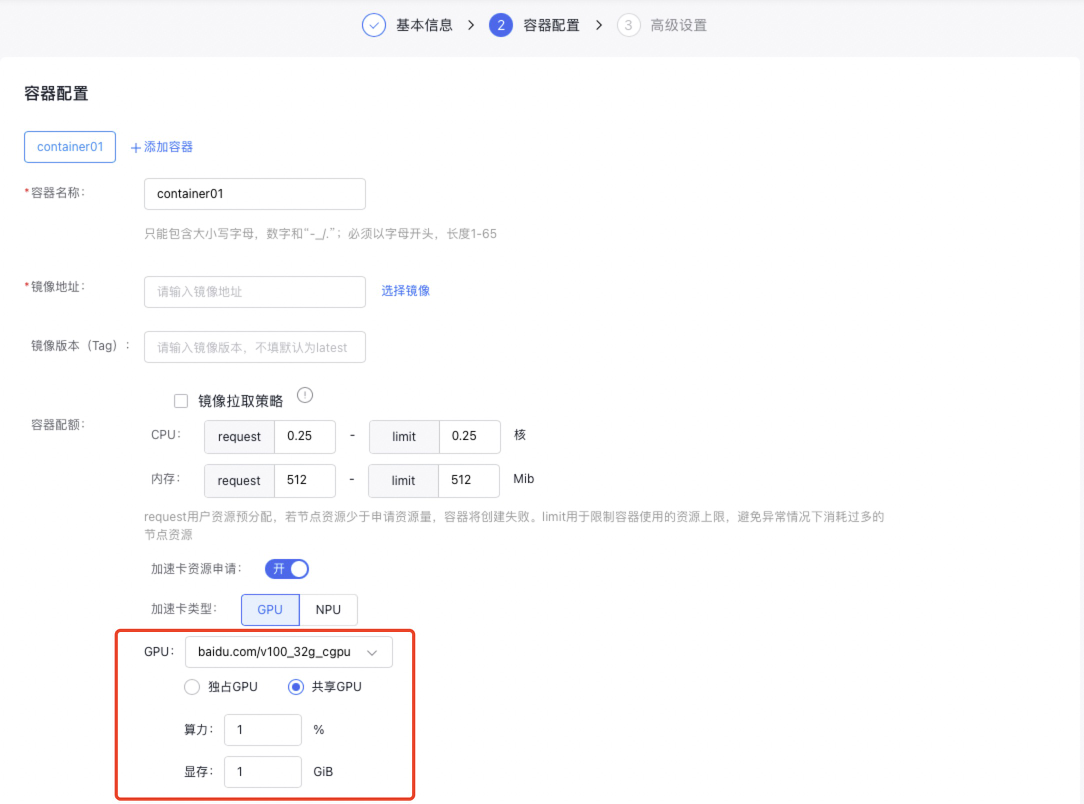
5.2. 在控制台创建工作负载
若您通过CCE控制台创建工作负载(操作步骤可参考工作负载),您可在工作负载的容器配置中指定GPU类型为独占或共享。独占和共享的资源输入限制和上文中AI任务的创建一致。
5.3. 使用 YAML 创建任务/工作负载
可参考 云原生 AI 任务管理 与 工作负载。
导航路径:产品服务->云原生->容器引擎 CCE->集群管理->集群列表->目标集群
在使用 YAML 创建任务或工作负载前,请先获取目标集群凭证,并确保对目标命名空间具备相应创建权限。您可在 YAML 配置中指定所需 GPU 卡资源为独占或共享,示例如下。
备注:
- 如使用Yaml的方式创建任务,调度器必须指定 schedulerName: volcano
- GPU显存资源必须申请,且 baidu.com/v100_32g_cgpu_memory 和 baidu.com/v100_32g_cgpu_memory_percent只能填写一个,不可同时填写
- 卡的资源名称根据第四部分资源描述填写,不同卡型号对应不同的资源名称。
5.3.1 单卡独占
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1 # 1 卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 1 # limit 与 request 必须一致
8 cpu: "4"
9 memory: 60Gi5.3.2 多卡独占
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 2 # 2 卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 2 # limit 与 request 必须一致
8 cpu: "4"
9 memory: 60Gi5.3.3 单卡共享(不进行算力隔离,仅显存隔离)
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu_memory: 10 # 10 GiB,可根据业务需求调整
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu_memory: 10
8 cpu: "4"
9 memory: 60Gi5.3.4 单卡共享(显存隔离和算力隔离)
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu_core: 50 # 50%,即 0.5 卡算力,可根据业务需求调整
4 baidu.com/v100_32g_cgpu_memory: 10 # 10 GiB,可根据业务需求调整
5 cpu: "4"
6 memory: 60Gi
7 limits:
8 baidu.com/v100_32g_cgpu_core: 50
9 baidu.com/v100_32g_cgpu_memory: 10
10 cpu: "4"
11 memory: 60Gi5.3.5 单容器多卡能力(GPU 显存 / 算力同时隔离与仅显存隔离)
通过指定资源描述符使用sGPU的单容器多卡能力,分为GPU显存/算力同时隔离以及仅隔离显存的场景。
- GPU显存/算力同时隔离
单张共享卡的资源:
- 每张 GPU卡的算力资源:baidu.com/xxx_xxx_cgpu_core/baidu.com/xxx_xxx_cgpu
- 每张 GPU卡的显存资源:baidu.com/xxx_xxx_cgpu_memory/baidu.com/xxx_xxx_cgpu
资源描述示例,如下示例代表:该Pod共申请50%的算力,以及10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 25%的算力以及5GiB显存。
1resources:
2 limits:
3 baidu.com/a10_24g_cgpu: "2"
4 baidu.com/a10_24g_cgpu_core: "50"
5 baidu.com/a10_24g_cgpu_memory: "10"- GPU显存隔离,算力共享
单张共享卡的资源:
- 每张 GPU卡的算力资源:与其他容器共享100%的算力。
- 每张 GPU卡的显存资源:baidu.com/xxx_xxx_cgpu_memory/baidu.com/xxx_xxx_cgpu
资源描述示例,如下示例代表:该Pod共申请10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 共享100%的算力以及5GiB显存。
1resources:
2 limits:
3 baidu.com/a10_24g_cgpu: "2"
4 baidu.com/a10_24g_cgpu_memory: "10"- 使用限制
- 单卡的显存 / 算力必须为正整数。即算力(
baidu.com/xxx_xxx_cgpu_core / baidu.com/xxx_xxx_cgpu)与显存(baidu.com/xxx_xxx_cgpu_memory / baidu.com/xxx_xxx_cgpu)均需为正整数。 - 单卡的显存 / 算力需大于等于对应资源的最小单位。
- 如果没有申请
_cgpu_memory或_cgpu_memory_percent,则不允许申请_cgpu_core。 - 显存隔离最小单位为
1 GiB。 - 算力隔离最小单位为
5%。
6. 共享GPU场景下的镜像构建注意事项
- 在共享GPU场景下,您在创建任务选择镜像时,需要注意该镜像的环境变量。
以下环境变量会由 GPU Manager的组件进行注入,请不要添加到镜像的环境变量里面:
| 环境变量 | 说明 |
|---|---|
| NVIDIA_VISIBLE_DEVICES | 可见 GPU 设备列表,由调度器分配 |
| NVIDIA_VISIBLE_GPUS_SLOT | 可见 GPU 设备插槽,由调度器分配 |
| NVIDIA_VISIBLE_GPUS_UUID | UUID 形式的可见 GPU 设备列表,由调度器分配 |
| LD_LIBRARY_PATH | 不推荐设置 LD_LIBRARY_PATH 环境变量,如果非要设置,需要把 /usr/lib64 目录也按 LD_LIBRARY_PATH=/usr/lib64:$LD_LIBRARY_PATH 形式添加进去 |
| CUDA_MPS_ACTIVE_THREAD_PERCENTAGE | MPS 算力隔离设置,由调度器分配 |
| CUDA_MPS_LOG_DIRECTORY | MPS 相关日志地址 |
| CUDA_MPS_PIPE_DIRECTORY | 和 MPS SERVER 通信的地址 |
| CGPUX_XXX | 以 CGPU 开头的环境变量,用于运行显存&算力隔离功能,比如 CGPU0_PRIORITY,CGPU0_SHAREMODE |
| CGPU_COUNT | 设备数量 |
| SGPU_DISABLE | 使用隔离最优型时,表示是否使用虚拟化的方式使用 GPU |
- 构建镜像时,请不要直接将集群中运行的 GPU 容器保存为镜像使用,此种方式保存的镜像会包含GPU Manager组件注入的环境变量,造成虚拟化功能不符合预期或者不可用。
7. (可选)验证GPU虚拟化的隔离效果
您在完成以上操作后,若您想验证被共享的GPU是否按照所设置的隔离参数运行,可通过以下步骤查看。
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击工作负载>容器组。
- 单击您要查看的Pod名称
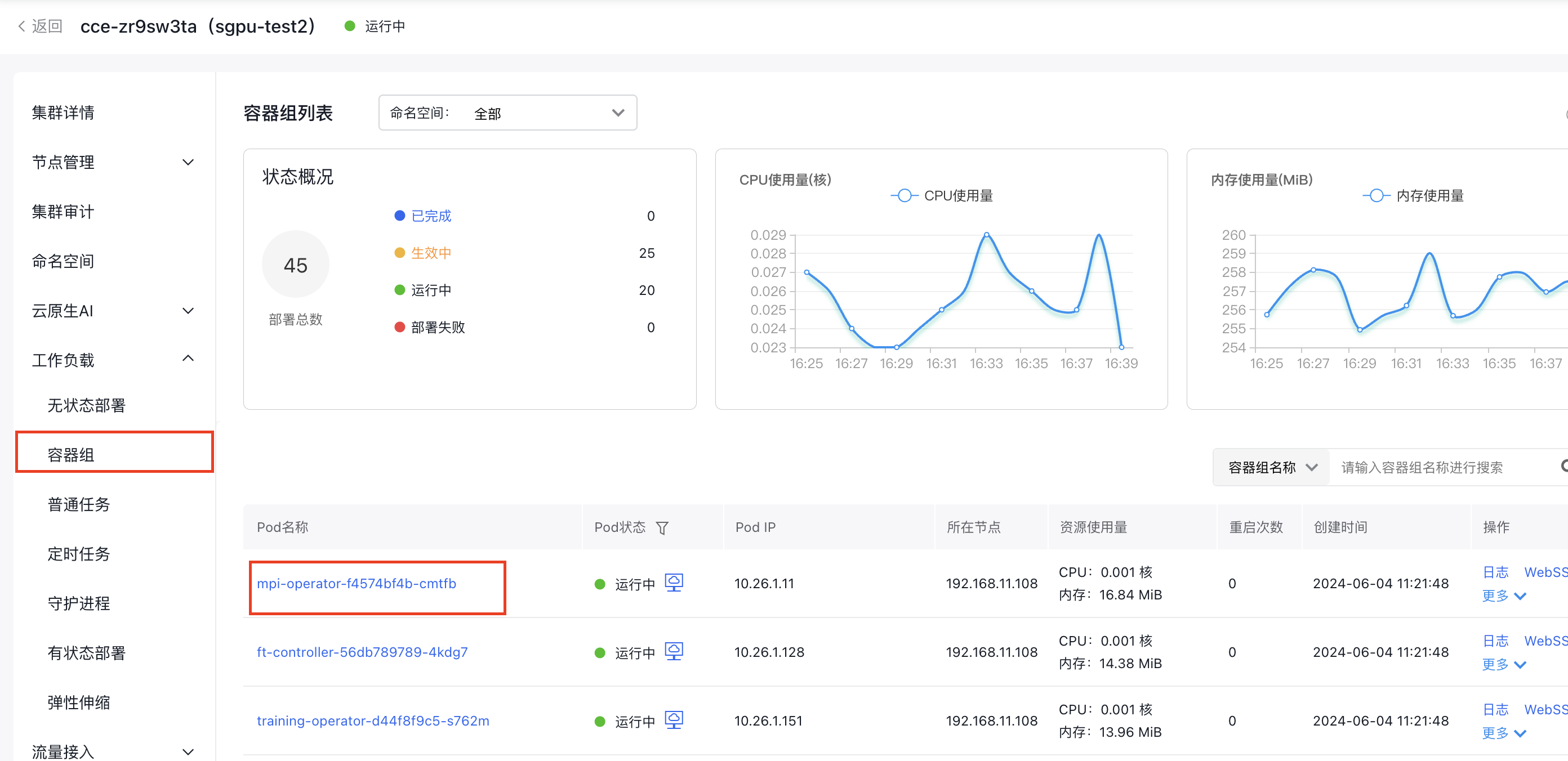
- 点击WebSSH,指令类型选择/bin/sh,点击连接
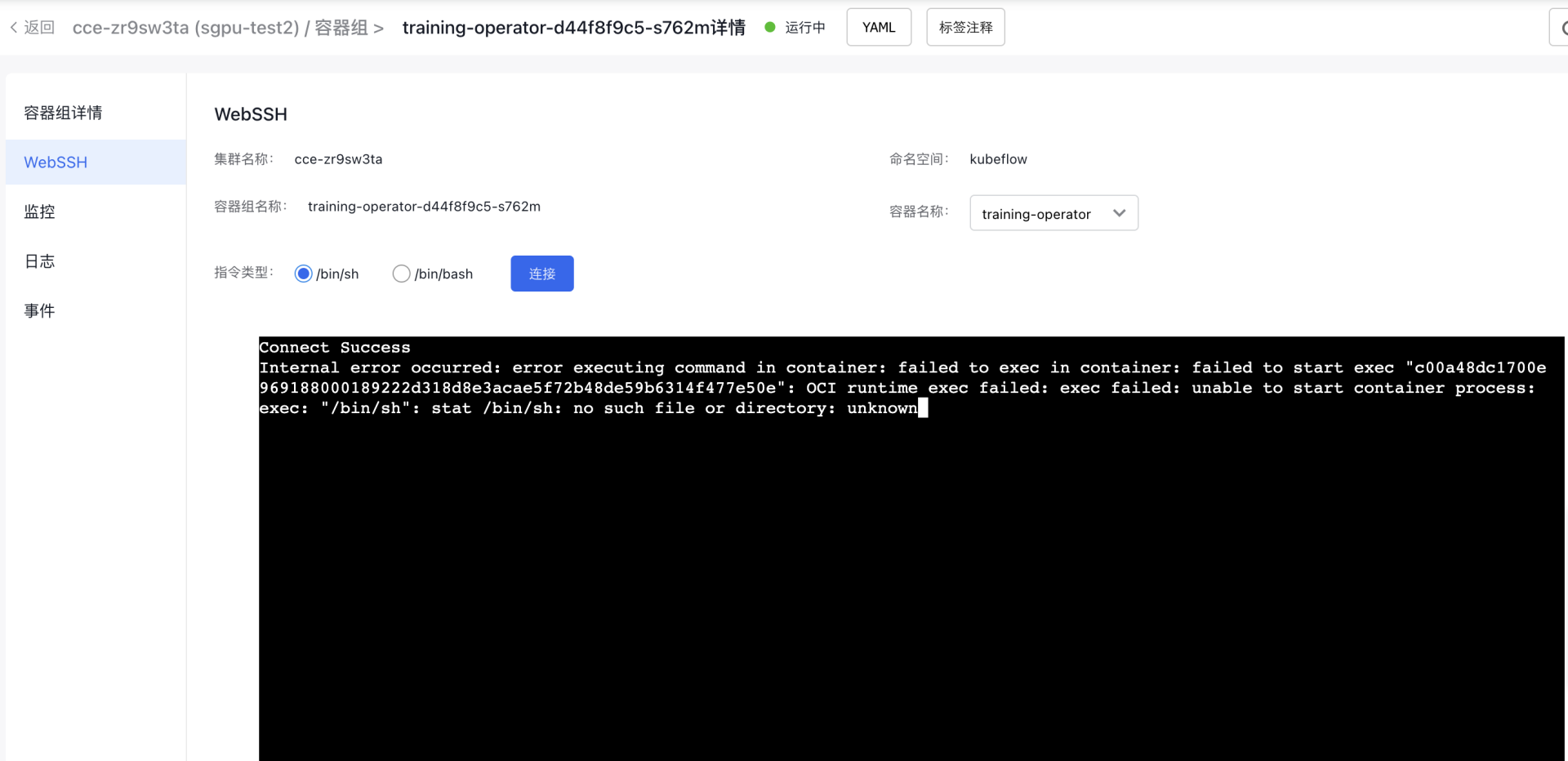
- 输入命令行:nvidia-smi,按下回车键
| 参数 | 说明 |
|---|---|
| GPU Name | 列出了服务器上的所有GPU。 |
| Memory-Usage | 显示了每个GPU的内存使用情况。 |
| GPU-Util | 显示了每个GPU的利用率。 |
| Processes | 显示了正在使用GPU的进程。 |
8. 关闭显存共享
1.关闭显存共享功能的限制条件
已开启显存共享功能的节点需要关闭显存共享功能时,系统会验证当前节点上是否有正在运行的显存共享任务,需等该节点所有显存共享任务都运行完成后才能够关闭显存共享功能,否则可能导致显存共享任务中断或任务结束时无法正常回收资源,影响节点上的后续任务。
您可以通过2、3提供的命令查看开启了显存共享的节点和查看该节点上显存共享任务的情况。
2.查询开启显存共享的节点
1kubectl get nodes -l cce.baidubce.com/gpu-share-device-plugin=enable该命令会列出开启了显存共享功能的所有节点,这些节点上都有标签cce.baidubce.com/gpu-share-device-plugin:enable。
3.查询运行显存共享任务的Pods
1kubectl get pods --all-namespaces -o json | jq -r '.items[] | select(.status.phase=="Running") | select(.spec.containers[].resources.limits // empty | keys[] // empty | test("baidu.com/.*(_core|_memory|_memory_percent)$")) | "\(.metadata.name) \(.spec.nodeName)"' | sort | uniq该命令会列出所有在运行状态且使用了显存共享功能的 Pods,以及它们所在的节点。这些节点都无法马上关闭显存共享功能,需要等这些Pods结束以后才能关闭节点显存共享功能。
4.使用label命令修改节点标签的风险
除控制台方式外,可以使用kubectl label nodes命令来修改节点标签为cce.baidubce.com/gpu-share-device-plugin:disable,关闭节点的显存共享功能,修改前请关注以下风险:
- 业务中断:修改节点标签之后会触发非共享场景的环境安装,导致正在运行的显存共享任务中断或者结束时无法正常回收资源,影响节点上的后续任务。
- 调度失败:修改标签之后,调度器可以向该节点调度非共享类型的任务,可能存在单机同时运行两种类型的任务,会有错卡,共享显存功能异常等问题。
为了避免这些风险,请始终确保集群中的节点标签正确地反映节点的能力,并且只有在确定节点上没有正在运行的显存共享任务时,再关闭节点显存共享功能。
评价此篇文章