
基础(必看):鉴权字符串生成
更新时间:2022-12-01
鉴权字符串生成
使用原始API进行访问BOS,需要自行计算鉴权信息。使用流程:
- 准备 ak/sk
- python3.6及以上环境
生成鉴权字符串完整demo
示例生成auth_key以GET请求访问Bucket为例
- 鉴权字符串算法代码
Python
1import hashlib
2import hmac
3import string
4import datetime
5
6
7AUTHORIZATION = "authorization"
8BCE_PREFIX = "x-bce-"
9DEFAULT_ENCODING = 'UTF-8'
10
11
12# 保存AK/SK的类
13class BceCredentials(object):
14 def __init__(self, access_key_id, secret_access_key):
15 self.access_key_id = access_key_id
16 self.secret_access_key = secret_access_key
17
18
19# 根据RFC 3986,除了:
20# 1.大小写英文字符
21# 2.阿拉伯数字
22# 3.点'.'、波浪线'~'、减号'-'以及下划线'_'
23# 以外都要编码
24RESERVED_CHAR_SET = set(string.ascii_letters + string.digits + '.~-_')
25
26
27def get_normalized_char(i):
28 char = chr(i)
29 if char in RESERVED_CHAR_SET:
30 return char
31 else:
32 return '%%%02X' % i
33
34
35NORMALIZED_CHAR_LIST = [get_normalized_char(i) for i in range(256)]
36
37
38# 规范化字符串
39def normalize_string(in_str, encoding_slash=True):
40 if in_str is None:
41 return ''
42
43 # 如果输入是unicode,则先使用UTF8编码之后再编码
44 # in_str = in_str.encode(DEFAULT_ENCODING) if isinstance(in_str, unicode) else str(in_str)
45 in_str = in_str if isinstance(in_str, str) else str(in_str)
46
47 # 在生成规范URI时。不需要对斜杠'/'进行编码,其他情况下都需要
48 if encoding_slash:
49 encode_f = lambda c: NORMALIZED_CHAR_LIST[ord(c)]
50 else:
51 # 仅仅在生成规范URI时。不需要对斜杠'/'进行编码
52 encode_f = lambda c: NORMALIZED_CHAR_LIST[ord(c)] if c != '/' else c
53
54 # 按照RFC 3986进行编码
55 return ''.join([encode_f(ch) for ch in in_str])
56
57
58# 生成规范URI
59def get_canonical_uri(path):
60 # 规范化URI的格式为:/{bucket}/{object},并且要对除了斜杠"/"之外的所有字符编码
61 return normalize_string(path, False)
62
63
64# 生成规范query string
65def get_canonical_querystring(params):
66 if params is None:
67 return ''
68
69 # 除了authorization之外,所有的query string全部加入编码
70 result = ['%s=%s' % (k, normalize_string(v)) for k, v in params.items() if k.lower != AUTHORIZATION]
71
72 # 按字典序排序
73 result.sort()
74
75 # 使用&符号连接所有字符串并返回
76 return '&'.join(result)
77
78
79# 生成规范header
80def get_canonical_headers(headers, headers_to_sign=None):
81 headers = headers or {}
82
83 # 没有指定header_to_sign的情况下,默认使用:
84 # 1.host
85 # 2.content-md5
86 # 3.content-length
87 # 4.content-type
88 # 5.所有以x-bce-开头的header项
89 # 生成规范header
90 if headers_to_sign is None or len(headers_to_sign) == 0:
91 headers_to_sign = {"host", "content-md5", "content-length", "content-type"}
92
93 # 对于header中的key,去掉前后的空白之后需要转化为小写
94 # 对于header中的value,转化为str之后去掉前后的空白
95 # f = lambda (key, value): (key.strip().lower(), str(value).strip())
96 f = lambda item: (item[0].strip().lower(), str(item[1]).strip())
97
98 result = []
99 for k, v in map(f, headers.items()):
100 # 无论何种情况,以x-bce-开头的header项都需要被添加到规范header中
101 if k.startswith(BCE_PREFIX) or k in headers_to_sign:
102 result.append("%s:%s" % (normalize_string(k), normalize_string(v)))
103
104 # 按照字典序排序
105 result.sort()
106
107 # 使用\n符号连接所有字符串并返回
108 return '\n'.join(result)
109
110
111# 签名主算法
112def sign(credentials, http_method, path, headers, params, expiration_in_seconds=1800, headers_to_sign=None):
113 headers = headers or {}
114 params = params or {}
115 x_bce_date = headers.get("x-bce-date")
116 # timestamp = int(datetime.datetime.strptime(x_bce_date, "%Y-%m-%dT%H:%M:%SZ").timestamp())
117 # 1.生成sign key
118 # 1.1.生成auth-string,格式为:bce-auth-v1/{accessKeyId}/{timestamp}/{expirationPeriodInSeconds}
119 sign_key_info = 'bce-auth-v1/%s/%s/%d' % (
120 credentials.access_key_id,
121 x_bce_date,
122 expiration_in_seconds)
123 # 1.2.使用auth-string加上SK,用SHA-256生成sign key
124 sign_key = hmac.new(
125 credentials.secret_access_key.encode("utf-8"),
126 sign_key_info.encode("utf-8"),
127 hashlib.sha256).hexdigest()
128
129 # 2.生成规范化uri
130 canonical_uri = get_canonical_uri(path)
131
132 # 3.生成规范化query string
133 canonical_querystring = get_canonical_querystring(params)
134
135 # 4.生成规范化header
136 canonical_headers = get_canonical_headers(headers, headers_to_sign)
137
138 # 5.使用'\n'将HTTP METHOD和2、3、4中的结果连接起来,成为一个大字符串
139 string_to_sign = '\n'.join(
140 [http_method, canonical_uri, canonical_querystring, canonical_headers])
141
142 # 6.使用5中生成的签名串和1中生成的sign key,用SHA-256算法生成签名结果
143 sign_result = hmac.new(sign_key.encode("utf-8"), string_to_sign.encode("utf-8"), hashlib.sha256).hexdigest()
144
145 # 7.拼接最终签名结果串
146 if headers_to_sign:
147 # 指定header to sign
148 result = '%s/%s/%s' % (sign_key_info, ';'.join(headers_to_sign), sign_result)
149 else:
150 # 不指定header to sign情况下的默认签名结果串
151 result = '%s//%s' % (sign_key_info, sign_result)
152 return result
153
154
155def get_x_bce_date(date=None):
156 """获取UTC格式的时间"""
157 if date is None:
158 format_string = "%Y-%m-%dT%H:%M:%SZ"
159 date = datetime.datetime.utcnow().strftime(format_string)
160 return date
161
162
163def generate_bos_auth(path, ak, sk, method, headers, params, expire_seconds=1800):
164 """生成bos的鉴权字符串,过期时间默认1800s"""
165 credentials = BceCredentials(ak, sk)
166 return sign(credentials, method, path, headers, params, expire_seconds, headers.keys())- 调用鉴权字符串
Python
1access_key = "AK"
2secret_key = "SK"
3bucket_name = "bucketName" # 替换为需要访问bucketName
4object_key = "/aaa.png" # 在请求url没有参数时,访问的key的名字就是path,注意以 '/'开头
5region = "bj.bcebos.com" # bucket所在的区域,不同区域服务域名不同
6request_method = "GET" # 请求方法类型 GET、PUT、HEAD、POST、DELETE
7host = f"{bucket_name}.{region}" # 根据bucket和服务域名组装访问域名
8# 构造访问的header信息,可以根据需要进行额外添加,例如:content-type字段
9header = {
10 "host": host,
11 "x-bce-date": get_x_bce_date()
12}
13# 如果请求在url中有带参数,也要参与鉴权
14param = {}
15# 生成鉴权字符串
16auth_key = generate_bos_auth(object_key, access_key, secret_key, request_method, header, param)
17# 构建完整的访问url
18request_url = f"http://{host}{object_key}?{AUTHORIZATION}={auth_key}"将<鉴权字符串算法代码><调用鉴权字符串>两部分代码组成一个py文件即可执行
注意:
- 生成的
auth_key只是一个authorization字段,需要拼接为request_url后才能进行正常访问。 request_url访问时需要带上x-bce-date字段,该字段尽量与生成签名时的x-bce-date字段相同,postman请求示例: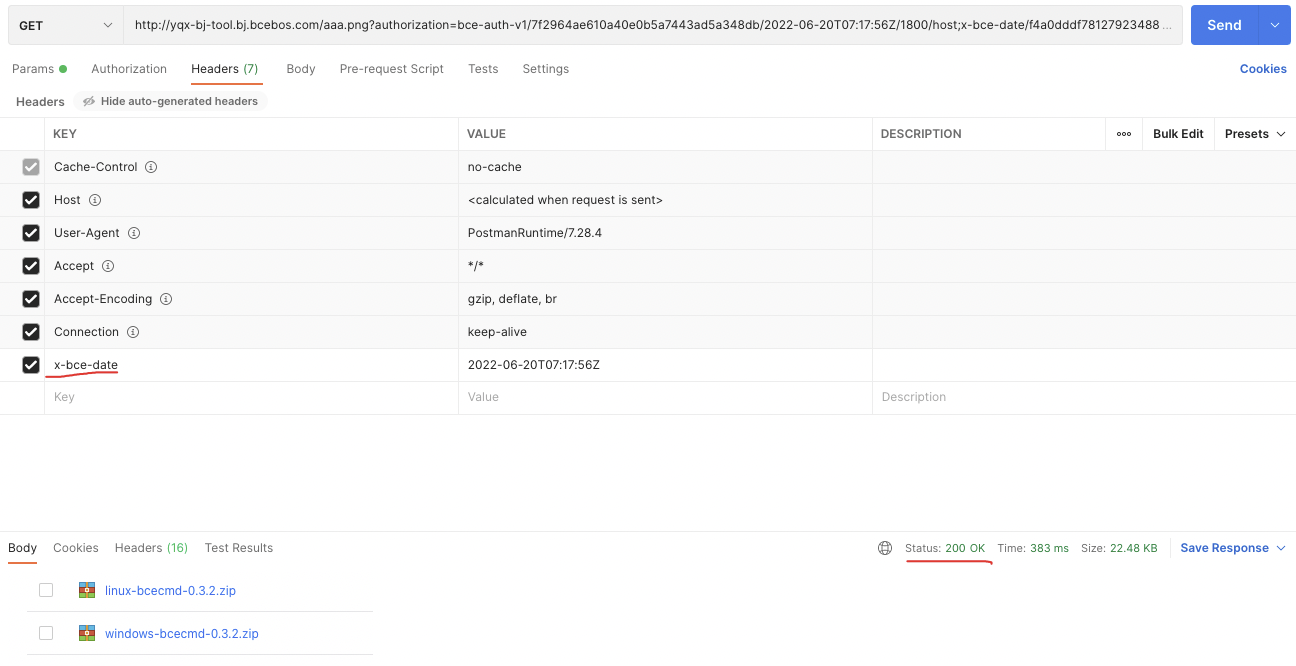
- 更多详情参考生成签名字符串。
评价此篇文章