
Kafka数据存储到BOS
更新时间:2024-08-30
工具概述
Apache Kafka是一个开源的分布式事件流平台,被广泛用于高性能数据管道、流分析、数据集成和关键任务应用。它支持通过connector方式将事件流数据导出到S3等对象存储系统上,本文将详细阐述如何利用Kafka的S3 Sink Connector插件将数据数据导出至BOS存储桶。
配置教程
-
下载所需版本的Kafka安装包和confluentinc-kafka-connect-s3安装包,解压并启动Kafka相关服务(注意部分kafka和connector版本存在不兼容问题,需要根据实际情况进行升级,本次以kafka-3.6.2和kafka-connect-s3-10.5.0版本演示)。
Shell1# 下载安装Kafka,创建plugins目录 2tar zxvf kafka_2.13-3.6.2.tgz 3cd kafka_2.13-3.6.2 4mkdir -p plugins 5# 启动Zookeeper 6bin/zookeeper-server-start.sh config/zookeeper.properties 7# 启动Kafka 8bin/kafka-server-start.sh config/server.properties 9# 下载安装S3 Sink Connector,放到Kafka安装后的plugins目录下 10unzip confluentinc-kafka-connect-s3-10.5.0.zip 11cp -r confluentinc-kafka-connect-s3-10.5.0 kafka_2.13-3.6.2/plugins -
修改Kafka的config目录下的
connect-standalone.properties配置文件,添加插件路径和部分配置。Shell1# Kafka集群的初始连接地址 2bootstrap.servers=localhost:9092 3# converter类型配置 4key.converter=org.apache.kafka.connect.json.JsonConverter 5value.converter=org.apache.kafka.connect.json.JsonConverter 6key.converter.schemas.enable=false 7value.converter.schemas.enable=false 8offset.storage.file.filename=/tmp/connect.offsets 9# Kafka Connect将偏移量刷新到存储文件的间隔时间 10offset.flush.interval.ms=10000 11# Kafka的插件所在具体路径 12plugin.path=/path/kafka_2.13-3.6.2/plugins -
配置S3 Sink Connector插件,修改
config/s3-sink.properties配置文件,并启动S3 Sink Connector,详见配置项,如下所示:Shell1name=s3-sink 2connector.class=io.confluent.connect.s3.S3SinkConnector 3# connector可以创建的最大任务数 4tasks.max=1 5# 指定读取数据的Kafka topic列表 6topics=my-topic 7# BOS Access Key ID 8aws.access.key.id=bos-ak 9# BOS Secret Access Key 10aws.secret.access.key=bos-sk 11# BOS Endpoint,例如https://s3.bj.bcebos.com 12store.url=bos-endpoint 13# BOS桶名称 14s3.bucket.name=bos-bkt 15storage.class=io.confluent.connect.s3.storage.S3Storage 16format.class=io.confluent.connect.s3.format.json.JsonFormat 17partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner 18# 将数据刷新到BOS之前缓存的最大记录数 19flush.size=3 -
启动S3 Sink Connector,创建kafka topic并写入数据,验证数据是否正常导出到BOS,执行如下命令:
Shell1# 启动S3 Sink Connector 2bin/connect-standalone.sh config/connect-standalone.properties config/s3-sink.properties 3# 创建一个名为my-topic的kafka topic 4bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic 5# 写入数据到my-topic,执行如下命令之后输入数据即可 6bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic 7# 数据成功导出到BOS后Connector会有如下类似输出 8[2024-08-28 12:34:00,186] INFO [s3-sink|task-0] Creating S3 output stream. (io.confluent.connect.s3.storage.S3Storage:200) 9[2024-08-28 12:34:00,191] INFO [s3-sink|task-0] Create S3OutputStream for bucket 'bos-bkt' key 'topics/my-topic/partition=0/my-topic+0+0000000000.json' (io.confluent.connect.s3.storage.S3OutputStream:96) 10[2024-08-28 12:34:23,694] INFO [s3-sink|task-0] Starting commit and rotation for topic partition my-topic-0 with start offset {partition=0=0} (io.confluent.connect.s3.TopicPartitionWriter:326) 11[2024-08-28 12:34:24,148] INFO [s3-sink|task-0] Files committed to S3. Target commit offset for my-topic-0 is 3 (io.confluent.connect.s3.TopicPartitionWriter:634) - 然后我们可以从BOS控制台看到导出的topic数据,格式为
bos-bkt/topics/my-topic/partition=0/my-topic+0+0000000000.json: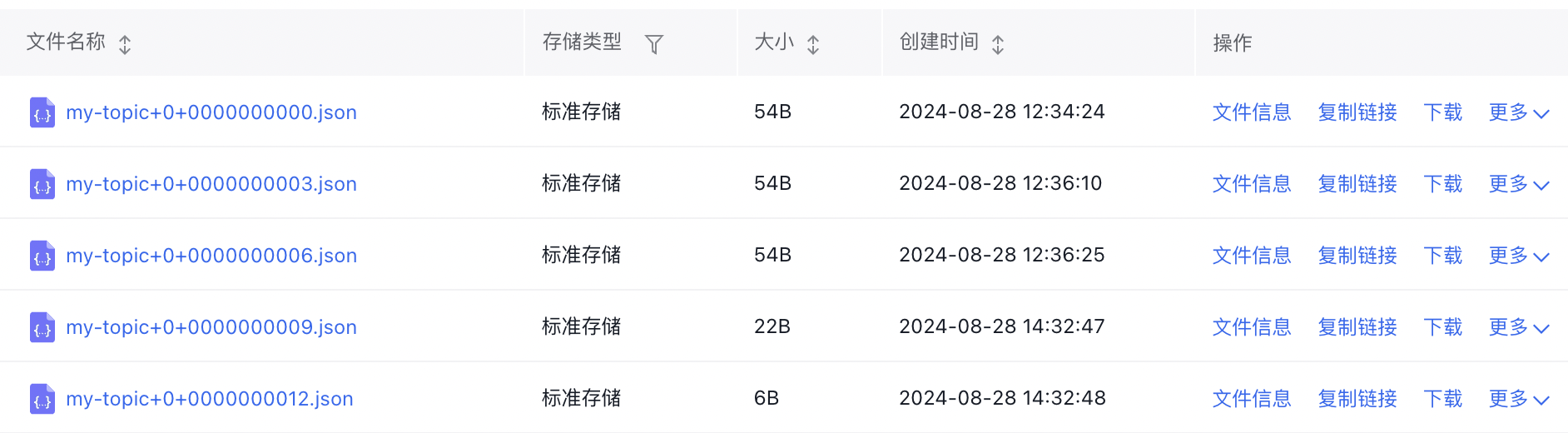
评价此篇文章