用BML实现开源大模型的预训练(Post-pretrain)
目录
1.准备工作(通过notebook或者本地IDE实现)
1.1.环境创建
1.2.代码下载
1.3.目录创建
1.4.准备预训练模型权重
1.5.准备训练数据
2.训练Pipeline说明
2.1.Step1:数据预处理
2.2.Step2:模型格式转换(HF->Megatron)
2.3.Step3:预训练(使用作业建模大模型案例实现)
2.4.Step4:模型格式转换(Megatron->HF)
2.5.Step5:快速导入并部署第三方模型
一、准备工作(通过notebook或者本地IDE实现)
预置的大模型案例,是针对处理后的数据以及转换成megatron格式的模型进行的。因此,如果需要使用自定义的模型,以及自定义的数据,可参考以下流程。
环境创建
数据处理以及模型转换均可使用作业建模+大模型案例提供的训练镜像实现,也可在任意环境实现,再将转换后的结果上传到存储中使用,以下提供了训练镜像构建时使用的基础镜像以及额外安装的第三方库。
1docker pull nvcr.io/nvidia/pytorch:23.10-py3 # 训练镜像
2pip3 install transformers==4.39.3 datasets==2.18.0 sentencepiece==0.2.0 nltk==3.8.1 accelerate==0.29.3# 第三方库
代码下载
目录创建
首先在个人环境或者bos存储中(使用作业建模的方式)创建自己的工作目录作为WORK_DIR,然后在WORK_DIR下分别创建code、data、output、pretrained_models目录,并上传代码bml-megatron-llm(提供的代码压缩包解压)至${WORK_DIR}/code。
准备预训练模型权重
下载好模型权重,保存至 ${WORK_DIR}/pretrained_models 目录下。
准备训练数据
下载开源数据集并保存到${WORK_DIR}/data/目录下,本案例的预训练数据集以Huggine Face上的suolyer/wudao为例,预置的大模型案例也是基于该数据集转化得到。
下载命令行:
1# 下载用于预训练的数据git clone
2https://huggingface.co/datasets/suolyer/wudao
二、训练Pipeline说明
以llama2-7B模型的处理流程为例进行说明,以下每一个步骤的脚本可以在个人环境中运行,也可打包成一个sh脚本,使用作业建模实现,或者使用notebook功能进行实现。
Step1:数据预处理
预训练数据须为 MMAP 格式文件数据(含 .bin 和 .idx 文件),以 suolyer/wudao 数据集的validation.json文件为例,介绍预处理过程。
执行以下命令将预训练数据转换成 MMAP 格式(MMAP数据是一种预先执行tokenize的数据格式,可以减少训练微调过程中等待数据读入的时间,尤其在处理大规模数据时优势更为突出)。
命令执行成功后,在 output-prefix 的 fullpath 目录下生成 .bin 和 .idx 文件。
1export WORK_DIR=/home/bml/storage/mnt/v-x2zt874luaxgmxbf/org/megatron_workspace/ #替换为个人工作目录
2export MEGATRON_PATH=${WORK_DIR}/code/bml-megatron-llm/Megatron-LM/
3export INPUT=${WORK_DIR}/data/wudao/validation.json
4export TOKENIZER_MODEL_PATH=${WORK_DIR}/pretrained_models/tokenizer.model # 替换为huggingface模型的对应文件路径
5export OUTPUT_PREFIX=${WORK_DIR}/data/wudao/validation
6export WORKERS=64
7export JSON_KEYS="content"
8bash ${MEGATRON_PATH}/scripts/data_preprocess/preprocess_train_data.sh脚本执行完成后,得到的数据如下。
1${WORK_DIR}/data/wudao/
2├── README.md
3├── test.json
4├── validation.json
5├── validation_content_document.bin # 新增 ${output-prefix}_${json-keys}_document.bin
6└── validation_content_document.idx # 新增 ${output-prefix}_${json-keys}_document.idx| 参数 | 描述 |
|---|---|
| WORK_DIR | 工作空间路径 |
| MEGATRON_PATH | Megatron代码的基础路径(***/Megatron-LM) |
| INPUT | 输入数据的json/jsonl文件路径,要求jsonl格式 |
| OUTPUT_PREFIX | 输出二进制训练文件前缀 |
| WORKERS | 处理数据的工作进程数,根据机器配置选择,多进程可以加快处理速度 |
| JSON_KEYS | json文件中训练文本的字段名,若有多个,按空格拼接,比如“key0 key1 key2”,默认为“text”。本案例中训练文本在“content”下,因此设置:--json-keys content |
| TOKENIZER_MODEL_PATH | tokenizer.model文件路径 |
Step2:模型格式转换(HF->Megatron)
将 Huggingface 格式的模型文件转换为 Megatron 格式。
1export WORK_DIR=/home/bml/storage/mnt/v-x2zt874luaxgmxbf/org/megatron_workspace/
2export MEGATRON_PATH=${WORK_DIR}/code/bml-megatron-llm/Megatron-LM/
3export HF_FORMAT_DIR=${WORK_DIR}/pretrained_models/
4export TOKENIZER_MODEL=${WORK_DIR}/pretrained_models/
5export MEGATRON_FORMAT_DIR=${WORK_DIR}/output/chinese-llama-2-7b_megatron_core_pp1_tp1/
6export PIPELINE_MODEL_PARALLEL=1
7export TENSOR_MODEL_PARALLEL=1
8bash ${MEGATRON_PATH}/scripts/checkpoint_convert/convert_llama_hf2megatron.sh| 参数 | 描述 |
|---|---|
| HF_FORMAT_DIR | 加载的HuggingFace模型的路径 |
| TOKENIZER_MODEL | tokenizer.model文件所在的目录 |
| MEGATRON_FORMAT_DIR | 保存的Megatron模型checkpoint输出的路径 |
| PIPELINE_MODEL_PARALLEL | 流水切片数量,与训练保持一致。不同参数量下的切片数量不同,在转换模型时需进行针对性修改 |
| TENSOR_MODEL_PARALLEL | 张量切片数量,与训练保持一致。不同参数量下的切片数量不同,在转换模型时需进行针对性修改 |
导出的Megatron格式的checkpoint目录的文件结构如下:
1${MEGATRON_FORMAT_DIR}
2├── iter_0000001
3│ └── mp_rank_00
4│ └── model_optim_rng.pt
5└── latest_checkpointed_iteration.txt
Step3:预训练(使用作业建模大模型案例实现)
大模型案例中,我们提供了预置的模型以及数据,可直接实现训练。用户可根据需要替换数据,经过Step1处理后,替换案例的数据集路径即可。对于模型文件,三个案例均已预置Megatron格式的权重,为了流程介绍的完整,因此我们提供了Step2的模型转换,建议用户直接使用预置案例里转换好的大模型即可。
预训练模型训练完后,保存为Megatron格式,需要使用step4将其转换为Huggingface格式,便于后续使用。
Step4:模型格式转换(Megatron->HF)
您可以将训练获得的 Megatron 格式的模型转换为 Huggingface 格式,具体操作步骤如下。后续您可以使用转换后的 Huggingface 格式的模型进行服务在线部署。
执行以下命令,可将训练生成的 Megatron 格式的模型转换为 Huggingface 格式的模型。
1export WORK_DIR=/home/bml/storage/mnt/v-x2zt874luaxgmxbf/org/megatron_workspace/
2export MEGATRON_PATH=${WORK_DIR}/code/bml-megatron-llm/Megatron-LM/
3export MEGATRON_FORMAT_DIR=${WORK_DIR}/output/chinese-llama-2-7b_megatron_core_pp1_tp1/iter_0000001/
4export HF_FORMAT_DIR=${WORK_DIR}/output/chinese-llama-2-7b_megatron_core_pp1_tp1_post_pretrain_hf/
5export REF_HF_FORMAT_DIR=${WORK_DIR}/pretrained_models
6export HF_PIPELINE_MODEL_PARALLEL=2
7bash ${MEGATRON_PATH}/scripts/checkpoint_convert/convert_llama_megatron2hf.sh部分参数介绍如下(其他参数设置参考“Step2:模型格式转换(HF->Megatron)”部分介绍):
| 参数 | 描述 |
|---|---|
| MEGATRON_FORMAT_DIR | 加载的Megatron模型checkpoint的路径 |
| HF_FORMAT_DIR | 保存的HuggingFace模型checkpoint的路径 |
| REF_HF_FORMAT_DIR | 参考的Huggingface模型目录,用于复制原始config、tokenizer文件 |
| HF_PIPELINE_MODEL_PARALLEL | 保存的HuggingFace模型checkpoint的流水切片数量(因为Huggingface官方的7B权重被划分为2片,所以这里也设为2,保持一致) |
转换后的Huggingface的checkpoint目录的文件结如下:
1${HF_FORMAT_DIR}
2├── config.json
3├── generation_config.json
4├── pytorch_model-00001-of-00002.bin
5├── pytorch_model-00002-of-00002.bin
6├── pytorch_model.bin.index.json
7├── README.md
8├── special_tokens_map.json
9├── tokenizer_config.json
10└── tokenizer.model
Step5:快速导入并部署第三方模型
您可以按照以下步骤进行相关操作,可查看快速导入并部署第三方模型文档。
前提准备
需要您提前开通对象存储BOS服务。
导入模型
使用千帆大模型控制台,在左侧功能列模型管理中选择我的模型,进入创建模型的主任务界面。
- 点击“创建模型”按钮,进行模型新建,填写以下基本信息:
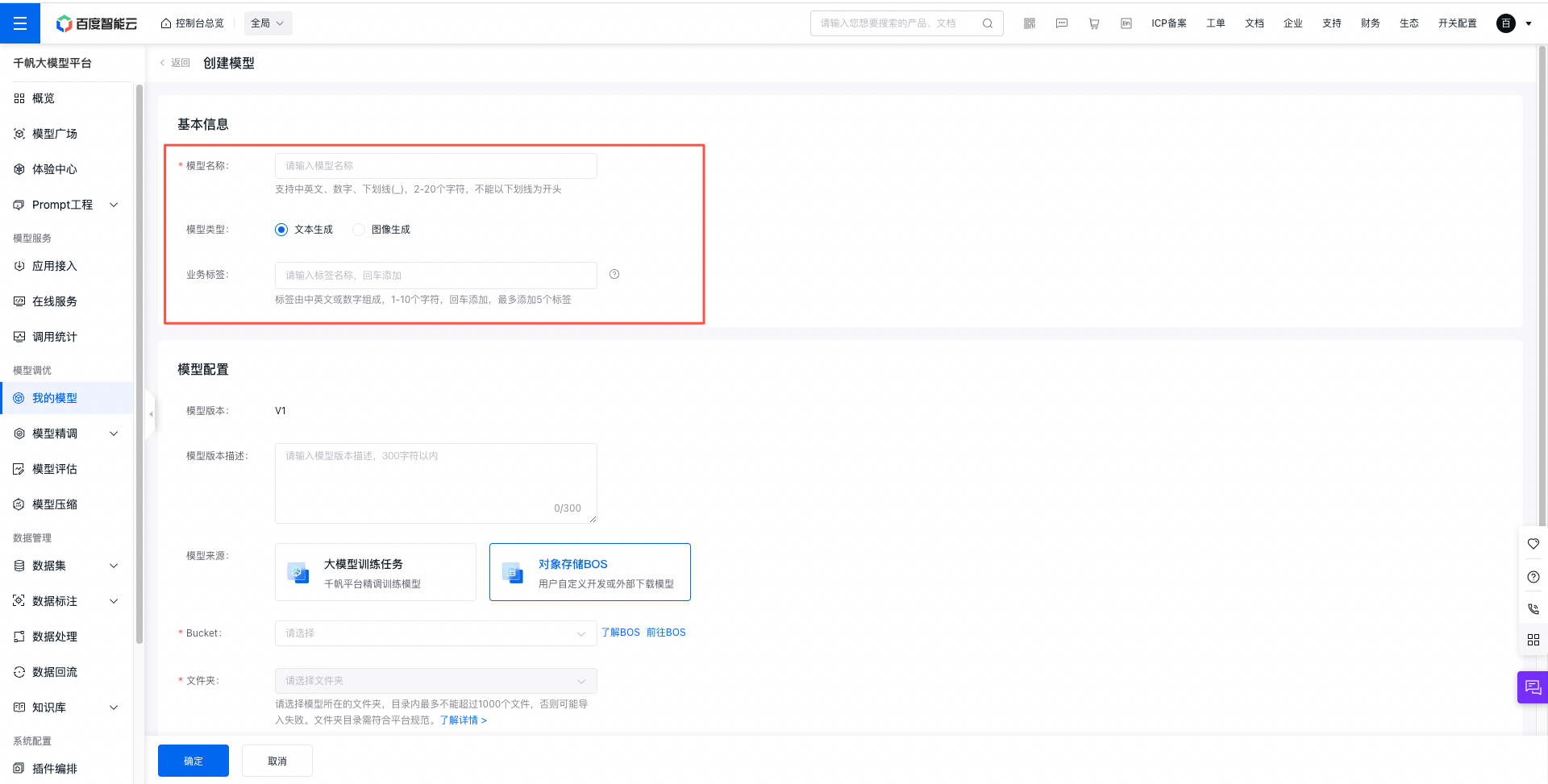
- 选择已完成的训练任务及运行,创建一个新的模型版本,具体字段包括:
- 模型版本:平台自动生成,版本号从V1起递增。
- 模型版本描述:非必填项,自定义的版本描述,记录模型的业务场景、使用方式等信息。
- 模型来源选择BOS,填写相应的Bucket和模型地址。模型需要提前上传到BOS平台,可以登录BOS控制台或者使用BOS工具上传。
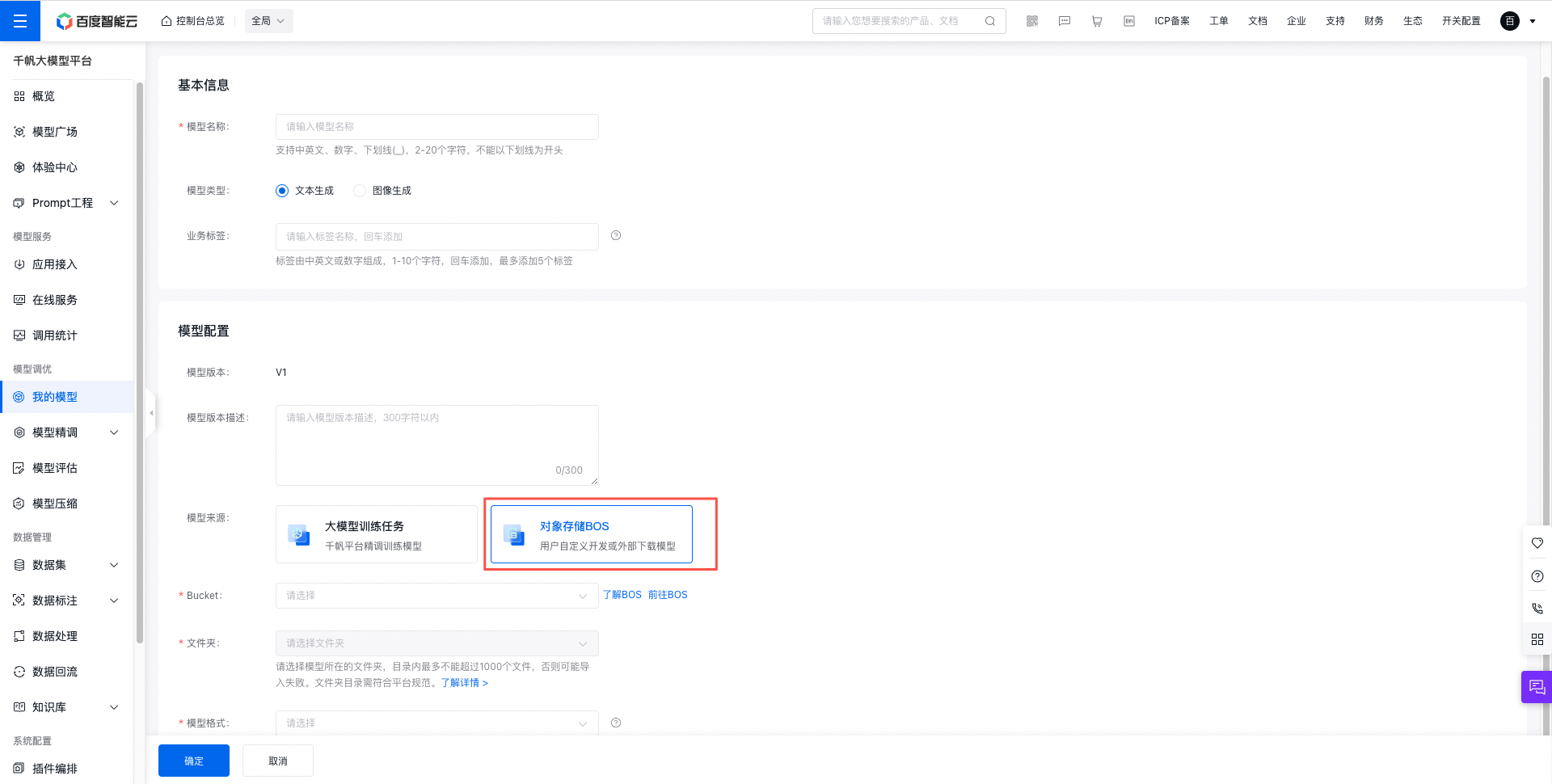
导入HF系列模型
- 输入输出模式多轮对话chat模型选择【对话模式】,单轮问答模型选择【续写模式】
- 如果您选择对话模式还需配置历史对话和当前问题的prompt:平台将根据此配置自动拼接当前用户问题和历史轮次问答,方便用户在线测试或接入对话类应用。
- 两种模式都支持【高级配置】,默认示例如下:
1{
2 "load_model_class": "AutoModelForCausalLM",
3 "load_tokenizer_class": "AutoTokenizer",
4 "enable_auto_batch": true,
5 "custom_end_str": "",
6 "token_decode_return_blank": true,
7 "tokenizer_special_tokens": {}
8}| 高级参数 | 说明 |
|---|---|
| load_model_class | 模型加载类,用于加载transformers模型;默认值 AutoModelForCausalLM |
| load_tokenizer_class | tokenizer加载类,用于加载模型;默认值 AutoTokenizer |
| enable_auto_batch | 处理请求时,是否支持auto batch;是否开启auto batch推理,增加服务吞吐;若模型batch推理不兼容,开启后可能导致效果有误;默认值:true |
| custom_end_str | 自定义生成结束字符串;防止模型不断生成;默认为空值,表示不设置 |
| token_decode_return_blank | 指定英文token解码后是否带有空格,设置为false时,平台会在英文单词间加入空格;默认值为true |
| tokenizer_special_tokens | 选填,需要添加到tokenizer的特殊token;例如 {"pad_token": "[PAD]"} |
部署服务
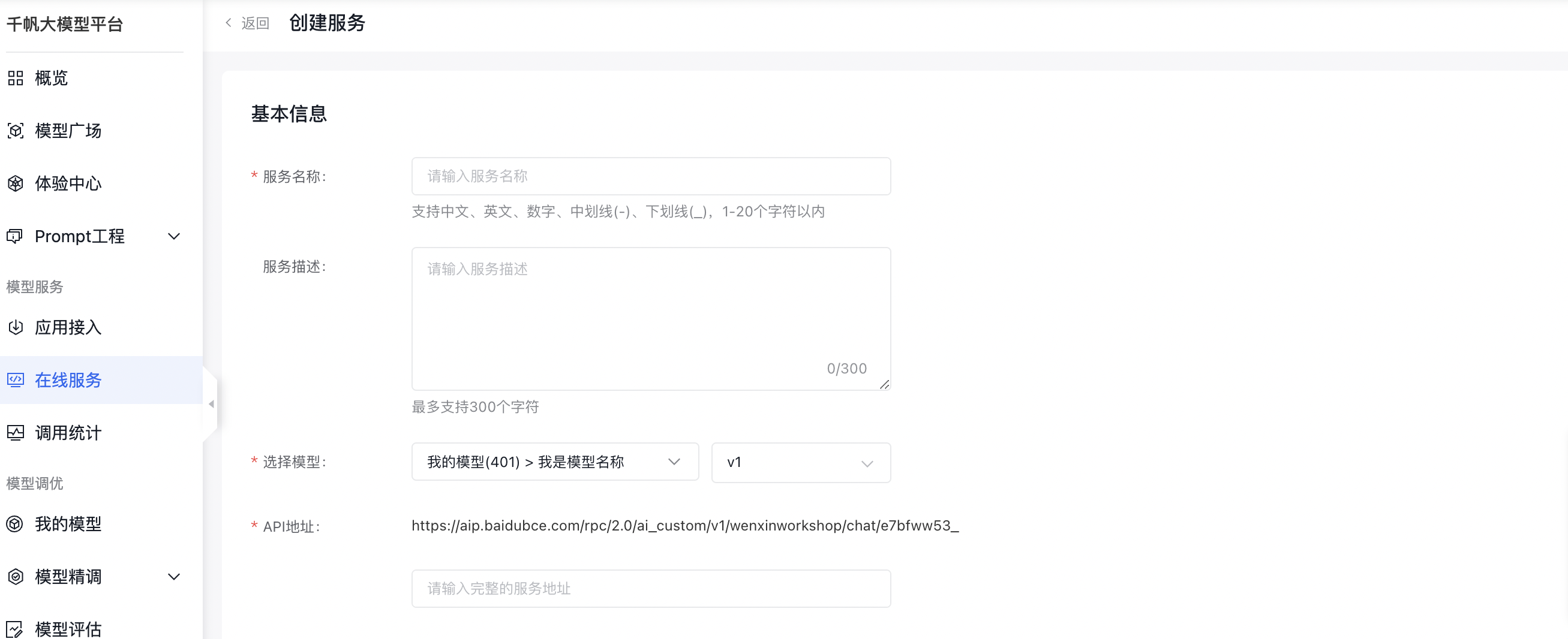
进入【我的模型】点击刚导入的模型进入【详情】页,模型【版本状态】变为“就绪”说明模型导入成功; 点击【部署】按钮进入【创建服务】。

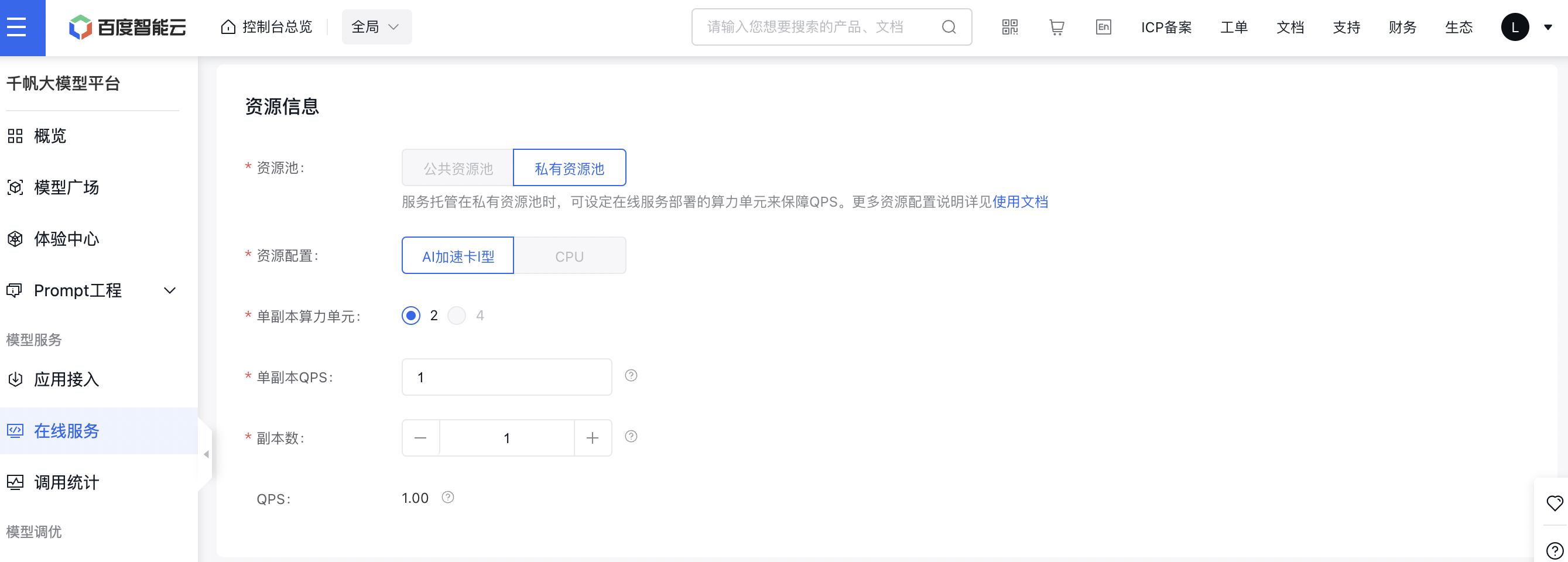
按下图流程完善服务部署,将服务部署至私有资源池。