
自动搜索作业代码编写规范
更新时间:2023-01-18
自动搜索作业代码编写规范
代码入参说明
自动搜索作业的实现过程:通过搜索算法获取多个超参数组合,每个组合都会通过训练得到一个评估结果,以此最终判断超参数组合的优劣,而用户编写的代码即是用于实现单次训练。
用户需要通过argparse模块接受在平台中填写的信息以及搜索算法反馈的超参数组合。

参数说明:
| 参数 | 说明 |
|---|---|
| train_dir/test_dir/output_dir | 用户在平台中填写的训练集路径、测试集路径、输出路径及其中的文件会同步到代码训练环境中,对应文件名称分别为argparse参数中的default默认值:trian_data/test_data/output,因此请用户切记不要修改这三处的default参数。 |
| job-id | 当前自动搜索作业的任务id,系统生成,用于构成输出路径的一部分 |
| trial-id | 任务中的每个试验都会拥有独立的试验id,argparse接受该参数用于构成模型输出路径的一部分。注:每个试验的模型保存路径为:output_dir/job-id/trial-id |
| metric | 接受用户在平台上填写的评价指标的名称 |
| data_sampling_scale | 接受用户在平台上填写的数据采样比例 |
其余用户自定义的待搜索的超参数同样需要写在argparse模块中,且名称与平台中填写的完全一致,每个试验运行时搜索算法会将参数值传入代码。
必要接口说明
自动搜索作业给予了用户极高的自由度,但仍然存在一些必须实现的接口,否则无法在平台中完成作业的训练,在编写代码前,请务必仔细阅读下面的几点说明。
- 代码入参说明中提到的argparse模块是必须实现的。
-
模型训练部分的代码,用户可以自定义实现,pytorch框架比较特殊,需要额外实现推理代码,见代码示例(链接到pytorch推理代码处),其余框架仅需要实现训练代码即可,平台为用户提供了推理代码用于预测,因此,模型保存的路径与格式,需要统一。
- 模型必须保存到args.output_dir/args.job-id/args.trial-id中,这也是为了方便用户最终选择需要的模型。
- 所有示例代码中main函数均是按照获取参数、加载数据集、模型定义、模型训练、模型保存、模型评估、上报结果的形式进行封装的,每种框架的模型保存方式在代码示例中的模型保存函数已经详细给出,特别注意,用户编写的模型保存函数的名称可以是自定义的,但必须将对应格式的模型保存到对应的路径下!
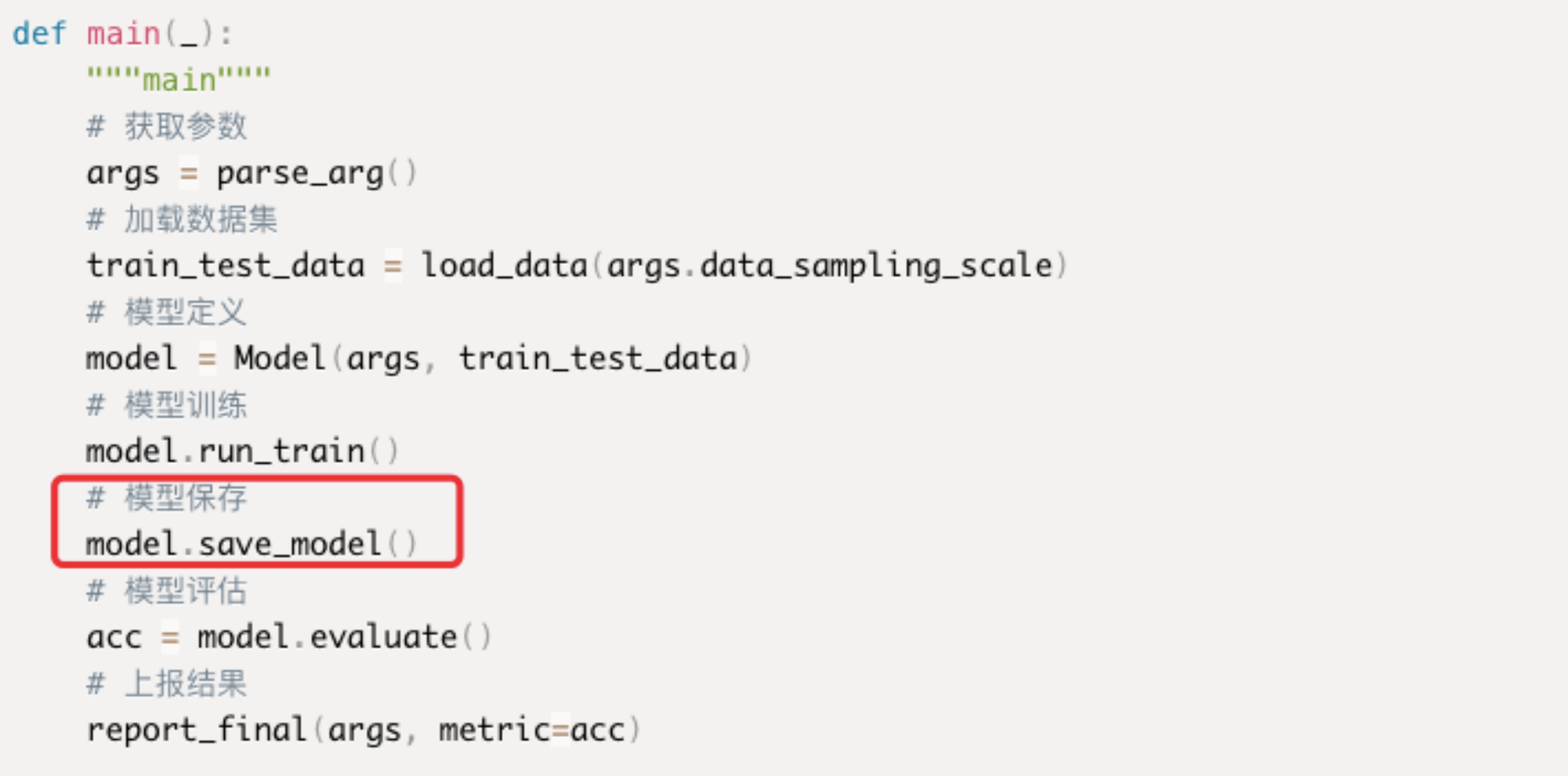
- 上报结果的函数实现:每次训练完成后,代码需要将评估结果汇报给搜索算法,用于下一个超参数组合的建议以及是否早停的判断。用户可以通过调用平台提供的SDK接口实现该功能:
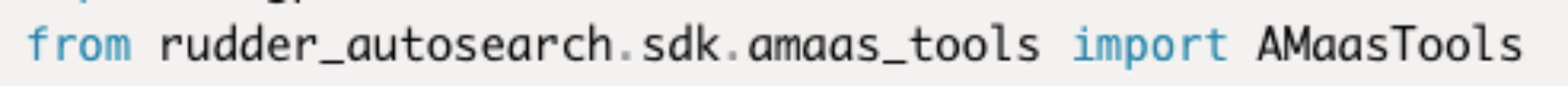
所有示例均是通过report_final函数实现结果的上报,传入的参数为args以及评估结果的值,函数内部结构建议用户不要做任何修改!上报结果实际上是调用的AMaasTools的report_final_result函数,如下为函数入参说明: metric:评价指标以字典的形式传入。 export_model_path:保存模型文件的文件夹路径,2中已经进行了说明 * checkpoint_path:模型的权重,该参数一般设为空字符,只有当搜索算法选择进化算法PBT时,才会使用,该算法每次试验前会用到其余试验的模型权重,因此每次模型训练完需要将权重保存路径进行上传,见4小点。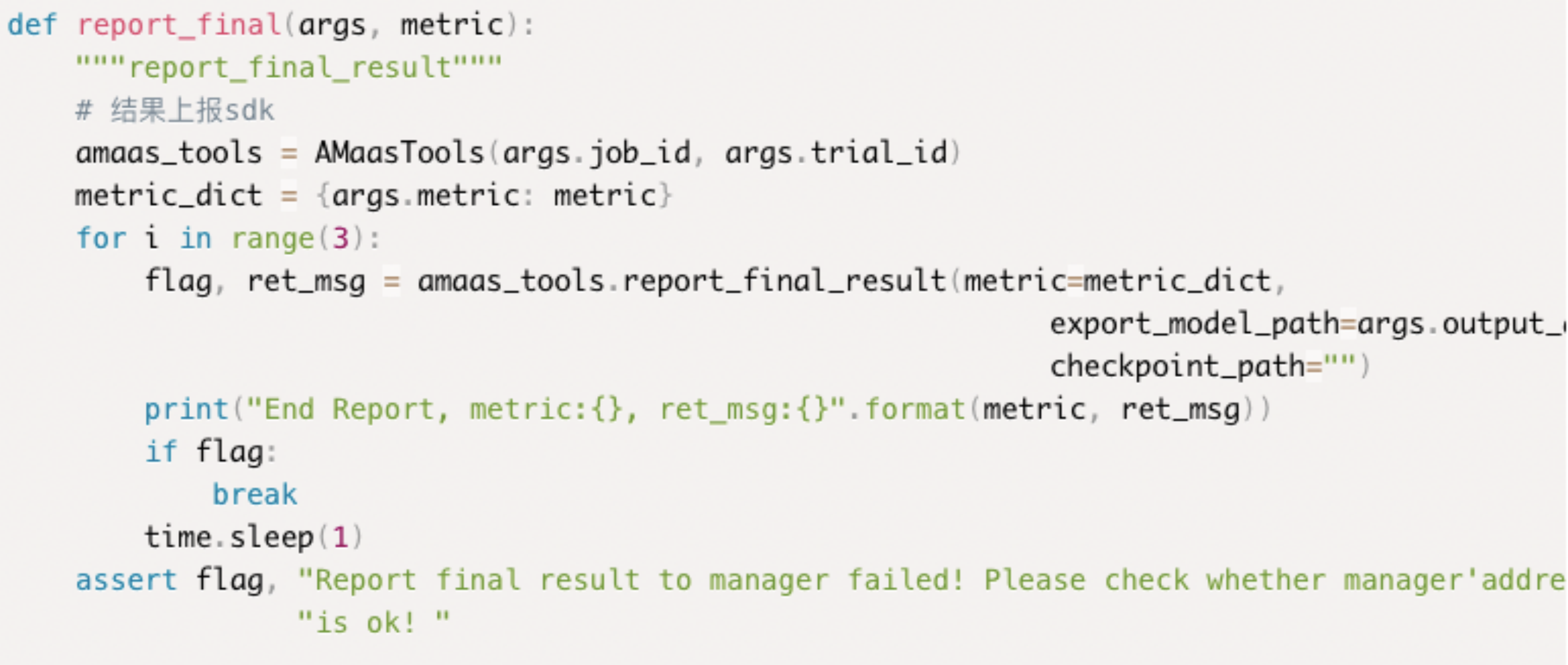
-
进化算法PBT:该搜索算法专门用于深度学习,详情见搜索算法简介,当采用该算法时,需要在代码中提供接受之前试验权重的接口,代码示例中的pytorch框架就是采用了进化算法PBT的搜索算法,点击这里查看,如下是PBT算法的关键步骤:
- 首先在argparse模块中需要新增resume_checkpoint_path参数,在训练时,系统会传入之前试验的模型文件路径,如果该试验属于随机初始化的第一个批次,则会传入空字符。用户只需添加该参数,具体传入内容由搜索算法决定。

- 接着需要实现模型加载的函数,从传入的模型路径中加载模型,从而实现继承之前试验中的模型权重的功能。

- 下图为结果上报函数,checkpoint_path处不再是空字符,而是模型文件的保存路径。注意:export_model_path需要传入的是模型所在的文件夹路径,而checkpoint_path是模型文件的路径!
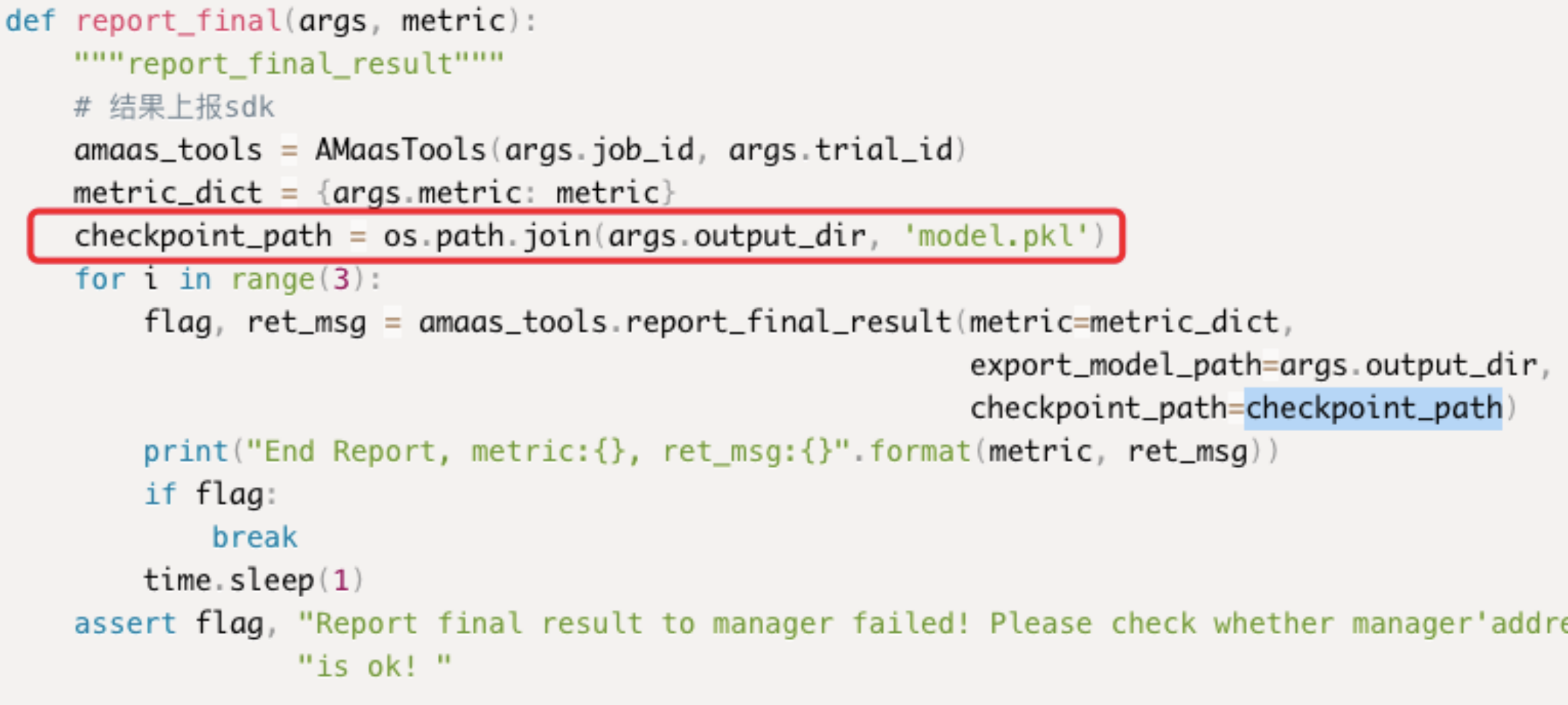
- 首先在argparse模块中需要新增resume_checkpoint_path参数,在训练时,系统会传入之前试验的模型文件路径,如果该试验属于随机初始化的第一个批次,则会传入空字符。用户只需添加该参数,具体传入内容由搜索算法决定。