
在BML平台使用并行文件系统PFS和对象存储BOS
更新时间:2023-07-11
在BML平台使用并行文件系统PFS
平台支持用户在用户资源池上关联并行文件存储PFS作为建模任务时的数据存储,当前支持使用并行文件系统PFS提交的任务:
- 自定义作业-训练作业任务、自动搜索作业任务
前提条件
- 用户在平台上已经挂载了容器引擎CCE资源作为用户资源池,点击了解容器引擎CCE;

- 用户已经创建了并行文件系统PFS,点击了解并行文件系统PFS。
- 并行文件系统PFS能够被容器引擎CCE资源访问到,也即能被对应的VPC访问到。
在用户资源池中挂载PFS实例
- Step1:进入平台管理-资源池管理,已挂载运行正常的用户资源池支持“挂载PFS”的操作项,点击即可选择挂载的PFS实例。

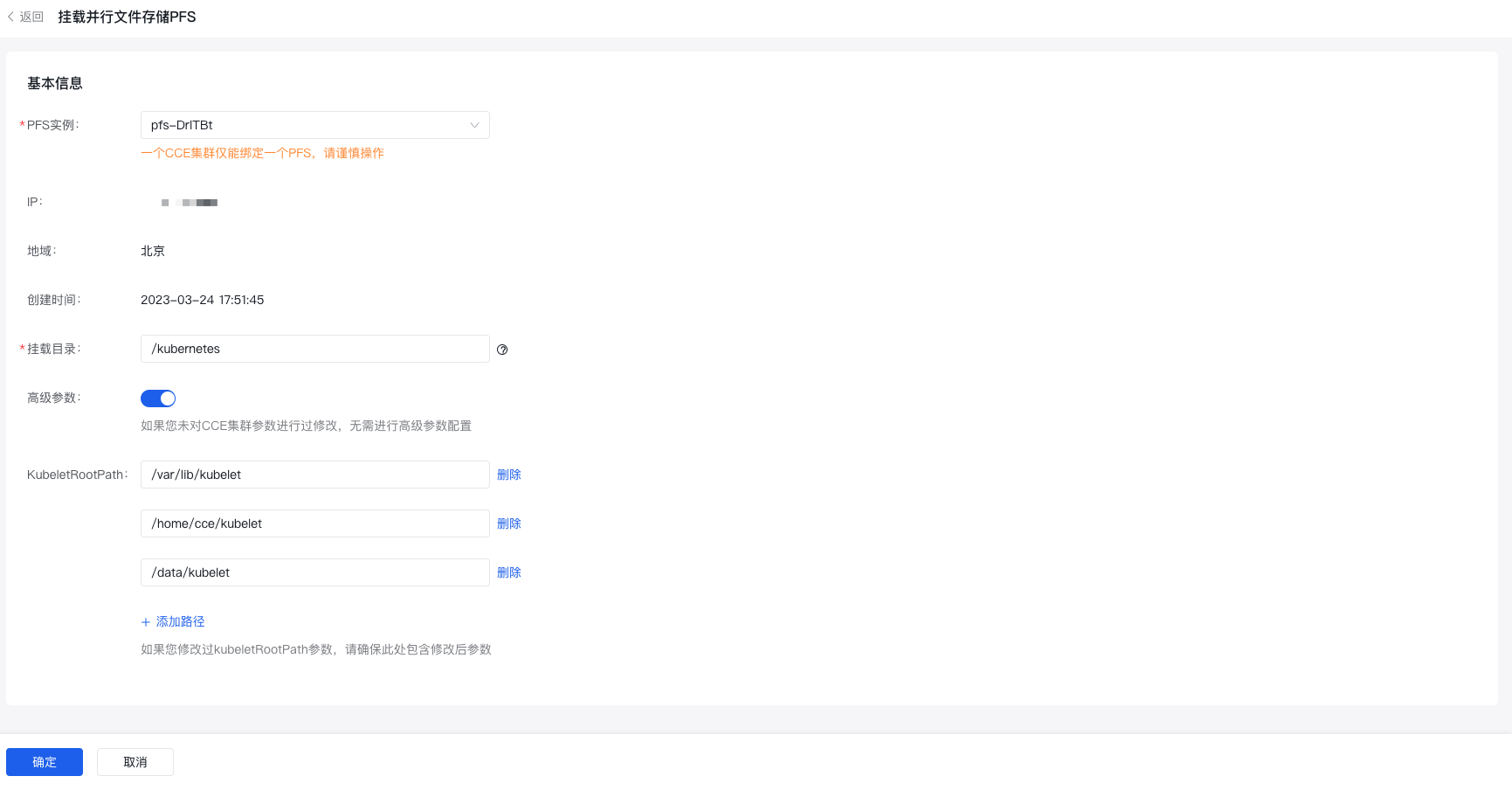
- Step2:完成引入PFS后,支持点击“查看PFS”,并支持卸载操作。


使用PFS作为数据来源提交作业建模任务
在提交作业建模任务时,选择用户资源池后,支持选择该资源池中引入的BOS存储或者PFS存储作为数据来源。
挂载数据和编辑代码时需要注意:平台仅能使用挂载路径下的文件,请确保您的相关文件在此挂载路径之下。
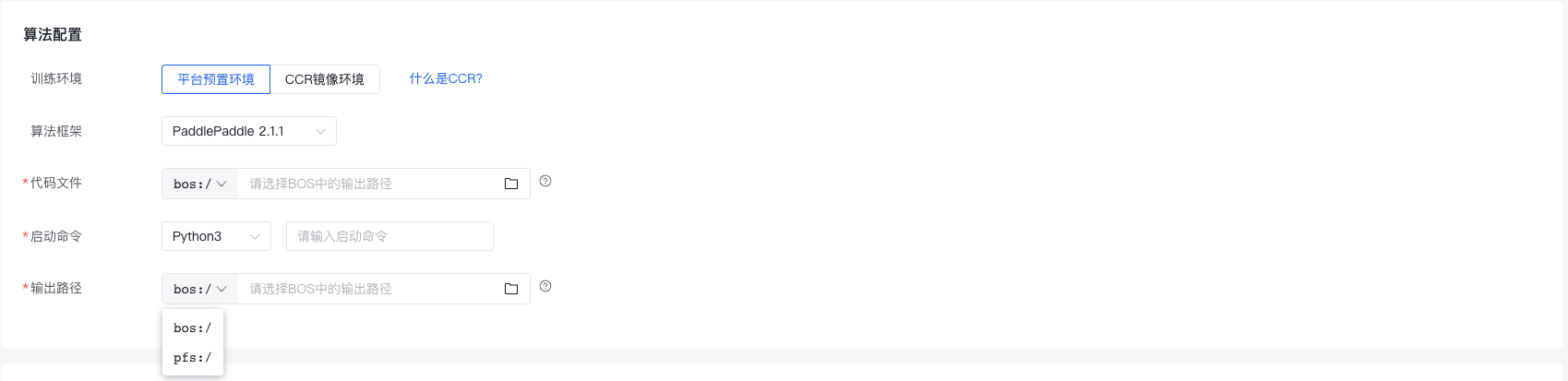
操作及代码示例
前提条件
平台上的用户资源池已经成功挂载PFS。
操作
依次点击 自定义作业 -> 训练作业 -> 新建
选择了用户资源池之后,算法配置信息填写如下:

以代码文件为例: 找到机器中pfs的挂载点,将代码及数据集上传到pfs挂载中,代码文件中只需要填写基于挂载路径的相对路径即可。

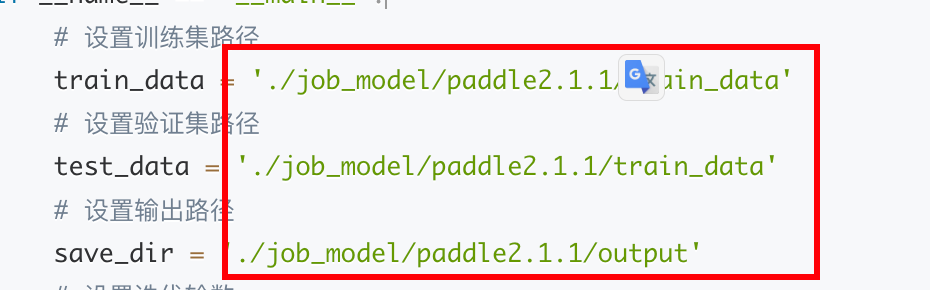
demo2.py内容附后, 为官网提供的多节点paddle2.1.1的demo案例,我们只需要修改输出路径为pfs中基于挂载路径的相对路径即可。
代码示例
Plain Text
1#!/usr/bin/env python
2# -*- coding: utf-8 -*-
3"""
4"""
5import os
6import gzip
7import struct
8import numpy as np
9from PIL import Image
10import time
11import paddle
12import paddle.distributed.fleet as fleet
13import paddle.static.nn as nn
14import paddle.fluid as fluid
15from paddle.io import Dataset
16TEST_IMAGE = 't10k-images-idx3-ubyte.gz'
17TEST_LABEL = 't10k-labels-idx1-ubyte.gz'
18TRAIN_IMAGE = 'train-images-idx3-ubyte.gz'
19TRAIN_LABEL = 'train-labels-idx1-ubyte.gz'
20class MNIST(Dataset):
21 """
22 MNIST
23 """
24 def __init__(self,
25 data_dir=None,
26 mode='train',
27 transform=None,
28 backend=None):
29 assert mode.lower() in ['train', 'test'], "mode should be 'train' or 'test', but got {}".format(mode)
30 if backend is None:
31 backend = paddle.vision.get_image_backend()
32 if backend not in ['pil', 'cv2']:
33 raise ValueError(
34 "Expected backend are one of ['pil', 'cv2'], but got {}"
35 .format(backend))
36 self.backend = backend
37 self.mode = mode.lower()
38 if self.mode == 'train':
39 self.image_path = os.path.join(data_dir, TRAIN_IMAGE)
40 self.label_path = os.path.join(data_dir, TRAIN_LABEL)
41 else:
42 self.image_path = os.path.join(data_dir, TEST_IMAGE)
43 self.label_path = os.path.join(data_dir, TEST_LABEL)
44 self.transform = transform
45 # read dataset into memory
46 self._parse_dataset()
47 self.dtype = paddle.get_default_dtype()
48 def _parse_dataset(self, buffer_size=100):
49 self.images = []
50 self.labels = []
51 with gzip.GzipFile(self.image_path, 'rb') as image_file:
52 img_buf = image_file.read()
53 with gzip.GzipFile(self.label_path, 'rb') as label_file:
54 lab_buf = label_file.read()
55 step_label = 0
56 offset_img = 0
57 # read from Big-endian
58 # get file info from magic byte
59 # image file : 16B
60 magic_byte_img = '>IIII'
61 magic_img, image_num, rows, cols = struct.unpack_from(
62 magic_byte_img, img_buf, offset_img)
63 offset_img += struct.calcsize(magic_byte_img)
64 offset_lab = 0
65 # label file : 8B
66 magic_byte_lab = '>II'
67 magic_lab, label_num = struct.unpack_from(magic_byte_lab,
68 lab_buf, offset_lab)
69 offset_lab += struct.calcsize(magic_byte_lab)
70 while True:
71 if step_label >= label_num:
72 break
73 fmt_label = '>' + str(buffer_size) + 'B'
74 labels = struct.unpack_from(fmt_label, lab_buf, offset_lab)
75 offset_lab += struct.calcsize(fmt_label)
76 step_label += buffer_size
77 fmt_images = '>' + str(buffer_size * rows * cols) + 'B'
78 images_temp = struct.unpack_from(fmt_images, img_buf,
79 offset_img)
80 images = np.reshape(images_temp, (buffer_size, rows *
81 cols)).astype('float32')
82 offset_img += struct.calcsize(fmt_images)
83 for i in range(buffer_size):
84 self.images.append(images[i, :])
85 self.labels.append(
86 np.array([labels[i]]).astype('int64'))
87 def __getitem__(self, idx):
88 image, label = self.images[idx], self.labels[idx]
89 image = np.reshape(image, [28, 28])
90 if self.backend == 'pil':
91 image = Image.fromarray(image.astype('uint8'), mode='L')
92 if self.transform is not None:
93 image = self.transform(image)
94 if self.backend == 'pil':
95 return image, label.astype('int64')
96 return image.astype(self.dtype), label.astype('int64')
97 def __len__(self):
98 return len(self.labels)
99def mlp_model():
100 """
101 mlp_model
102 """
103 x = paddle.static.data(name="x", shape=[64, 28, 28], dtype='float32')
104 y = paddle.static.data(name="y", shape=[64, 1], dtype='int64')
105 x_flatten = paddle.reshape(x, [64, 784])
106 fc_1 = nn.fc(x=x_flatten, size=128, activation='tanh')
107 fc_2 = nn.fc(x=fc_1, size=128, activation='tanh')
108 prediction = nn.fc(x=[fc_2], size=10, activation='softmax')
109 cost = paddle.fluid.layers.cross_entropy(input=prediction, label=y)
110 acc_top1 = paddle.metric.accuracy(input=prediction, label=y, k=1)
111 avg_cost = paddle.mean(x=cost)
112 res = [x, y, prediction, avg_cost, acc_top1]
113 return res
114def train(epoch, exe, train_dataloader, cost, acc):
115 """
116 train
117 """
118 total_time = 0
119 step = 0
120 for data in train_dataloader():
121 step += 1
122 start_time = time.time()
123 loss_val, acc_val = exe.run(
124 paddle.static.default_main_program(),
125 feed=data, fetch_list=[cost.name, acc.name])
126 if step % 100 == 0:
127 end_time = time.time()
128 total_time += (end_time - start_time)
129 print(
130 "epoch: %d, step:%d, train_loss: %f, train_acc: %f, total time cost = %f, speed: %f"
131 % (epoch, step, loss_val[0], acc_val[0], total_time,
132 1 / (end_time - start_time) ))
133def test(exe, test_dataloader, cost, acc):
134 """
135 test
136 """
137 total_time = 0
138 step = 0
139 for data in test_dataloader():
140 step += 1
141 start_time = time.time()
142 loss_val, acc_val = exe.run(
143 paddle.static.default_main_program(),
144 feed=data, fetch_list=[cost.name, acc.name])
145 if step % 100 == 0:
146 end_time = time.time()
147 total_time += (end_time - start_time)
148 print(
149 "step:%d, test_loss: %f, test_acc: %f, total time cost = %f, speed: %f"
150 % (step, loss_val[0], acc_val[0], total_time,
151 1 / (end_time - start_time) ))
152def save(save_dir, feed_vars, fetch_vars, exe):
153 """
154 save
155 """
156 path_prefix = os.path.join(save_dir, 'model')
157 if fleet.is_first_worker():
158 paddle.static.save_inference_model(path_prefix, feed_vars, fetch_vars, exe)
159if __name__ == '__main__':
160 # 设置训练集路径
161 train_data = './job_model/paddle2.1.1/train_data'
162 # 设置验证集路径
163 test_data = './job_model/paddle2.1.1/train_data'
164 # 设置输出路径
165 save_dir = './job_model/paddle2.1.1/output'
166 # 设置迭代轮数
167 epochs = 10
168 # 设置验证间隔轮数
169 test_interval = 2
170 # 设置模型保存间隔轮数
171 save_interval = 2
172 paddle.enable_static()
173 paddle.vision.set_image_backend('cv2')
174 # 训练数据集
175 train_dataset = MNIST(data_dir=train_data, mode='train')
176 # 验证数据集
177 test_dataset = MNIST(data_dir=test_data, mode='test')
178 # 设置模型
179 [x, y, pred, cost, acc] = mlp_model()
180 place = paddle.CUDAPlace(int(os.environ.get('FLAGS_selected_gpus', 0)))
181 # 数据加载
182 train_dataloader = paddle.io.DataLoader(
183 train_dataset, feed_list=[x, y], drop_last=True,
184 places=place, batch_size=64, shuffle=True, return_list=False)
185 test_dataloader = paddle.io.DataLoader(
186 test_dataset, feed_list=[x, y], drop_last=True,
187 places=place, batch_size=64, return_list=False)
188 # fleet初始化
189 strategy = fleet.DistributedStrategy()
190 fleet.init(is_collective=True, strategy=strategy)
191 # 设置优化器
192 optimizer = paddle.optimizer.Adam()
193 optimizer = fleet.distributed_optimizer(optimizer)
194 optimizer.minimize(cost)
195 exe = paddle.static.Executor(place)
196 exe.run(paddle.static.default_startup_program())
197 prog = paddle.static.default_main_program()
198 for epoch in range(epochs):
199 train(epoch, exe, train_dataloader, cost, acc)
200 if epoch % test_interval == 0:
201 test(exe, test_dataloader, cost, acc)
202 # save model
203 if epoch % save_interval == 0:
204 save(save_dir, [x], [pred], exe)资源配置 (依据代码情况填写即可,上文中的案例用到了多节点和GPU资源)
