
配置视觉任务
更新时间:2023-01-18
配置训练集及评测集
配置训练集
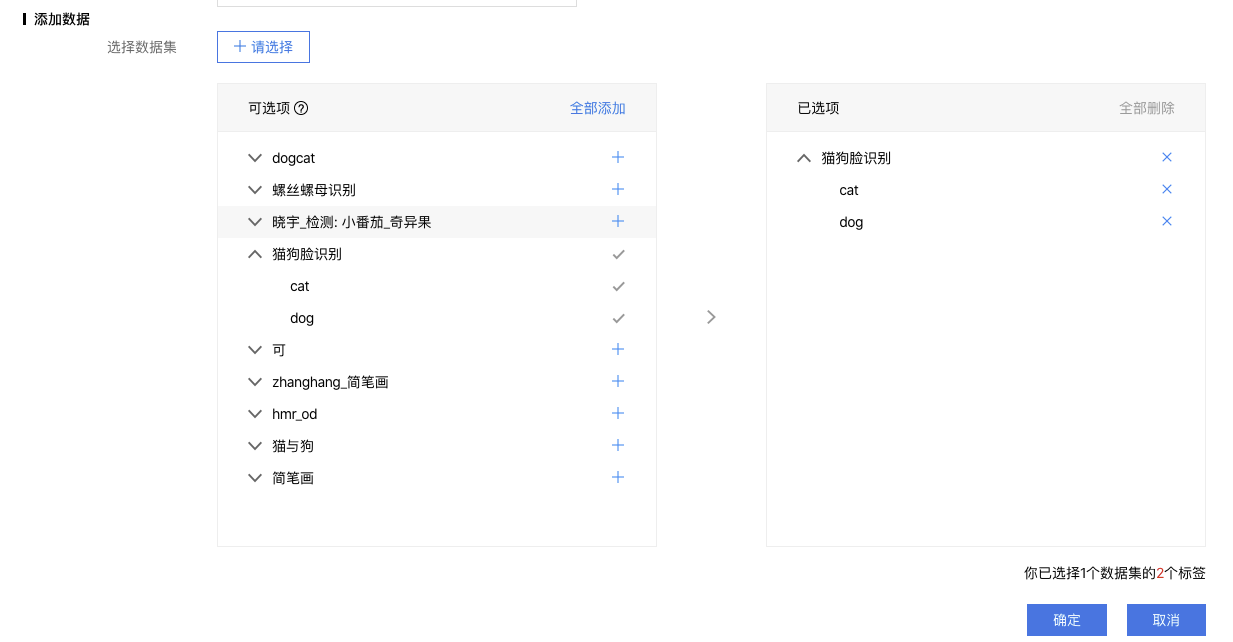
在添加任务备注后,在添加数据的位置选择添加训练集。
可选的数据集要求如下:
- 数据集标注类型与项目类型一致,如同为图像分类-单图单标签/物体检测-矩形框标注等
- 数据集数据量不为0;
- 数据集状态非智能标注中,非导入中
数据集状态支持导入多个数据集的多个标签,如果选择标签名称一致,则相应数据内容会被合并。 当一个项目新建了多个任务类型进行迭代训练时,训练数据会默认为最近一次训练版本所选的数据,如果标签不变仅每个标签下的标注数据发生变化,或者配置脚本内容发生变化,则数据的部分可以不做任何操作。
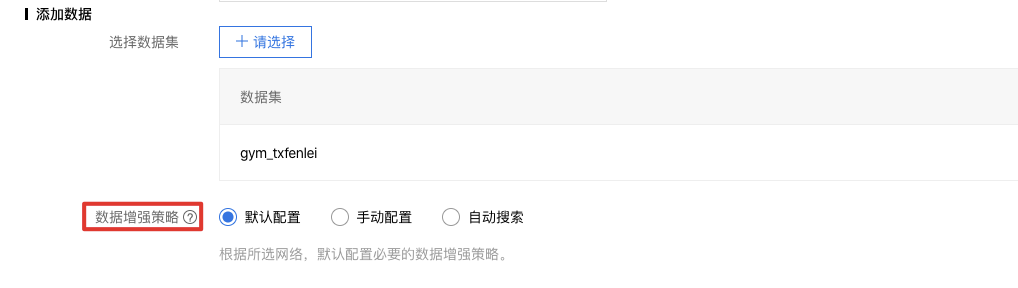
配置数据增强策略
在配置完训练集之后,紧接着就可以配置数据增强策略。
深度学习模型的成功很大程度上要归功于大量的标注数据集。通常来说,通过增加数据的数量和多样性往往能提升模型的效果。当在实践中无法收集到数目庞大的高质量数据时,可以通过配置数据增强策略,对数据本身进行一定程度的扰动从而产生"新"数据。模型会通过学习大量的"新"数据,提高泛化能力。
你可以在「默认配置」、「手动配置」、「自动搜索」三个选项进行选择,完成数据增强策略的配置。
配置评测集
评测集为非必选项,如果额外上传一批非在训练集的数据作为评测集,可在模型训练完毕后单独获得额外评测集的测试效果。其中评测集的标签需要与训练集所选标签完全一致,否则将无法启动训练任务。
配置脚本注意事项
说明:BML目前支持飞桨(Paddle Paddle)深度学习框架 了解飞桨
目前BML为每一种预训练模型都预置了脚本代码,在不需要修改的情况下可直接启动训练。
自定义脚本内容过程中有如下注意事项:
- 可以自定义的部分包括超参配置字典conf和模型头部网络定义函数create_model。主体网络(含预训练参数)在页面可选。
- 超参配置conf包括可调的超参,比如训练轮数epoch,其类型和范围见注释。不要随意设置否则可能会训练失败,比如batch size太大,可能导致显存不够而失败。
- 超参配置conf不需要设置类别数,这是通过数据集推断出来的。
- 函数create_model完成头部网络定义,输出要求是一个字典,其中包括'loss'和'infer_out'两个key,'loss'是网络损失,'infer_out'是预测输出。如果修改有误可能会导致训练失败。
- 在分类任务中,请保证infer_out的Tensor形状是BatchSize x ClassNumber
- 在检测任务中,请保证infer_out的LodTensor形状是 BoxNumber x 6,其中每行是(label, confidence, xmin, ymin, xmax, ymax)
- conf中如果有可供配置的模型结构参数,请阅读相关注释或链接后再行修改,随意设置可能会导致训练失败或训练精度异常。