
AIAK- Training Pytorch版
更新时间:2024-02-04
AIAK-Training 简介
AI 加速套件AI Accelerate Kit是基于百度云 IAAS 资源推出的 AI 加速能力,可用来加速基于 PyTorch 等深度学习框架的 AI 应用,详情可进一步查看 AI加速套件-AIAK 简介。
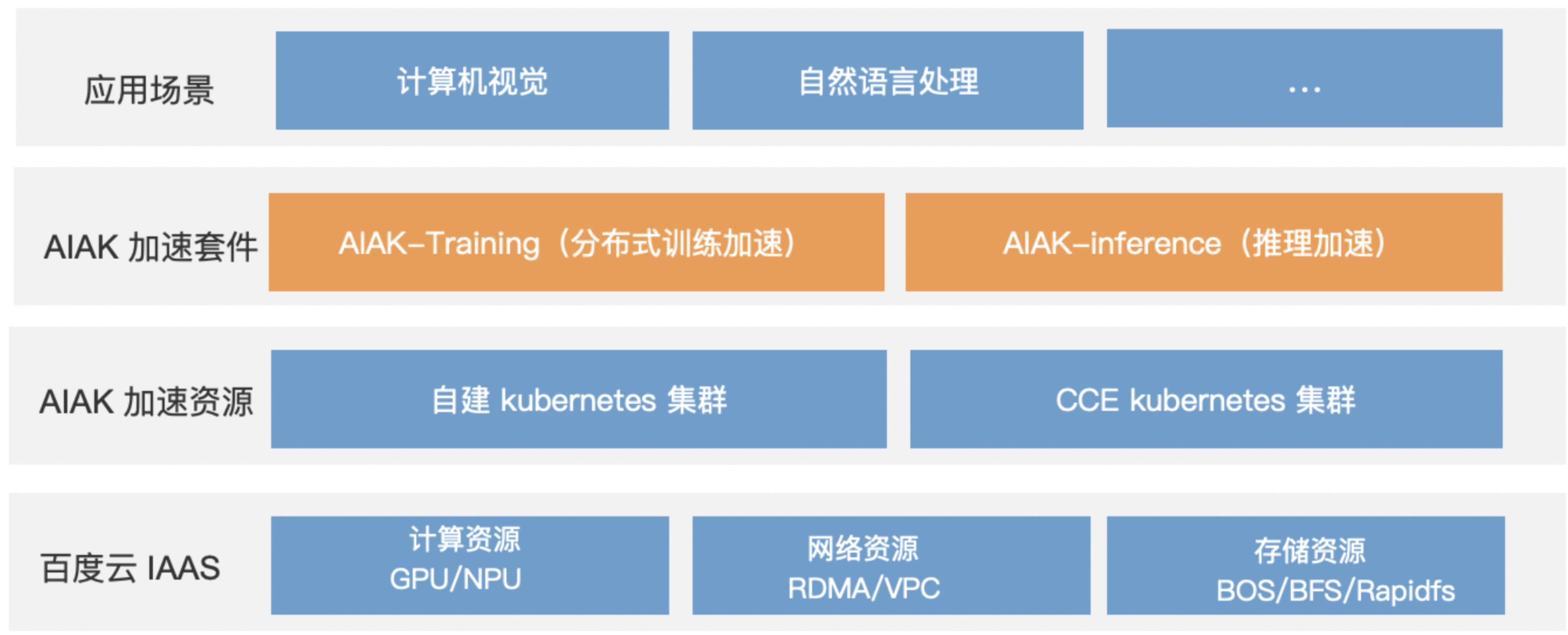
应用场景
AIAK-Training PyTorch版主要适用于计算机视觉模型,例如:Swin Transformer、Faster R-CNN、Mask R-CNN、YOLOV7、STDC等。
使用示例
1. 创建训练任务
选择PyTorch下的AIAK-Training镜像,并指定模型网络代码文件、数据集文件、输出文件等各自的BOS存储路径。
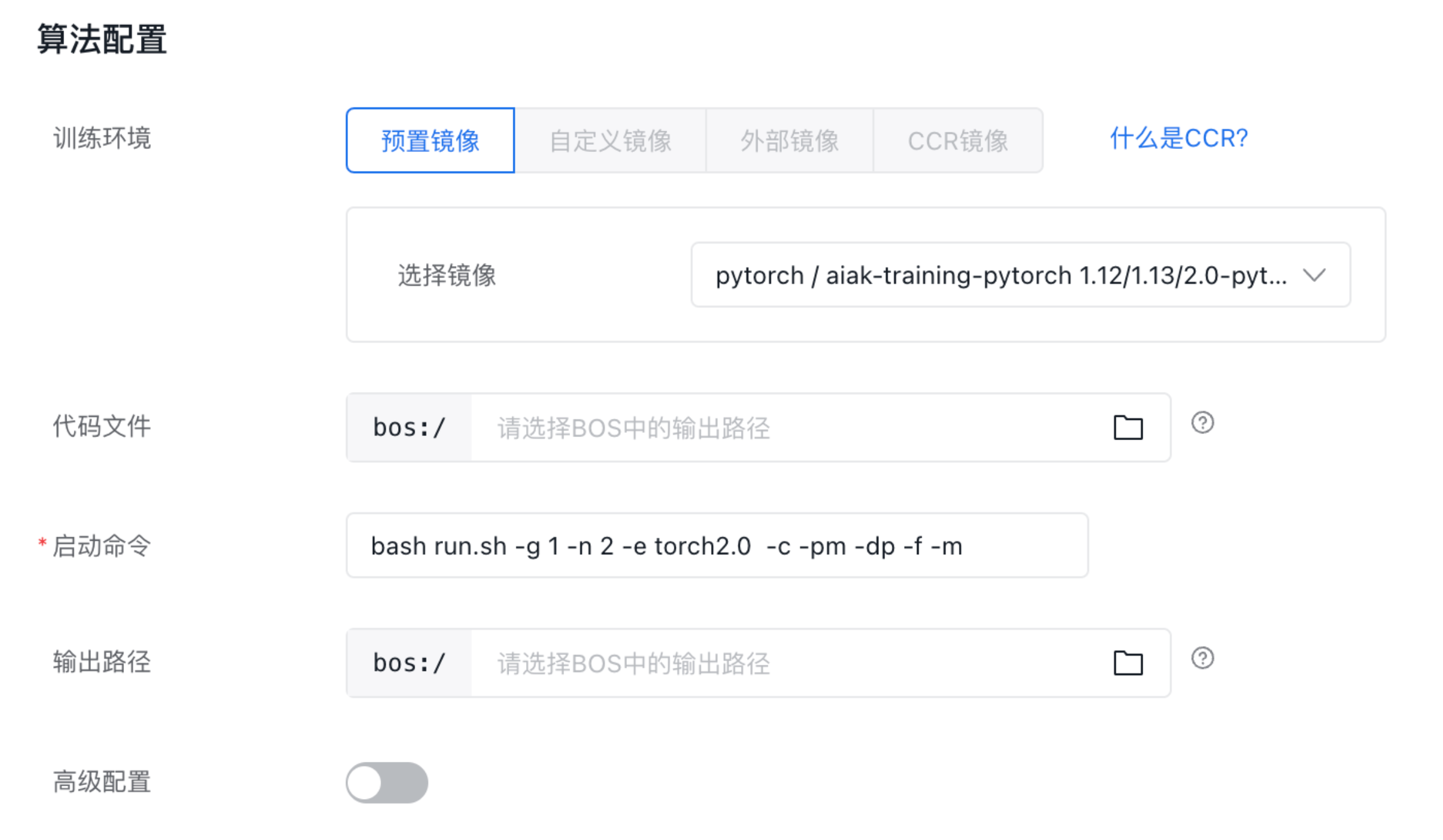
在输入启动命令时,通过传入约定参数来开启AIAK-Training的训练加速能力,以下为单机/多机场景下的启动命令示例。
Plain Text
1单机-不加速(1节点、1GPU):bash run.sh -g 1 -e torch2.0
2单机-AIAK-Training加速(1节点、1GPU):bash run.sh -g 1 -e torch2.0 -c -pm -dp -f -m
3多机-仅常规加速(2节点、2GPU):bash run.sh -g 1 -n 2 -e torch2.0
4多机-AIAK-Training加速(2节点、2GPU):bash run.sh -g 1 -n 2 -e torch2.0 -c -pm -dp -f -m参数含义如下:
Plain Text
1 -e)
2 TRAIN_CONDA_ENV=$2;
3 选择conda环境版本,目前可支持torch2.0、torch1.12、torch1.13,默认base环境不支持训练。
4 -i)
5 RANK=$2;
6 单机训练默认为0,多机训练默认为0,1,2……
7 如两机训练:第一台机器执行脚本时此参数为0,第二台机器执行脚本时此参数为1
8 -g)
9 GPUS=$2;
10 每台机器上的GPU卡数
11 -n)
12 NNODES=$2;
13 总节点数,单机训练为1,两机训练为2等等
14 -p)
15 MASTER_PORT=$2;
16 master节点的端口
17 -h)
18 MASTER_ADDR=$2;
19 master节点的地址
20 -c)
21 CHANNEL_LAST="--use_channel_last";
22 减少 nchw -> nhwc 转换的开销
23 -pm)
24 PIN_MEMORY="--use_pin_memory";
25 加速 H2D
26 -dp)
27 DATA_PREFETCH="--use_data_prefetch";
28 实现H2D和前向计算overlap,缩短训练耗时
29 -f)
30 FUSED_OPTIMIZER="--fused_optimizer";
31 通过算子融合,加速参数更新
32 -m)
33 MULTI_EPOCHS_LOADER="--use_multi_epochs_loader";
34 跨epoch dataloader优化
35 -a)
36 AFFINITY="--set_affinity";
37 实现CPU-GPU的亲和性绑定,消除跨numa传输带来的带宽损耗
38 -flb)
39 FUSED_LINEAR_BIAS="--use_fused_linear";
40 算子融合策略,支持 Module算子替换,减少kernel launch的时间
41 -fln)
42 FUSED_LAYERNORM="--use_fused_layernorm";
43 算子融合策略,支持 Module算子替换,减少kernel launch的时间
44 -d)
45 DYNAMO="--use-dynamo";
46 适用于PyTorch2.0的加速特性2. 提交训练任务
选择运行环境,并按需配置计算节点数,提交训练任务。 训练完成后,通过训练任务的训练耗时或训练吞吐量对比,可对比AIAK-Training镜像所带来的训练加速效果提升。