配置专家模式表格数据预测任务
更新时间:2023-01-18
表格预测任务支持AutoML和专家两种运行方式:
- AutoML模式:全流程自动建模,用户只需设置数据集、目标列以及制定任务类型即可,而无需关注数据处理以及算法配置等过程,系统会自动完成建模过程,并从中挑选最优的模型作为训练任务的运行结果。
- 专家模式:高度开放的建模方式,用户可以进行特征工程、算法、超参搜索等配置,具备相关技能的开发者可以在方式下获得更多的开发自由度。
创建专家建模任务
操作场景
以iris数据集为例,创建多分类模型,iris数据集示例如下:
Plain Text
1sepal_length,sepal_width,petal_length,petal_width,species
2
35.1,3.5,1.4,0.2,setosa
4
54.9,3.0,1.4,0.2,setosa
6
74.7,3.2,1.3,0.2,setosa
8
94.6,3.1,1.5,0.2,setosa前提条件
在创建表格预测任务前,需满足如下条件:
- 必须已成功创建“表格”类数据,数据集导入状态为“已完成”
- 数据集中行数必须大于0,即必须是非空数据集
操作步骤
- 在BML操作台的左侧导航菜单上单击“脚本调参”,进入脚本调参列表页面。
-
单击已创建的“iris分类”所在行的“新建任务”,进入“新建任务”页面。
配置参数如下所示:
-
基本信息
- 开发方式:选择专家模式
- 训练方式:支持单机和分布式两种模式,单击模式支持更多的算法。
- 任务备注:请根据实际情况填写,详细的配置说明可以参考初始化脚本头部的注释内容。
-
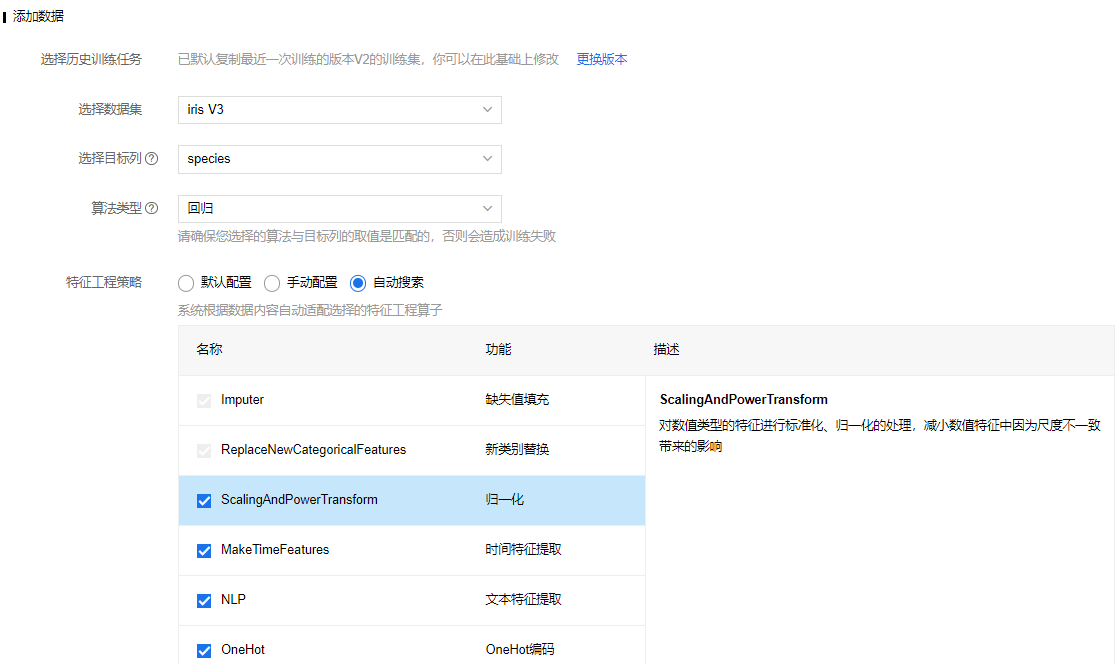
添加数据
- 选择数据集:选择已创建的iris数据集
- 选择目标列:设置为species
- 算法类型:设置为“多分类”
-
特征工程策略:
- 默认配置:执行系统默认的特征工程策略
- 手动配置:用户可以手工配置各个特征工程算子的执行参数从而控制其执行方式
- 自动搜索:用户可以选择要使用那些特征工程算子,系统会自动搜索并完成用户选择的特征工程算子的配置。
-
配置任务
- 系统会根据用户选择的训练方式以及算法类型自动生成任务脚本,在不需要修改的情况下可直接启动训练。
-
自定义脚本内容过程中有如下注意事项:
- 可以自定义的部分为超参配置字典conf部分,包括是否开启超参搜索,训练模型类型和模型配置,具体见脚本中的注释
- 训练默认开启自动超参搜索,如需关闭请手动将"hyperparameter_tune"的参数值由"True"更改为"False"
- BML当前表格数据预测支持模型为CAT(CatBoost), LGBM(LightGBM),RF(RandomForest), LR(Logistic Regression), XGB(Xgboost), KNN(k-NearestNeighbor)
- 在"hp_space"中已经预置可搜索的超参数,用户无需修改参数名称,随意设置可能会导致训练失败
- 在超参搜索范围内的取值方式支持:平均采样(uniform),非平均采样(quniform), 离散值(choice), 对数平均采样(loguniform),随机整数(randint)五种,超参搜索范围设置过大可能会导致训练时间过长。
-
CAT模型支持搜索的超参数,已经预置默认搜索范围,详见脚本内容
超参数 说明 depth 决策树的深度 iterations 最大树数 learning_rate 学习率,控制机器学习网络的学习速度,学习率越低,损失函数的 变化速度就越慢,反之亦然 l2_leaf_reg L2正则项,防止模型过拟合 border_count numerical features的分割数 -
LGBM模型支持搜索的超参数,已经预置默认搜索范围,详见脚本内容
超参数 说明 num_leaves 决策树的叶子数 boosting_type boosting参数的类型,默认包含"rf", "gbdt", "dart", "goss" n_estimators 对原始数据集进行有放回抽样生成的子数据集个数,即决策树的个 数,n_estimators太小,容易欠拟合,n_estimators太大,计算量会太大 max_depth 决策树最大深度 subsample 每棵树随机采样的比例 learning_rate 学习率 colsample_bytree 每棵随机采样的列数的占比(每一列是一个特征) reg_alpha L1正则项,防止模型过拟合 reg_lambda L2正则项,防止模型过拟合 -
RF模型支持搜索的超参数,已经预置默认搜索范围,详见脚本内容
超参数 说明 n_estimators 对原始数据集进行有放回抽样生成的子数据集个数,即决策树的个 数,n_estimators太小,容易欠拟合,n_estimators太大,计算量会太大 max_features 随机森林允许单个决策树使用特征的最大数量 max_depth 决策树最大深度 min_samples_split 节点可分的最小样本数,少于该数值次叶子节点不再可分 min_samples_leaf 叶子节点上应有的最少样例数,样例数量不符合则不能构成一个叶子节点 bootstrap 是否对样本集进行有放回抽样来构建树
-
发布模型
- 自动发布-开:即完成训练后,系统会自动将当前任务得到的模型发布到模型仓库中
- 自动发布-关:完成训练后,用户可以根据模型精度等再决定是否将模型发布到模型仓库
-
配置资源
- 运行环境:请根据数据量以及期望的运行速度进行设置。根据经验值,在建模过程中,数据会在内存中膨胀为原始大小的10倍,为保证任务顺利完成,请尽量确保配置的资源的内存不小于原始数据集的10倍。
- 选择节点数:只有选择的“分布式”的训练方式才可以设置为大于1的值。
- 最长训练时间:该时长指算法求解阶段的最长时长,若超过该时长,算法仍未得到结果,系统会强制结束训练任务。
配置示例如下所示:
-
基本信息部分:
-
添加数据部分:
-
-
单击“提交训练任务”,开始执行模型训练。
提交任务后可以在任务列表中查看任务的执行状态。