
快速入门
本文以信用卡诈骗场景为例,帮助您快速构建可视化建模实验。
数据准备
本例所采用的Credit card fraud( https://www.kaggle.com/mlg-ulb/creditcardfraud) 数据集包含 2013 年九月欧洲的信用卡持有者的交易记录,交易次数共有 284807 次,其中的 492 次为诈骗交易。该数据集多用于金融领域,建模的目的是检测信用卡欺诈行为。
- 进入“数据集 > 项目数据集“菜单,新建creditcard数据集,上传数据。
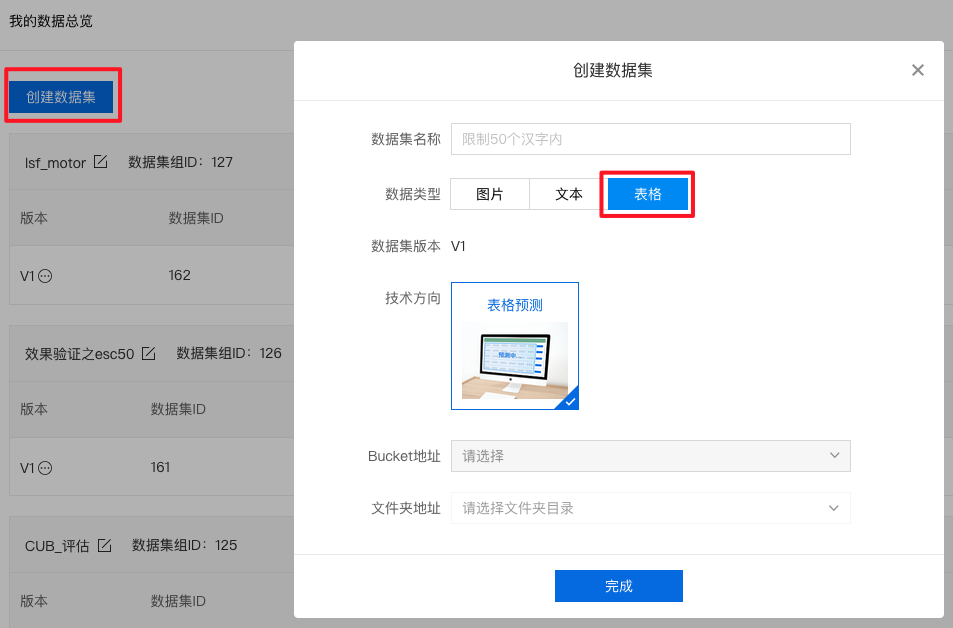
- 数据集上传成功后,可点进数据集名称,查看数据表详情。数据表中包含V1-V28特征列(经PCA处理)、Time列(表示数据集中每个交易和第一个交易之间经过的秒数)、Amount列(表示交易金额) 和 Class列(在发生欺诈时其值为1,否则为0)。
创建实验
进入“模型开发 > 可视化建模”页面,新建实验。

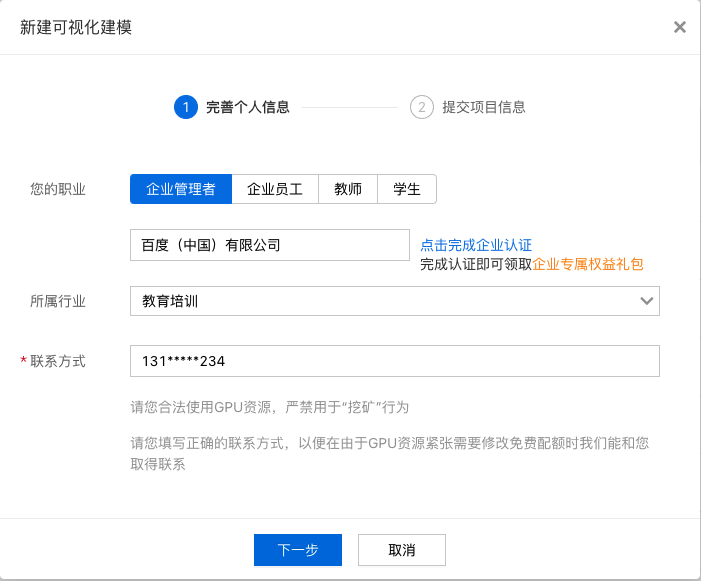
完善个人信息。
填写项目信息。
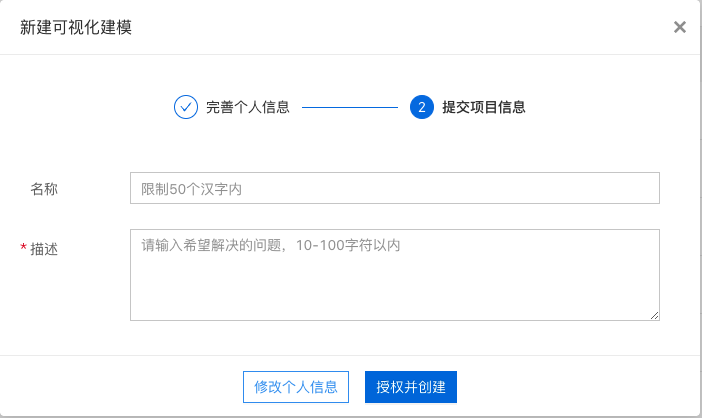
完成创建,并生成一条记录。
训练模型
- 进入实验详情,从左侧组件面板拖拽下列组件,拼接实验。
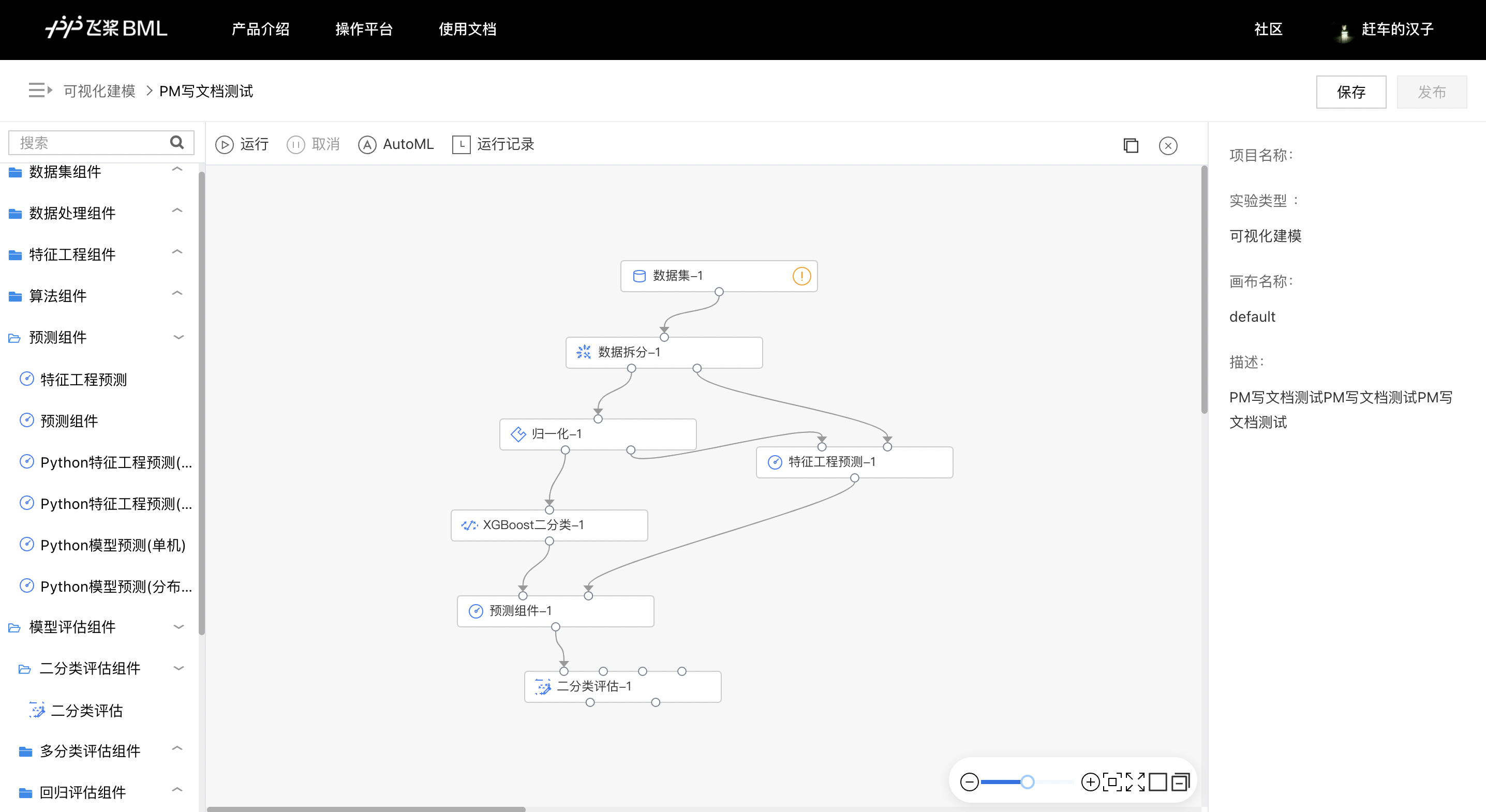
各算子组件的配置详情如下:
数据集
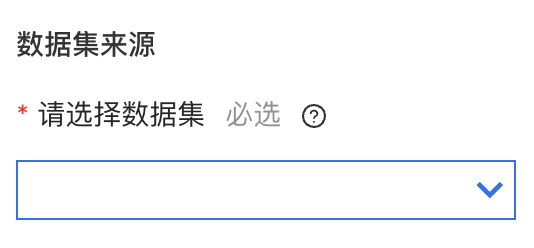
拖拽“数据集”组件到画布中。在右侧的“字段设置”配置区,选择creditcard数据集。
数据拆分
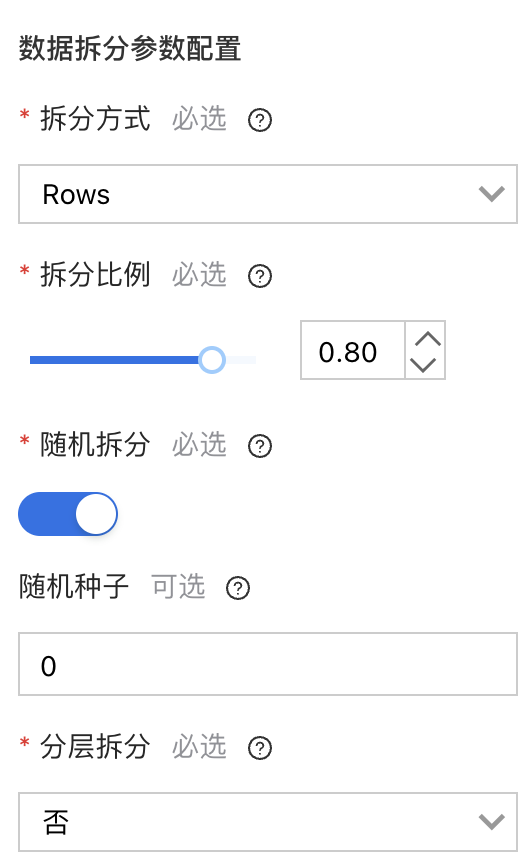
拖拽“数据拆分”组件,将数据集拆分成为训练集和测试集两个部分。字段设置保持系统默认配置;资源配置选择当前可用的资源池,并配置各类资源。
归一化
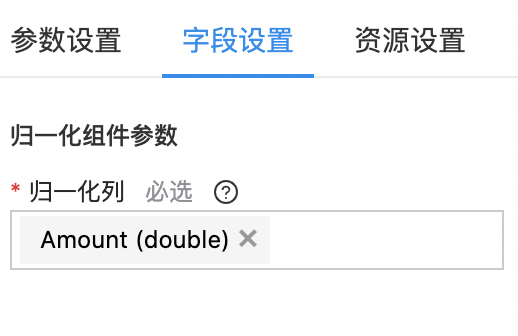
拖拽“归一化”组件。在“参数设置“的“归一化方法”中选择“MAXMIN”,在“字段设置”的“归一化列”中选择“Amount(double)",将交易金额归一化处理。

XGBoost二分类
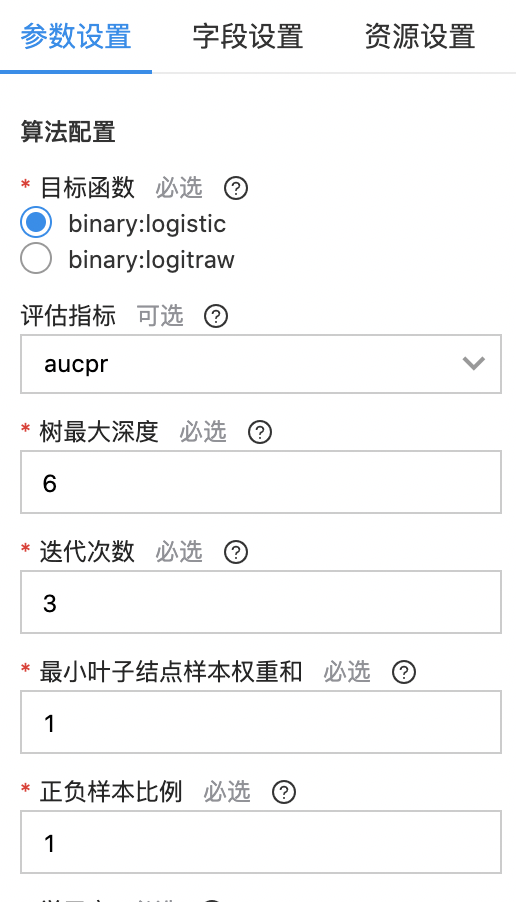
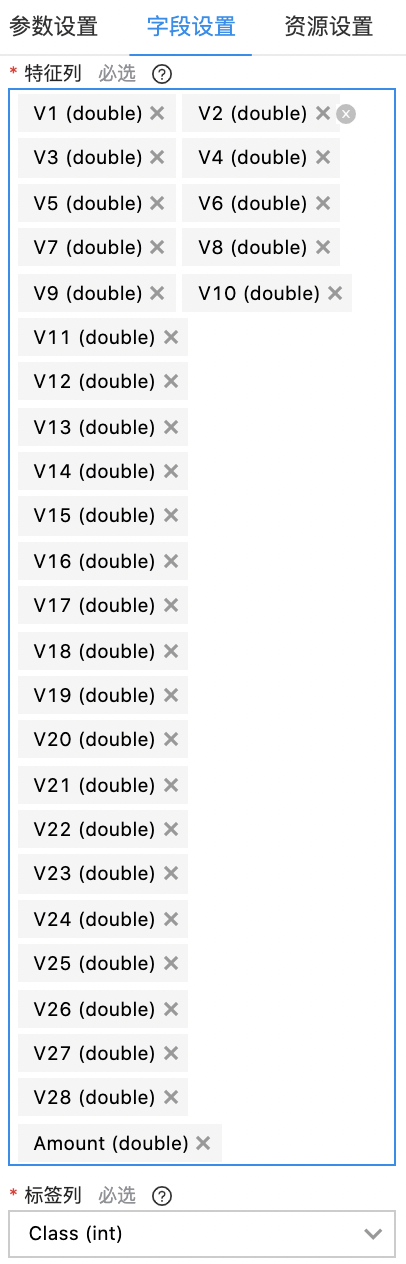
拖拽“XGBoost二分类“到画布中,在“参数配置”的“评估指标”中选择“aucpr"(PR曲线下的面积),其他可保持默认配置或根据训练情况修改。在“字段设置”的“特征列”中选择v1-v28列和Amount列,“标签列”中选择“Class(int)"。
特征工程预测
拖拽“特征工程预测”组件,对测试集做相应处理。
预测组件
拖拽“预测组件”,用于模型预测。
二分类评估
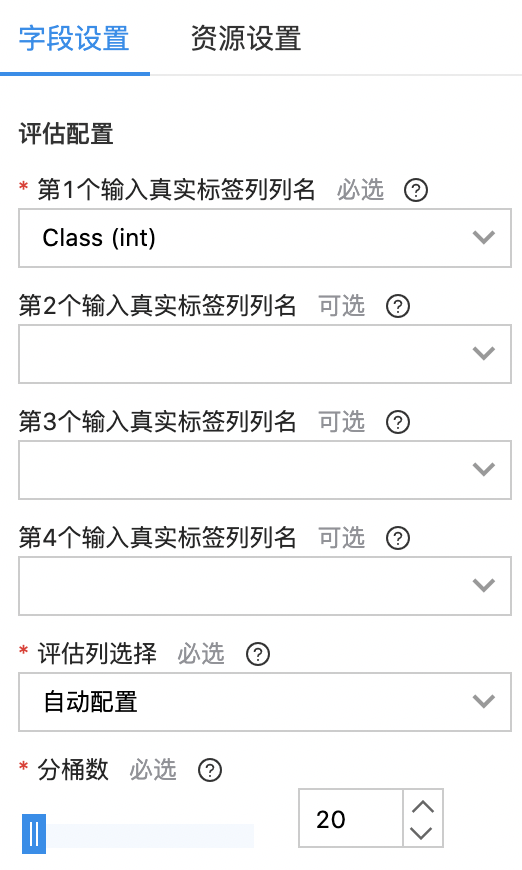
拖拽“二分类评估“组件到画布中,查看模型训练效果。在“字段设置”的“第一个输入真实标签列中选择“Class(int)"。
组建参数配置完成后,点击页面上方的”开始训练“按钮。
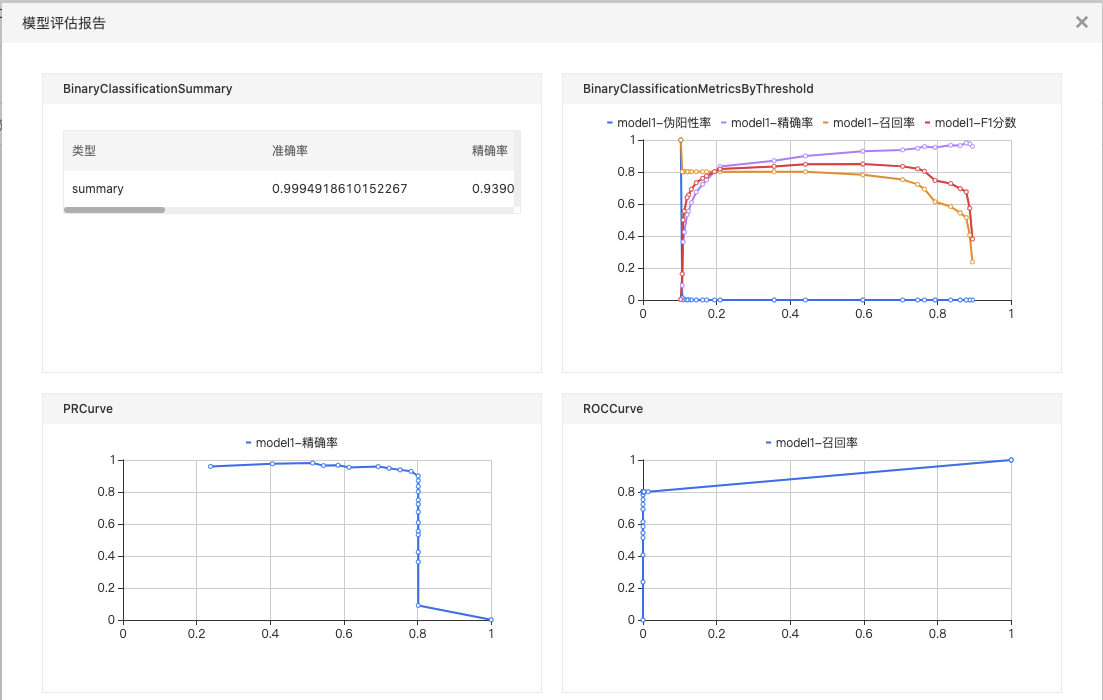
训练完成后,右击“二分类评估”组件,选择”查看评估报告“。
发布模型到模型中心
模型中心是AI模型的集中纳管、评估、优化转换处理场所,提供模型纳管、评估、压缩等功能。
- 模型训练完成后,选择画布右上方的“发布”按钮,将模型发布到模型中心,方便后续部署为API服务并进行调用。
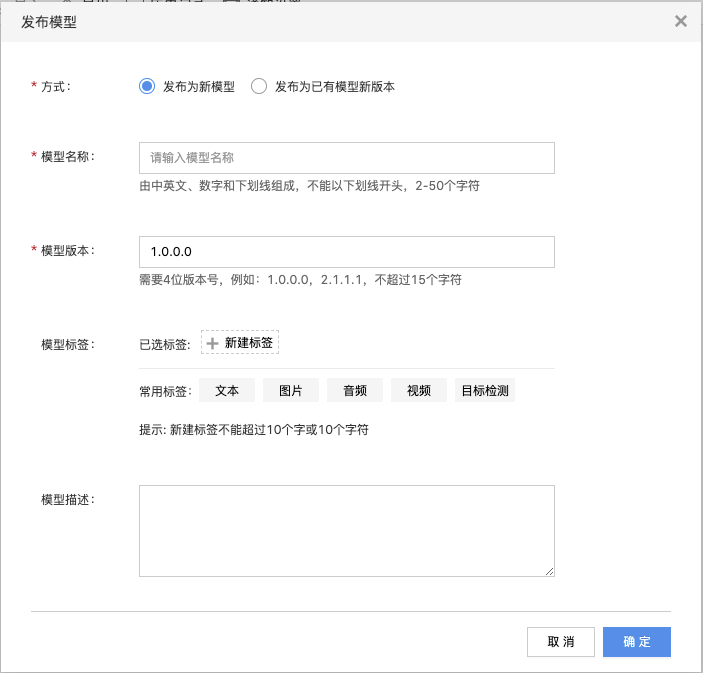
- 发布模型后,进入“模型中心”菜单,在“模型列表”页面找到相应的creditcard模型。点进模型,当模型状态变为“就绪”时,表示模型发布成功。
导出模型文件
平台支持您在模型中心中导出模型包,跨平台使用。
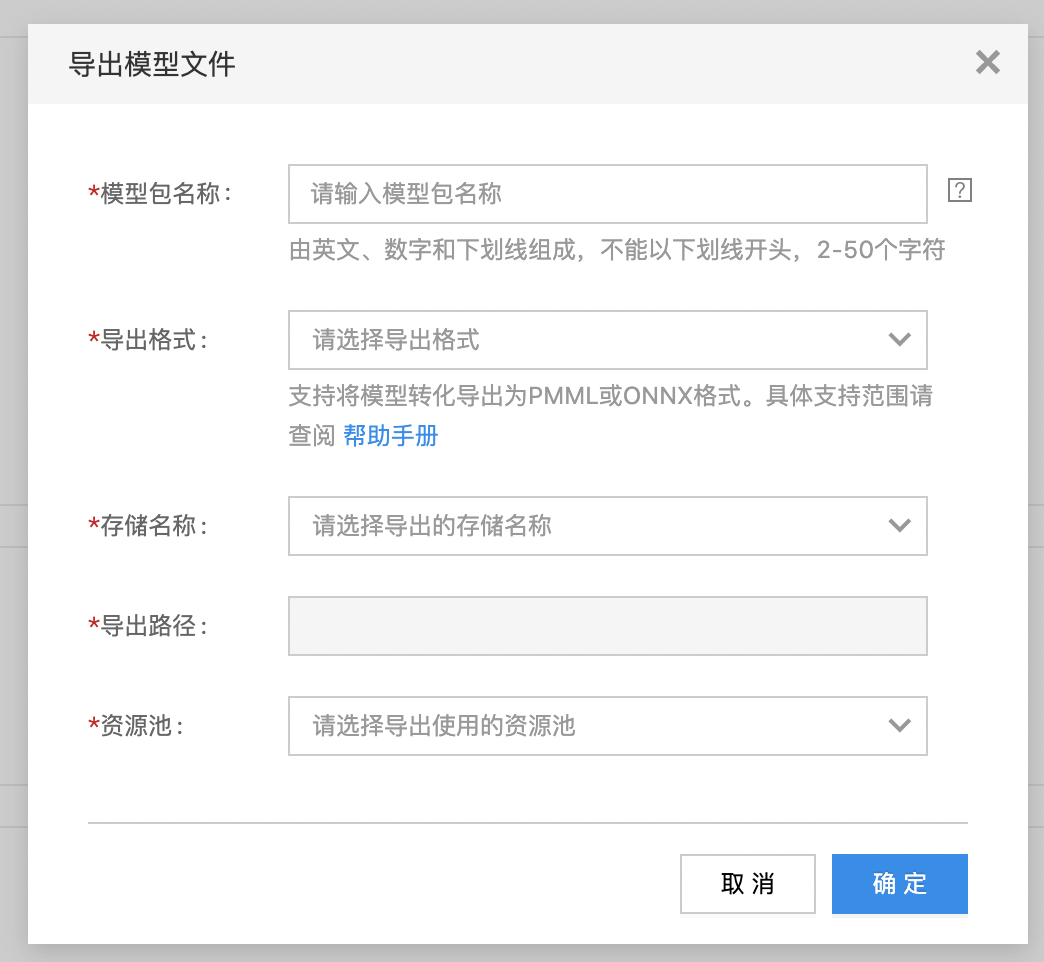
- 进入模型详情页,点击页面上方的“导出模型文件”按钮。

- 在导出页面中,设置模型包名称,并选择存储卷,点击“确定”。
- 进入任务列表,可查看导出任务的状态,并点击“详情”,跳转至存储页面。
- 进入存储卷,下载模型包。

发布模型为预测服务
如果您部署了预测服务,可将模型发布为服务,方便API调用。
- 进入模型管理-版本列表页,点击“部署-在线服务”。
在弹出的创建页面中,设置服务名称、接口地址、模型名称及版本、资源等参数。点击“确定”,将模型发布为服务。
- 进入“公有云部署 > 在线服务“菜单,当服务的状态变为”运行中“时,表示服务发布成功。

点进服务详情,可查看服务地址,并监控服务的模型列表、配置历史、运行记录等信息。
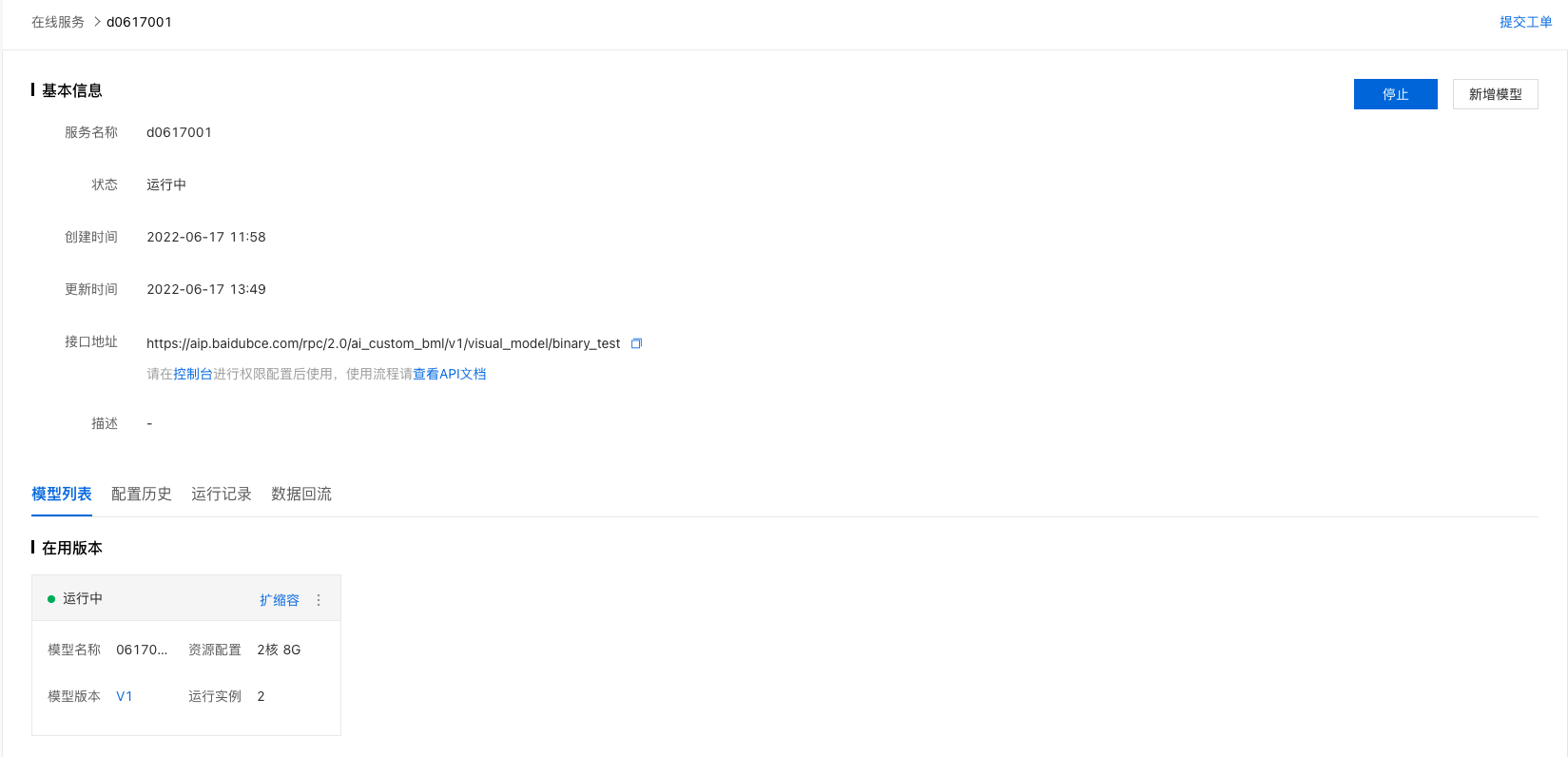
关于预测服务的详细内容,请参考“预测服务”章节。