
基于 Notebook 的通用模板使用指南
目录
1.创建并启动Notebook
2.训练物体检测模型
3.配置并发布模型
4.校验模型
5.部署在线服务
基于 Notebook 的通用模板使用指南
本文采用物体检测模型的开发过程为例,介绍通用模板从创建 Notebook 任务到引入数据、训练模型,再到保存模型、部署模型的全流程。
创建并启动Notebook
1、在 BML 左侧导航栏中点击『Notebook』
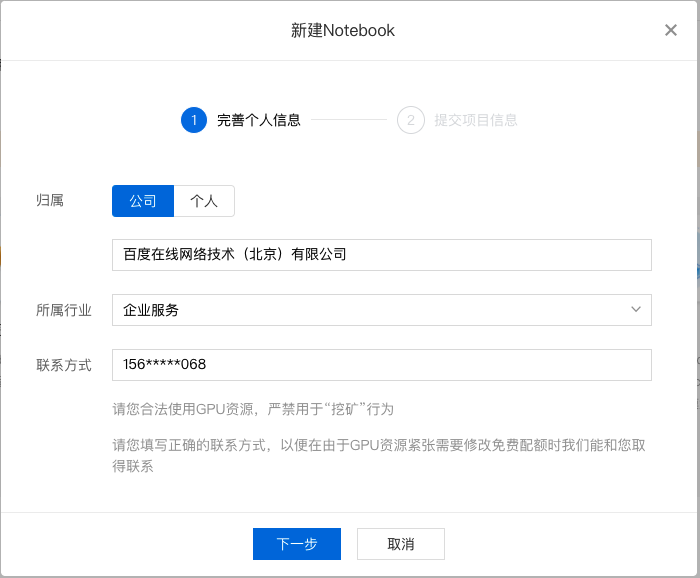
2、在 Notebook 页面点击『新建』,在弹出框中填写公司/个人信息以及项目信息,示例如下:
填写基础信息
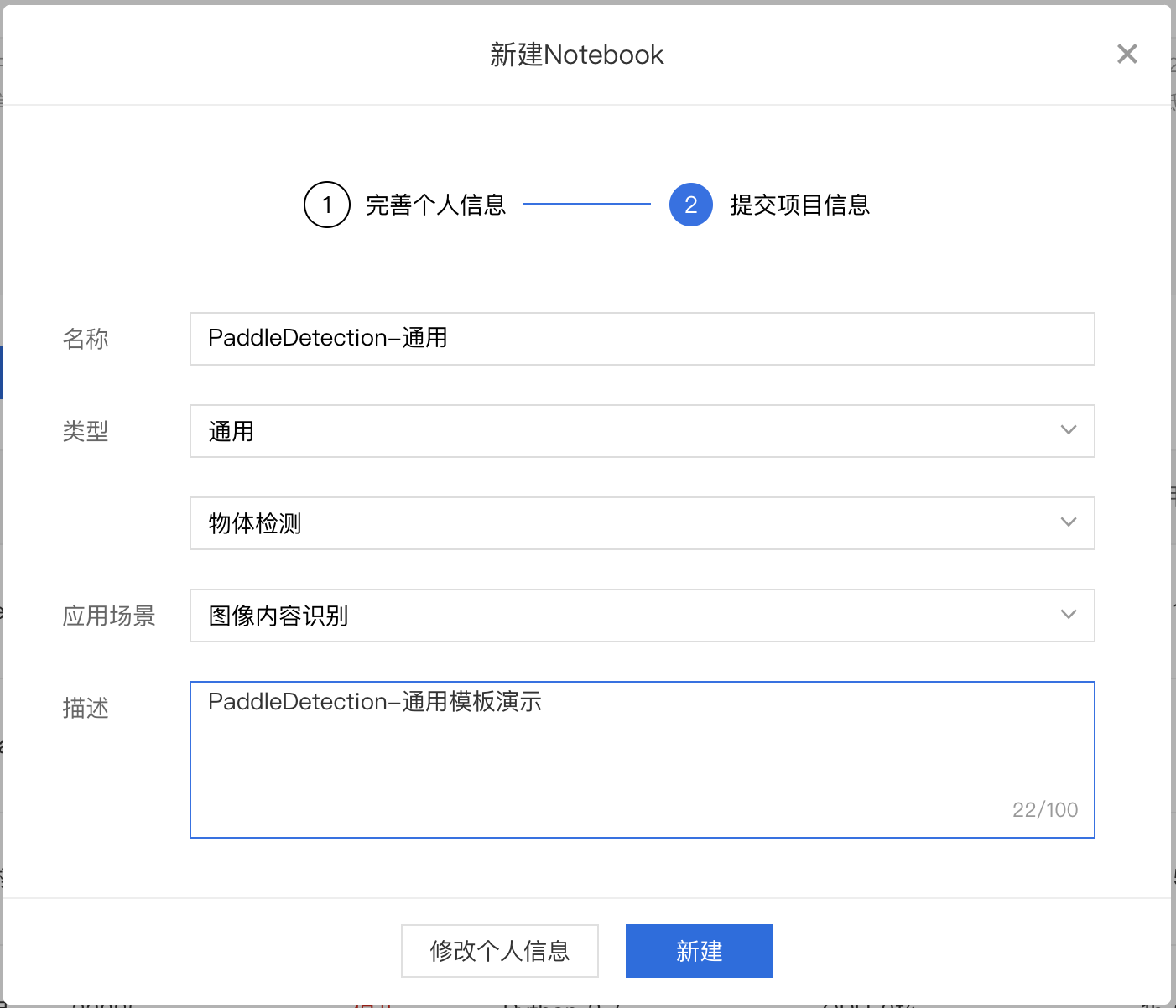
填写项目信息
3、对 Notebook 任务操作入口中点击『配置』进行资源配置,示例如下:
选择开发语言、AI 框架,由于本次采用 PaddleClas 进行演示,所以需要选择 python3.7、PaddlePaddle2.0.0。选择资源规格,由于深度学习所需的训练资源一般较多,需要选择GPU V100的资源规格。
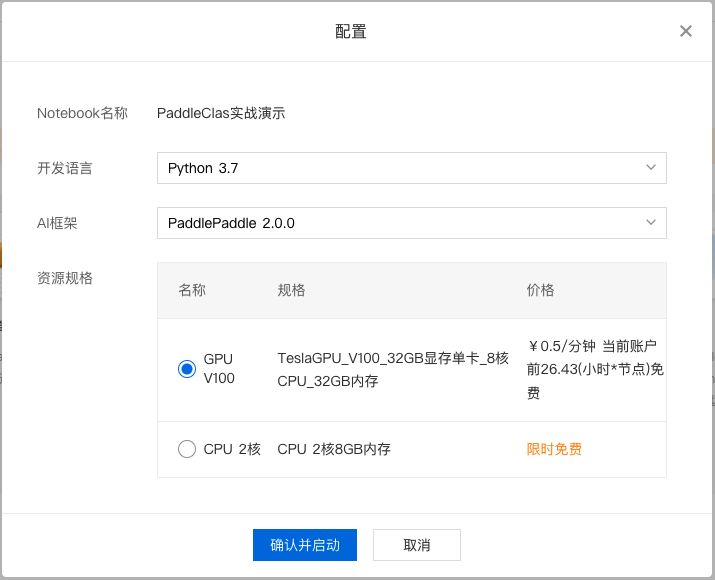
完成配置后点击『确认并启动』,即可启动 Notebook,启动过程中需要完成资源的申请以及实例创建,请耐心等待。
4、等待 Notebook 启动后,点击『打开』,页面跳转到 Notebook,即完成 Notebook 的创建与启动,示例如下:
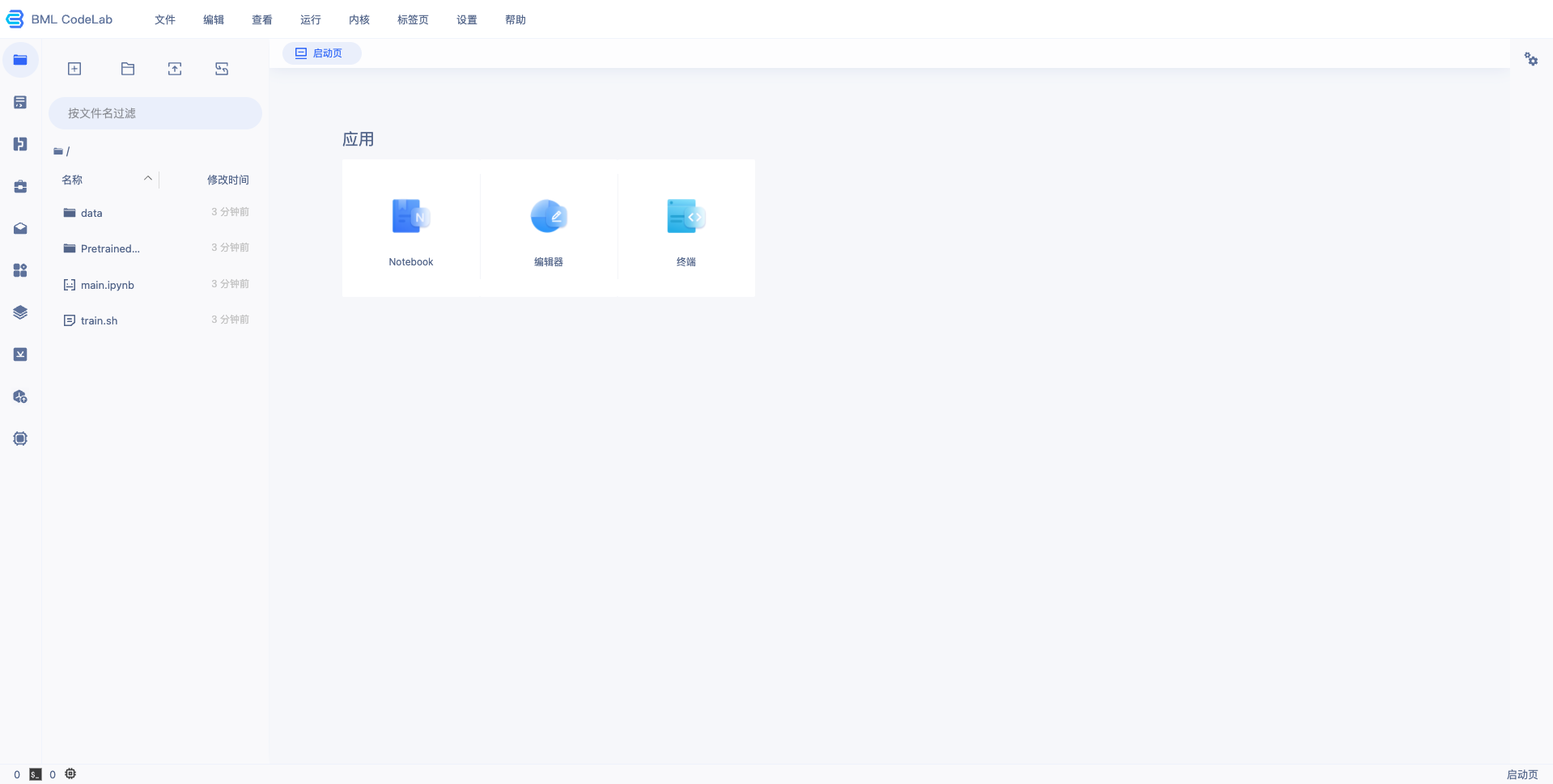
训练物体检测模型
下载 PaddleDetection 套件
打开进入 Notebook,点击进入终端,输入如下命令切换到 /home/work/ 目录。
1cd /home/work/本文以 PaddleDetection 代码库 release/2.3 分支为例,输入如下命令克隆PaddleDetection代码库并切换至release/2.3分支。整个过程需要数十秒,请耐心等待。
1# gitee 国内下载比较快
2git clone https://gitee.com/paddlepaddle/PaddleDetection.git -b release/2.3
3# github
4# git clone https://github.com/PaddlePaddle/PaddleDetection.git -b release/2.3安装环境
在终端环境中,安装该版本的 PaddleDetection 代码包依赖的 paddlepaddle-gpu,执行如下命令:
1python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html安装完成后,使用 python 或 python3 进入python解释器,输入 import paddle ,再输入 paddle.utils.run_check()
如果出现 PaddlePaddle is installed successfully!,说明成功安装。
准备训练数据
训练数据是模型生产的重要条件,优质的数据集可以很大程度上的提升模型训练效果,准备数据可以参考链接。本文所用的安全帽检测数据集可前往此链接进行下载:下载链接。
1、导入用户数据。
在 Notebook 中并不能直接访问您在 BML 中创建的数据集,需要通过左边选择栏的导入数据集选项,进行数据集导入。导入的数据位于用户目录的 data/ 文件夹(当原始数据集有更新时,不会自动同步,需要手工进行同步)。
注:若在BML中未创建数据集,请先参考 数据服务 ,创建、上传、标注数据集。
2、数据转换。
PaddleDetection 训练所需要的数据格式与 BML 默认的数据格式有所不同,所以需要利用脚本将导入的数据转为 PaddleDetection 支持的数据格式,并进行3:7切分。
PaddleDetection 默认支持的标注格式为 COCO格式,转换脚本如下:
1import os
2import cv2
3import json
4import glob
5import codecs
6import random
7from pycocotools.coco import COCO
8
9def parse_bml_json(json_file):
10 """
11 解析BML标注文件
12 :return:
13 """
14 annos = json.loads(codecs.open(json_file).read())
15 labels = annos['labels']
16 bboxes = []
17 for label in labels:
18 x1 = label["x1"]
19 y1 = label["y1"]
20 x2 = label["x2"]
21 y2 = label["y2"]
22 id = label["name"]
23 bboxes.append([x1, y1, x2, y2, id])
24 return bboxes
25
26
27def bbox_transform(box):
28 """
29 x1, y1, x2, y2 转为 x1, y1, width, height
30 :return
31 """
32 box = list(map(lambda x: float(x), box))
33 box[2] = box[2] - box[0]
34 box[3] = box[3] - box[1]
35 return box
36
37
38def parse_label_list(src_data_dir, save_dir):
39 """
40 遍历标注文件,获取label_list
41 :return:
42 """
43 label_list = []
44 anno_files = glob.glob(src_data_dir + "*.json")
45 for anno_f in anno_files:
46 annos = json.loads(codecs.open(anno_f).read())
47 for lb in annos["labels"]:
48 label_list.append(lb["name"])
49 label_list = list(set(label_list))
50 with codecs.open(os.path.join(save_dir, "label_list.txt"), 'w', encoding="utf-8") as f:
51 for id, label in enumerate(label_list):
52 f.writelines("%s:%s\n" % (id, label))
53 return len(label_list), label_list
54
55
56def bml2coco(src_dir, coco_json_file):
57 """
58 BML标注格式转为COCO标注格式
59 :return:
60 """
61 coco_images = []
62 coco_annotations = []
63
64 image_id = 0
65 anno_id = 0
66 image_list = glob.glob(src_dir + "*.[jJPpBb][PpNnMm]*")
67 for image_file in image_list:
68 anno_f = image_file.split(".")[0] + ".json"
69 if not os.path.isfile(anno_f):
70 continue
71 bboxes = parse_bml_json(anno_f)
72 im = cv2.imread(image_file)
73 h, w, _ = im.shape
74 image_i = {"file_name": os.path.basename(image_file), "id": image_id, "width": w, "height": h}
75 coco_images.append(image_i)
76 for id, bbox in enumerate(bboxes):
77 # bbox : [x1, y1, x2, y2, label_name]
78 anno_i = {"image_id": image_id, "bbox": bbox_transform(bbox[:4]), 'category_id': label_list.index(bbox[4]),
79 'id': anno_id, 'area': 1.1, 'iscrowd': 0, "segmentation": None}
80 anno_id += 1
81 coco_annotations.append(anno_i)
82
83 image_id += 1
84
85 coco_categories = [{"id": id, "name": label_name} for id, label_name in enumerate(label_list)]
86 coco_dict = {"info": "info", "licenses": "BMLCloud", "images": coco_images, "annotations": coco_annotations,
87 "categories": coco_categories}
88 with open(coco_json_file, 'w', encoding="utf-8") as fin:
89 json.dump(coco_dict, fin, ensure_ascii=False)
90
91
92def split_det_origin_dataset(
93 origin_file_path,
94 train_file_path,
95 eval_file_path,
96 ratio=0.7):
97 """
98 按比例切分物体检测原始数据集
99 :return:
100 """
101 coco = COCO(origin_file_path)
102 img_ids = coco.getImgIds()
103 items_num = len(img_ids)
104 train_indexes, eval_indexes = random_split_indexes(items_num, ratio)
105 train_items = [img_ids[i] for i in train_indexes]
106 eval_items = [img_ids[i] for i in eval_indexes]
107
108 dump_det_dataset(coco, train_items, train_file_path)
109 dump_det_dataset(coco, eval_items, eval_file_path)
110
111 return items_num, len(train_items), len(eval_items)
112
113
114def random_split_indexes(items_num, ratio=0.7):
115 """
116 按比例分割整个list的index
117 :return:分割后的两个index子列表
118 """
119 offset = round(items_num * ratio)
120 full_indexes = list(range(items_num))
121 random.shuffle(full_indexes)
122 sub_indexes_1 = full_indexes[:offset]
123 sub_indexes_2 = full_indexes[offset:]
124
125 return sub_indexes_1, sub_indexes_2
126
127
128def dump_det_dataset(coco, img_id_list, save_file_path):
129 """
130 物体检测数据集保存
131 :return:
132 """
133 imgs = coco.loadImgs(img_id_list)
134 img_anno_ids = coco.getAnnIds(imgIds=img_id_list, iscrowd=0)
135 instances = coco.loadAnns(img_anno_ids)
136 cat_ids = coco.getCatIds()
137 categories = coco.loadCats(cat_ids)
138 common_dict = {
139 "info": coco.dataset["info"],
140 "licenses": coco.dataset["licenses"],
141 "categories": categories
142 }
143 img_dict = {
144 "image_nums": len(imgs),
145 "images": imgs,
146 "annotations": instances
147 }
148 img_dict.update(common_dict)
149
150 json_file = open(save_file_path, 'w', encoding='UTF-8')
151 json.dump(img_dict, json_file)
152
153
154class_nums, label_list = parse_label_list("/home/work/data/${dataset_id}/", "/home/work/PretrainedModel/")
155bml2coco("/home/work/data/${dataset_id}/", "/home/work/PretrainedModel/org_data_list.json")
156split_det_origin_dataset("/home/work/PretrainedModel/org_data_list.json", "/home/work/PretrainedModel/train_data_list.json", "/home/work/PretrainedModel/eval_data_list.json")将上述脚本存放为 coversion.py 代码脚本,并将脚本最后两行的 ${dataset_id} 替换为所指定数据集的 ID(下图红框中的ID),在终端中运行即可。
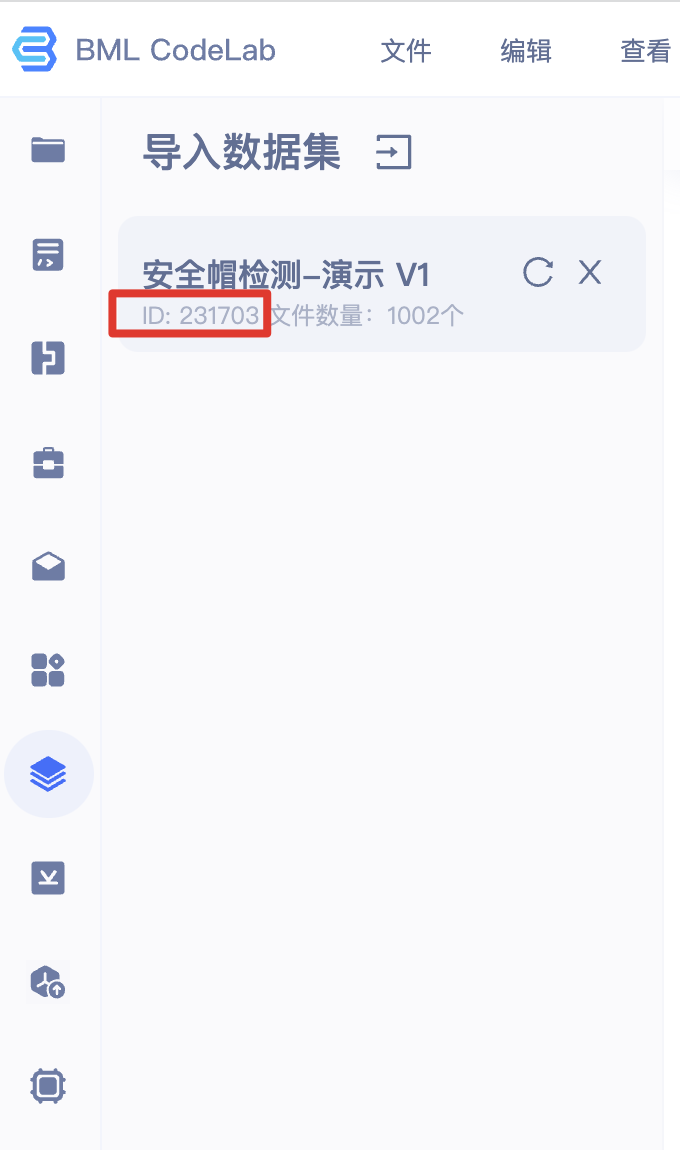
运行代码。
1python coversion.py注意:如果报错 No module named 'pycocotools',需要通过如下命令安装相关依赖包,再运行 coversion.py 代码。
1pip install pycocotools运行 coversion.py 代码成功之后将在 PretrainedModel/ 文件夹下生成对应的数据文件,包括 label_list.txt、train_data_list.json、eval_data_list.json、org_data_list.json。

训练模型
1、在终端中打开 PaddleDetection 目录。
1cd /home/work/PaddleDetection2、修改yaml配置文件。
在PaddleDetection 2.0后续版本,采用了模块解耦设计,用户可以组合配置模块实现检测器,并可自由修改覆盖各模块配置,本文以 configs/yolov3/yolov3_darknet53_270e_coco.yml 为例:
1yolov3_darknet53_270e_coco.yml 主配置入口文件
2coco_detection.yml 主要说明了训练数据和验证数据的路径
3runtime.yml 主要说明了公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
4optimizer_270e.yml 主要说明了学习率和优化器的配置。
5yolov3_darknet53.yml 主要说明模型、和主干网络的情况。
6yolov3_reader.yml 主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等需要修改/覆盖的参数均可写在主配置入口文件中,主要修改点为训练、验证数据集路径、运行epoch数、学习率等,修改后的主配置文件如下(注释行即为需要修改的点):
1_BASE_: [
2 '../datasets/coco_detection.yml',
3 '../runtime.yml',
4 '_base_/optimizer_270e.yml',
5 '_base_/yolov3_darknet53.yml',
6 '_base_/yolov3_reader.yml',
7]
8
9snapshot_epoch: 5
10weights: output/yolov3_darknet53_270e_coco/model_final
11
12# 预训练权重地址
13pretrain_weights: https://paddledet.bj.bcebos.com/models/yolov3_darknet53_270e_coco.pdparams
14
15# coco_detection.yml
16num_classes: 2 #实际类别数
17TrainDataset:
18 !COCODataSet
19 image_dir: data/${dataset_id}/ # 图片地址
20 anno_path: PretrainedModel/train_data_list.json # 标注文件
21 dataset_dir: /home/work/ # 数据集根目录
22 data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
23
24EvalDataset:
25 !COCODataSet
26 image_dir: data/${dataset_id}/ # 图片地址
27 anno_path: PretrainedModel/eval_data_list.json # 标注文件
28 dataset_dir: /home/work/ # 数据集根目录
29
30# optimizer_270e.yml
31epoch: 50 # 迭代轮数
32LearningRate:
33 base_lr: 0.0001 # 学习率
34 schedulers:
35 - !PiecewiseDecay
36 gamma: 0.1
37 milestones:
38 - 30
39 - 45
40 - !LinearWarmup
41 start_factor: 0.
42 steps: 4003、训练模型。
在终端中执行以下命令,开始模型训练。
1cd /home/work/PaddleDetection/
2python tools/train.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml --eval 注意:如果报错 No module named 'lap' 和 No module named 'motmetrics' ,则需要通过如下命令安装相关依赖包,再运行 coversion.py 代码。(如果缺失其他模块,也可用类似命令下载安装)
1pip install lap motmetrics4、模型评估
在终端中执行以下命令,开始模型评估。
1python tools/eval.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml \
2 -o weights=output/yolov3_darknet53_270e_coco/model_final运行完成输出如下结果:

5、模型预测。
在终端中执行以下命令,开始模型预测(注意修改图片路径)。
1python tools/infer.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml \
2 --infer_img=/home/work/data/${task_id}/xxx.jpeg \
3 --output_dir=infer_output/ \
4 --draw_threshold=0.5 \
5 -o weights=output/yolov3_darknet53_270e_coco/model_final6、导出模型。
在终端中执行以下命令,将最佳模型转为可以用于发布的 inference 模型
1python tools/export_model.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml \
2 --output_dir=/home/work/PretrainedModel/ \
3 -o weights=output/yolov3_darknet53_270e_coco/model_final在终端中执行以下命令,将导出模型移至 /home/work/PretrainedModel/ 目录。
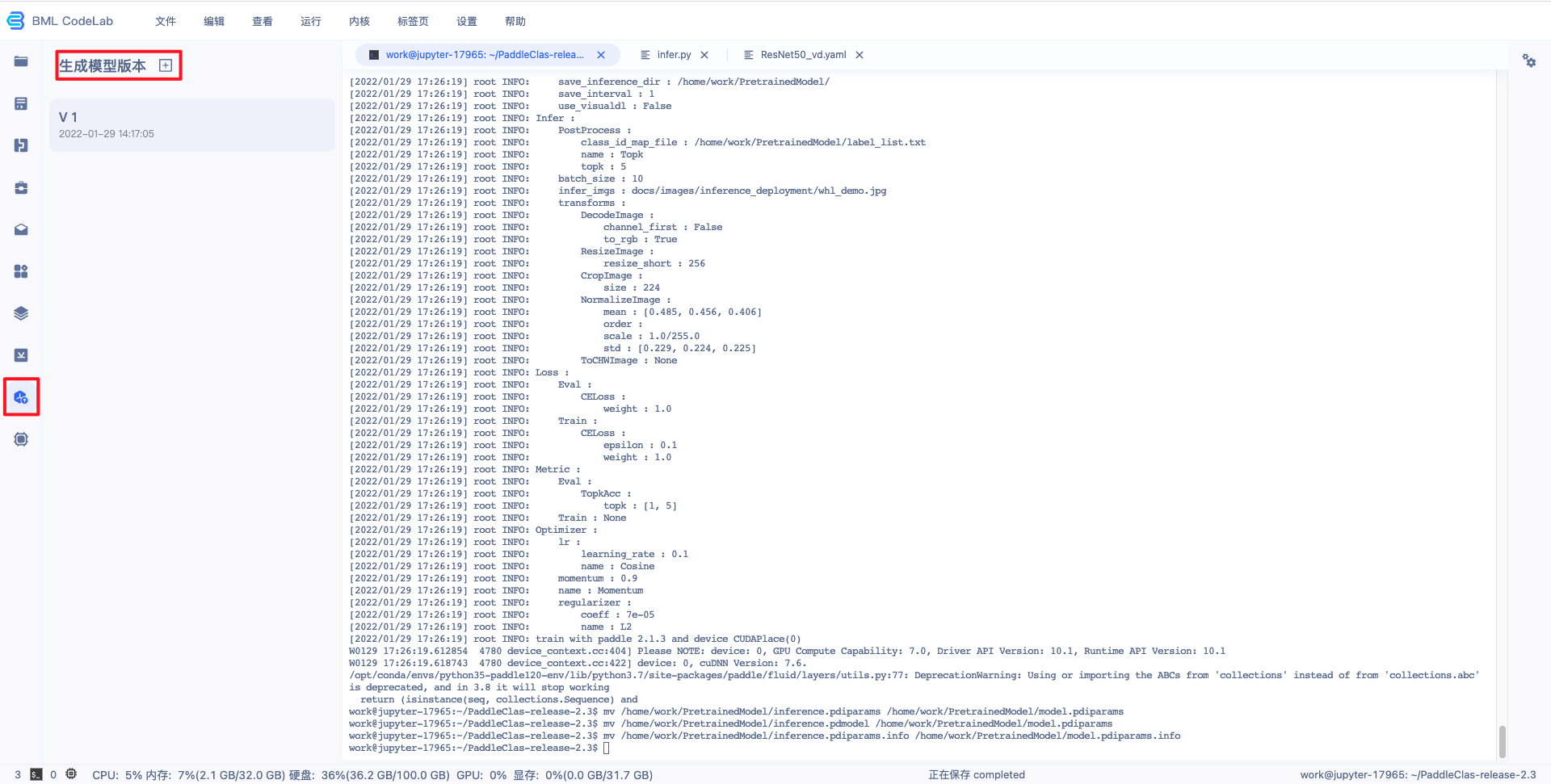
1mv /home/work/PretrainedModel/yolov3_darknet53_270e_coco/* /home/work/PretrainedModel/7、生成模型版本。
Notebook中的模型文件只有生成模型版本后,才可以执行发布和部署功能:
- 请确保要保存的模型文件在
/home/work/PretrainedModel目录下。模型支持版本管理功能,在保存时可以生成新版本也可以覆盖已有的且尚未部署的模型版本,每个版本的模型都可以独立部署。每个模型版本中保存的模型文件大小上限为1.5GB。 - 在保存模式时也可以将训练模型的代码一并保存。代码支持版本管理功能,用户再次启动Notebook时,可以使用指定的代码版本来初始化Notebook工作空间即/home/work目录下data以外的空间。每个代码版本中保存的文件大小上限为150M。
点击左侧导航栏中的生成模型版本组件,打开弹窗填写信息。
模型属性-选择 AI 框架选择 PaddlePaddle2.0.0,若上一次操作中进行了代码保存,可在“代码版本”选择对应的代码版本。
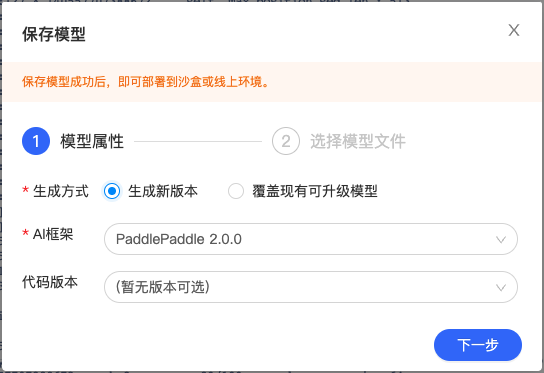
选择模型文件-选择 label_list.txt、model.pdiparams、model.pdmodel 、 infer_cfg.yaml 文件。
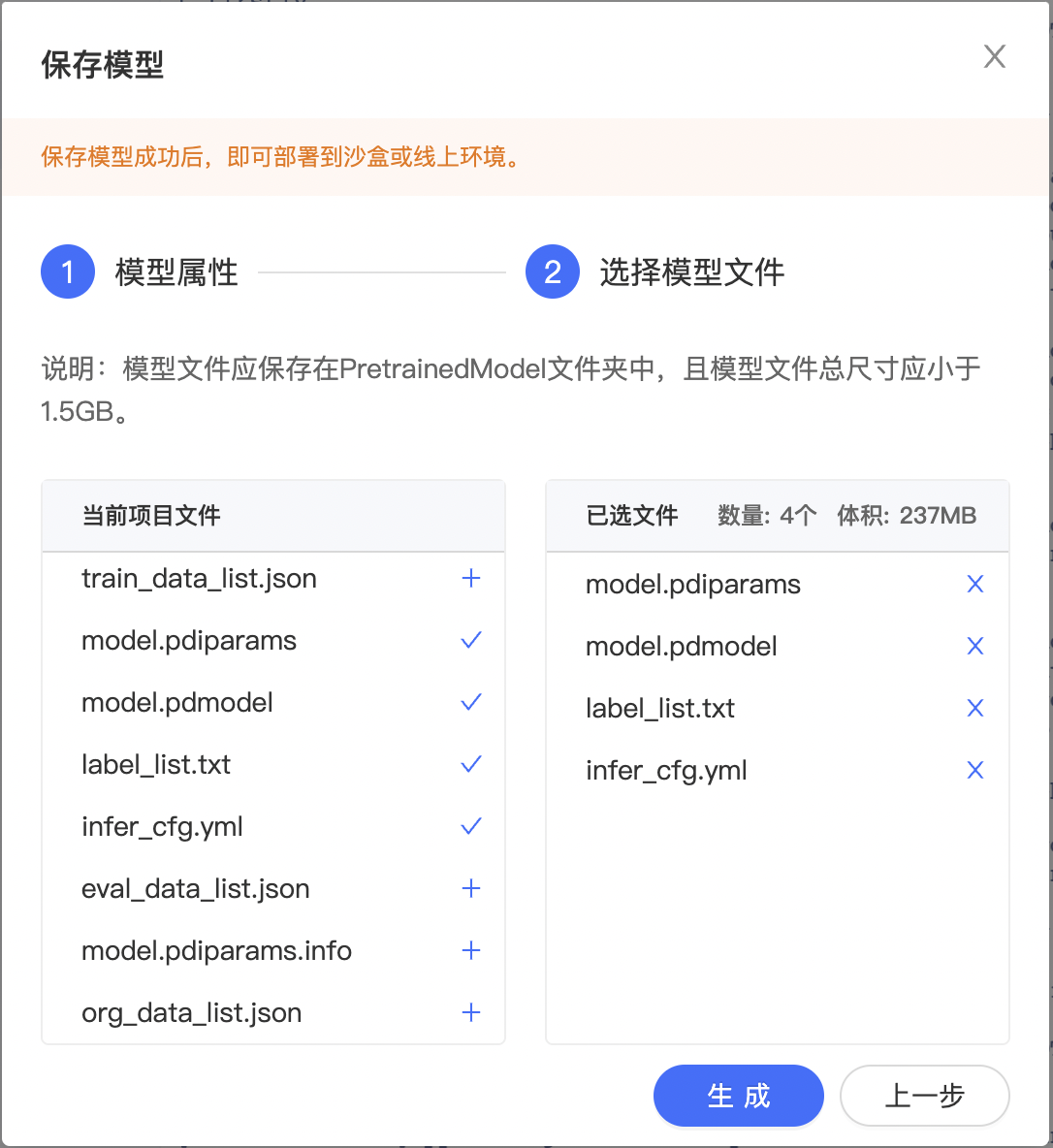
点击『生成』即可生成模型版本,生成模型版本一般需要数十秒,请耐心等待。
配置并发布模型
本文以 PaddlePaddle 的 物体检测模型为例,详细介绍配置说明如下:
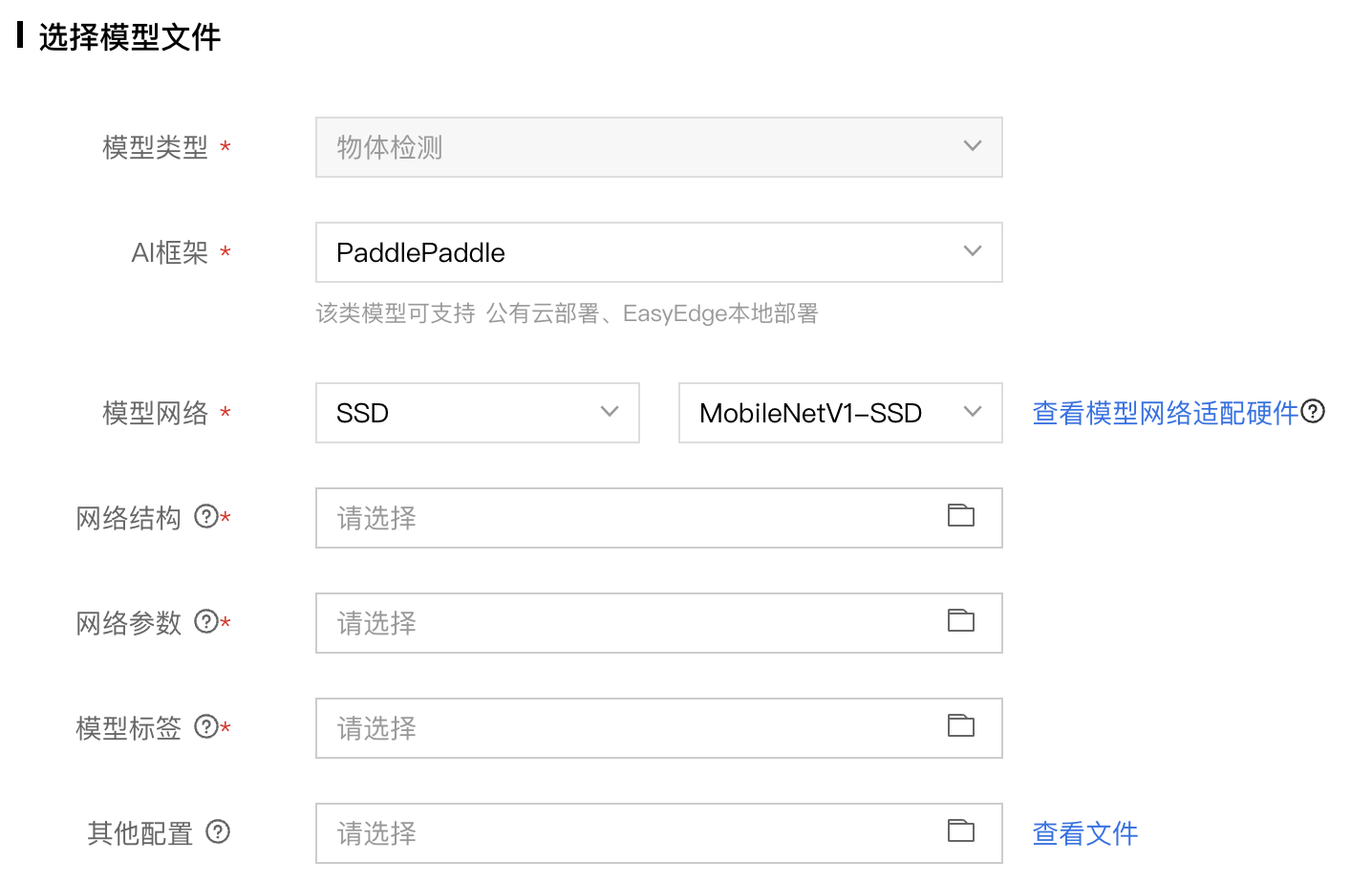
根据平台截图可以看出,主要需要设置一下几个配置
- 模型网络:保存模型对应网络结构名称,例如SSD, YOLO等;
- 网络结构:PaddlePaddle 保存为推理模型(save_inference_model)时,保存的网络结构文件,默认名字是model.pdparams。具体参考:PaddlePaddle模型保存 PaddlePaddle save_inference_model API
- 网络参数:PaddlePaddle 保存为推理模型(save_inference_model)时,网络参数可以保存为单独的params文件,或者分散的多个独立文件。对于模型参数文件,请上传单独的params文件,或者将多个分散文件打包成zip(不带子目录)上传。具体参考:PaddlePaddle模型保存 PaddlePaddle save_inference_model API
- 模型标签:模型识别的所有类别的标识,支持字母/数字/下划线/中划线/点;
- 其他配置:其他配置包括图片预处理、后处理以及网络输入输出层的选择等配置。
对于其他应用方向及框架的模型配置,都是类似的,但配置项可能存在差异。 具体使用时,可以根据自身模型的训练框架和应用类型,进行选择查看需要提供的配置项。而且配置项旁边有hover提示,如果不清楚,可以查看提示进一步了解。
操作步骤如下
1、查看前置条件是否满足:需要训练完成,并生成了相应的模型生成版本(详见训练模型的第六步)。
2、回到 BML Notebook 列表页,点击『模型发布列表』即可进入配置页面。

3、点击配置,即可进入配置流程。

4、填写模型信息。

5、选择待发布的模型文件,点击确定按钮。
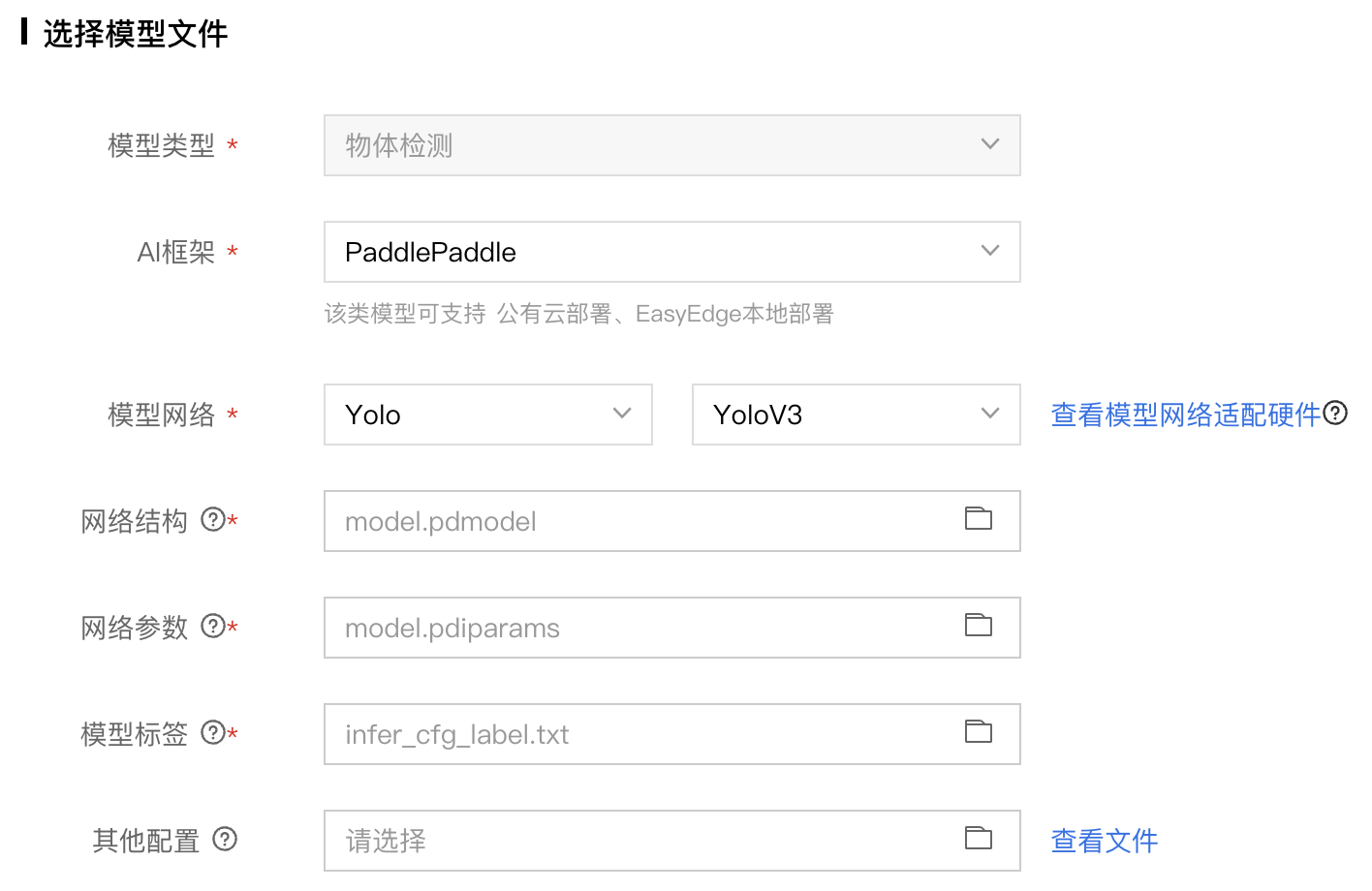
本文采用了PaddlePaddle中的yoloV3模型,故而选择如图。
另外,对 Paddle2.x 的模型而言:
- 网络结构文件
model.pdmodel:必需选择,且名字固定。 - 网络参数文件
model.pdiparams:必需选择,且名字固定。 - 模型标签文件:
label_list.txt,必须选择。(注:因为paddle detection套件默认将标签存放在infer_cfg.yaml了,因此需要在notebook环境里面手动存储为txt文件,每行代表一个标签。)
7、点击提交即可进入模型验证阶段,验证时间一般需要数十秒,请耐心等待。

验证通过后,显示有效。

8、点击发布,填写相关信息后,即可发布成功。
9、点击左侧导航栏模型管理,即可查看发布成功的模型。

校验模型
1、点击『版本列表』。

2、点击『校验模型』。
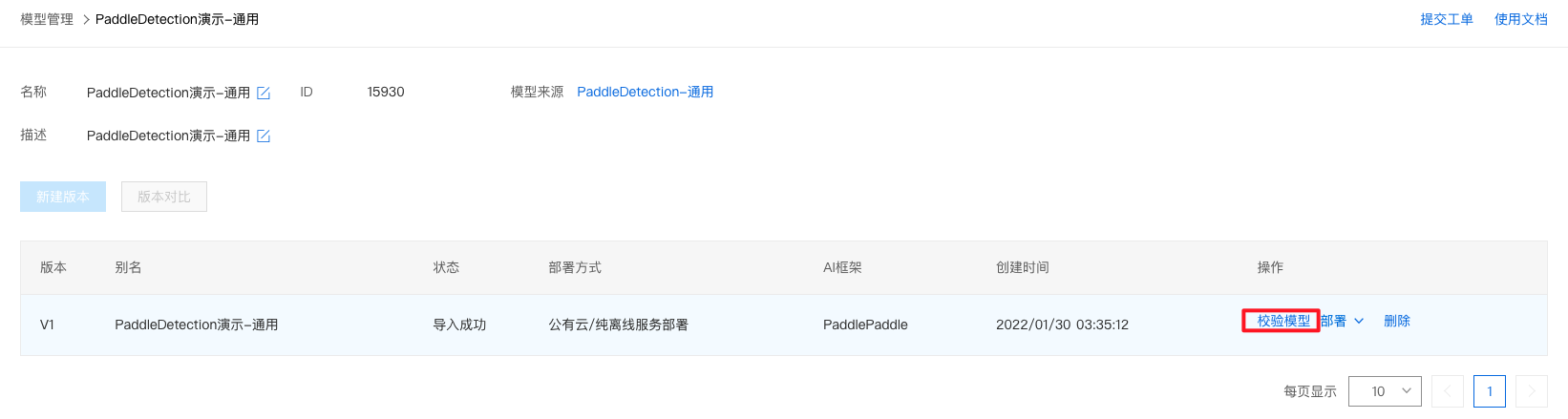
3、点击『启动模型校验』,启动约需5分钟,请耐心等待。
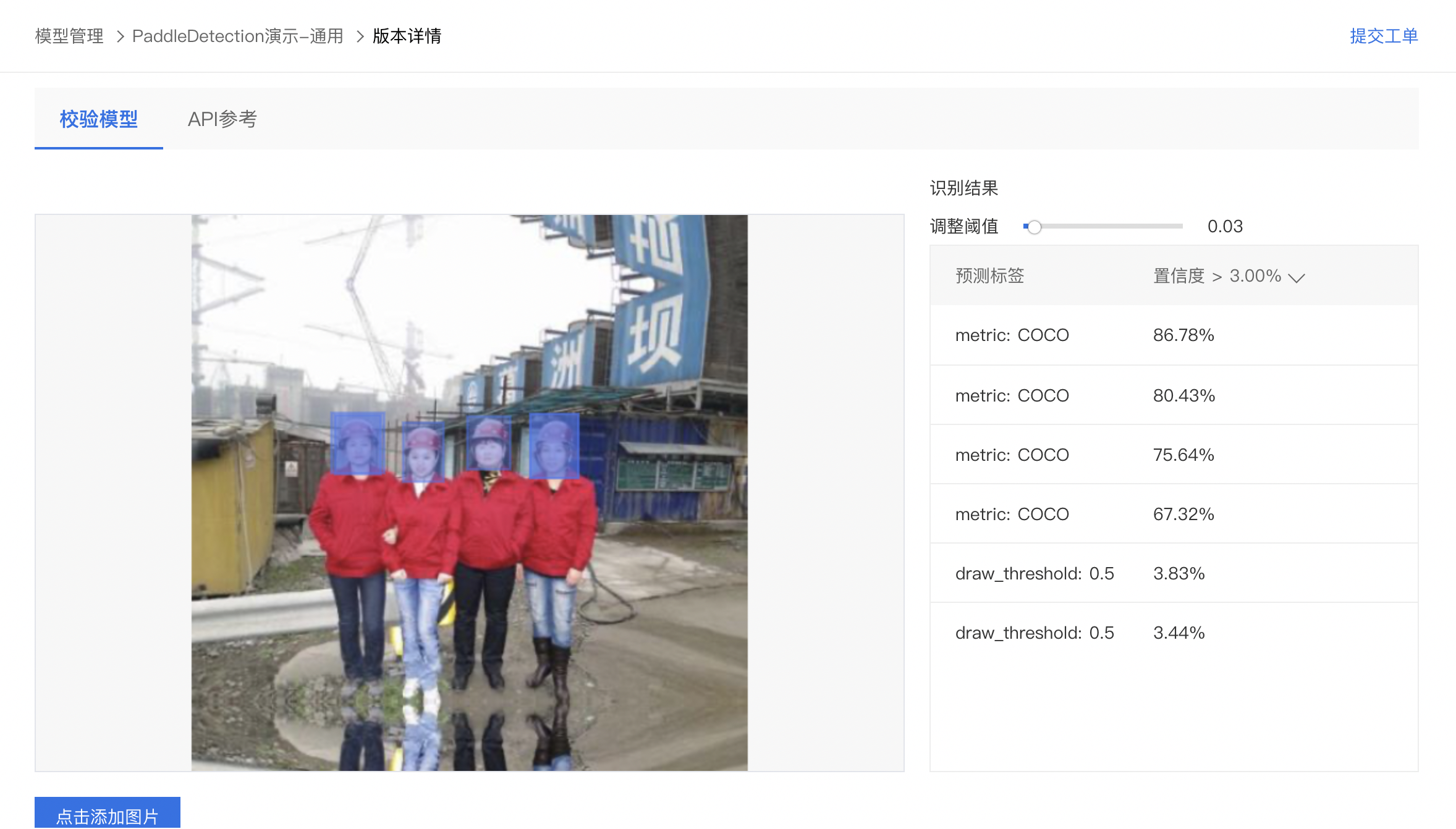
4、上传图像即可开始校验,示例如下:
部署在线服务
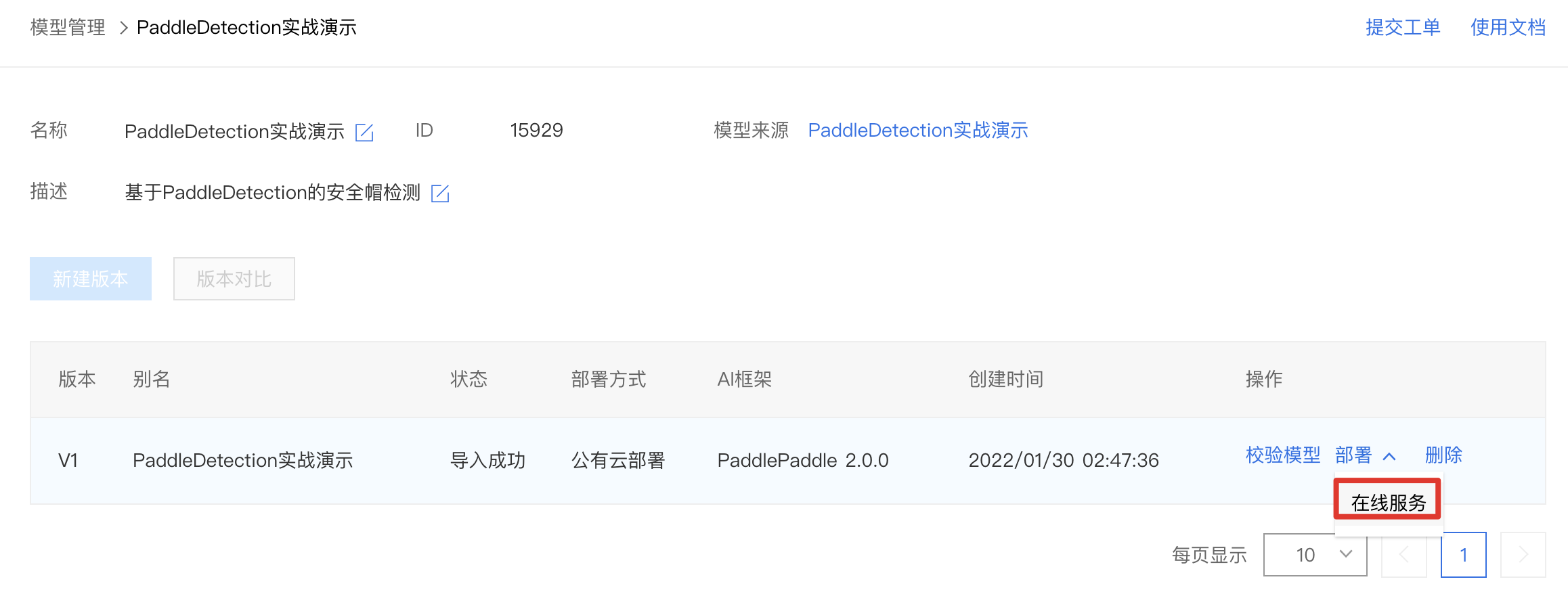
1、点击『版本列表』。

2、点击部署-在线服务。
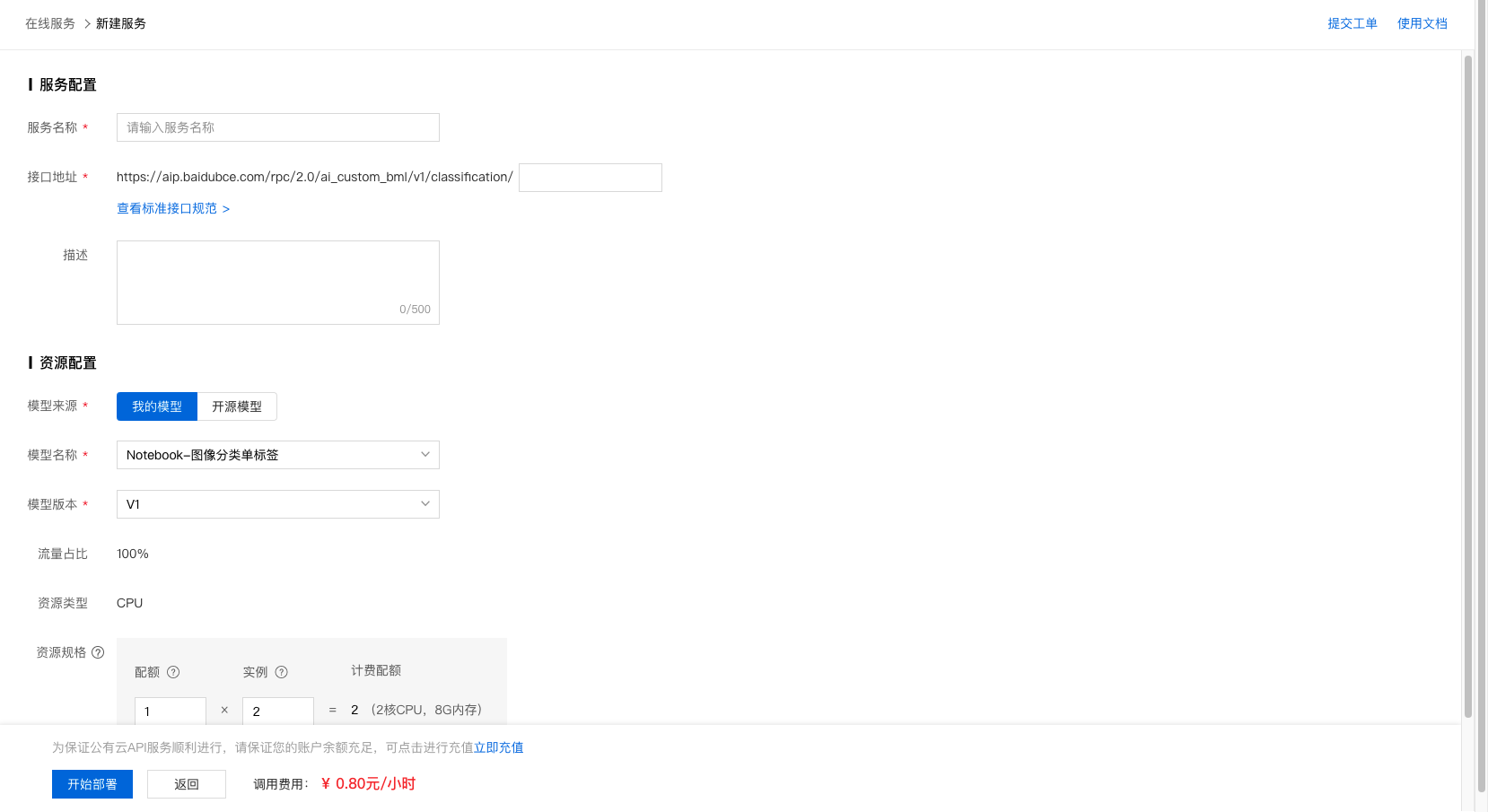
3、完成信息填写及资源规格选择后,即可开始部署。
4、部署过程需要数十秒时间,请耐心等待。部署完成后,示例如下:

5、API调用方法请参考 公有云部署管理。
总结
-
更多丰富的内容与示例可以参考PaddleDetection的github与教程文档。
- PaddleDetection github地址:https://github.com/PaddlePaddle/PaddleDetection/
- PaddleDetection教程文档地址:https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.3/docs/tutorials/GETTING_STARTED_cn.md
- 如果在使用PaddleDetection的过程中遇到问题,欢迎去PaddleDetection的github上提issue:https://github.com/PaddlePaddle/PaddleDetection/issues/new