003-数据处理组件
数据处理
SMOTE过采样
SMOTE算法的基本思想就是采用KNN技术对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。
输入
- 输入一个数据集。
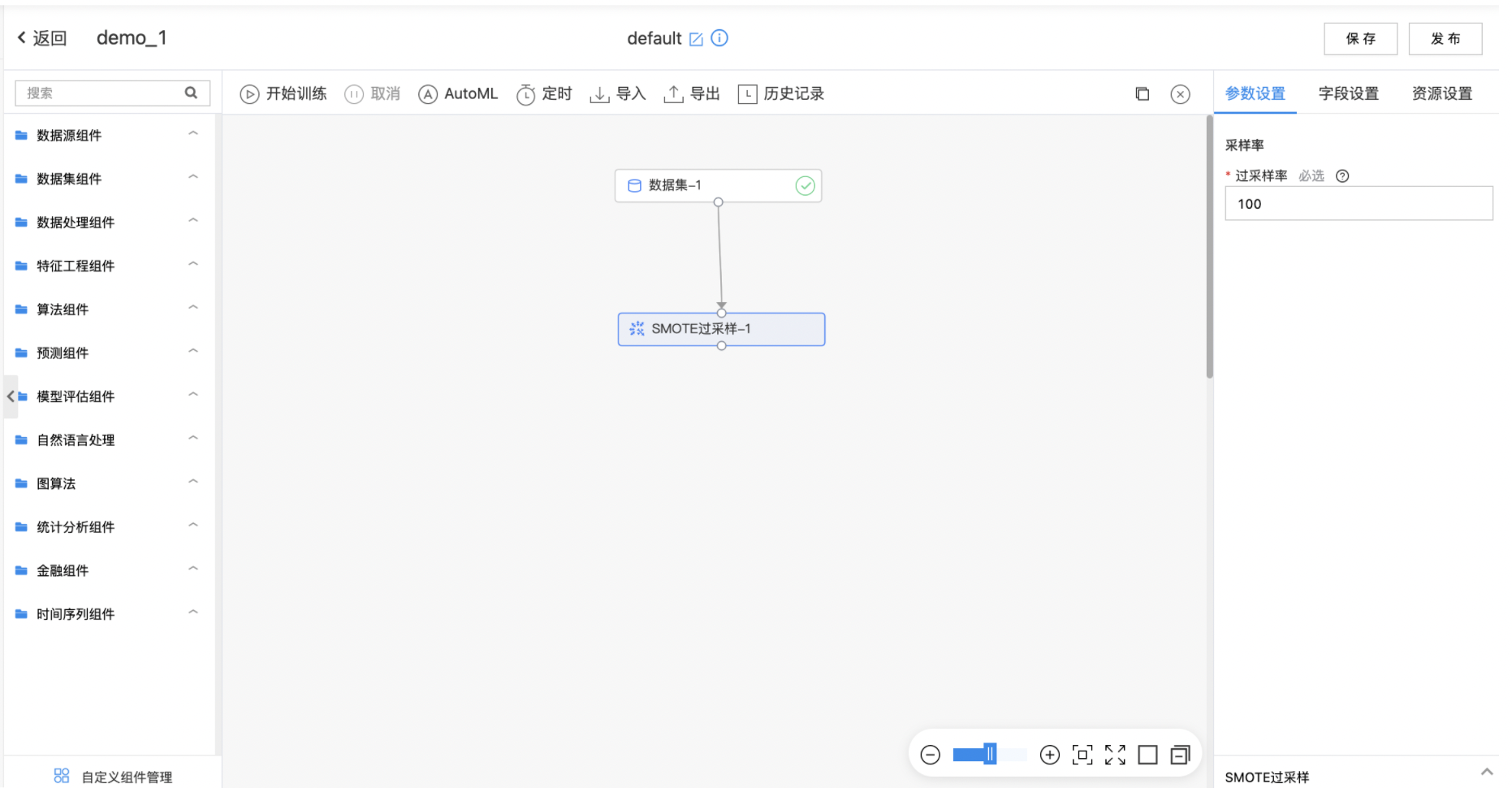
- 填写过采样率、过采样依赖的标签列与过采样标签。
输出
- SMOTE过采样后的数据集。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 过采样率 | 是 | 过采样扩充的样本数占当前该标签样本数的百分比,输入范围:[1,inf) | 100 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 标签列 | 是 | SMOTE过采样依据的标签列,即用户希望平衡的样本标签 | 无 |
| 过采样标签 | 是 | 要进行SMOTE过采样的标签,即用户希望扩充样本的类别 | 无 |
计算逻辑
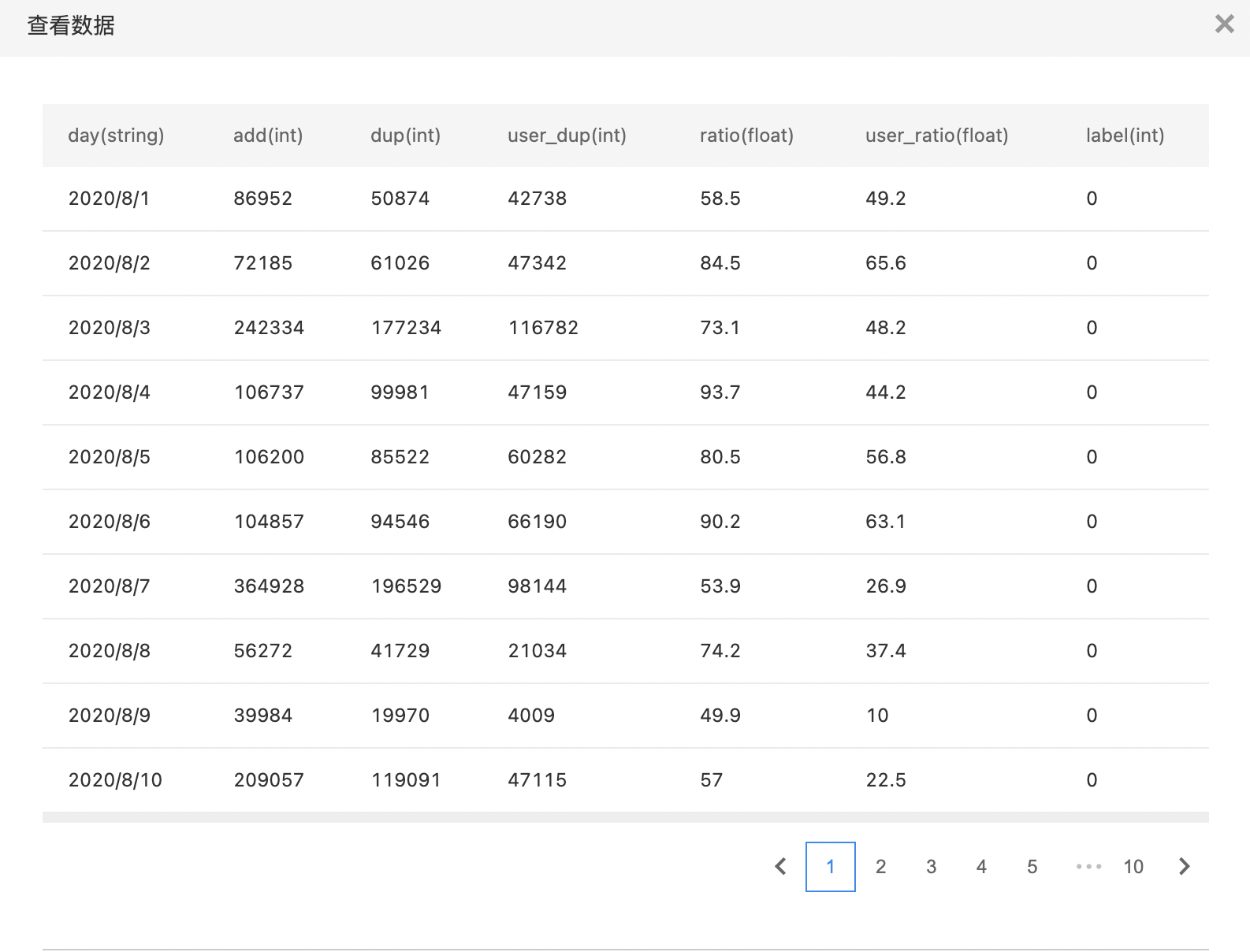
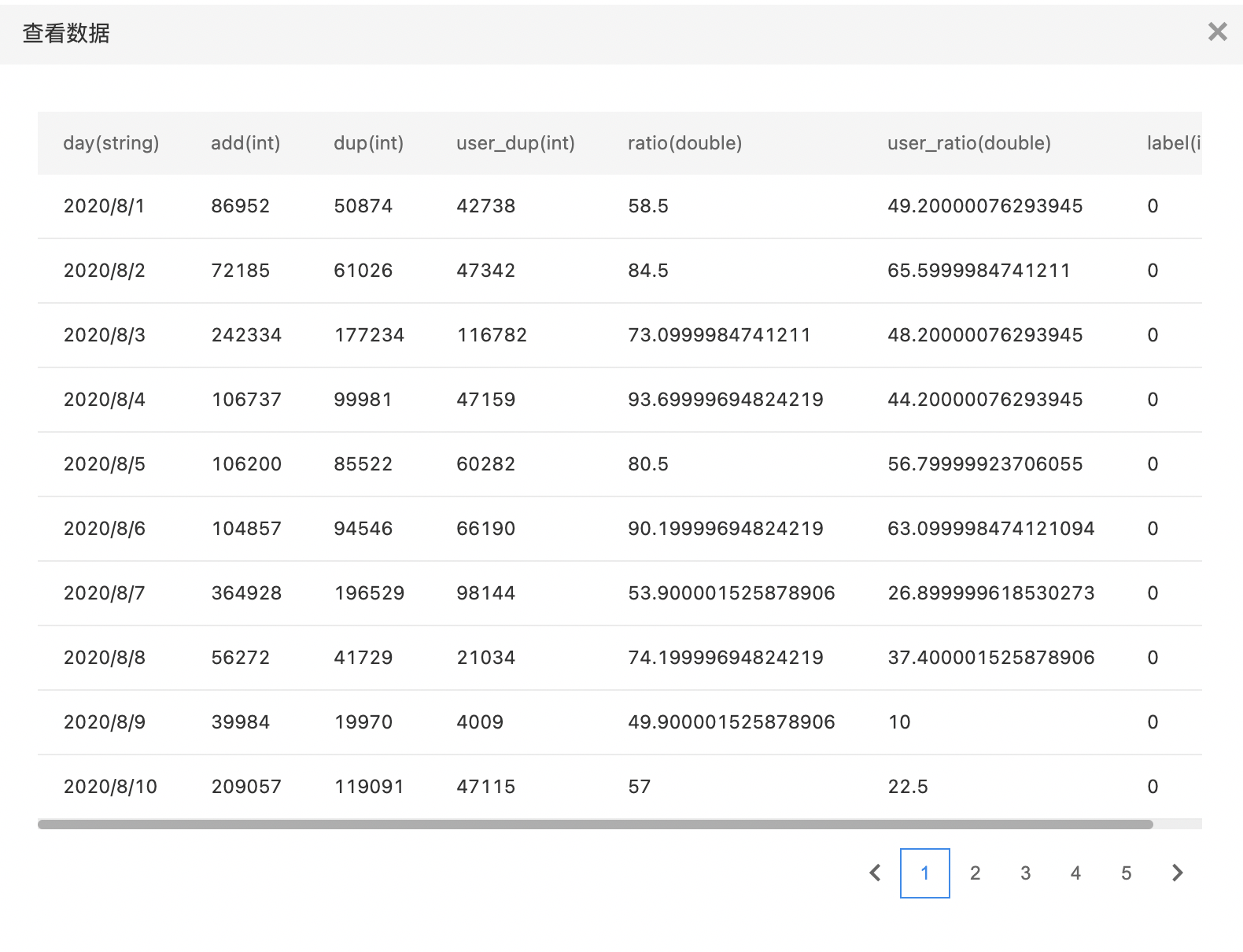
假设当前数据集存在10个样本类别为0,100个样本类别为1,过采样率输入50,标签列选择数据集对应的类别标签,过采样标签输入0,最终输出数据集为原始的10个类别为0的样本,100个类别为1的样本,还有过采样扩充的5个类别为0的样本,其中【扩充样本数=该标签样本数*过采样率】。
使用示例
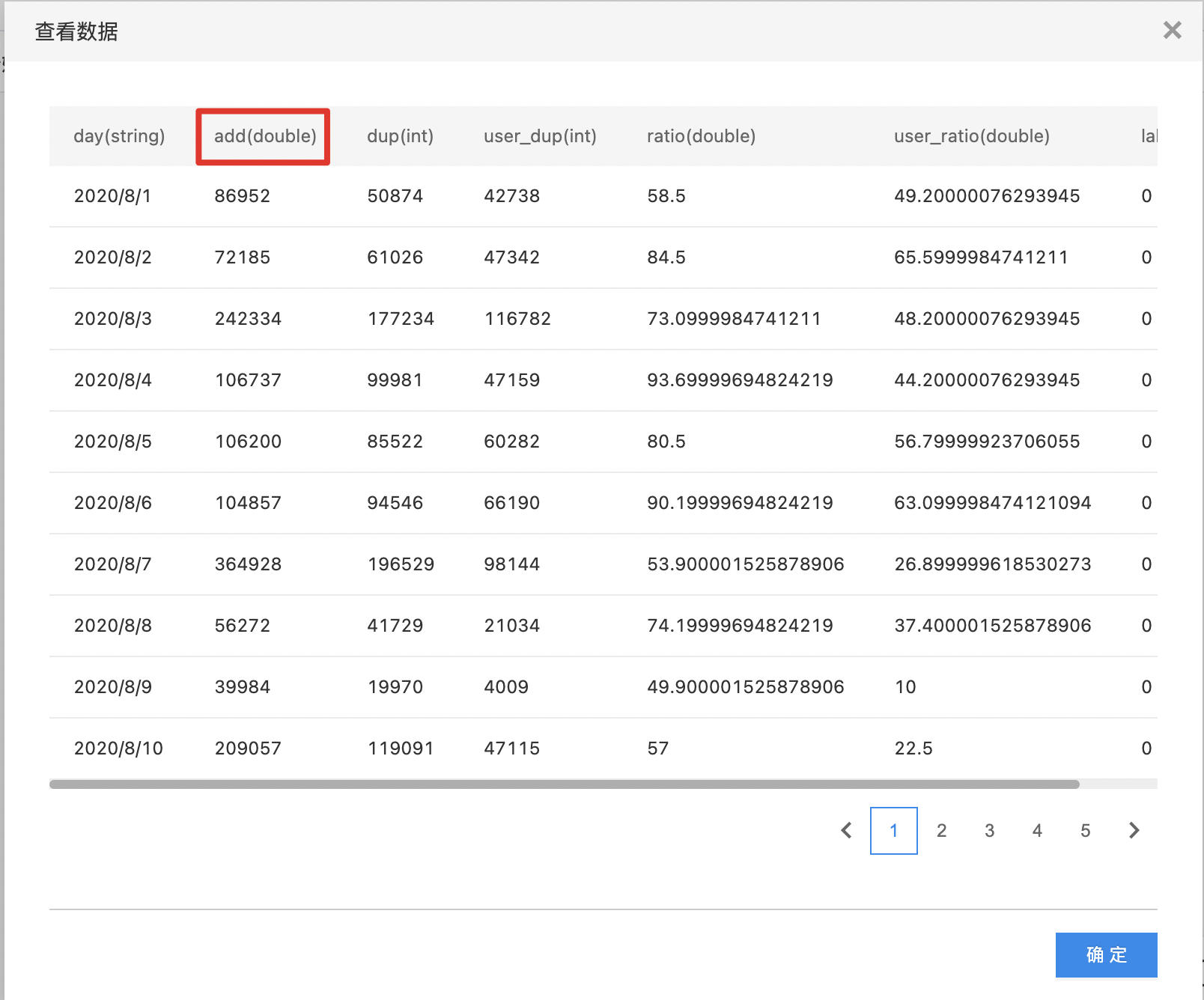
- 查看原始数据,此数据集中包含110个样本,其中10个样本类别为0,100个样本类别为1。
- 构建算子结构,配置参数,完成训练。
- 运行完成后查看扩充数据,最新数据集包含120个样本,其中20个样本类别为0,100个样本类别为1。
简单采样
简单采样提供了三种采样方式,即随机采样、分层采样、权重采样,采样量计算方式可以选择比例计算与数量计算。
输入
- 输入一个数据集,根据需要选择不同的采样方式,选择响应的键列与采样数计算方式。
输出
- 简单采样后的数据集。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 采样方式 | 是 | 选择采样的方式:RandomSampling - 随机采样、StratifiedSampling - 分层采样、WeightedSampling - 权重采样 | 无 |
| 分层键列 | 是 | 选泽用于分层采样的键列,不能是数组类型,采样结果的类别比例分层键列的分层比例一致 | 无 |
| 权重值列 | 是 | 选择权重采样的权重值列,必须是数值类型,样本对应的该列值即被采样的概率,权重越大被采样的概率越大 | 无 |
| 采样量计算方式 | 是 | 采样量的计算方式:Nmuber - 数量方式、Ratio - 比例方式 | 无 |
| 采样比例 | 是 | 采样的比例,输入范围:[0.01,0.99] | 0.80 |
| 采样个数 | 是 | 采样的个数,输入范围:[1,inf) | 无 |
| 随机种子 | 否 | 采样过程是随机的,采样结果与随机种子输入的值相关,若其他参数不变,随机种子输入一样的值,那么采样结果也是相同的 | 0 |
| 是否放回采样 | 是 | 采样过程中是否放回样本 | 关闭 |
计算逻辑
随机采样:系统随机从数据集中采集样本,随机种子的输入值不同导致采样结果不同。
分层采样:选择分层键列,假设分层键列为性别,其中男性与女性的比例为6:4,那么采样结果的样本比例也为6:4。
权重采样:选择权重值列,假设权重值列为班级,样本A的班级序号为2,样本B的班级序号为1,则样本A被采样的概率为样本B的2倍。
采样数:最终的采样数依赖于采样量计算方式,假设原始数据集样本数为100,如果选择数量方式,则最终数据集的采样数量与输入数量一致,如果选择比例方式,比例为0.8,则最终数据集的采样数量80。
使用示例
如下图所示,构建算子结构,配置采样条件,运行后得到采样结果。

欠采样
为解决样本不平衡问题,欠采样对多数类别样本进行分析,并去除部分多数类别样本,进而使原始数据中的类别不再严重失衡。
输入
- 输入一个数据集,填写采样率、欠采样依赖的标签列与欠采样标签。
输出
- 欠采样后的数据集。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 采样率 | 是 | 欠采样后该标签样本数占原该标签样本数的百分比,输入范围:[0.01,0.99]。 | 0.5 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
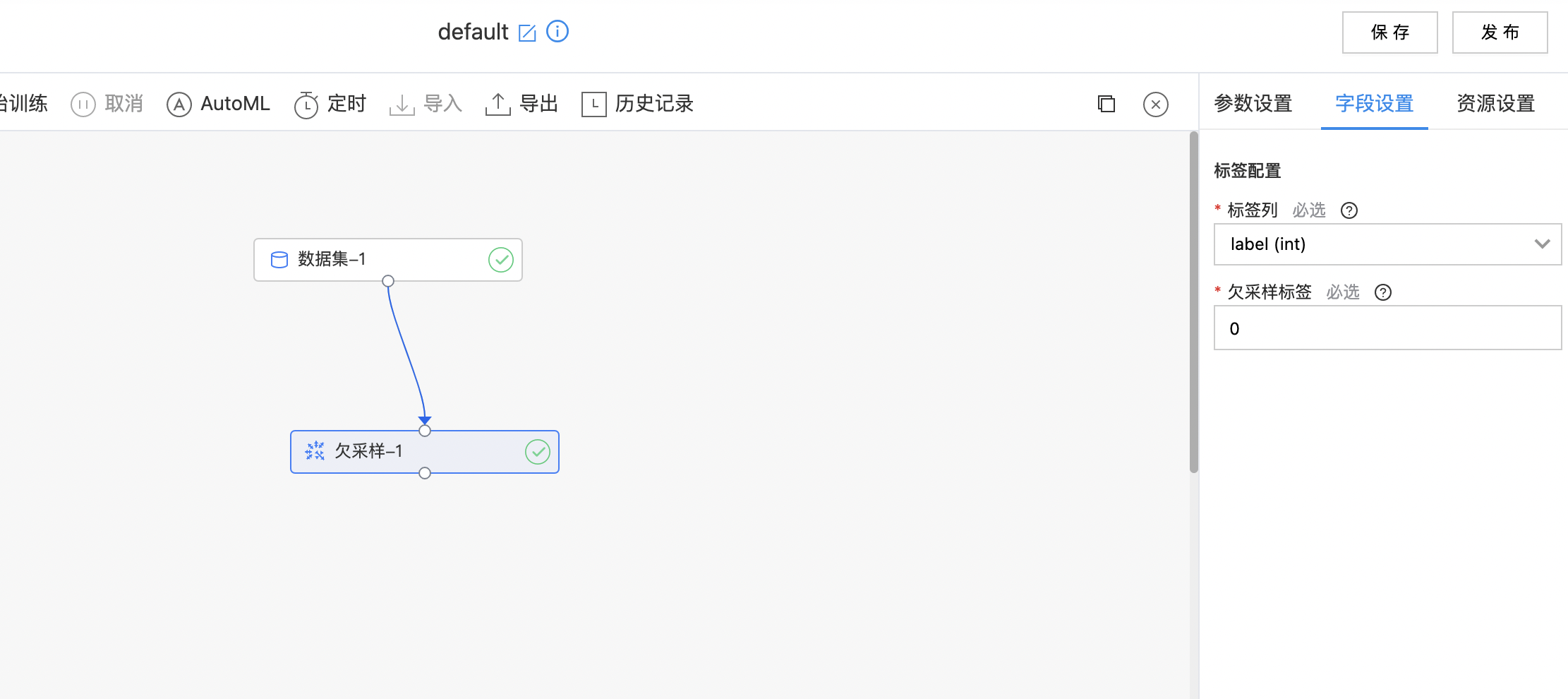
| 标签列 | 是 | 欠采样依据的标签列,即用户希望平衡的样本标。 | 无 |
| 欠采样标签 | 是 | 要进行欠采样的标签,即用户希望缩减样本的类别。 | 无 |
计算逻辑
假设当前数据集存在10个样本类别为0,100个样本类别为1,欠采样率输入0.5,标签列选择数据集对应的类别标签,过采样标签输入1,最终输出数据集为原始的10个类别为0的样本,50个类别为1的样本。
使用示例
如下图所示,构建算子结构,配置需要欠采样的标签,运行后得到采样结果。
列选择
选择需要保留的数据列组合成为一个新的数据集作为输出。
输入
- 上游数据集组件中选择的数据集,选择需要保留的数据列。
输出
- 输出数据集的列名称顺序与选择的列顺序一致;可用于修改列的顺序。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
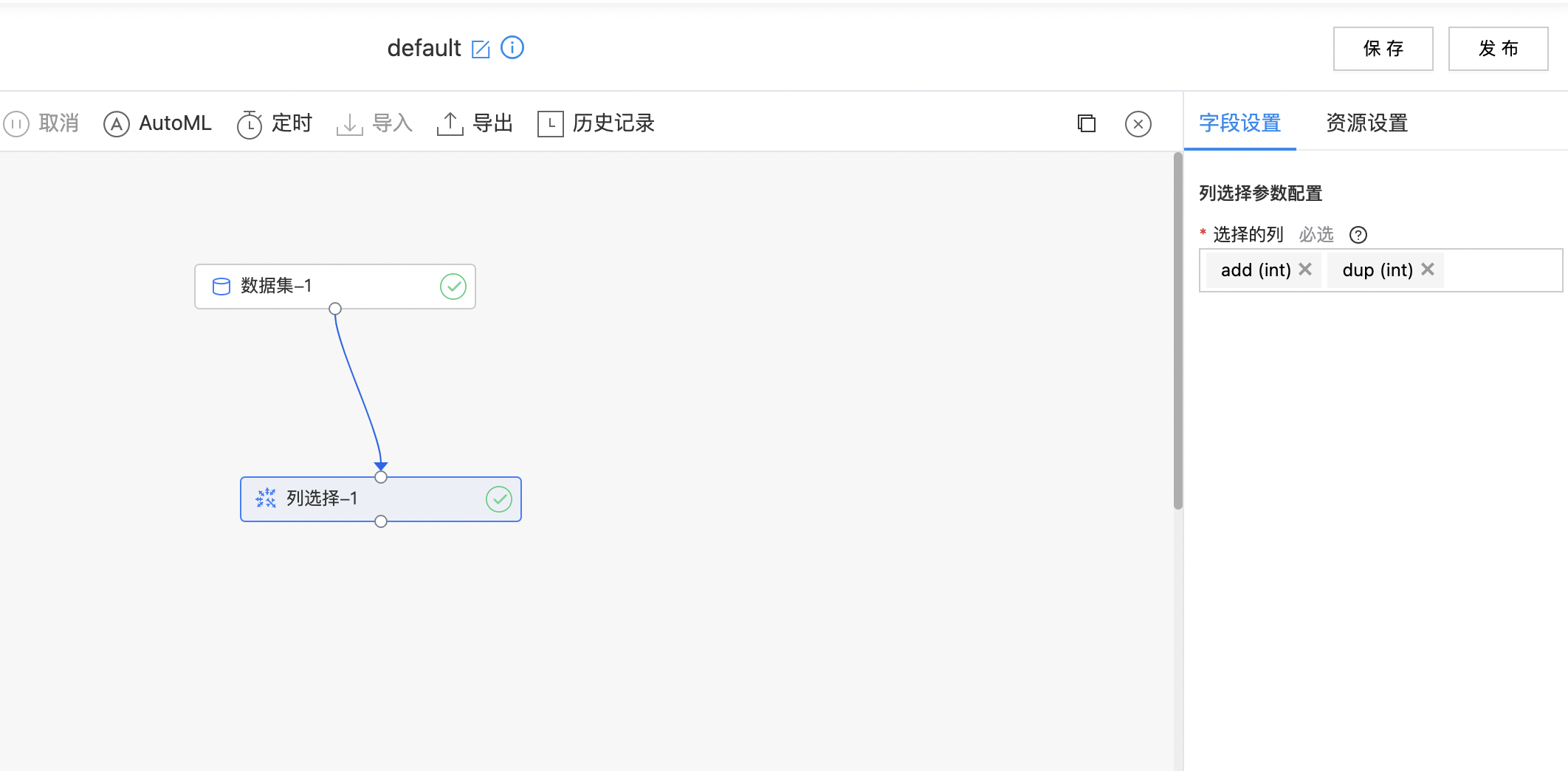
| 选择的列 | 是 | 选择需要保留的列,可多选 | 无 |
使用示例
- 如下图所示,构建算子结构,选择需要的数据列。
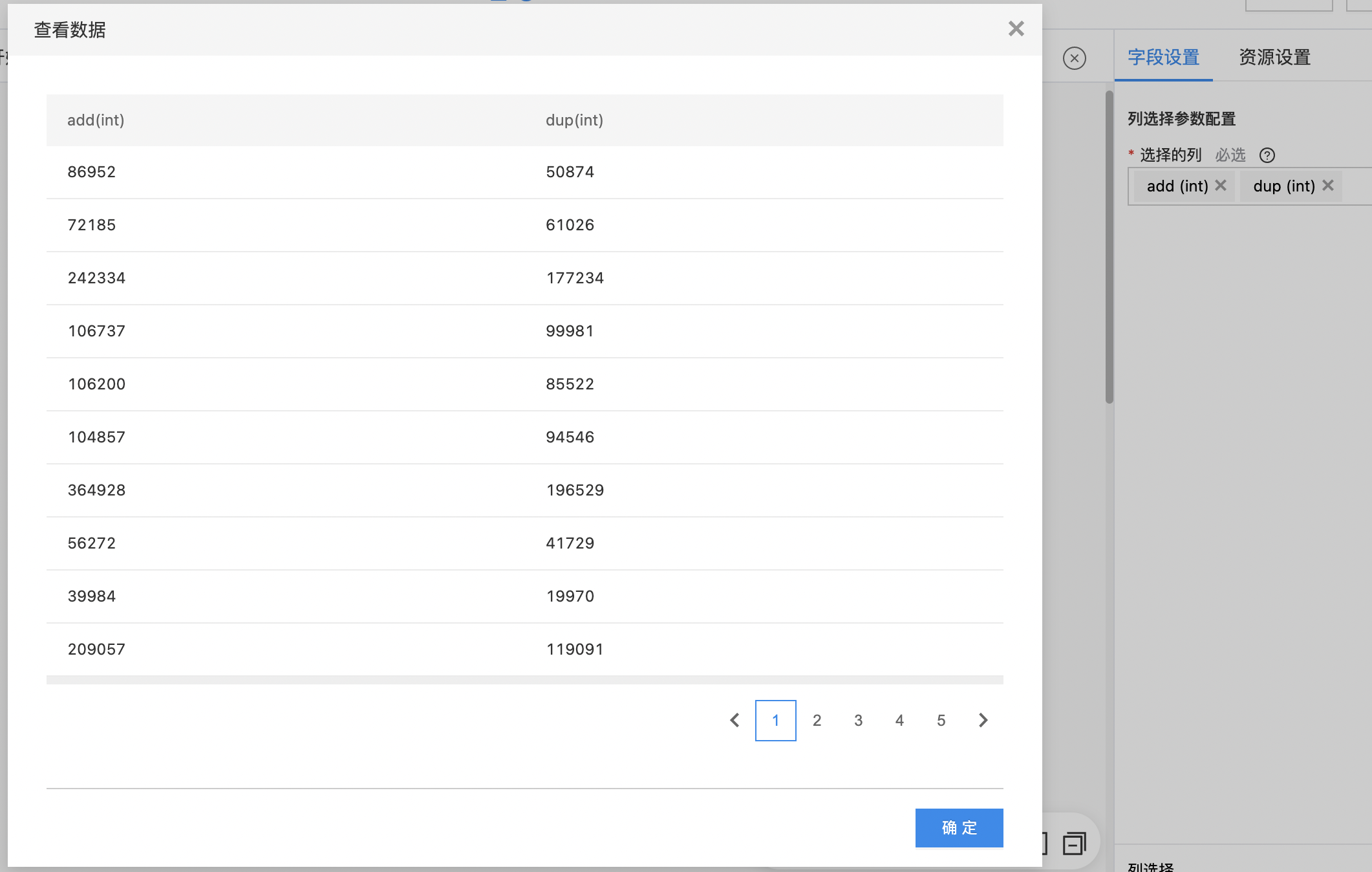
- 查看列选择结果。
数据类型转换
选择需要进行类型转换的列, 经过数据类型转换,得到目标类型的列,并替换原始数据集对应列。
输入
- 输入一个数据集,选择需要转换类型的列。
输出
- 输出一个数据集,需要转换数据类型的列已经完成转换并替换原始数据对应列。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输出类型 | 是 | 目标转换类型,目前支持整型,双精度浮点型,字符串之间的相互合法转换,以及字符串合法转换成时间戳、日期 | 字符串 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
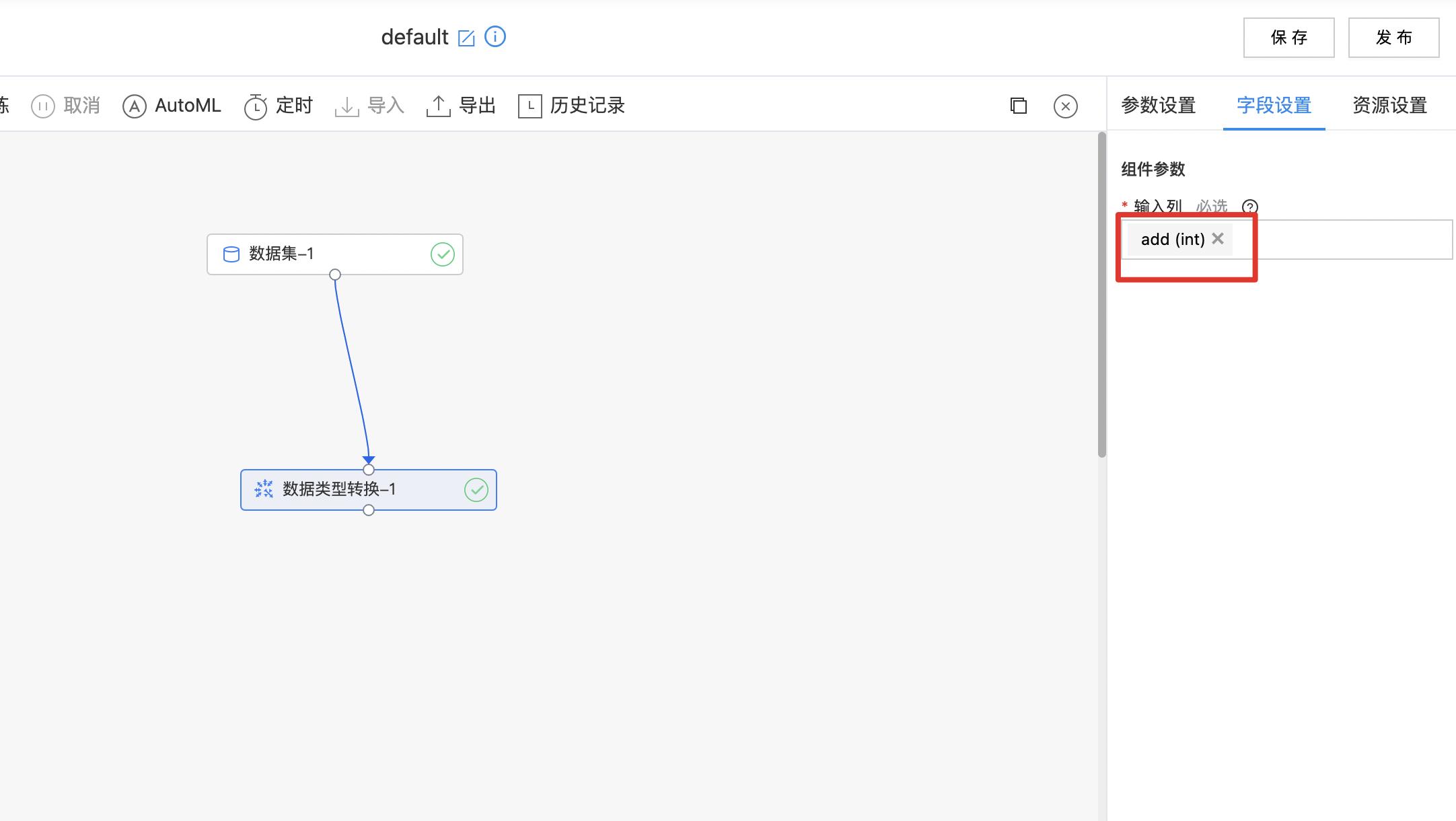
| 输入列 | 是 | 选择需要进行类型转换的列 | 无 |
特殊格式说明
时间戳字符串支持格式,时间单位:yyyy(年)|MM(月)|dd(日)|HH(时[0,23])|mm(分)|ss(秒),不同的时间单位可以任意顺序组合且之间的连接是特殊符号即可(例如/、-、#、@等),例如yyyy-MM-dd HH:mm:ss(默认)。
日期字符串支持格式,时间单位:yyyy(年)|MM(月)|dd(日),不同的时间单位可以任意顺序组合且之间的连接是特殊符号即可(例如/、-、#、@等),例如yyyy-MM-dd(默认)。
使用示例
- 如下图所示,构建算子结构,选择需要转换数据类型的列。
- 查看数据类型转换结果。
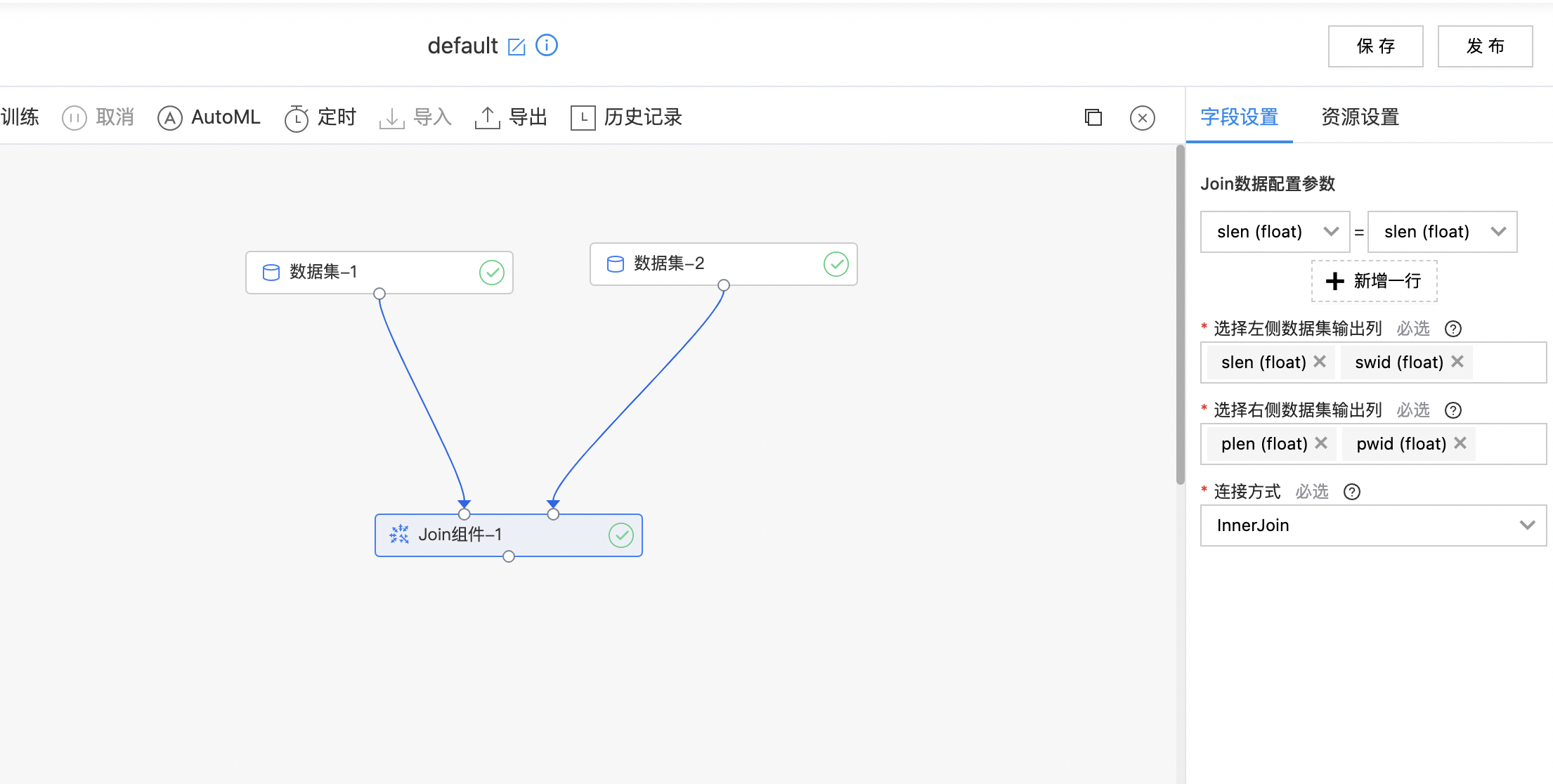
Join组件
输入两个数据集,用户选择两个数据集用于Join的Key键列和指定的Join方式进行数据连接。
输入
- 输入两个数据集,用户分别选择左侧与右侧的数据集连接键列(单选),再分别选择左侧和右侧的数据集输出列(多选),最后选择Join连接方式。
输出
- 输出Join操作后的结果数据集。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 左侧数据集连接键列 | 是 | 选择左侧的数据集连接键列,支持多键列 | 无 |
| 右侧数据集连接键列 | 是 | 选择右侧的数据集连接键列,支持多键列 | 无 |
| 选择左侧数据集输出列 | 是 | 选择左侧数据集需要的输出列(多选),选择的输出列名称不能重复 | 无 |
| 选择右侧数据集输出列 | 是 | 选择右侧数据集需要的输出列(多选),选择的输出列名称不能重复,当与左侧数据集列名称重复时,列名称默认会加前缀right_ | 无 |
| 连接方式 | 是 | 两个输入数据集的Join连接方式,支持FullOuterJoin - 全连接、InnerJoin - 内连接、LeftOuterJoin - 左连接、RightOuterJoin - 右连接 | InnerJoin |
使用示例
- 如下图所示,构建算子结构,选择需要join处理的列。
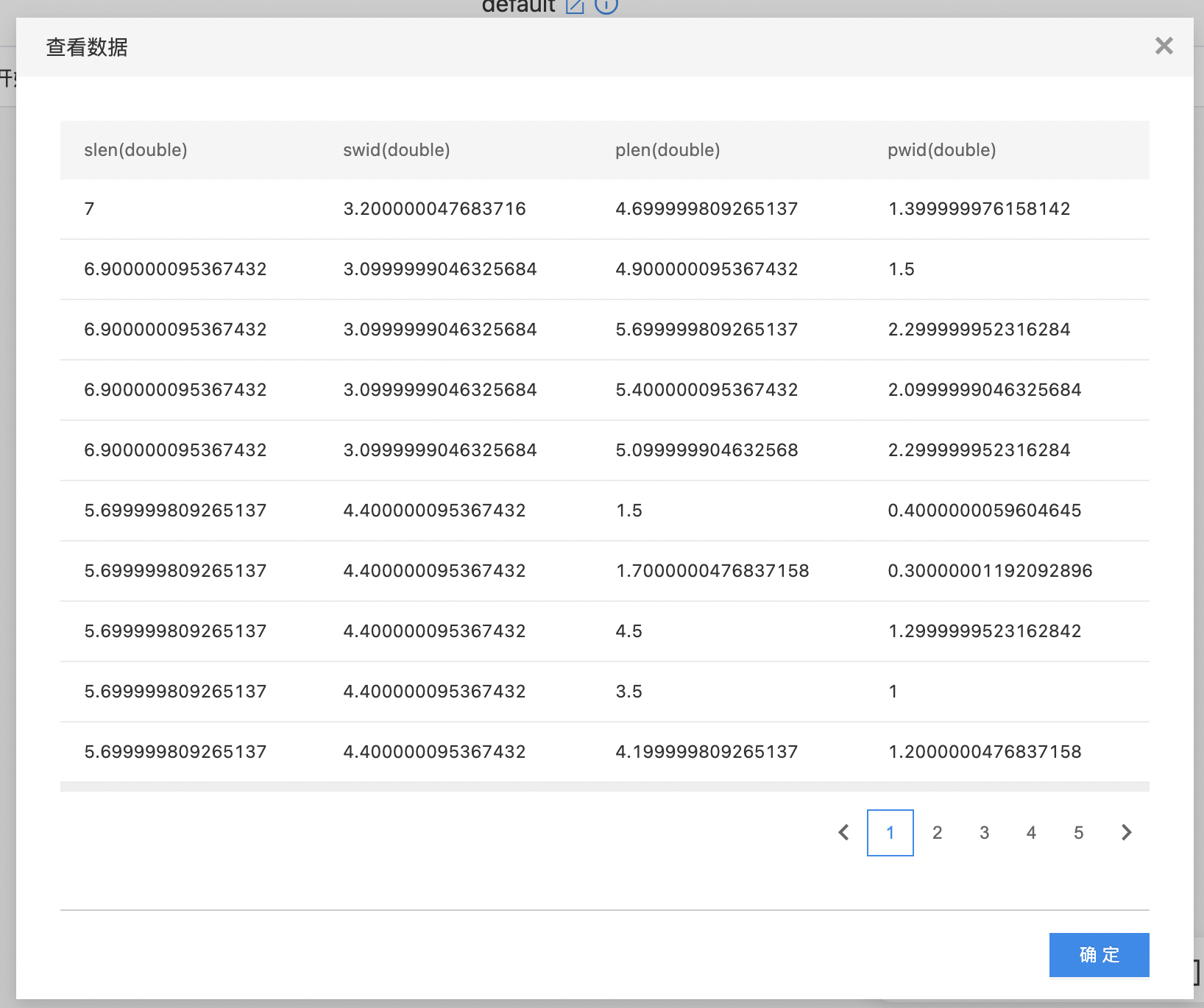
- 查看结果数据集。
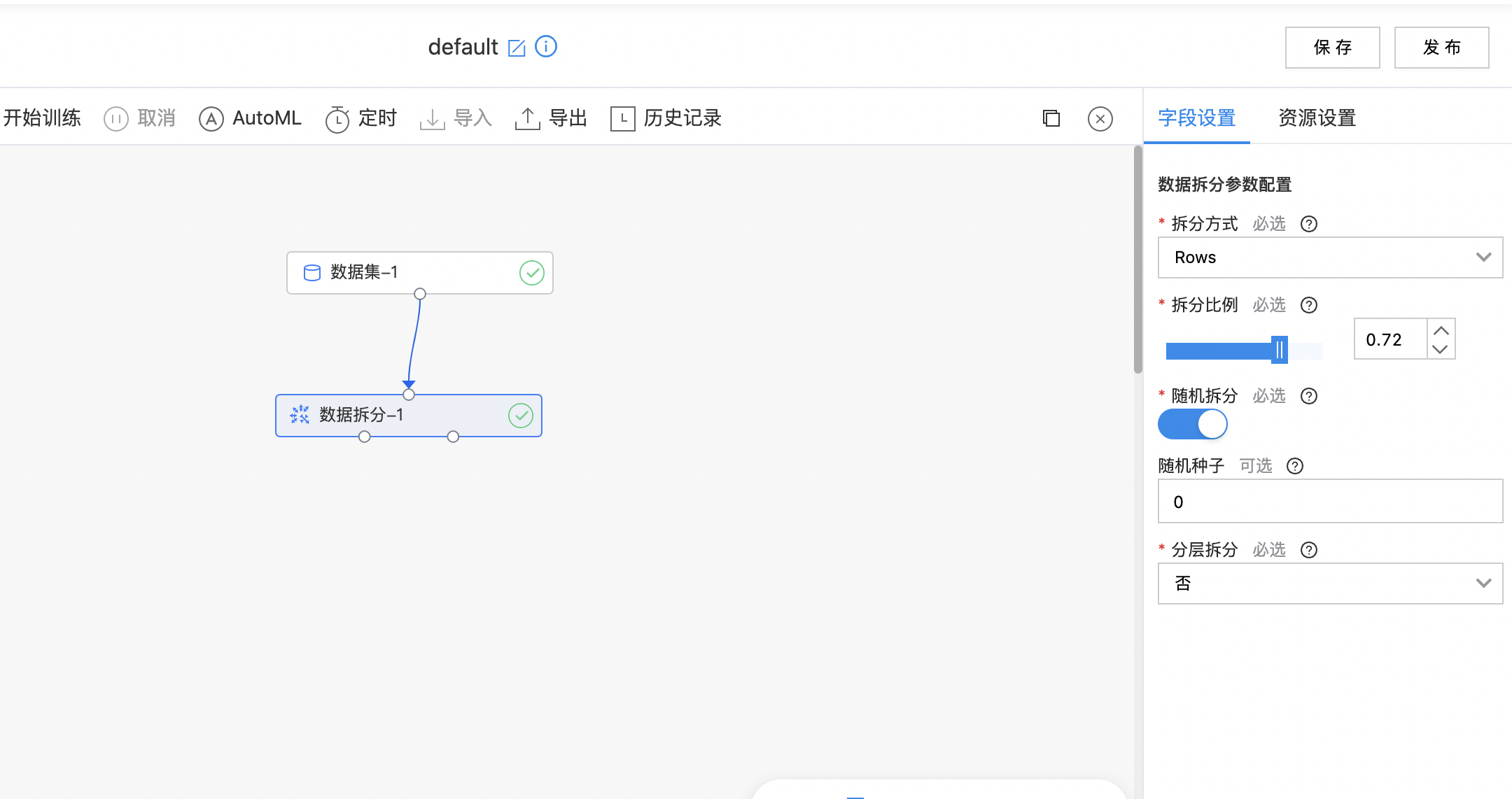
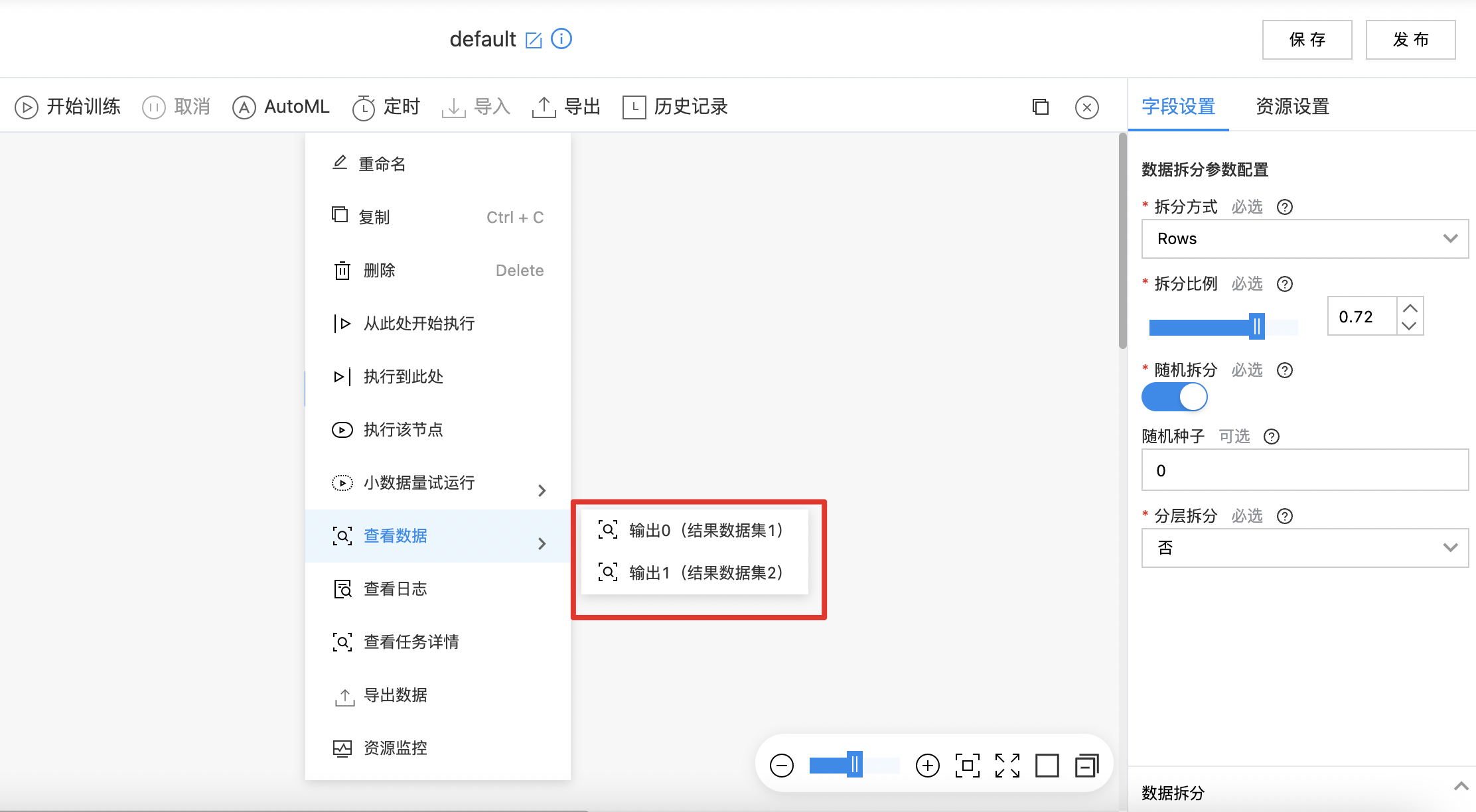
数据拆分
数据拆分组件可以根据拆分条件,将数据集拆分为两个数据集。
输入
- 输入一个数据集,选择数据拆分方式、拆分比例等参数。
输出
- 输出拆分后的两个数据集。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 拆分方式 | 是 | 选择数据集的拆分方式名,支持:Rows - 行拆分、Times - 时间戳拆分、Date - 日期拆分 | Rows |
| 拆分比例 | 是 | 选择数据集的拆分比例,输入范围[0.01,0.99] | 0.80 |
| 随机拆分 | 是 | 是否随机拆分开关 | 开启 |
| 随机种子 | 否 | 随机种子初始值 | 0 |
| 分层拆分 | 是 | 是否选择分层拆分 | 否 |
| 用于分层拆分的列名称 | 是 | 选择分层拆分后,拆分后的两个数据集内样本类别比例与拆分键列的分类比例一致 | 无 |
| 时间列 | 是 | 时间拆分方式下,选择用于拆分的时间列列名,要求是时间戳类型, 格式: 2006-01-01 00:00:00 | 无 |
| 日期列 | 是 | 用于拆分的日期列列名, 要求是date类型, 格式: 2006-01-01 | 无 |
| 时间阈值 | 是 | 时间戳阈值, 拆分后小于此时间戳的为一组数据, 大于等于此时间戳的为后一组数据, 格式: 2006-01-01 00:00:00 | 2006-01-01 00:00:00 |
| 时间阈值格式 | 是 | 上述时间戳阈值的格式,按照 java.text.SimpleDateFormat 的标准填写 | yyyy-MM-dd |
计算逻辑
拆分比例:假设数据集A样本数为100,拆分比例输入0.6,则拆分后的数据集B含样本数60,数据集C含样本数40。
分层拆分:假设数据集A样本数为100,其中40个样本为类别0,60个样本为类别1,拆分比例输入0.6,选择分层拆分列为性别,该列的类别比例男:女为5:5,最终的拆分结果为数据集B包含60个样本,其中30个样本类别为0,30个样本类别为1,其余样本被拆分至数据集C。
使用示例
- 如下图所示,构建算子结构,配置拆分方式。
- 拆分为两个数据集,右键可查看结果。
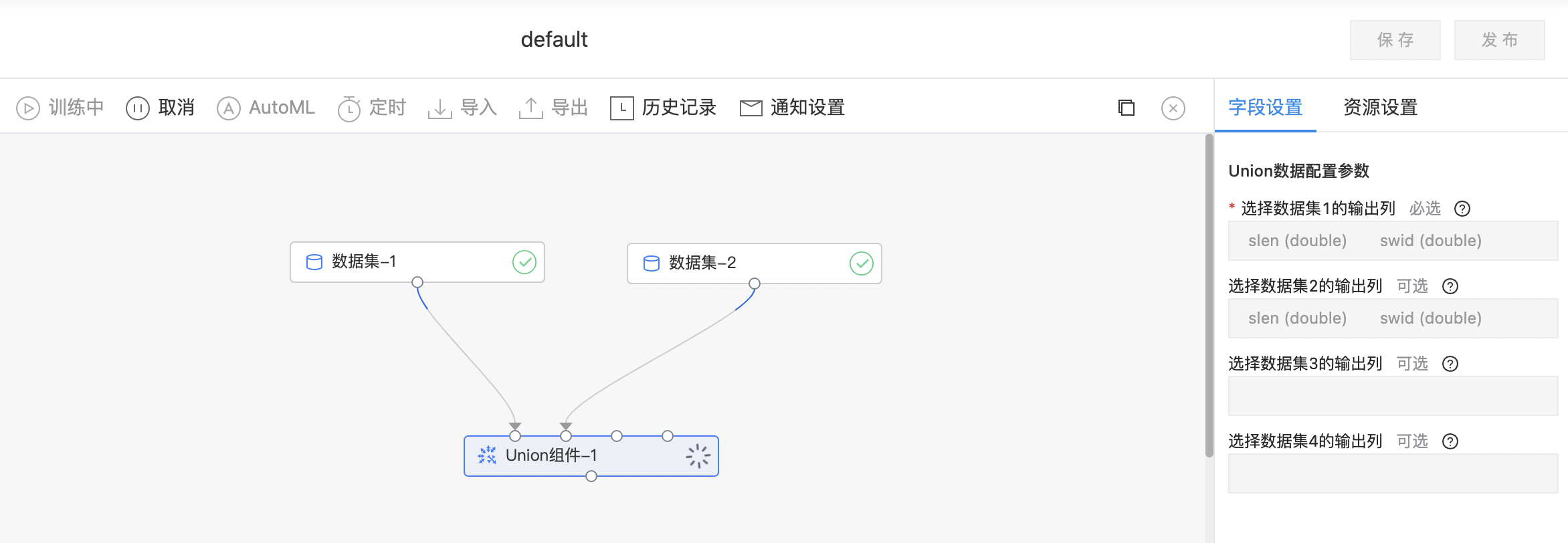
Union组件
Union组件将两个数据集通过Union操作合并成一个数据集,要求两个数据集的列名、列数和schema一致。
输入
- 可输入四个数据集,用户分别选择对应数据集需要输出的列。
输出
- 输出Union操作后的结果数据集。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 选择左侧数据集输出列 | 是 | 选择左侧数据集输出列名称,选择的输出列名称不能重复 | 无 |
| 选择右侧数据集输出列 | 是 | 选择右侧数据集输出列名称,选择的输出列名称不能重复 | 无 |
使用示例
如下图所示,构建算子结构,选择需要输出的列。
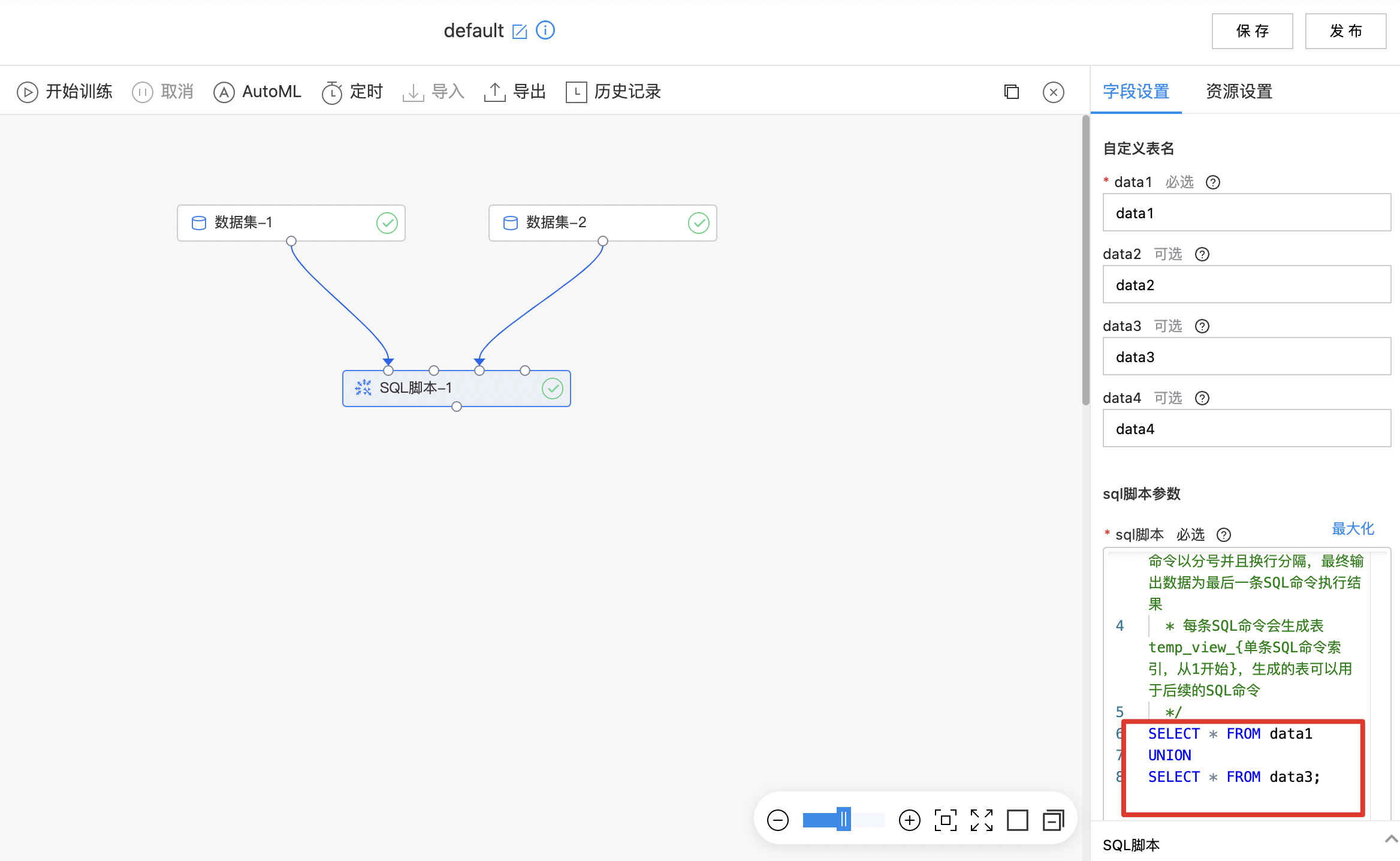
SQL脚本
SQL脚本组件支持最多输入四个数据集,利用自定义SQL语句对数据集进行查询操作,查询结果作为最终输出数据。
输入
- 输入1~4个数据集,数据表名默认映射为data1、data2、data3、data4,表名也可自定义,编辑SQL语句查询数据表。
输出
- 根据SQL语句查询结果输出数据集。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| data1 | 是 | 输入表名1,由字母、数字和下划线组成,第一个字符必须是字母 | data1 |
| data2 | 否 | 输入表名2,由字母、数字和下划线组成,第一个字符必须是字母 | data2 |
| data3 | 否 | 输入表名3,由字母、数字和下划线组成,第一个字符必须是字母 | data3 |
| data4 | 否 | 输入表名4,由字母、数字和下划线组成,第一个字符必须是字母 | data4 |
| sql脚本 | 是 | 输入数据表的名字已自动映射为 data1 data2 data3 data4,也可以自定义数据表名;支持多条SQL命令,每条SQL命令以分号并且换行分隔,最终输出数据为最后一条SQL命令执行结果;每条SQL命令会生成表 tempview{单条SQL命令索引,从1开始},生成的表可以用于后续的SQL命令 |
使用示例
- 拖入两个数据集组件:数据集-1、数据集-2
- 拖入sql脚本组件,将数据集-1和数据集-2分别连接至组件的第一输入节点和第三输入节点,编写sql脚本并运行算子节点
- 算子运行完成后查看输出数据
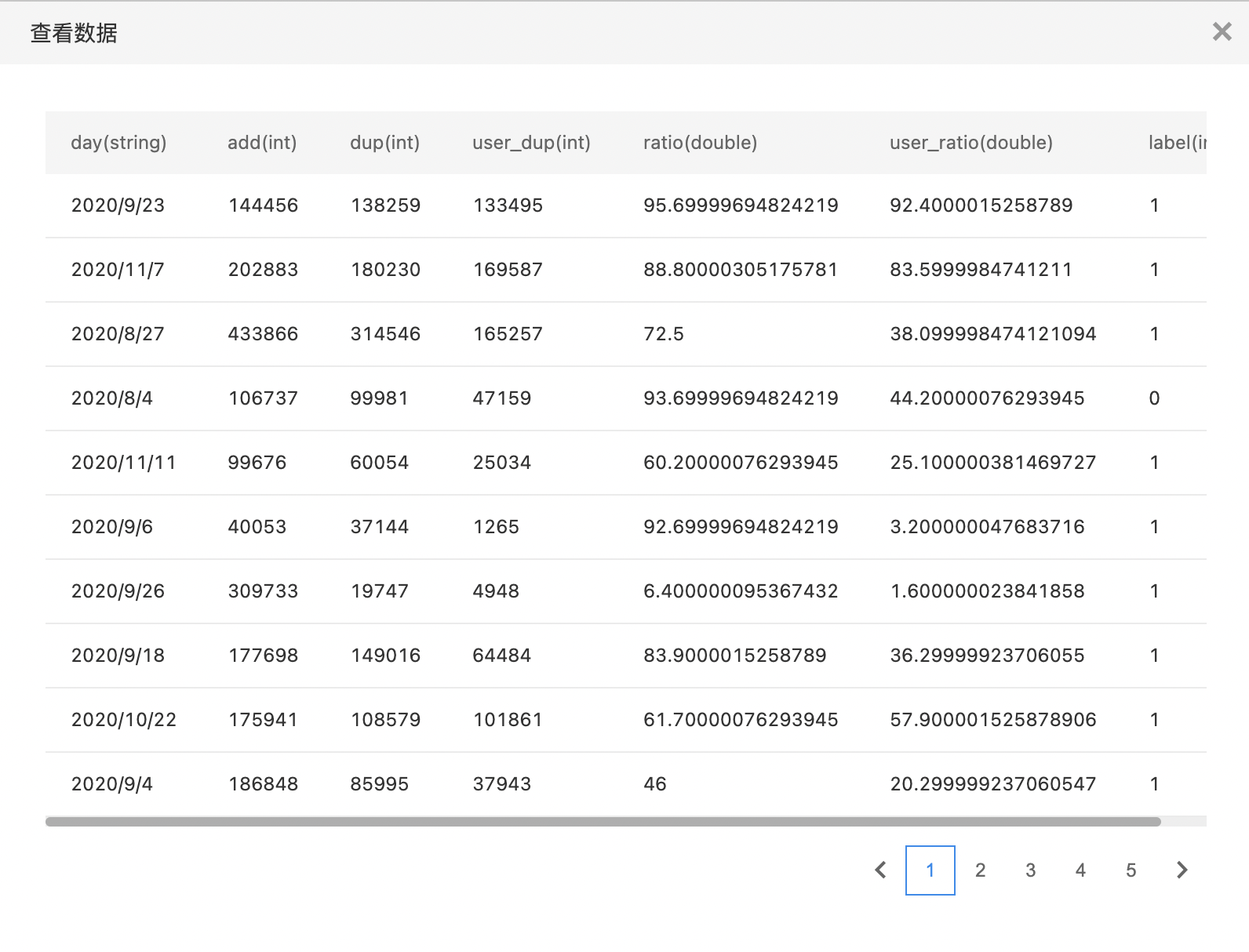
特征探索工具
Featuretools 使用 DFS(深度特征合成)进行自动化特征工程。可以结合原始数据以及对数据的理解为机器学习和预测建模构建有意义的特征,它通过时间和关系数据集自动创建特征。
输入
- 输入最多四个数据集。用于构建时间以及关系数据集(实体集)。
输出
- 输出是一个数据集,包含由DFS自动衍生的特征,可以选择与某个(非空)输入数据集进行合并输出。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
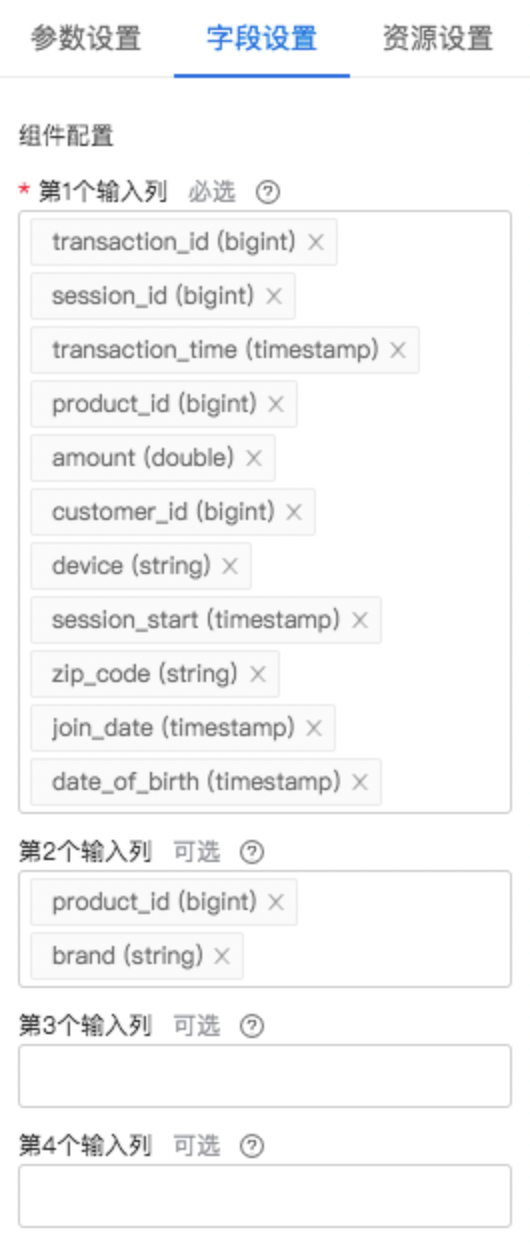
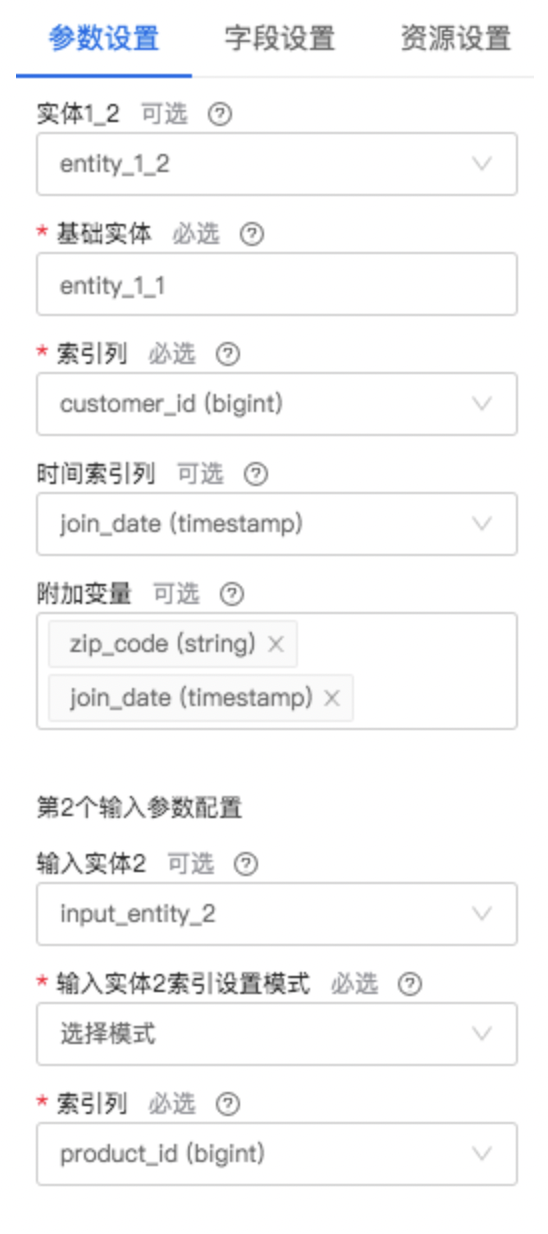
| 输入实体1 | 是 | 加载第1个输入(列)数据作为一个实体,并添加至实体集 | 无 |
| 索引设置模式 | 是 | 提供两种模式:生成模式、选择模式,选择模式需要选择索引列 | 无 |
| 时间索引列 | 否 | 输入实体1的时间索引列,需要存在于第1个输入列中,且需要是时间戳或日期类型 | 无 |
| 实体1_1 | 否 | 通过输入实体1创建实体1_1,并添加至实体集;输入实体1为其基础实体 | 无 |
| 索引列 | 是 | 输入实体1的索引列,需要存在于第1个输入列中,且需要是字符串或整数类型,且列中值唯一 | 无 |
| 附加变量 | 否 | 要从基础实体中删除并移至实体1_1的变量列表。需要包含于基础实体的数据框中;不能包含实体1_1及其基础实体的索引列;需要包含实体1_1的时间索引列;保留对应于索引列的数据 | 无 |
| 实体1_2 | 否 | 通过输入实体1或其已创建的实体1_1创建实体1_2,并添加至实体集 | 无 |
| 基础实体 | 是 | 实体1_2的基础实体,需要是输入实体1或其已创建的实体1_1 | 无 |
| 目标实体 | 是 | 要进行预测的实体,需要是实体集中已存在的实体 | 无 |
| 输出方式 | 是 | 提供5种输出方式:特征矩阵、第1个数据集左连接特征矩阵、第2个数据集左连接特征矩阵、第3个数据集左连接特征矩阵、第4个数据集左连接特征矩阵。如果选择左连接方式输出,则需要对应输入数据集存在 | 无 |
算子参数说明
特征探索工具组件最多可以输入4个数据集,上述表格仅是1个数据集的参数信息,与其余3个数据集的参数信息一致,不再赘述。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
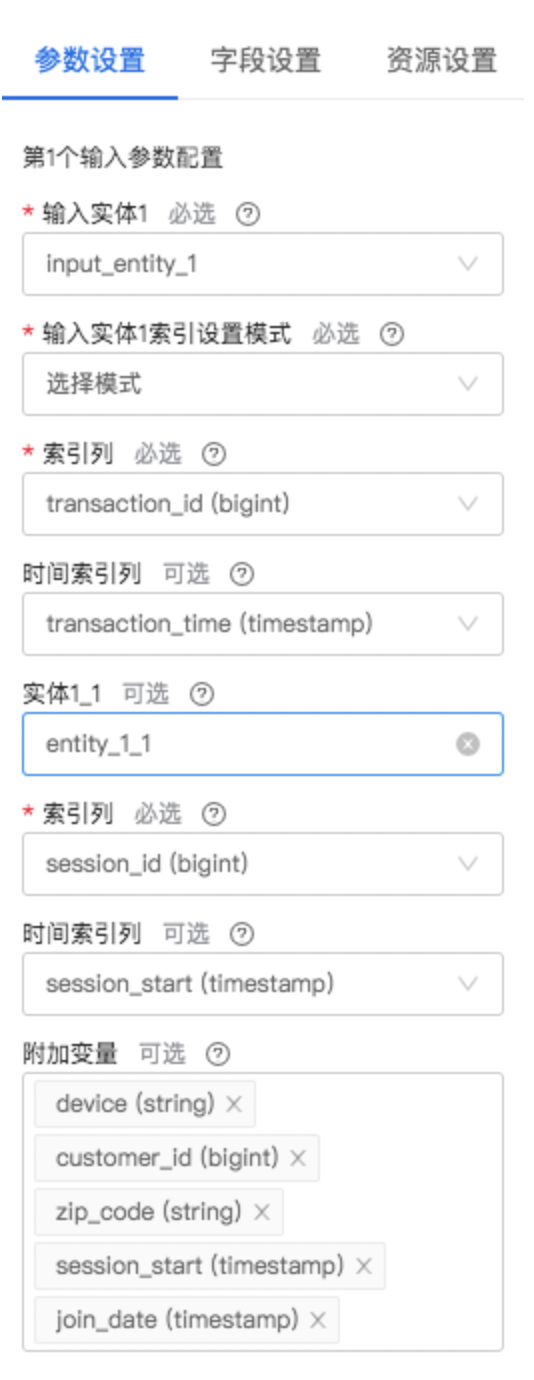
| 第1个输入列 | 是 | 深度特征合成使用的输入列,用于加载第1个输入数据作为一个实体,需要是非数组类型 | 无 |
| 第2个输入列 | 否 | 深度特征合成使用的输入列,用于加载第1个输入数据作为一个实体,需要是非数组类型 | 无 |
| 第3个输入列 | 否 | 深度特征合成使用的输入列,用于加载第1个输入数据作为一个实体,需要是非数组类型 | 无 |
| 第4个输入列 | 否 | 深度特征合成使用的输入列,用于加载第1个输入数据作为一个实体,需要是非数组类型 | 无 |
使用示例
首先对操作流程加以概述:
-
首先创建包含实体(及关系)的实体集(实体:单个数据集对象;实体集:多个关联的数据集对象)
1)先创建一个空的实体集 - 后端已实现(无需关心)
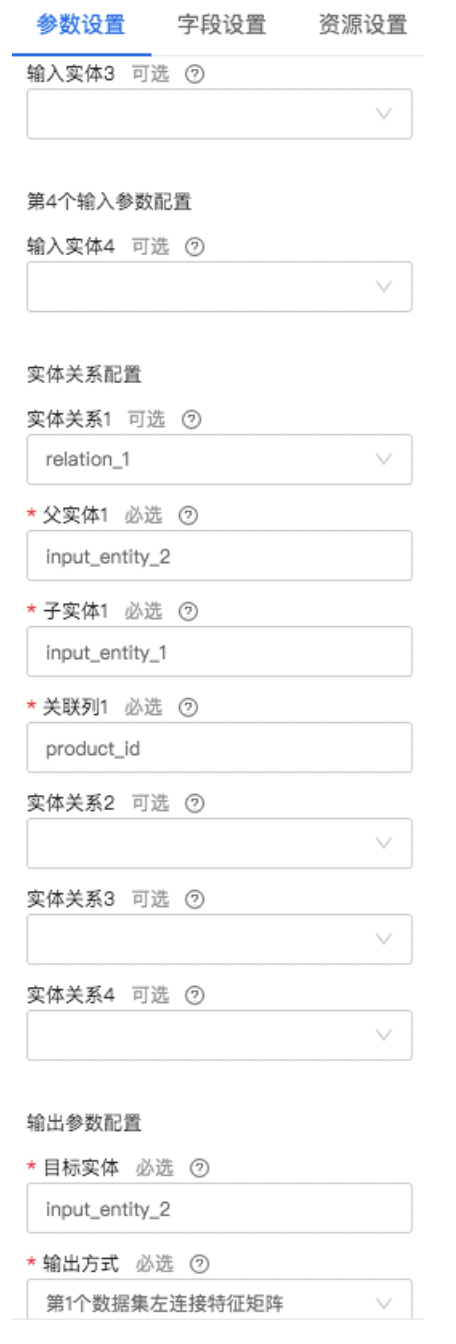
2)然后往实体集中添加实体:有两种添加实体的方式 - 需前端配置参数 - 直接加载单个数据集为一个实体:输入实体 - 通过已有实体创建一个新的实体:输入实体创建实体、输入实体创建的实体创建实体(包含实体间的一个关系,关系是由创建过程 中新实体索引列指定,创建的新实体为父实体,原实体为子实体,父实体数据与子实体数据针对索引列是一对多的关系)
3)添加关系:关联两个实体(父实体与子实体通过关联列构成数据一对多的关系) - 需前端配置参数
- DFS使用包含实体(及关系)的实体集:DFS会通过实体集及要进行预测的实体自动构建特征
1)选择实体集入口:目标实体 - 需前端输入实体集中已存在的实体(名称)
2)输出方式:DFS自动构建的特征或其连接输入特征 - 需前端选择
组件说明:最多支持4个输入数据集(用于创建输入实体)- 最多创建4个输入实体,每个输入实体最多关联创建2个实体,最多添加4个实体间关系
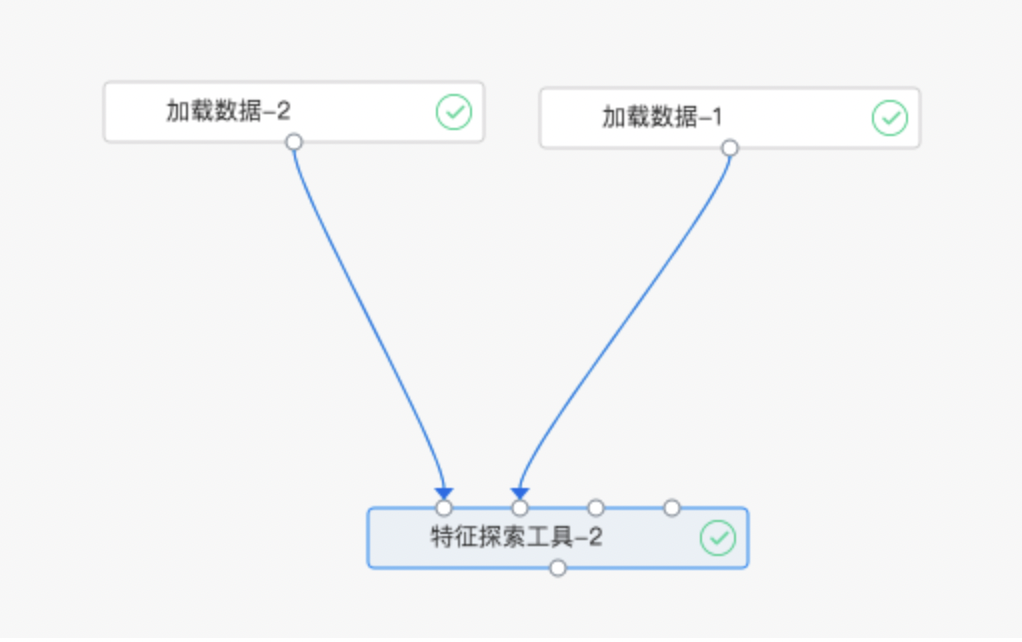
下面给出详细的配置图例:
-
算子组件连接图:
-
参数配置图:
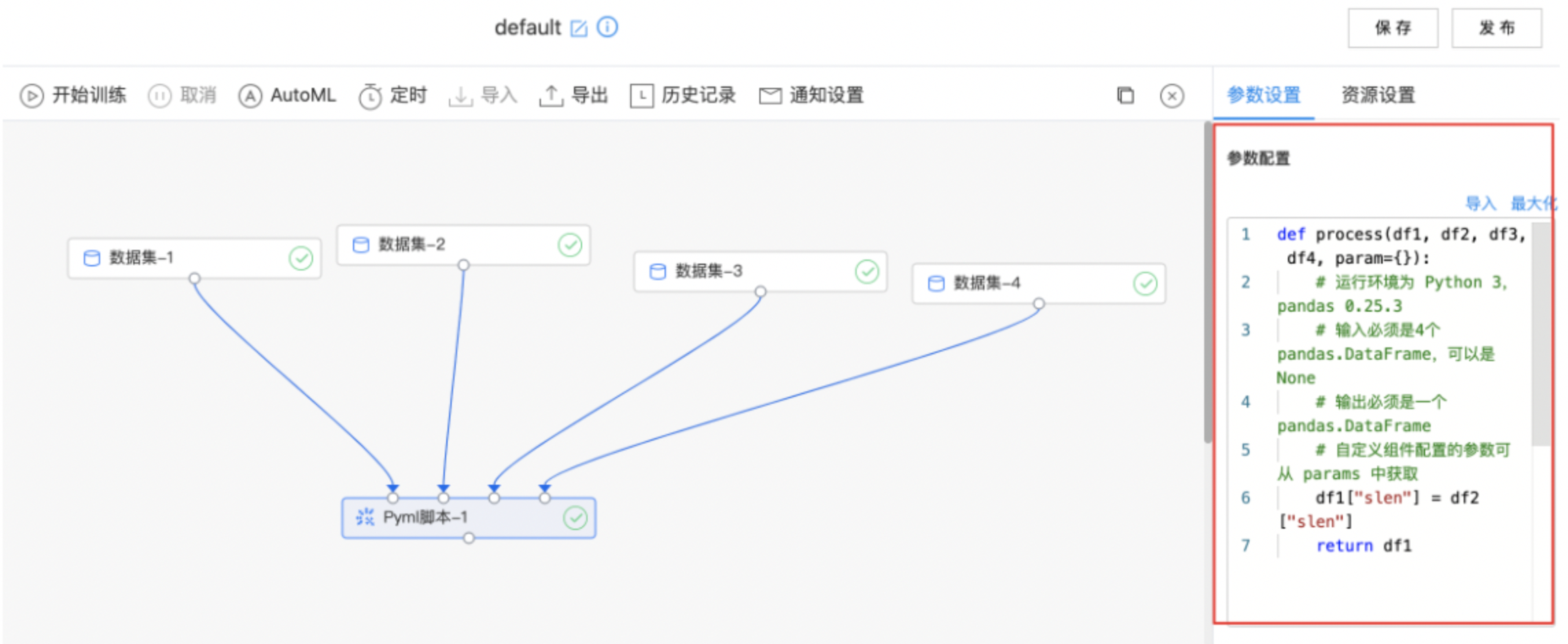
Pyml脚本
使用Pyml脚本组件处理数据。
输入
- 支持输入四个数据集,需要编写处理数据的Python代码。
输出
- 处理后的数据集。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python代码编辑窗口 | 是 | 在编辑窗口中编辑处理数据脚本 | 无 |
使用示例
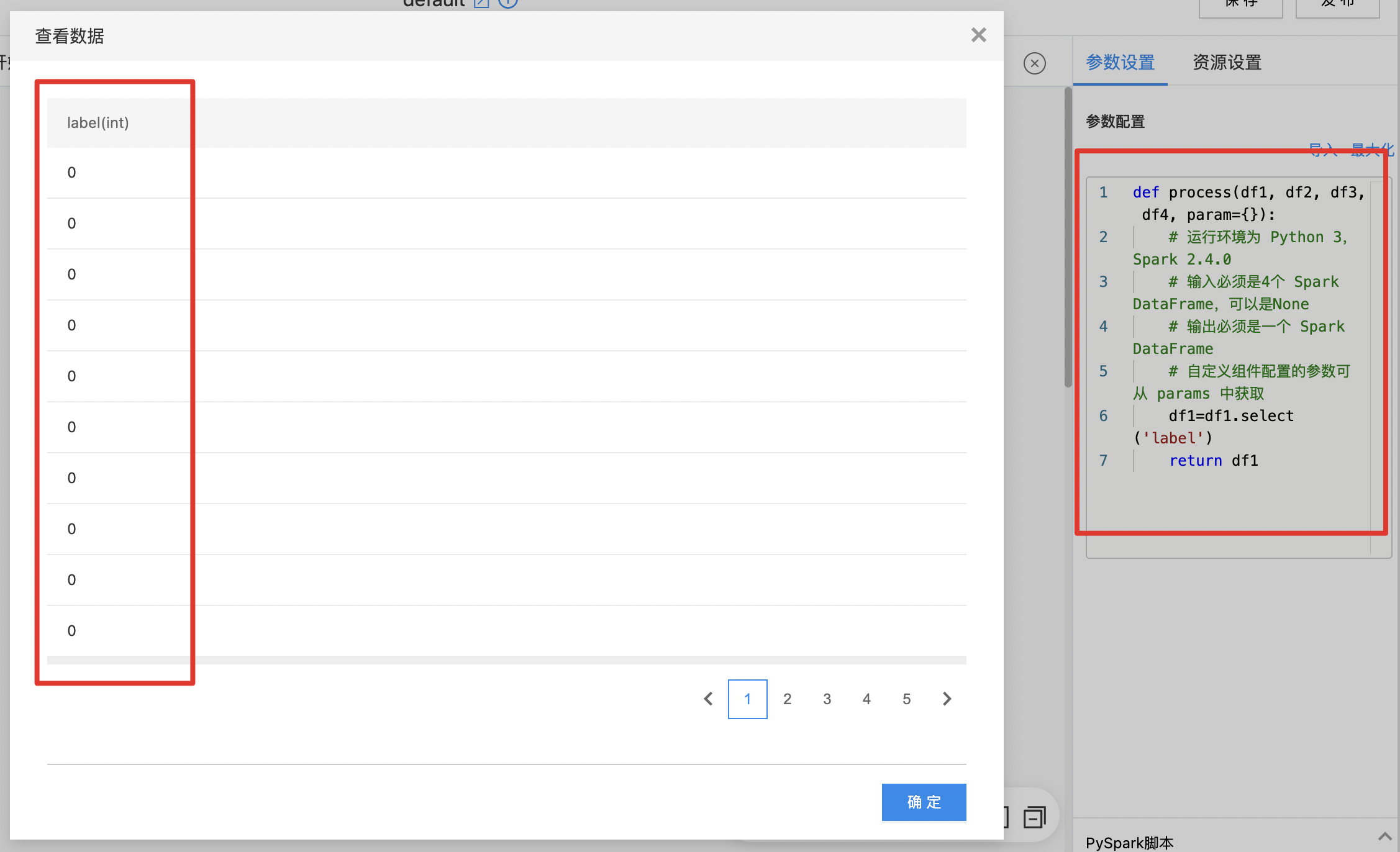
- 编写处理数据的Python代码,等待算子运行成功。
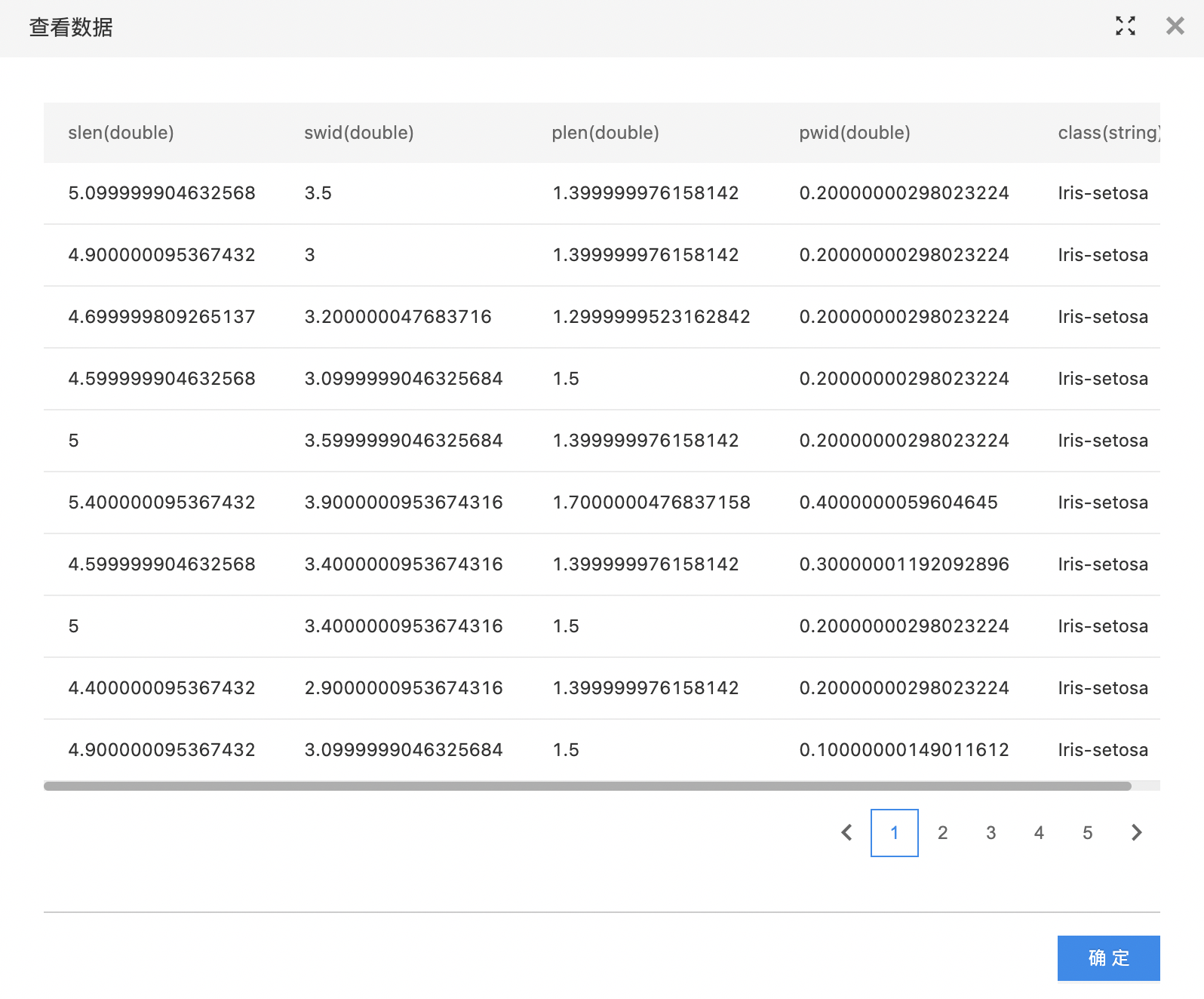
- 查看数据处理结果。
PySpark导出数据
使用PySpark脚本导出数据。
输入
- 输入一个数据集,需要编写导出数据的Python代码。
输出
- 导出数据集。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python代码编辑窗口 | 是 | 在编辑窗口中编辑导出数据脚本 | 无 |
使用示例
-
编写数据导出Python代码,等待算子运行成功。
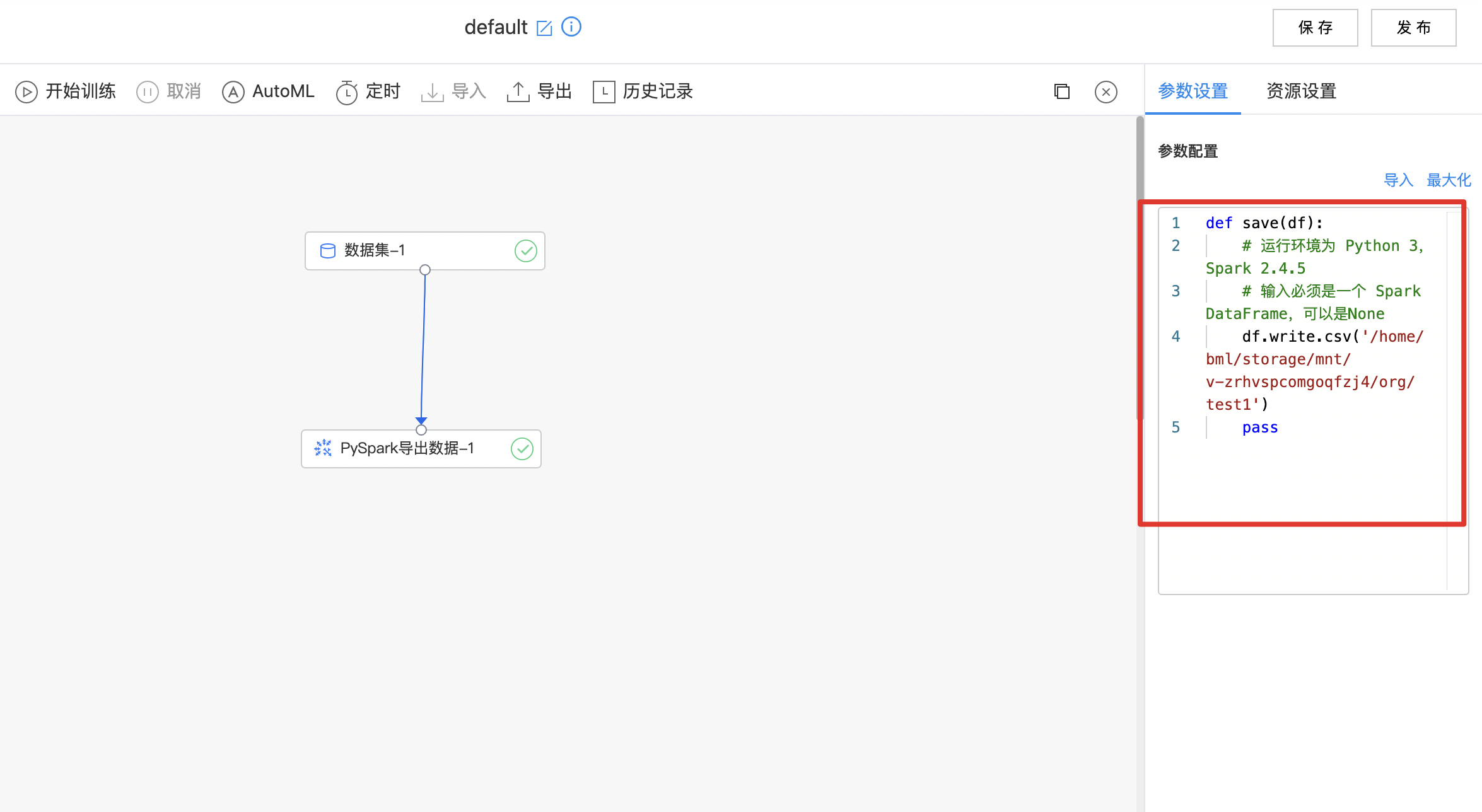
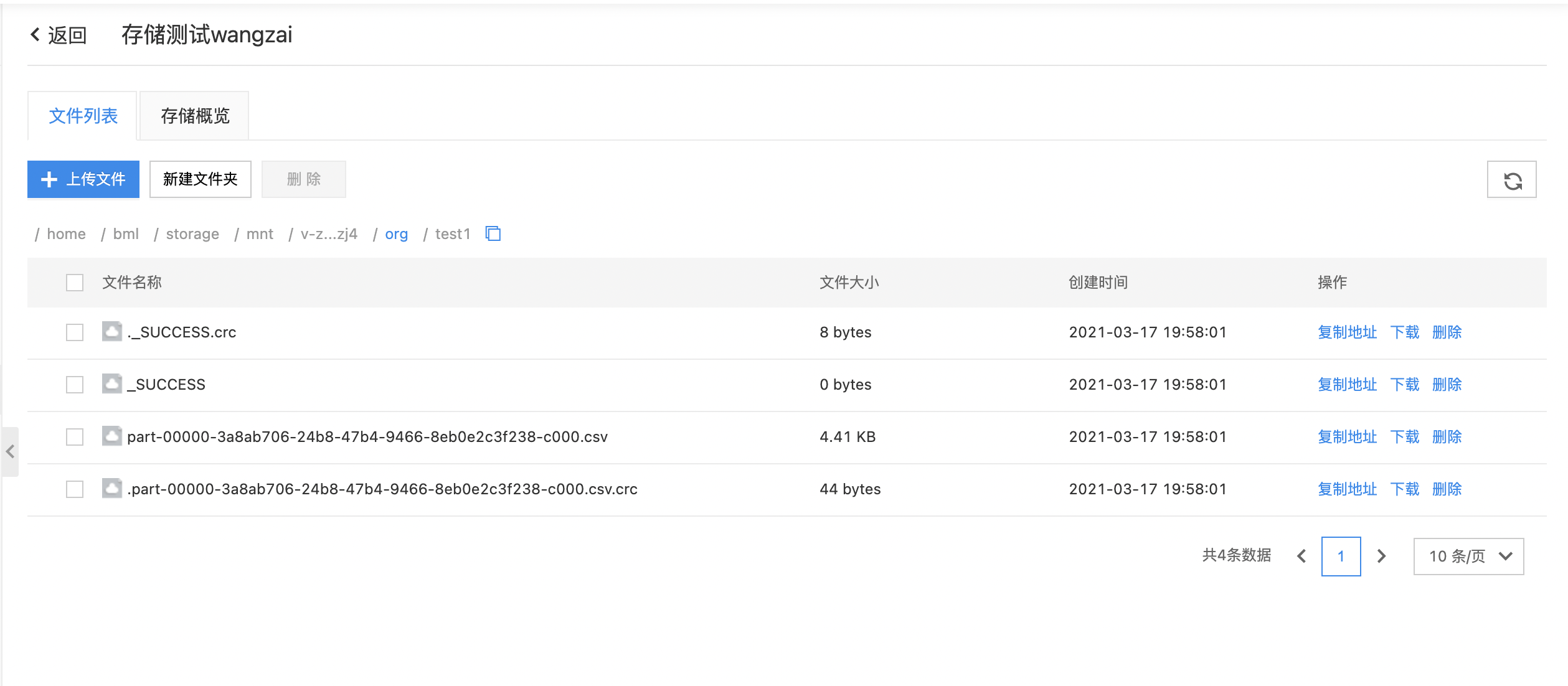
-
到相应路径查看导出的数据文件
PySpark脚本
使用PySpark脚本导出数据。
输入
- 最多输入四个数据表。
输出
- 输出一个数据表。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| Python代码编辑窗口 | 是 | 在编辑窗口中编辑数据处理脚本 | 无 |
使用示例
-
拖入数据集组件,选择数据集
-
拖入PySpark脚本组件,连接数据集组件后,在代码编辑窗口编写代码,运行查看结果