
预置模型调参模式开发
为有一定AI开发基础的开发者提供预置模型调参建模方式,涵盖ResNet、YOLO、PicoDet、MaskRCNN等近30种网络类型,适配大部分场景,开发者只需选择合适的预训练模型以及网络,根据自身经验进行调整,以获得更适合特定场景的模型。
训练配置
预置模型调参模式下支持对模型文件导出类型、训练使用算法与网络类型、网络参数等内容进行设置。
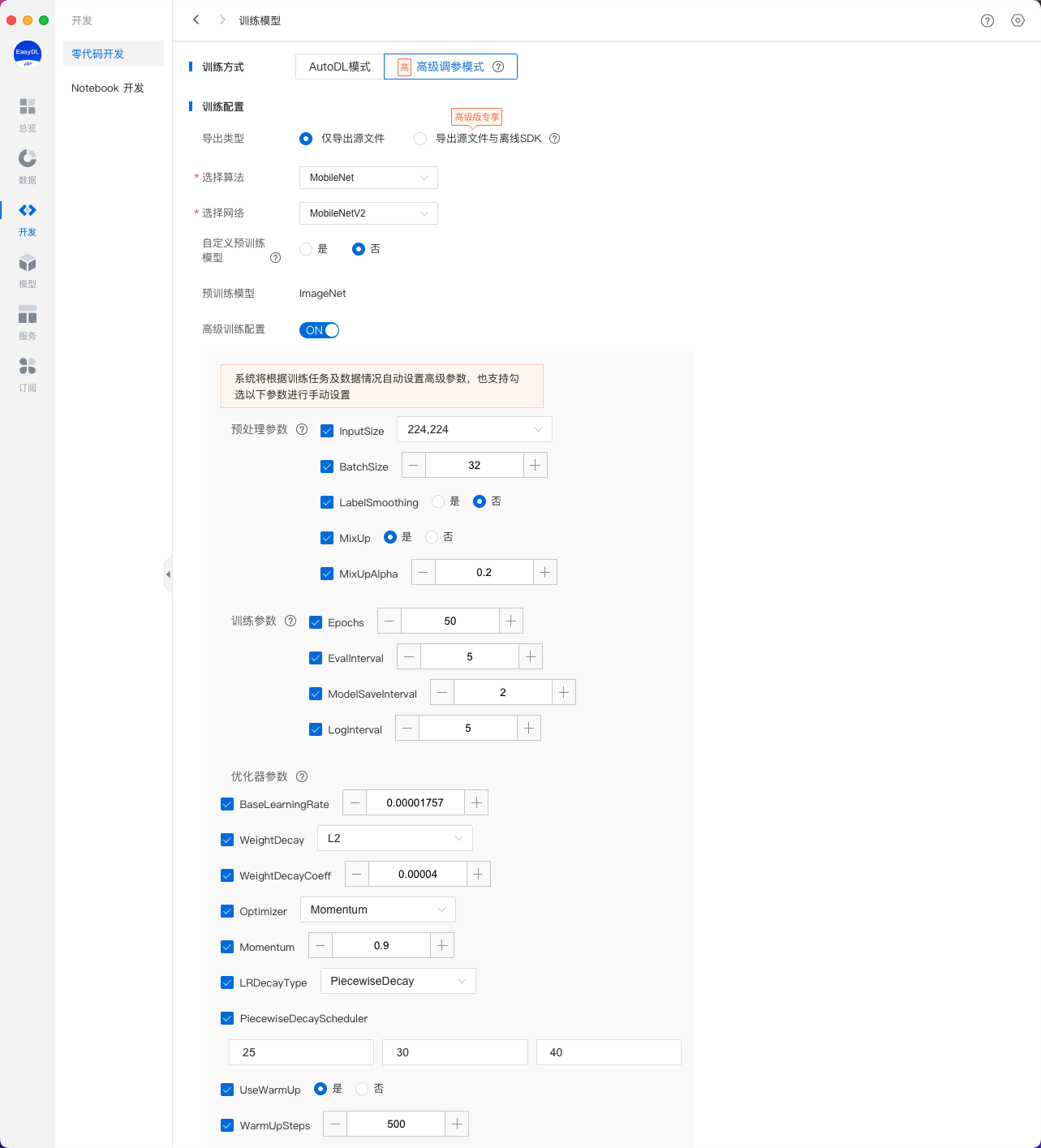
导出类型
- 导出模型源文件:训练完成后支持将模型源文件导出,模型源文件可通过Paddle-Inference转化至实际应用场景中使用
- 导出模型源文件与离线SDK:训练完成后可直接将模型发布为SDK包,可直接用于业务集成,省去繁琐转化过程
预置算法及网络选择
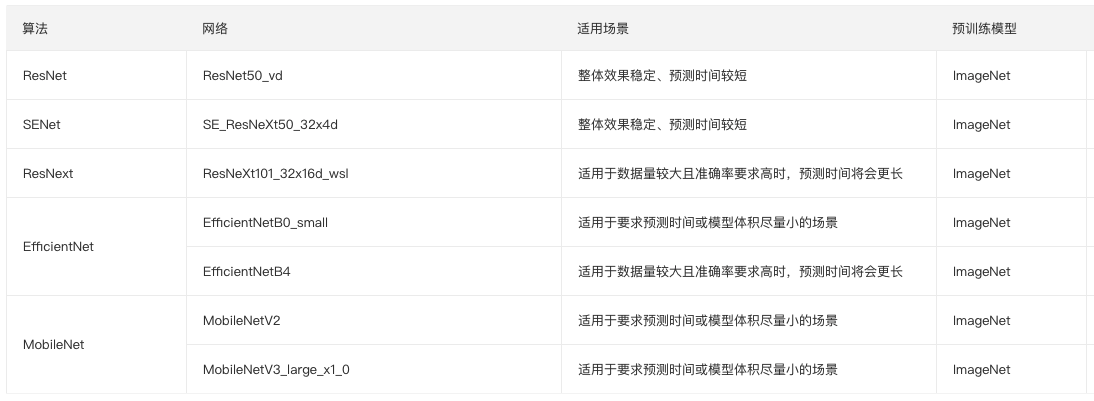
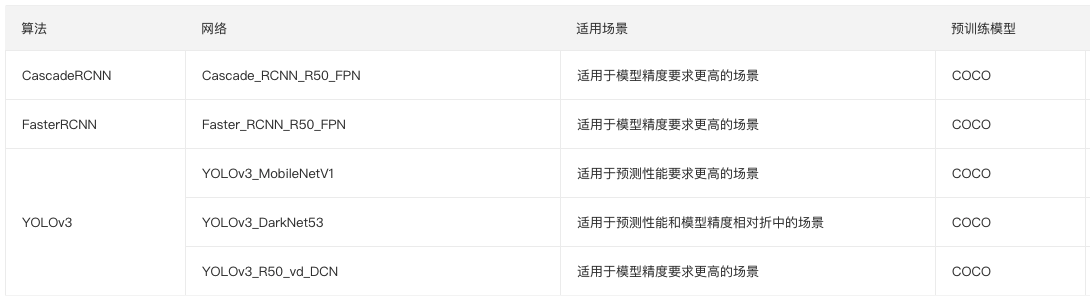
预置模型调参模式中,现已含盖ResNet50_vd、YOLOv3_MobileNetV1、SSD_MobileNetV1、Mask_RCNN_R50_vd_FPN等图像分类、物体检测、实例分割3类场景下14类网络,后续还将进一步提升预置网络数量。
图像分类
物体检测
实例分割

高级训练配置(模型参数)
高级训练配置中提供了预处理参数、训练参数、优化器参数可供选择调整,系统将根据训练任务及数据情况自动设置高级参数,也支持勾选部分参数进行手动设置。
图像分类
预处理参数
| 参数 | 说明 |
|---|---|
| InputSize | 输入图像分辨率,值越大训练时显存占用越大。 |
| BatchSize | 一次训练所选取的样本数,值越大训练时显存占用越大。 |
| LabelSmoonthing | 标签平滑,是机器学习领域的一种正则化方法,通常用于分类问题,目的是防止模型在训练时过于自信地预测标签,改善泛化能力差的问题。 |
| MixUpAlpha | 图像混合系数,MixUp是一种数据增强方式,通过将随机的两张样本按比例混合,在训练过程中不会出现非信息像素,从而能够提高训练效率。 |
训练参数
| 参数 | 说明 |
|---|---|
| Epochs | 训练集完整参与训练的次数,迭代轮数越多训练耗时越长。 |
| EvalInterval | 训练中评估的次数,评估间隔越小评估越频繁,训练耗时越长。 |
| ModelSaveInterval | 训练中模型保存间隔,间隔越小训练过程中保存的模型越多。 |
| LogInterva | 训练日志输出间隔,间隔越小训练日志内容越多。 |
优化器参数
| 参数 | 说明 |
|---|---|
| BaseLearningRate | 单BatchSize对应的学习率,会根据BatchSize和卡数线性增大。学习率是在梯度下降的过程中更新权重时的超参数。学习率过高会导致模型难以收敛;过低会可能导致模型收敛速度过慢,建议根据经验设定合理值 |
| WeightDecay | 分位L1和L2正则。L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| WeightDecayCoeff | 分位L1和L2正则。L1或L2正则:L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| Optimizer | 优化器是在梯度下降中影响参数更新方式的选项,有Momentum,RMSProp,Adam等。 |
| Momentum | 参数更新的计算公式中的动量因子 |
| LRDecayType | 学习率衰减策略,随着训练迭代数的增加,学习率慢慢减小,以帮助模型收敛,常见的策略有阶梯式下降(PiecewiseDecay),余弦下降(CosineDecay)等。 |
| UseWarmUp | 是否使用学习率热身策略。 |
| WarmUpSteps | 学习率热身迭代数,通过该迭代次数后,学习率慢慢增加到指定值。 |
物体检测
网络参数
| 参数 | 说明 |
|---|---|
| KeepTopK | 每个图像可以保留的总边界框数。 |
| ScoreThreshold | 过滤掉低置信度分数的边界框的阈值。 |
| NmsThreshold | 对检测框进行非极大值抑制(NMS)时使用的IOU阈值。 |
| Anchors | 基于锚框的检测框架里对预置锚框(anchor)大小的设置。 |
预处理参数
| 参数 | 说明 |
|---|---|
| InputSize | 输入图像分辨率,值越大训练时显存占用越大。 |
| BatchSize | 一次训练所选取的样本数,值越大训练时显存占用越大。 |
训练参数
| 参数 | 说明 |
|---|---|
| Epochs | 训练集完整参与训练的次数,迭代轮数越多训练耗时越长。 |
| EvalInterval | 训练中评估的次数,评估间隔越小评估越频繁,训练耗时越长。 |
| ModelSaveInterval | 训练中模型保存间隔,间隔越小训练过程中保存的模型越多。 |
| LogInterva | 训练日志输出间隔,间隔越小训练日志内容越多。 |
优化器参数
| 参数 | 说明 |
|---|---|
| BaseLearningRate | 单BatchSize对应的学习率,会根据BatchSize和卡数线性增大。学习率是在梯度下降的过程中更新权重时的超参数。学习率过高会导致模型难以收敛;过低会可能导致模型收敛速度过慢,建议根据经验设定合理值 |
| WeightDecay | 分位L1和L2正则。L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| WeightDecayCoeff | 分位L1和L2正则。L1或L2正则:L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| Optimizer | 优化器是在梯度下降中影响参数更新方式的选项,有Momentum,RMSProp,Adam等。 |
| Momentum | 参数更新的计算公式中的动量因子 |
| LRDecayType | 学习率衰减策略,随着训练迭代数的增加,学习率慢慢减小,以帮助模型收敛,常见的策略有阶梯式下降(PiecewiseDecay),余弦下降(CosineDecay)等。 |
| UseWarmUp | 是否使用学习率热身策略。 |
| WarmUpSteps | 学习率热身迭代数,通过该迭代次数后,学习率慢慢增加到指定值。 |
实例分割
网络参数
| 参数 | 说明 |
|---|---|
| KeepTopK | 每个图像可以保留的总边界框数。 |
| ScoreThreshold | 过滤掉低置信度分数的边界框的阈值。 |
| NmsThreshold | 对检测框进行非极大值抑制(NMS)时使用的IOU阈值。 |
| Anchors | 基于锚框的检测框架里对预置锚框(anchor)大小的设置。 |
预处理参数
| 参数 | 说明 |
|---|---|
| InputSize | 输入图像分辨率,值越大训练时显存占用越大。 |
| BatchSize | 一次训练所选取的样本数,值越大训练时显存占用越大。 |
训练参数
| 参数 | 说明 |
|---|---|
| Epochs | 训练集完整参与训练的次数,迭代轮数越多训练耗时越长。 |
| EvalInterval | 训练中评估的次数,评估间隔越小评估越频繁,训练耗时越长。 |
| ModelSaveInterval | 训练中模型保存间隔,间隔越小训练过程中保存的模型越多。 |
| LogInterva | 训练日志输出间隔,间隔越小训练日志内容越多。 |
优化器参数
| 参数 | 说明 |
|---|---|
| BaseLearningRate | 单BatchSize对应的学习率,会根据BatchSize和卡数线性增大。学习率是在梯度下降的过程中更新权重时的超参数。学习率过高会导致模型难以收敛;过低会可能导致模型收敛速度过慢,建议根据经验设定合理值 |
| WeightDecay | 分位L1和L2正则。L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| WeightDecayCoeff | 分位L1和L2正则。L1或L2正则:L1正则化系数,用于权重矩阵稀疏;L2正则化系数,用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
| Optimizer | 优化器是在梯度下降中影响参数更新方式的选项,有Momentum,RMSProp,Adam等。 |
| Momentum | 参数更新的计算公式中的动量因子 |
| LRDecayType | 学习率衰减策略,随着训练迭代数的增加,学习率慢慢减小,以帮助模型收敛,常见的策略有阶梯式下降(PiecewiseDecay),余弦下降(CosineDecay)等。 |
| UseWarmUp | 是否使用学习率热身策略。 |
| WarmUpSteps | 学习率热身迭代数,通过该迭代次数后,学习率慢慢增加到指定值。 |
训练完成后同步发布为模型
任务训练完成后可通过评估、校验验证任务效果,任务效果满足实际使用要求后发布为模型完成模型部署流程,如当前任务已经过多轮迭代且任务效果较有保证可勾选训练完成后同步发布为模型,并输入发布为的模型名称以及版本描述,训练成功后将会自动发布为模型
任务与模型一一对应,如当前任务已有版本发布为模型,则当前任务下的其他版本发布时仅支持发布在当前模型下
数据配置
添加训练数据
- 先选择数据集,再按分类选择数据集里的图片,可从多个数据集选择图片
- 训练时间与数据量大小有关,数据量越大,训练耗时越长 Tips:
- 图像分类任务类型,如只有1个分类需要识别,或者实际业务场景所要识别的图片内容不可控,可以在训练前勾选"增加识别结果为[其他]的默认分类"。勾选后,模型会将与训练集无关的图片识别为"其他"
- 如果同一个分类的数据分散在不同的数据集里,可以在训练时同时从这些数据集里选择分类,模型训练时会合并分类名称相同的图片
添加自定义验证集
AI模型在训练时,每训练一批数据会进行模型效果检验,以某一张验证图片作为验证数据,通过验证结果反馈去调节训练。可以简单地把AI模型训练理解为学生学习,训练集则为每天的上课内容,验证集即为每周的课后作业,质量更高的每周课后作业能够更好的指导学生学习并找寻自己的不足,从而提高成绩。同理AI模型训练的验证集也是这个功效。
注:学生的课后作业应该与上课内容对应,这样才能巩固知识。因此,验证集的标签也应与训练集完全一致。
添加自定义测试集
如果学生的期末考试是平时的练习题,那么学生可能通过记忆去解题,而不是通过学习的方法去做题,所以期末考试的试题应与平时作业不能一样,才能检验学生的学习成果。那么同理,AI模型的效果测试不能使用训练数据进行测试,应使用训练数据集外的数据测试,这样才能真实的反映模型效果。
注:期末考试的内容属于学期的内容,但不一定需要完全包括所学内容。同理,测试集的标签是训练集的全集或者子集即可。
配置数据增强策略
深度学习模型的成功很大程度上要归功于大量的标注数据集。通常来说,通过增加数据的数量和多样性往往能提升模型的效果。当在实践中无法收集到数目庞大的高质量数据时,可以通过配置数据增强策略,对数据本身进行一定程度的扰动从而产生"新"数据。模型会通过学习大量的"新"数据,提高泛化能力。
你可以在「默认配置」、「手动配置」2种方式中进行选择,完成数据增强策略的配置。
默认配置
如果你不需要特别配置数据增强策略,就可以选择默认配置。后台会根据你选择的算法,自动配置必要的数据增强策略。
手动配置
飞桨EasyDL提供了大量的数据增强算子供开发者手动配置。你可以通过下方的算子功能说明或训练页面的效果展示,来了解不同算子的功能:
| 算子名 | 功能 |
|---|---|
| ShearX | 剪切图像的水平边 |
| ShearY | 剪切图像的垂直边 |
| TranslateX | 按指定距离(像素点个数)水平移动图像 |
| TranslateY | 按指定距离(像素点个数)垂直移动图像 |
| Rotate | 按指定角度旋转图像 |
| AutoContrast | 自动优化图像对比度 |
| Contrast | 调整图像对比度 |
| Invert | 将图像转换为反色图像 |
| Equalize | 将图像转换为灰色值均匀分布的图像 |
| Solarize | 为图像中指定阈值之上的所有像素值取反 |
| Posterize | 减少每个颜色通道的bits至指定位数 |
| Color | 调整图像颜色平衡 |
| Brightness | 调整图像亮度 |
| Sharpness | 调整图像清晰度 |
| Cutout | 通过随机遮挡增加模型鲁棒性,可设定遮挡区域的长宽比例 |

训练环境配置
飞桨EasyDL支持以Intel CPU,或可通过NVIDIA旗下不同型号显卡加速训练。
如果您的计算机有NVIDIA® GPU,且需要使用GPU环境进行训练,请确保满足以下条件:
- Windows 7/8/10/11:需安装 CUDA 11.2 与 cuDNN v8.2.1
- Ubuntu 16.04/18.4/20.4: 需 CUDA 11.2 与 cuDNN v8.1.1
- CentOS 7:需 CUDA 11.2 与 cuDNN v8.1.1
CUDA、cuDNN安装指南
您可参考NVIDIA官方文档了解CUDA和CUDNN的安装流程和配置方法,详见:
评价此篇文章