
图像分类训练操作说明
数据提交后,可以在导航中找到【训练模型】,按以下步骤操作,启动模型训练:
注:1.启动训练前请确保数据已经标注完成,否则无法启动训练
- 下述训练功能点中,标注为星号(*)的功能为非必要选择项,可根据实际需求考虑是否使用
① 选择模型
选择此次训练的模型
② 添加数据
添加训练数据
- 先选择数据集,再按分类选择数据集里的图片,可从多个数据集选择图片
- 训练时间与数据量大小有关,以实际训练时长为准
Tips:
- 如只有1个分类需要识别,或者实际业务场景所要识别的图片内容不可控,可以在训练前勾选"增加识别结果为[其他]的默认分类"。勾选后,模型会将与训练集无关的图片识别为"其他"
- 如果同一个分类的数据分散在不同的数据集里,可以在训练时同时从这些数据集里选择分类,模型训练时会合并分类名称相同的图片
添加自定义验证集*
AI模型在训练时,每训练一批数据会进行模型效果检验,以某一张验证图片作为验证数据,通过验证结果反馈去调节训练。可以简单地把AI模型训练理解为学生学习,训练集则为每天的上课内容,验证集即为每周的课后作业,质量更高的每周课后作业能够更好的指导学生学习并找寻自己的不足,从而提高成绩。同理AI模型训练的验证集也是这个功效。
注:学生的课后作业应该与上课内容对应,这样才能巩固知识。因此,验证集的标签也应与训练集完全一致。
添加自定义测试集*
如果学生的期末考试是平时的练习题,那么学生可能通过记忆去解题,而不是通过学习的方法去做题,所以期末考试的试题应与平时作业不能一样,才能检验学生的学习成果。那么同理,AI模型的效果测试不能使用训练数据进行测试,应使用训练数据集外的数据测试,这样才能真实的反映模型效果。
注:期末考试的内容属于学期的内容,但不一定需要完全包括所学内容。同理,测试集的标签是训练集的全集或者子集即可。
配置数据增强策略
深度学习模型的成功很大程度上要归功于大量的标注数据集。通常来说,通过增加数据的数量和多样性往往能提升模型的效果。当在实践中无法收集到数目庞大的高质量数据时,可以通过配置数据增强策略,对数据本身进行一定程度的扰动从而产生"新"数据。模型会通过学习大量的"新"数据,提高泛化能力。
你可以在「默认配置」、「手动配置」、「自动数据增强」3种方式中进行选择,完成数据增强策略的配置。
默认配置
如果你不需要特别配置数据增强策略,就可以选择默认配置。后台会根据你选择的算法,自动配置必要的数据增强策略。
手动配置
EasyDL提供了大量的数据增强算子供开发者手动配置。你可以通过下方的算子功能说明或训练页面的效果展示,来了解不同算子的功能:
| 算子名 | 功能 |
|---|---|
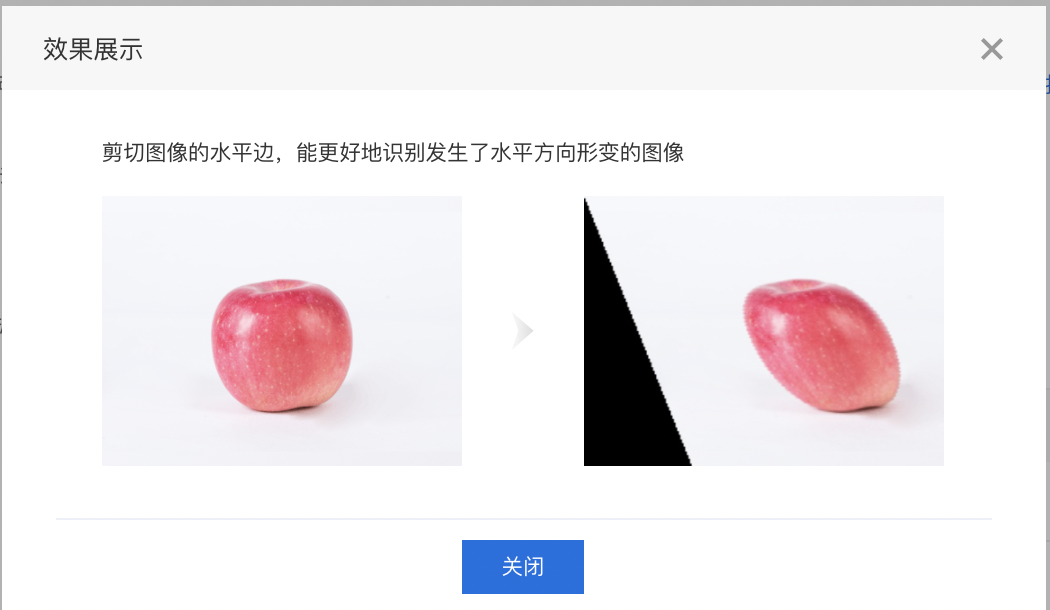
| ShearX | 剪切图像的水平边 |
| ShearY | 剪切图像的垂直边 |
| TranslateX | 按指定距离(像素点个数)水平移动图像 |
| TranslateY | 按指定距离(像素点个数)垂直移动图像 |
| Rotate | 按指定角度旋转图像 |
| AutoContrast | 自动优化图像对比度 |
| Contrast | 调整图像对比度 |
| Invert | 将图像转换为反色图像 |
| Equalize | 将图像转换为灰色值均匀分布的图像 |
| Solarize | 为图像中指定阈值之上的所有像素值取反 |
| Posterize | 减少每个颜色通道的bits至指定位数 |
| Color | 调整图像颜色平衡 |
| Brightness | 调整图像亮度 |
| Sharpness | 调整图像清晰度 |
| Cutout | 通过随机遮挡增加模型鲁棒性,可设定遮挡区域的长宽比例 |
自动数据增强
在训练方式选择「精度提升配置包」选项后,此处数据增强策略提供「自动数据增强」选项。自动数据增强算法会根据您数据的特性,自动选择数据增强算子。使用付费机型训练的用户请注意,自动数据增强算法可能会增加模型训练时间。
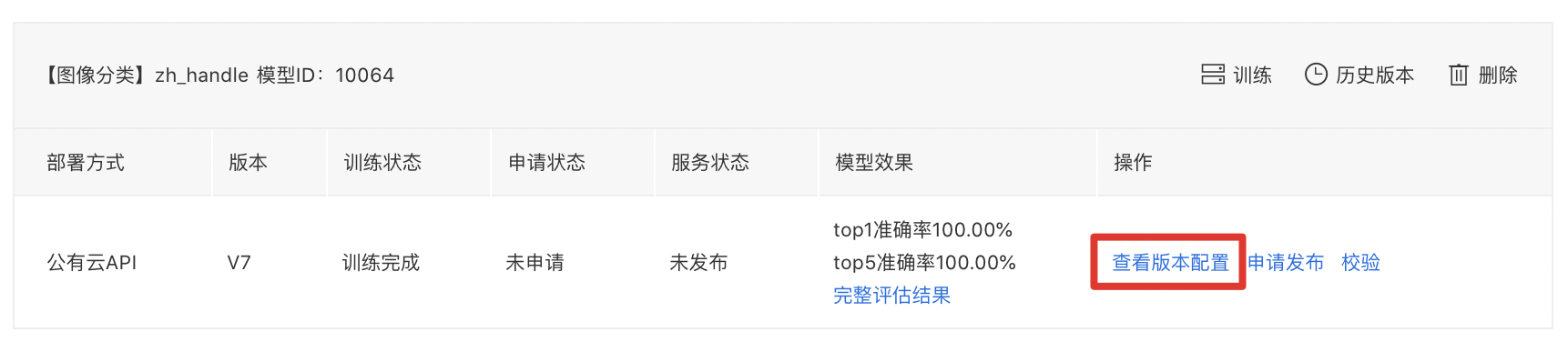
模型训练完成后,可在「我的模型-查看版本配置」中,查看配置记录:
配置建议
算子的配置建议贴合实际场景。
比如,数字识别的数据集中,因为对数字的旋转很有可能导致错误样本的产生,所以不建议对数字数据集进行旋转操作。再比如,检测数据集中,如果标注量比较少,就可以通过随机平移的算子增强数据集,模型也更容易学习到目标物体的平移不变性。
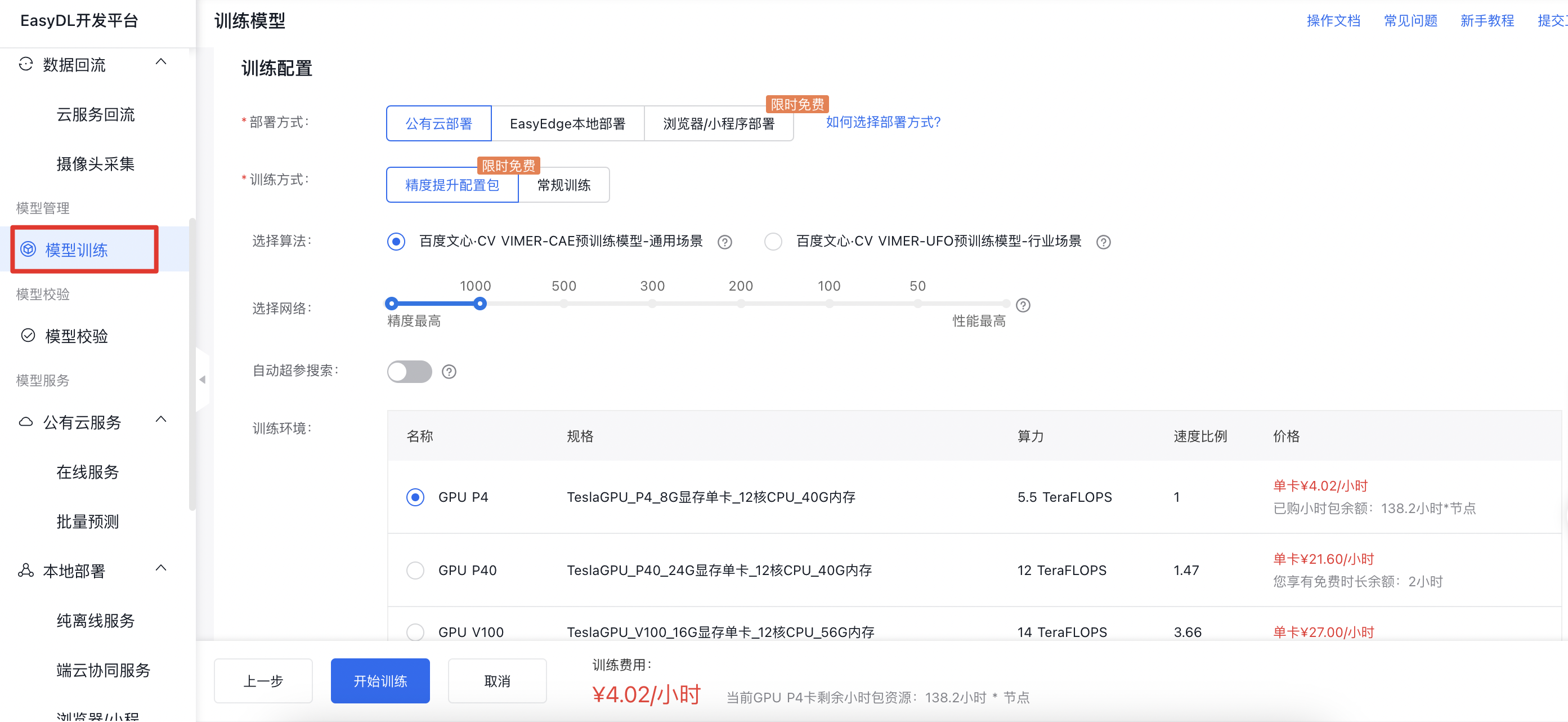
③ 训练配置
部署方式
- 可选择「公有云API」、「EasyEdge本地部署」
- 不知道如何选择?请参考如何选择部署方式
选择设备
- 如果您选择了「EasyEdge本地部署」,请根据实际部署设备选择设备
- 如果您选择了「公有云API」,则可按需选择训练方式
增量训练*
增量训练:在模型迭代训练时,用户在原训练数据上增加了训练数据,可通过加载原训练数据训练的模型参数进行模型训练。这样可让模型收敛速度变快,训练时间变短,同时在数据集质量较高的情况下,可能获得的模型效果也会更好。
注:1. 仅可选择同一部署方式下的训练的模型作为基准模型版本
- 增量训练时所选择的标签应完全包含基准模型的标签。例如基准模型训练的标签为“A”、“B”,那么增量训练时的标签至少有“A”、“B”,不能只有“A”,不能为“C”,可以是“A”、“B”、“C”。
训练方式
EasyDL目前提供完全免费的「常规训练」,以及限时免费的「精度提升配置包」两种选项。
- 「常规训练」包括EasyDL历史提供的「高精度」、「高性能」等模型选择,以及常规的模型训练配置
- 「精度提升配置包」选用百度自有超大规模预训练模型,让模型有更好的精度效果。并提供按云调用时延选择网络模型的形式,根据您实际应用场景需求,选择更合适的模型。另外,EasyDL会持续在「精度提升配置包」中新增提升模型精度效果的配置策略,敬请期待。
自动超参搜索*
自动超参搜索目前仅在精度提升配置包的选项下提供。选择开启自动超参搜索后,算法会多次实验,自动搜寻出适合模型训练的各种参数,来达到高精度的模型效果。
注:开启自动超参搜索后会增加3倍以上的训练时间,请根据实际需求考虑后选择
高级训练配置*
高级训练配置开关默认关闭,建议对深度学习有一定了解的用户根据实际情况考虑使用。高级训练配置目前提供「输入图片分辨率」、「epoch」、「数据不平衡优化」三个配置项
- 输入图片分辨率:可以根据具体应用场景选择输入图片分辨率,如目标主体在图片中较小,就可适当增加输入图片分辨率,增强目标在数据层面的特性。推荐值为该类算法任务输入图片分辨率普遍最优值。
- epoch:训练集完整参与训练的次数。如有训练数据集较大,模型训练不充分,模型精度较低的情况,可适当设置较大epoch值(大于100),使模型训练更完整。
- 数据不平衡优化:适用于不同分类图片量差异较大的情况。当不同分类之间图片数量差异超过10倍以上时,建议开启。开启后可提升模型准确率及泛化能力
选择算法
不同的部署方式下,可以选择不同的算法。每个算法旁边有一个小问号,可以查看详细说明。
例如:选择「公有云API」后,可以在「高精度」、「高性能」、「AutoDL Transfer」3种算法中选择。鼠标移动到「AutoDL Transfer」右侧的问号上,可以看到对AutoDL算法的详细说明。
- 高精度模型在识别准确率上表现较好,但在识别速度上表现较弱。高性能模型反之。
- 如果你已从AI市场购买了模型算法,也可以基于已购模型的算法训练: 前往AI市场购买>
- 本地部署的用户可在算法推理性能大表中查看具体硬件上评测的性能信息
③ 添加数据
添加训练数据
- 先选择数据集,再按分类选择数据集里的图片,可从多个数据集选择图片
- 训练时间与数据量大小有关,以实际训练时长为准
Tips:
- 如只有1个分类需要识别,或者实际业务场景所要识别的图片内容不可控,可以在训练前勾选"增加识别结果为[其他]的默认分类"。勾选后,模型会将与训练集无关的图片识别为"其他"
- 如果同一个分类的数据分散在不同的数据集里,可以在训练时同时从这些数据集里选择分类,模型训练时会合并分类名称相同的图片
添加自定义验证集*
AI模型在训练时,每训练一批数据会进行模型效果检验,以某一张验证图片作为验证数据,通过验证结果反馈去调节训练。可以简单地把AI模型训练理解为学生学习,训练集则为每天的上课内容,验证集即为每周的课后作业,质量更高的每周课后作业能够更好的指导学生学习并找寻自己的不足,从而提高成绩。同理AI模型训练的验证集也是这个功效。
注:学生的课后作业应该与上课内容对应,这样才能巩固知识。因此,验证集的标签也应与训练集完全一致。
添加自定义测试集*
如果学生的期末考试是平时的练习题,那么学生可能通过记忆去解题,而不是通过学习的方法去做题,所以期末考试的试题应与平时作业不能一样,才能检验学生的学习成果。那么同理,AI模型的效果测试不能使用训练数据进行测试,应使用训练数据集外的数据测试,这样才能真实的反映模型效果。
注:期末考试的内容属于学期的内容,但不一定需要完全包括所学内容。同理,测试集的标签是训练集的全集或者子集即可。
配置数据增强策略
深度学习模型的成功很大程度上要归功于大量的标注数据集。通常来说,通过增加数据的数量和多样性往往能提升模型的效果。当在实践中无法收集到数目庞大的高质量数据时,可以通过配置数据增强策略,对数据本身进行一定程度的扰动从而产生"新"数据。模型会通过学习大量的"新"数据,提高泛化能力。
你可以在「默认配置」、「手动配置」、「自动数据增强」3种方式中进行选择,完成数据增强策略的配置。
默认配置
如果你不需要特别配置数据增强策略,就可以选择默认配置。后台会根据你选择的算法,自动配置必要的数据增强策略。
手动配置
EasyDL提供了大量的数据增强算子供开发者手动配置。你可以通过下方的算子功能说明或训练页面的效果展示,来了解不同算子的功能:
| 算子名 | 功能 |
|---|---|
| ShearX | 剪切图像的水平边 |
| ShearY | 剪切图像的垂直边 |
| TranslateX | 按指定距离(像素点个数)水平移动图像 |
| TranslateY | 按指定距离(像素点个数)垂直移动图像 |
| Rotate | 按指定角度旋转图像 |
| AutoContrast | 自动优化图像对比度 |
| Contrast | 调整图像对比度 |
| Invert | 将图像转换为反色图像 |
| Equalize | 将图像转换为灰色值均匀分布的图像 |
| Solarize | 为图像中指定阈值之上的所有像素值取反 |
| Posterize | 减少每个颜色通道的bits至指定位数 |
| Color | 调整图像颜色平衡 |
| Brightness | 调整图像亮度 |
| Sharpness | 调整图像清晰度 |
| Cutout | 通过随机遮挡增加模型鲁棒性,可设定遮挡区域的长宽比例 |
自动数据增强
在训练方式选择「精度提升配置包」选项后,此处数据增强策略提供「自动数据增强」选项。自动数据增强算法会根据您数据的特性,自动选择数据增强算子。使用付费机型训练的用户请注意,自动数据增强算法可能会增加模型训练时间。
模型训练完成后,可在「我的模型-查看版本配置」中,查看配置记录:
配置建议
算子的配置建议贴合实际场景。
比如,数字识别的数据集中,因为对数字的旋转很有可能导致错误样本的产生,所以不建议对数字数据集进行旋转操作。再比如,检测数据集中,如果标注量比较少,就可以通过随机平移的算子增强数据集,模型也更容易学习到目标物体的平移不变性。
④ 训练模型
点击「开始训练」,训练模型。
- 模型训练过程中,可以设置训练完成的短信提醒并离开页面。
- 平台提供付费算力,付费算力可用于模型训练,可根据实际需求购买算力使用时长。
- 训练时间与数据量大小有关,以实际训练时长为准。
各类算力价格如下:
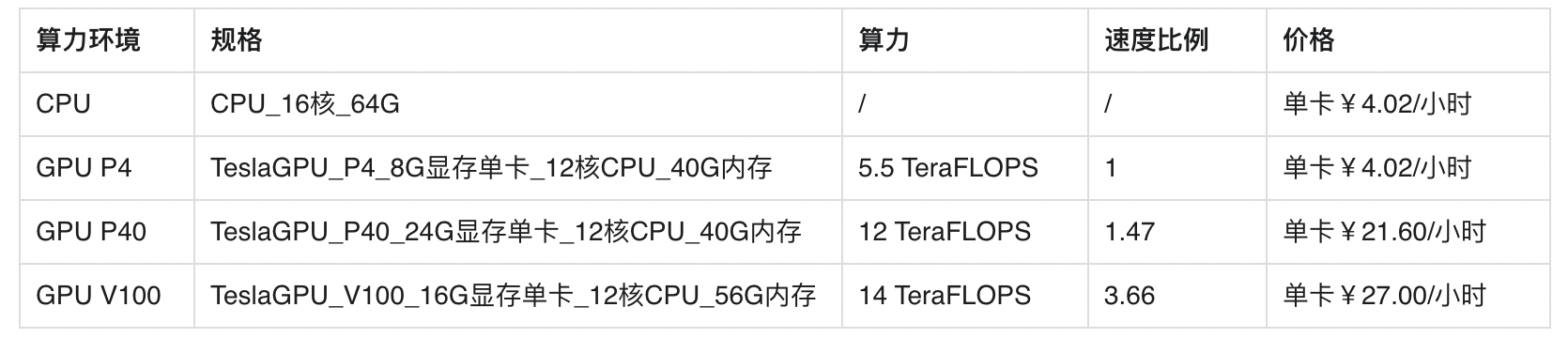
支持算力小时包和储值两种付费方式。算力按分钟计费,账单金额精确至小数点后2位。训练失败、训练状态为排队中时长均不纳入收费时长。
评价此篇文章