
经典版语音识别创建模型
在导航栏【模型中心】-【我的模型】页中可以点击【创建模型】按钮;也可以直接点击左侧导航菜单中的【创建模型】进入创建模型步骤。目前一个账号下支持创建10个模型,模型可删除。
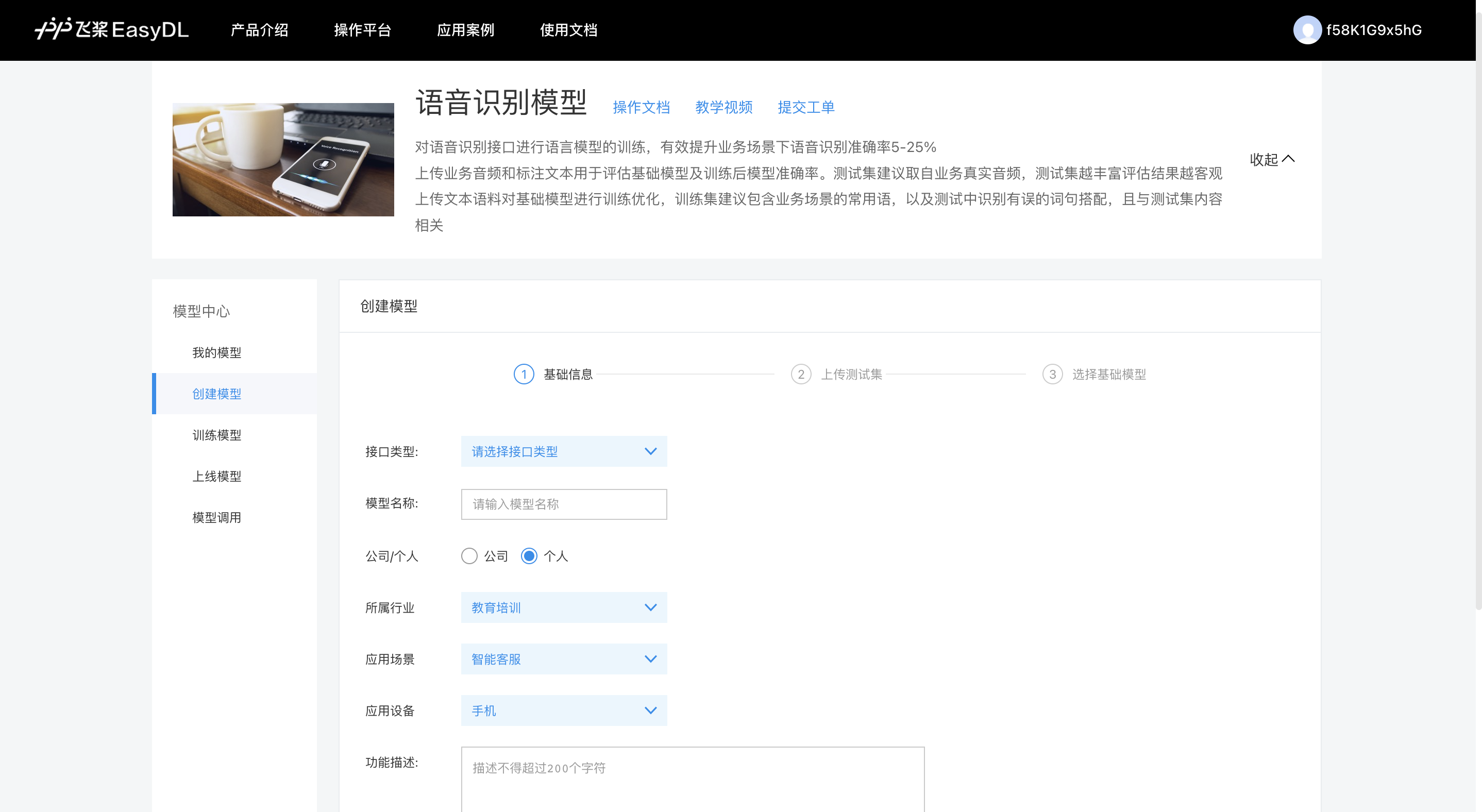
在创建模型步骤中,需要进行“基础信息填写”“上传测试集”“选择基础模型”三个环节完成创建。
测试集的作用为通过上传音频和正确的标注文本评估基础模型的识别率,根据基础模型识别率选择最合适的基础模型进行训练。等模型训练后系统自动使用该测试集评估得到训练后模型的识别率,可以直观的查看训练提升效果。
-
基础信息:包括接口类型、模型名称、公司/个人、所属行业、应用场景、应用设备、功能描述、邮箱地址、联系方式
- 接口类型:包括短语音识别(支持16K采样率音频)、实时语音识别(支持16K采样率音频)和呼叫中心场景(支持8K采样率音频)3种,用户可以基于应用场景和音频采样率来进行选择。
- 模型名称:用户可自行填写模型名称,可支持中文、英文、数字、下划线.+#*()^-
- 公司/个人:模型归属企业则需要填写企业名称,归属个人则不需填写
- 所属行业:企业业务或个人应用所属的行业信息
- 应用场景:语音识别模型应用落地的业务场景
- 应用设备:业务中使用语音技术的录音设备终端
- 功能描述:描述模型应用的场景,有助于上线审核哦
- 邮箱地址:填写联系人的邮箱地址,用于模型上线等信息的通知
- 联系方式:第一个模型需要用户填写联系方式,后面的模型系统自动复制第一个模型的联系方式(可修改)其中,公司/个人、所属行业、应用场景、应用设备、功能描述、邮箱地址、联系方式在第一个模型中的填写信息会重复使用,后面创建的模型不用重复填写,但可修改信息
-
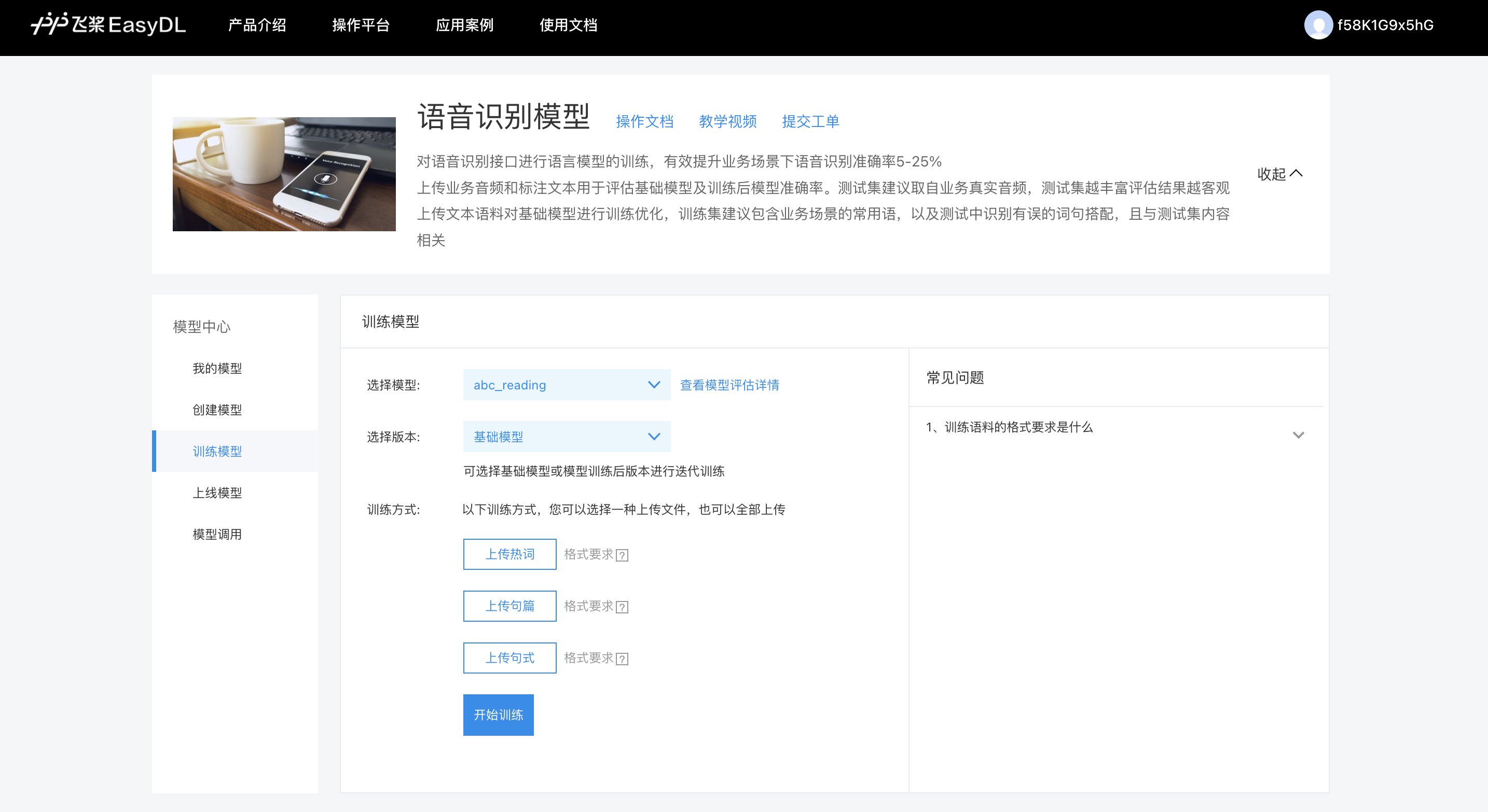
上传测试集:包括填写测试集名称、上传语音文件、上传标注文件
- 上传测试集:用户可自行填写测试集名称,可支持中文、英文、数字、下划线.+#*()^-
-
上传语音文件:上传音频压缩zip文件(请将所有音频文件直接压缩,请勿将音频存放在文件夹内再压缩),格式要求:
- 16k 16bit单声道pcm/wav文件
- 8k 16bit 单声道pcm/wav文件(客服场景);
- 音频文件名请不要包含中文、特殊符号、空格等字符;
- 所有音频需直接打包压缩为zip文件格式后上传,zip大小不超过100M,解压后单个音频大小不超过150M
-
上传标注文件:上传音频的标注文本txt文件,格式要求:
- 标注文件内容应与音频文件相对应的内容一致(单条音频对应文本长度不超过5000字);
- 标注文件格式应为txt格式,GBK编码;
- 标注txt文本中,由音频名称、标注内容两部分构成,用"tab"区隔,带后缀或不带后缀均可;
上传完语音文件及标注文件,点击【开始评估】,后台进入评估状态,此时弹窗提示评估完毕时间,并自动跳转回【我的模型】。一个账号只能同时评估一个模型。待模型评估完毕后通过【我的模型】可以点击进入“选择基础模型”
- 选择基础模型:系统根据基础模型的识别率自动推荐适合训练的基础模型,基础模型识别率超过50%才可选择进行训练。
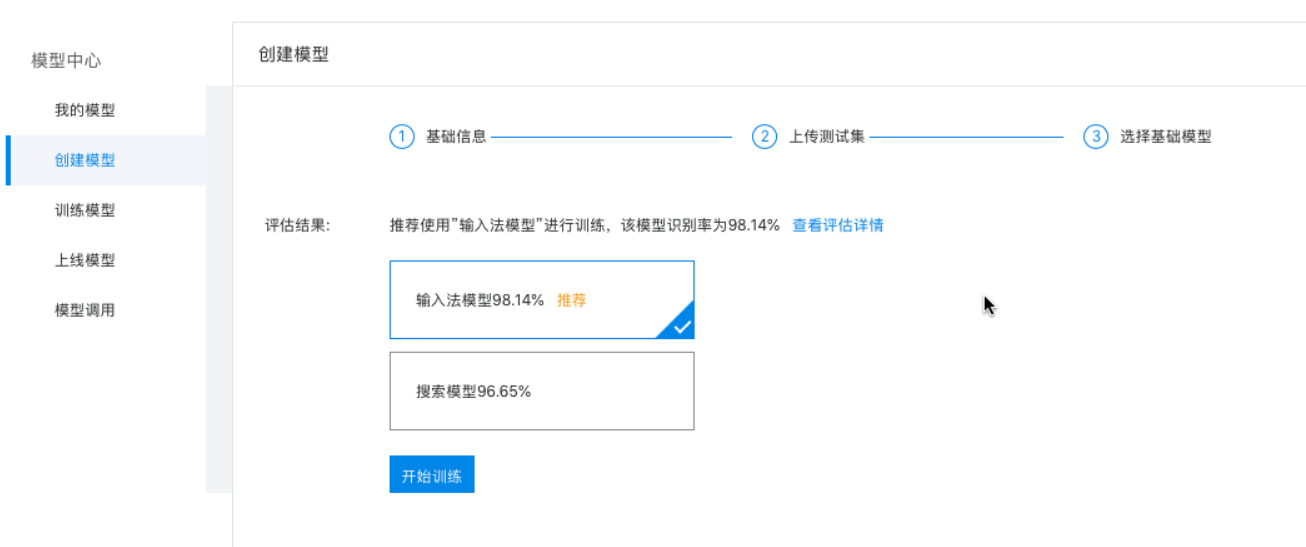
若基础模型识别率未达到50%,请检查语音文件和标注文件内容是否匹配,若不匹配,训练结果无意义。若检查标注文件无误后识别率仍旧过低,可以加入官方QQ群进行咨询:686267521
- 短语音识别产品类型中目前支持对短语音识别极速版进行训练
- 实时语音识别产品类型中目前支持对实时语音识别的中文普通话模型进行训练
- 呼叫中心产品类型中目前支持对呼叫中心语音解决方案进行训练
选择基础模型后点击【开始训练】即可在该模型上进行模型训练。
点击“查看评估详情”可以查看测试集在基础模型上的具体识别结果,评估详情包括:字准率,句准率,插入错误,删除错误,替换错误5个指标,以及在该测试集上的具体识别结果与标注结果的对比,根据识别错误信息可以更加精准地准备训练文本。
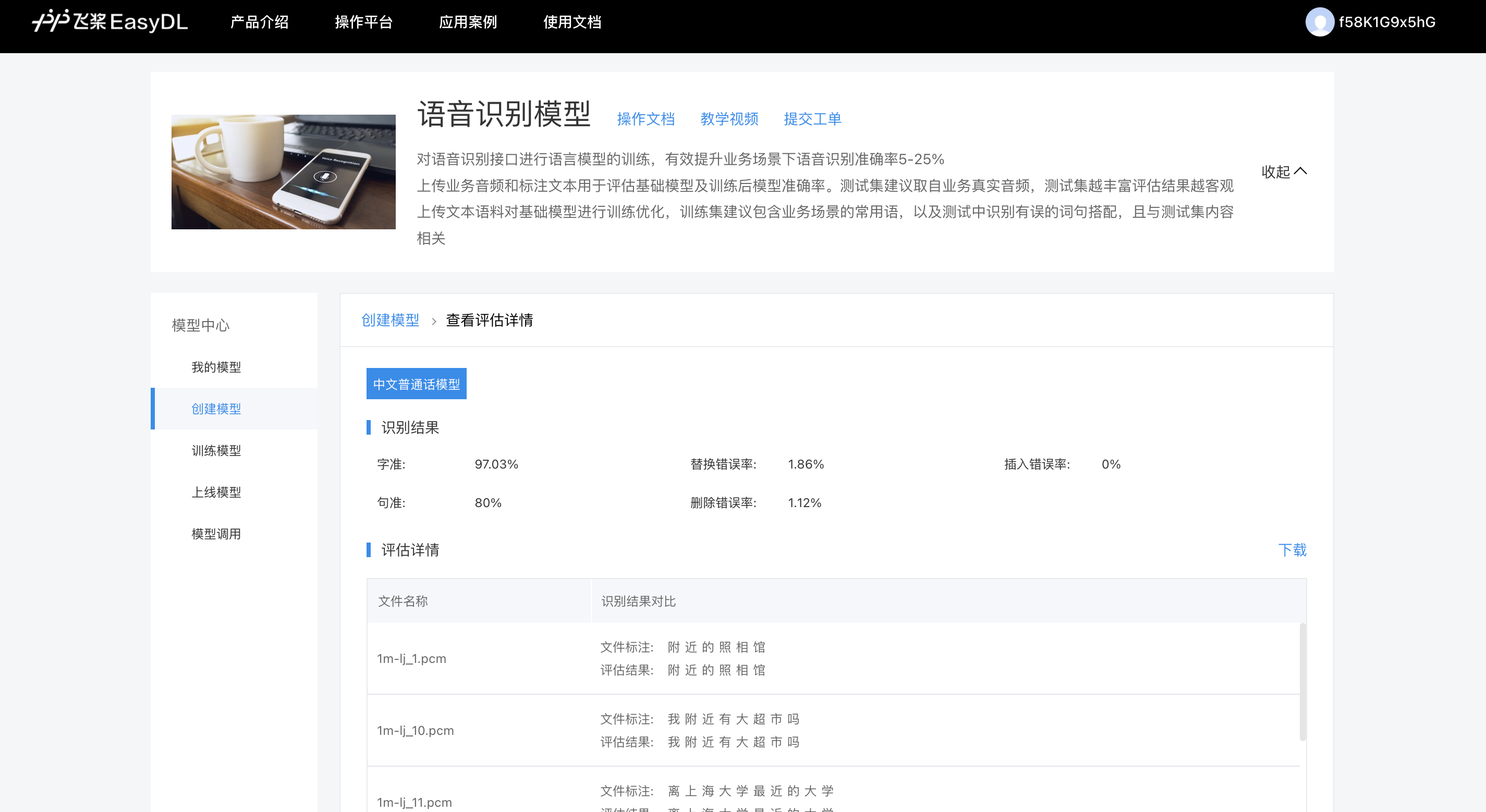
在“查看评估详情”页点击“返回上一步”或“创建模型”可返回选择基础模型
评价此篇文章